

Comment SpringBoot utilise Caffeine pour implémenter la mise en cache

Pourquoi ajouter la mise en cache aux applications
Avant de découvrir comment ajouter la mise en cache aux applications, la première question qui nous vient à l'esprit est de savoir pourquoi nous devons utiliser la mise en cache dans les applications.
Supposons qu'il existe une application qui contient des données client et que l'utilisateur fasse deux requêtes pour obtenir les données du client (id=100).
C'est ce qui se passe sans mise en cache.
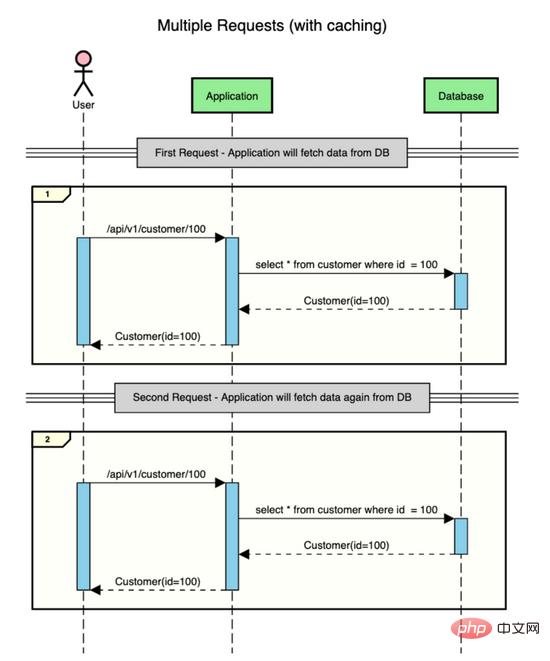
Comme vous pouvez le constater, pour chaque requête, l'application se rend dans la base de données pour récupérer les données. Obtenir des données à partir de la base de données est une opération coûteuse car elle implique des E/S.
Cependant, si vous disposez d'un magasin de cache au milieu où vous pouvez stocker temporairement des données pendant une courte période de temps, vous pouvez enregistrer ces allers-retours dans la base de données et les enregistrer au moment des IO.
Voici à quoi ressemble l'interaction ci-dessus lors de l'utilisation de la mise en cache.
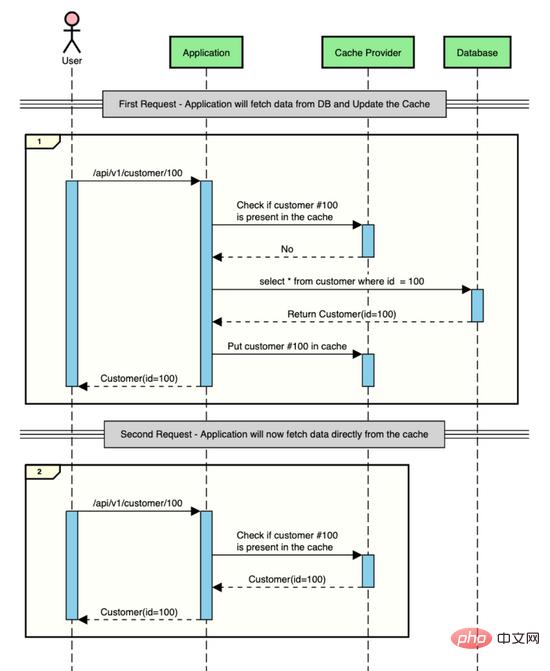
Implémentation de la mise en cache dans les applications Spring Boot
Quelle prise en charge de la mise en cache SpringBoot fournit-elle ?
SpringBoot fournit uniquement une abstraction de cache que vous pouvez utiliser pour ajouter du cache de manière transparente et facile à votre application Spring.
Il ne fournit pas de véritable stockage de cache.
Cependant, il peut fonctionner avec différents types de fournisseurs de cache comme Ehcache, Hazelcast, Redis, Caffee, etc.
L'abstraction de la mise en cache de SpringBoot peut être ajoutée aux méthodes (à l'aide d'annotations)
Fondamentalement, avant d'exécuter la méthode, le framework Spring vérifiera si les données de la méthode sont déjà mises en cache
Si oui, il les récupérera à partir du cache Récupérer les données de.
