

Comment maîtriser les fichiers journaux SpringBoot

Fichier journal SpringBoot
1. À quoi servent les journaux
Le journal est une partie importante du programme Imaginez si le programme signale une erreur et ne vous permet pas d'ouvrir la console pour afficher le. log, vous pouvez alors trouver le rapport d'erreur. La raison ?
Pour nous, l'objectif principal des journaux est de dépanner et de localiser les problèmes. En plus de découvrir et de localiser les problèmes, nous pouvons également réaliser les fonctions suivantes grâce aux journaux :
Enregistrer les journaux de connexion des utilisateurs pour faciliter l'analyse pour savoir si les utilisateurs se connectent normalement ou pirater les utilisateurs de manière malveillante
Enregistrer les journaux de fonctionnement du système pour faciliter les données récupération Enregistrez le temps d'exécution du programme avec l'opérateur de positionnement
pour faciliter le programme d'optimisation afin de fournir un support de données à l'avenir
2 Comment utiliser les journaux
Le projet Spring Boot aura une sortie de journal par défaut. lorsqu'il est démarré, comme indiqué ci-dessous :

Grâce aux informations ci-dessus, nous pouvons trouver :
Spring Boot a un cadre de journalisation intégré
Par défaut, le journal de sortie n'est pas défini et imprimé par le développeur, alors comment le développeur peut-il le définir dans le programme ?
Le journal est imprimé sur la console par défaut, mais le journal de la console ne peut pas être enregistré. Comment enregistrer le journal de manière permanente ?
3. Impression personnalisée du journal
Étapes de mise en œuvre permettant aux développeurs de personnaliser l'impression du journal :
Obtenez le journal dans le programme
-
Utilisez la syntaxe appropriée de l'objet journal pour afficher le contenu à imprimer
3.1 Obtenir l'objet journal dans le programme
private static final Logger log = LoggerFactory.getLogger(UserController.class);
La fabrique de journaux doit transmettre le type de chaque classe, afin que nous puissions connaître la classe appartenant au journal et localiser le problème de manière plus pratique et intuitive
Remarque : l'objet logger appartient au package org.slf4j, ne faites pas de mauvaise erreur

3.2 Utilisez l'objet journal pour imprimer le journal
Il existe de nombreuses façons d'imprimer l'objet journal, nous pouvons utiliser la méthode info pour afficher le journal,
@Controller
@ResponseBody
public class UserController {
private static final Logger log = LoggerFactory.getLogger(UserController.class);