Sinon, il exécutera la méthode et mettra en cache les données
Il fournit également une abstraction pour mettre à jour ou supprimer les données du cache.
Dans notre blog actuel, nous apprendrons comment ajouter une mise en cache à l'aide de Caffeine, une bibliothèque de mise en cache hautes performances et presque optimale basée sur Java 8.
Vous pouvez spécifier le fournisseur de cache à utiliser dans le fichier application.yaml en définissant la propriété spring.cache.type. application.yaml 文件中指定使用哪个缓存提供程序来设置 spring.cache.type 属性。
但是,如果没有提供属性,Spring将根据添加的库自动检测缓存提供程序。
添加生成依赖项
现在假设您已经启动并运行了基本的Spring boot应用程序,让我们添加缓存依赖项。
打开 build.gradle 文件,并添加以下依赖项以启用Spring Boot的缓存
compile('org.springframework.boot:spring-boot-starter-cache')
接下来我们将添加对Caffeine的依赖
compile group: 'com.github.ben-manes.caffeine', name: 'caffeine', version: '2.8.5'
缓存配置
现在我们需要在Spring Boot应用程序中启用缓存。
为此,我们需要创建一个配置类并提供注释 @EnableCaching 。
@Configuration
@EnableCaching
public class CacheConfig {
}现在这个类是一个空类,但是我们可以向它添加更多配置(如果需要)。
现在我们已经启用了缓存,让我们提供缓存名称和缓存属性的配置,如缓存大小、缓存过期时间等
最简单的方法是在 application.yaml 中添加配置
spring:
cache:
cache-names: customers, users, roles
caffeine:
spec: maximumSize=500, expireAfterAccess=60s上述配置执行以下操作
将可用缓存名称限制为客户、用户和角色。将最大缓存大小设置为500。
当缓存中的对象数达到此限制时,将根据缓存逐出策略从缓存中删除对象。将缓存过期时间设置为1分钟。
这意味着项目将在添加到缓存1分钟后从缓存中删除。
还有另一种配置缓存的方法,而不是在 application.yaml 文件中配置缓存。
您可以在缓存配置类中添加并提供一个 CacheManager Bean,该Bean可以完成与上面在 application.yaml 中的配置完全相同的工作
@Bean
public CacheManager cacheManager() {
Caffeine<Object, Object> caffeineCacheBuilder =
Caffeine.newBuilder()
.maximumSize(500)
.expireAfterAccess(
1, TimeUnit.MINUTES);
CaffeineCacheManager cacheManager =
new CaffeineCacheManager(
"customers", "roles", "users");
cacheManager.setCaffeine(caffeineCacheBuilder);
return cacheManager;
}在我们的代码示例中,我们将使用Java配置。
我们可以在Java中做更多的事情,比如配置 RemovalListener ,当一个项从缓存中删除时执行 RemovalListener ,或者启用缓存统计记录,等等。
缓存方法结果
在我们使用的示例Spring boot应用程序中,我们已经有了以下API GET /API/v1/customer/{id} 来检索客户记录。
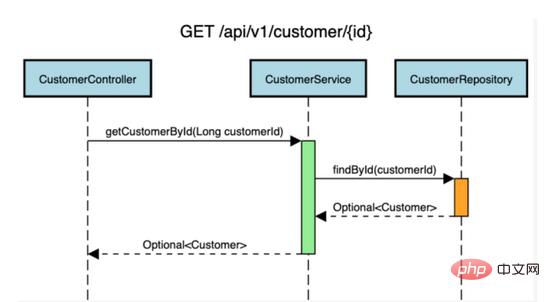
我们将向CustomerService类的 getCustomerByd(longCustomerId) 方法添加缓存。
要做到这一点,我们只需要做两件事
1. 将注释 @CacheConfig(cacheNames=“customers”) 添加到 CustomerService 类
提供此选项将确保 CustomerService
build.gradle et ajoutez les dépendances suivantes pour activer le cache de Spring Boot🎜@Service
@Log4j2
@CacheConfig(cacheNames = "customers")
public class CustomerService {
@Autowired
private CustomerRepository customerRepository;
@Cacheable
public Optional<Customer> getCustomerById(Long customerId) {
log.info("Fetching customer by id: {}", customerId);
return customerRepository.findById(customerId);
}
} 代码如下:log.info("Fetching customer by id: {}", customerId);@EnableCaching . 🎜@CachePut @cacheexecute
application.yaml< /code> 🎜 <div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>@Cacheable( value = "persons", unless = "#result?.id")
public Optional<Person> getPerson(Long personId)</pre><div class="contentsignin">Copier après la connexion</div></div><div class="contentsignin">Copier après la connexion</div></div>🎜La configuration ci-dessus fait ce qui suit🎜🎜🎜🎜Limite les noms de cache disponibles aux clients, utilisateurs et rôles. Définissez la taille maximale du cache sur 500. 🎜🎜🎜🎜Lorsque le nombre d'objets dans le cache atteint cette limite, les objets seront supprimés du cache conformément à la politique d'expulsion du cache. Définissez le délai d'expiration du cache sur 1 minute. 🎜🎜🎜🎜Cela signifie que l'élément sera supprimé du cache 1 minute après avoir été ajouté au cache. 🎜🎜🎜🎜Il existe une autre façon de configurer le cache au lieu de configurer le cache dans le fichier <code>application.yaml. 🎜🎜Vous pouvez ajouter et fournir un bean CacheManager dans la classe de configuration du cache, qui peut faire exactement le même travail que la configuration ci-dessus dans application.yaml 🎜@Cacheable(value = "persons", condition="#fetchFromCache") public Optional<Person> getPerson(long personId, boolean fetchFromCache)