@RequestMapping("/sayhi")
public void sayHi() {
log.trace("trace");
log.debug("debug");
log.info("info");
log.warn("warn");
log.error("error");
}
}
4. Niveau de journalisation
4.1 À quoi sert le niveau de journalisation ?
Le niveau de journalisation peut vous aider à filtrer les informations importantes. Par exemple, si vous définissez le niveau de journalisation sur erreur, vous ne pouvez voir que le journal des erreurs du programme et ignorer les journaux de débogage ordinaires et les journaux d'activité. Cela fait gagner du temps aux développeurs lors du filtrage
Le niveau de journalisation peut contrôler si un programme doit imprimer des journaux dans différents environnements. Par exemple, dans l'environnement de développement, nous avons besoin d'informations très détaillées, tandis que dans l'environnement de production, une petite quantité d'informations. des informations seront générées afin de maintenir les performances et la sécurité des journaux, et ces besoins peuvent être satisfaits grâce aux niveaux de journalisation
4.2 Classification et utilisation des niveaux de journalisation
Les niveaux de journalisation sont divisés en :
trace : trace, c'est-à-dire un peu, le niveau le plus bas
debug : obligatoire Imprimer les informations clés pendant le débogage
info : informations d'impression ordinaires (niveau de journalisation par défaut)
warn : avertissement : n'affecte pas l'utilisation, mais des problèmes qui doivent attention
erreur : message d'erreur, niveau supérieur Informations du journal des erreurs
fatal : Fatal, un événement qui provoque la sortie du programme en raison d'une exception de code
L'ordre des niveaux de journalisation :
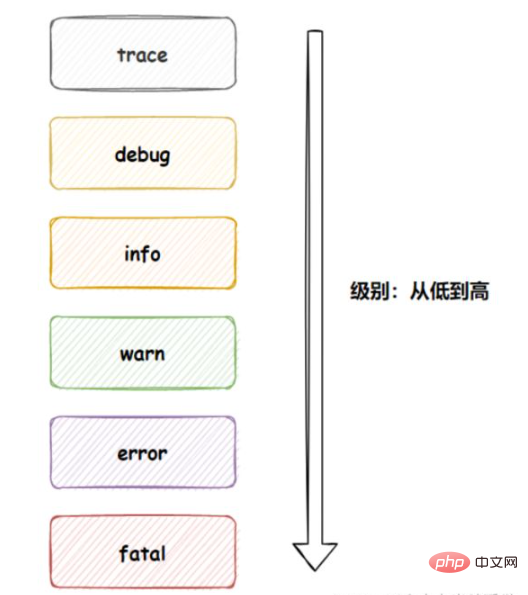
Plus le niveau est élevé, moins les informations sont reçues, comme défini. Si warn, vous ne pouvez recevoir que warn et les niveaux supérieurs
Paramètres du niveau de journalisation
logging:
level:
root: errorNiveau de sortie du journal par défaut
Effacer les paramètres du journal dans le fichier de configuration et observez le niveau de journalisation affiché par la console
Obtenez la conclusion, le niveau de sortie du journal par défaut est info
Lorsqu'il existe des paramètres de niveau de journalisation local et de niveau de journalisation global, puis lors de l'accès au journal local, le niveau de journalisation local est utilisé. C'est-à-dire que la priorité des journaux locaux est supérieure à la priorité des journaux globaux
5. Persistance des journaux