RemovalListener, exécuter RemovalListener lorsqu'un élément est supprimé du cache, ou activer la journalisation des statistiques du cache, etc. 🎜🎜Résultats de la méthode de cache🎜🎜Dans l'exemple d'application Spring Boot que nous utilisons, nous disposons déjà de l'API GET /API/v1/customer/{id} suivante pour récupérer les enregistrements client. 🎜🎜🎜🎜Nous appliquerons le Classe CustomerService La méthode getCustomerByd(longCustomerId) ajoute la mise en cache. 🎜🎜Pour ce faire, il suffit de faire deux choses🎜🎜1. Ajouter l'annotation @CacheConfig(cacheNames="customers") à la classe CustomerService🎜🎜 Fournir cette option garantira que toutes les méthodes pouvant être mises en cache de CustomerService utiliseront le nom de cache "clients" 🎜2. 向方法 Optional getCustomerById(Long customerId) 添加注释 @Cacheable
@Service
@Log4j2
@CacheConfig(cacheNames = "customers")
public class CustomerService {
@Autowired
private CustomerRepository customerRepository;
@Cacheable
public Optional<Customer> getCustomerById(Long customerId) {
log.info("Fetching customer by id: {}", customerId);
return customerRepository.findById(customerId);
}
}另外,在方法 getCustomerById() 中添加一个 LOGGER 语句,以便我们知道服务方法是否得到执行,或者值是否从缓存返回。
代码如下:log.info("Fetching customer by id: {}", customerId);测试缓存是否正常工作
这就是缓存工作所需的全部内容。现在是测试缓存的时候了。
启动您的应用程序,并点击客户获取url
http://localhost:8080/api/v1/customer/
在第一次API调用之后,您将在日志中看到以下行—“ Fetching customer by id ”。
但是,如果再次点击API,您将不会在日志中看到任何内容。这意味着该方法没有得到执行,并且从缓存返回客户记录。
现在等待一分钟(因为缓存过期时间设置为1分钟)。
一分钟后再次点击GETAPI,您将看到下面的语句再次被记录——“通过id获取客户”。
这意味着客户记录在1分钟后从缓存中删除,必须再次从数据库中获取。
为什么缓存有时会很危险
缓存更新/失效
通常我们缓存 GET 调用,以提高性能。
但我们需要非常小心的是缓存对象的更新/删除。
@CachePut @cacheexecute
如果未将 @CachePut/@cacheexecute 放入更新/删除方法中,GET调用中缓存返回的对象将与数据库中存储的对象不同。考虑下面的示例场景。
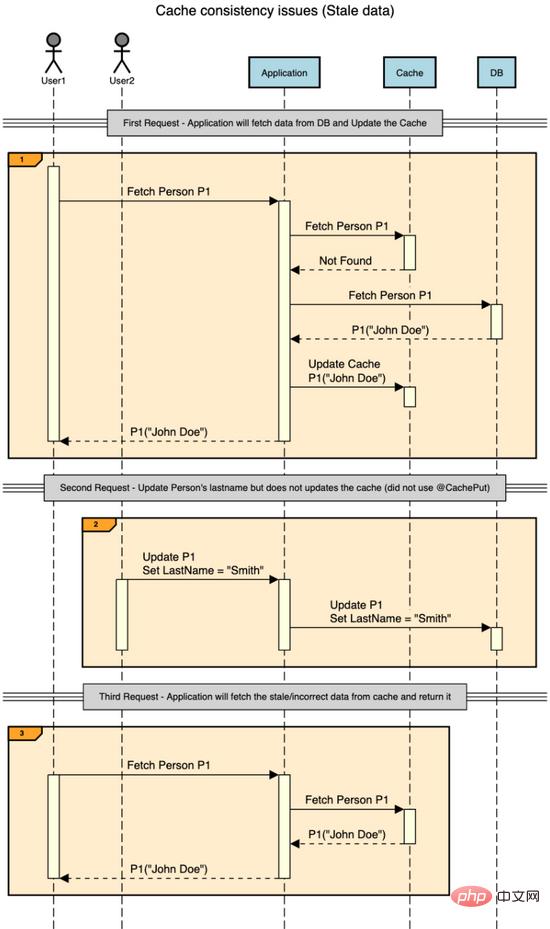
如您所见,第二个请求已将人名更新为“ John Smith ”。但由于它没有更新缓存,因此从此处开始的所有请求都将从缓存中获取过时的个人记录(“ John Doe ”),直到该项在缓存中被删除/更新。
缓存复制
大多数现代web应用程序通常有多个应用程序节点,并且在大多数情况下都有一个负载平衡器,可以将用户请求重定向到一个可用的应用程序节点。
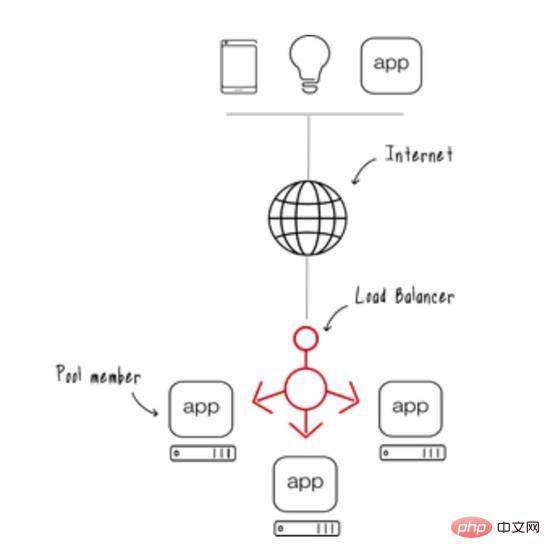
这种类型的部署为应用程序提供了可伸缩性,任何用户请求都可以由任何一个可用的应用程序节点提供服务。
在这些分布式环境(具有多个应用服务器节点)中,缓存可以通过两种方式实现
应用服务器中的嵌入式缓存(正如我们现在看到的)
远程缓存服务器
嵌入式缓存
嵌入式缓存驻留在应用程序服务器中,它随应用程序服务器启动/停止。由于每台服务器都有自己的缓存副本,因此对其缓存的任何更改/更新都不会自动反映在其他应用程序服务器的缓存中。
考虑具有嵌入式缓存的多节点应用服务器的下面场景,其中用户可以根据应用服务器为其请求服务而得到不同的结果。
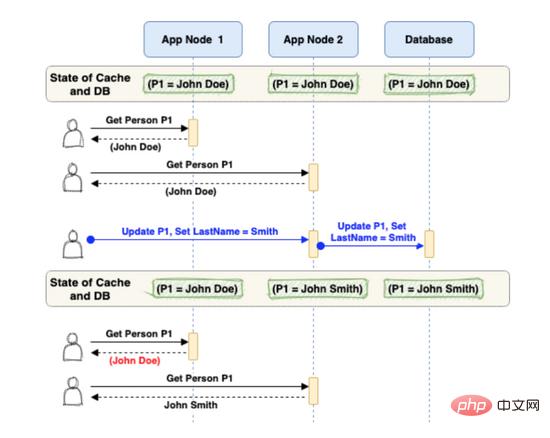
正如您在上面的示例中所看到的,更新请求更新了 Application Node2 的数据库和嵌入式缓存。
但是, Application Node1 的嵌入式缓存未更新,并且包含过时数据。因此, Application Node1 的任何请求都将继续服务于旧数据。
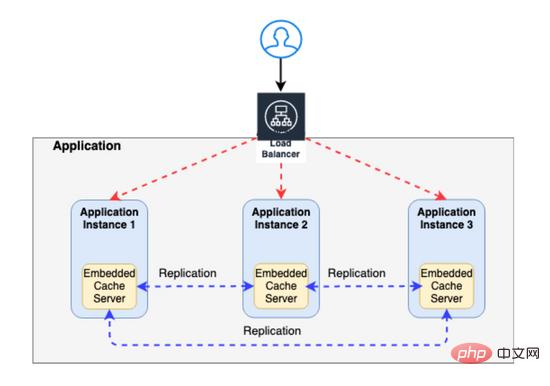
要解决这个问题,您需要实现 CACHE REPLICATION —其中任何一个缓存中的任何更新都会自动复制到其他缓存(下图中显示为蓝色虚线)
远程缓存服务器
解决上述问题的另一种方法是使用远程缓存服务器(如下所示)。

然而,这种方法的最大缺点是增加了响应时间——这是由于从远程缓存服务器获取数据时的网络延迟(与内存缓存相比)
缓存自定义
到目前为止,我们看到的缓存示例是向应用程序添加基本缓存所需的唯一代码。
然而,现实世界的场景可能不是那么简单,可能需要进行一些定制。在本节中,我们将看到几个这样的例子
缓存密钥
我们知道缓存是密钥、值对的存储。
示例1:默认缓存键–具有单参数的方法
最简单的缓存键是当方法只有一个参数,并且该参数成为缓存键时。在下面的示例中, Long customerId 是缓存键

示例2:默认缓存键–具有多个参数的方法
在下面的示例中,缓存键是所有三个参数的SimpleKey– countryId 、 regionId 、 personId 。

示例3:自定义缓存密钥
在下面的示例中,我们将此人的 emailAddress 指定为缓存的密钥

示例4:使用 KeyGenerator 的自定义缓存密钥
让我们看看下面的示例–如果要缓存当前登录用户的所有角色,该怎么办。

该方法中没有提供任何参数,该方法在内部获取当前登录用户并返回其角色。
为了实现这个需求,我们需要创建一个如下所示的自定义密钥生成器

然后我们可以在我们的方法中使用这个键生成器,如下所示。

条件缓存
在某些用例中,我们只希望在满足某些条件的情况下缓存结果
示例1(支持 java.util.Optional –仅当存在时才缓存)
仅当结果中存在 person 对象时,才缓存 person 对象。
@Cacheable( value = "persons", unless = "#result?.id") public Optional<Person> getPerson(Long personId)
示例2(如果需要,by-pass缓存)
@Cacheable(value = "persons", condition="#fetchFromCache") public Optional<Person> getPerson(long personId, boolean fetchFromCache)
仅当方法参数“ fetchFromCache ”为true时,才从缓存中获取人员。通过这种方式,方法的调用方有时可以决定绕过缓存并直接从数据库获取值。
示例3(基于对象属性的条件计算)
仅当价格低于500且产品有库存时,才缓存产品。
@Cacheable( value="products", condition="#product.price<500", unless="#result.outOfStock") public Product findProduct(Product product)
@CachePut
我们已经看到 @Cacheable 用于将项目放入缓存。
但是,如果该对象被更新,并且我们想要更新缓存,该怎么办?
我们已经在前面的一节中看到,不更新缓存post任何更新操作都可能导致从缓存返回错误的结果。
@CachePut(key = "#person.id") public Person update(Person person)
但是如果 @Cacheable 和 @CachePut 都将一个项目放入缓存,它们之间有什么区别?
主要区别在于实际的方法执行
@Cacheable @CachePut
缓存失效
缓存失效与将对象放入缓存一样重要。
当我们想要从缓存中删除一个或多个对象时,有很多场景。让我们看一些例子。
例1
假设我们有一个用于批量导入个人记录的API。
我们希望在调用此方法之前,应该清除整个 person 缓存(因为大多数 person 记录可能会在导入时更新,而缓存可能会过时)。我们可以这样做如下
@CacheEvict( value = "persons", allEntries = true, beforeInvocation = true) public void importPersons()
例2
我们有一个Delete Person API,我们希望它在删除时也能从缓存中删除 Person 记录。
@CacheEvict( value = "persons", key = "#person.emailAddress") public void deletePerson(Person person)
默认情况下 @CacheEvict 在方法调用后运行。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment Springboot intègre Jasypt pour implémenter le chiffrement des fichiers de configuration
Jun 01, 2023 am 08:55 AM
Comment Springboot intègre Jasypt pour implémenter le chiffrement des fichiers de configuration
Jun 01, 2023 am 08:55 AM
Introduction à Jasypt Jasypt est une bibliothèque Java qui permet à un développeur d'ajouter des fonctionnalités de chiffrement de base à son projet avec un minimum d'effort et ne nécessite pas une compréhension approfondie du fonctionnement du chiffrement. Haute sécurité pour le chiffrement unidirectionnel et bidirectionnel. technologie de cryptage basée sur des normes. Cryptez les mots de passe, le texte, les chiffres, les binaires... Convient pour l'intégration dans des applications basées sur Spring, API ouverte, pour une utilisation avec n'importe quel fournisseur JCE... Ajoutez la dépendance suivante : com.github.ulisesbocchiojasypt-spring-boot-starter2 1.1. Les avantages de Jasypt protègent la sécurité de notre système. Même en cas de fuite du code, la source de données peut être garantie.
 Comment SpringBoot intègre Redisson pour implémenter la file d'attente différée
May 30, 2023 pm 02:40 PM
Comment SpringBoot intègre Redisson pour implémenter la file d'attente différée
May 30, 2023 pm 02:40 PM
Scénario d'utilisation 1. La commande a été passée avec succès mais le paiement n'a pas été effectué dans les 30 minutes. Le paiement a expiré et la commande a été automatiquement annulée 2. La commande a été signée et aucune évaluation n'a été effectuée pendant 7 jours après la signature. Si la commande expire et n'est pas évaluée, le système donne par défaut une note positive. 3. La commande est passée avec succès. Si le commerçant ne reçoit pas la commande pendant 5 minutes, la commande est annulée. 4. Le délai de livraison expire et. un rappel par SMS est envoyé... Pour les scénarios avec des délais longs et de faibles performances en temps réel, nous pouvons utiliser la planification des tâches pour effectuer un traitement d'interrogation régulier. Par exemple : xxl-job Aujourd'hui, nous allons choisir
 Comment utiliser Redis pour implémenter des verrous distribués dans SpringBoot
Jun 03, 2023 am 08:16 AM
Comment utiliser Redis pour implémenter des verrous distribués dans SpringBoot
Jun 03, 2023 am 08:16 AM
1. Redis implémente le principe du verrouillage distribué et pourquoi les verrous distribués sont nécessaires. Avant de parler de verrous distribués, il est nécessaire d'expliquer pourquoi les verrous distribués sont nécessaires. Le contraire des verrous distribués est le verrouillage autonome. Lorsque nous écrivons des programmes multithreads, nous évitons les problèmes de données causés par l'utilisation d'une variable partagée en même temps. Nous utilisons généralement un verrou pour exclure mutuellement les variables partagées afin de garantir l'exactitude de celles-ci. les variables partagées. Son champ d’utilisation est dans le même processus. S’il existe plusieurs processus qui doivent exploiter une ressource partagée en même temps, comment peuvent-ils s’exclure mutuellement ? Les applications métier d'aujourd'hui sont généralement une architecture de microservices, ce qui signifie également qu'une application déploiera plusieurs processus si plusieurs processus doivent modifier la même ligne d'enregistrements dans MySQL, afin d'éviter les données sales causées par des opérations dans le désordre, les besoins de distribution. à introduire à ce moment-là. Le style est verrouillé. Vous voulez marquer des points
 Comment résoudre le problème selon lequel Springboot ne peut pas accéder au fichier après l'avoir lu dans un package jar
Jun 03, 2023 pm 04:38 PM
Comment résoudre le problème selon lequel Springboot ne peut pas accéder au fichier après l'avoir lu dans un package jar
Jun 03, 2023 pm 04:38 PM
Springboot lit le fichier, mais ne peut pas accéder au dernier développement après l'avoir empaqueté dans un package jar. Il existe une situation dans laquelle Springboot ne peut pas lire le fichier après l'avoir empaqueté dans un package jar. La raison en est qu'après l'empaquetage, le chemin virtuel du fichier. n’est pas valide et n’est accessible que via le flux Read. Le fichier se trouve sous les ressources publicvoidtest(){Listnames=newArrayList();InputStreamReaderread=null;try{ClassPathResourceresource=newClassPathResource("name.txt");Input
 Comment implémenter Springboot+Mybatis-plus sans utiliser d'instructions SQL pour ajouter plusieurs tables
Jun 02, 2023 am 11:07 AM
Comment implémenter Springboot+Mybatis-plus sans utiliser d'instructions SQL pour ajouter plusieurs tables
Jun 02, 2023 am 11:07 AM
Lorsque Springboot+Mybatis-plus n'utilise pas d'instructions SQL pour effectuer des opérations d'ajout de plusieurs tables, les problèmes que j'ai rencontrés sont décomposés en simulant la réflexion dans l'environnement de test : Créez un objet BrandDTO avec des paramètres pour simuler le passage des paramètres en arrière-plan. qu'il est extrêmement difficile d'effectuer des opérations multi-tables dans Mybatis-plus. Si vous n'utilisez pas d'outils tels que Mybatis-plus-join, vous pouvez uniquement configurer le fichier Mapper.xml correspondant et configurer le ResultMap malodorant et long, puis. écrivez l'instruction SQL correspondante Bien que cette méthode semble lourde, elle est très flexible et nous permet de
 Comment SpringBoot personnalise Redis pour implémenter la sérialisation du cache
Jun 03, 2023 am 11:32 AM
Comment SpringBoot personnalise Redis pour implémenter la sérialisation du cache
Jun 03, 2023 am 11:32 AM
1. Personnalisez RedisTemplate1.1, mécanisme de sérialisation par défaut RedisAPI. L'implémentation du cache Redis basée sur l'API utilise le modèle RedisTemplate pour les opérations de mise en cache des données. Ici, ouvrez la classe RedisTemplate et affichez les informations sur le code source de la classe. Déclarer la clé, diverses méthodes de sérialisation de la valeur, la valeur initiale est vide @NullableprivateRedisSe
 Comparaison et analyse des différences entre SpringBoot et SpringMVC
Dec 29, 2023 am 11:02 AM
Comparaison et analyse des différences entre SpringBoot et SpringMVC
Dec 29, 2023 am 11:02 AM
SpringBoot et SpringMVC sont tous deux des frameworks couramment utilisés dans le développement Java, mais il existe des différences évidentes entre eux. Cet article explorera les fonctionnalités et les utilisations de ces deux frameworks et comparera leurs différences. Tout d’abord, découvrons SpringBoot. SpringBoot a été développé par l'équipe Pivotal pour simplifier la création et le déploiement d'applications basées sur le framework Spring. Il fournit un moyen rapide et léger de créer des fichiers exécutables autonomes.
 Comment obtenir la valeur dans application.yml au Springboot
Jun 03, 2023 pm 06:43 PM
Comment obtenir la valeur dans application.yml au Springboot
Jun 03, 2023 pm 06:43 PM
Dans les projets, certaines informations de configuration sont souvent nécessaires. Ces informations peuvent avoir des configurations différentes dans l'environnement de test et dans l'environnement de production, et peuvent devoir être modifiées ultérieurement en fonction des conditions commerciales réelles. Nous ne pouvons pas coder en dur ces configurations dans le code. Il est préférable de les écrire dans le fichier de configuration. Par exemple, vous pouvez écrire ces informations dans le fichier application.yml. Alors, comment obtenir ou utiliser cette adresse dans le code ? Il existe 2 méthodes. Méthode 1 : Nous pouvons obtenir la valeur correspondant à la clé dans le fichier de configuration (application.yml) via le ${key} annoté avec @Value. Cette méthode convient aux situations où il y a relativement peu de microservices. Méthode 2 : En réalité. projets, Quand les affaires sont compliquées, la logique