Les journaux ci-dessus sont affichés sur la console. Cependant, dans l'environnement de production, nous devons donc sauvegarder les journaux. que nous pouvons retracer après l'apparition de problèmes. Question, le processus de sauvegarde des journaux est appelé persistance
Si vous souhaitez conserver les journaux, il vous suffit de spécifier le répertoire de stockage des journaux dans le fichier de configuration ou de spécifier le fichier de sauvegarde des journaux. nom, et Spring Boot écrira les journaux de la console Allez dans le répertoire ou le fichier correspondant
Configurez le chemin de sauvegarde du fichier journal :
logging:
file:
path: D:\rizhi Le chemin enregistré, qui contient les paramètres pour les caractères d'échappement Nous pouvons utiliser ce /. comme séparateur. /来作为分割符。
如果坚持使用Windows下的分割符,我们需要使用
配置日志文件的文件名:
logging:
file:
name: D:/rizhi/logger/spring.log6. 更简单的日志输出–lombok
每次使用LoggerFactory.getLogger很繁琐,且每个类都添加一遍,也很麻烦。这里的lombok是一种更好的日志输出方式
添加lombok框架支持
使用@slf4j注解输出日志
6.1 添加 lombok 依赖
首先要安装一个插件:
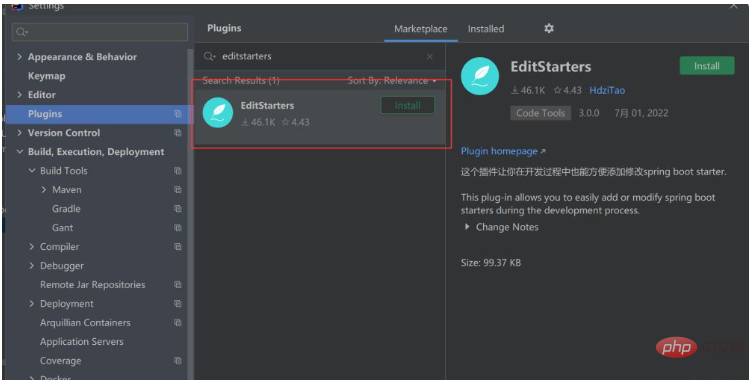
然后再pom.xml页面右键、
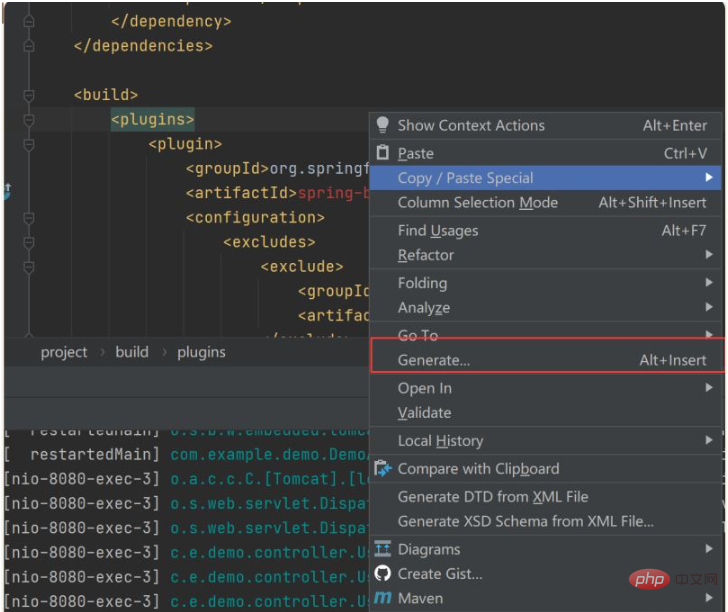
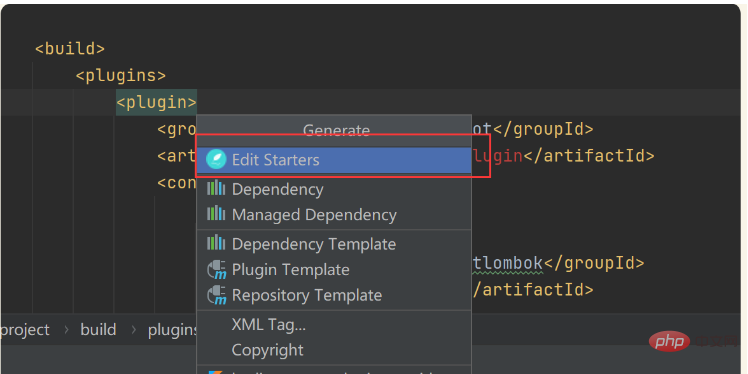
最后重新添加依赖就可以了
6.2 输出日志
使用@Slf4j注解,在程序中使用log对象即可输入日志并且只能使用log对象才能输出,这是lombok提供的对象名
6.3 lombok原理解释
lombok 能够打印⽇志的密码就在 target ⽬录⾥⾯,target 为项⽬最终执⾏的代码,查看 target ⽬录我们可以发现:
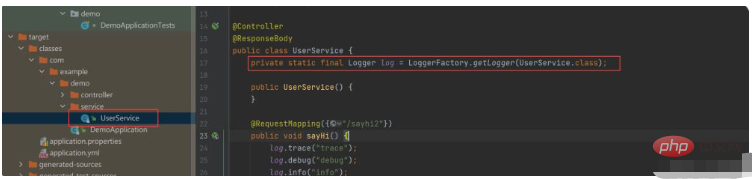
这里的@Slf4j注解变成了一个对象。
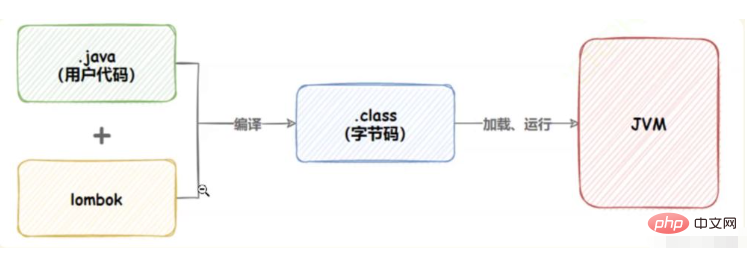
下面是java程序的运行原理:
6.4 lombok更多注解说明
基本注解
| 注解 | 作用 |
|---|---|
| @Getter | 自动添加get方法 |
| @Setter | 自动添加set方法 |
| @ToString | 自动添加toString方法 |
| @EqualsAndHashCode | 自动添加equals和hasCode方法 |
| @NoArgsConstructor | 自动添加无参构造方法 |
| @AllArgsConstructor | 自动添加全属性构造方法,顺序按照属性的定义顺序 |
| @NonNull | 属性不能为null |
| @RequiredArgsConstructor | 自动添加必须属性的构造方法,final + @NonNull的属性为需 |
组合注解:
| 注解 | 作用 |
|---|---|
| @Data | @Getter+@Setter+EqualsAndHashCode+@RequiredArgsConstructor+@NoArgsConstructor |
日志注解
| 注解 | 作用 |
|---|---|
| @Slf4j | 添加一个名为log的对象 |
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment Springboot intègre Jasypt pour implémenter le chiffrement des fichiers de configuration
Jun 01, 2023 am 08:55 AM
Comment Springboot intègre Jasypt pour implémenter le chiffrement des fichiers de configuration
Jun 01, 2023 am 08:55 AM
Introduction à Jasypt Jasypt est une bibliothèque Java qui permet à un développeur d'ajouter des fonctionnalités de chiffrement de base à son projet avec un minimum d'effort et ne nécessite pas une compréhension approfondie du fonctionnement du chiffrement. Haute sécurité pour le chiffrement unidirectionnel et bidirectionnel. technologie de cryptage basée sur des normes. Cryptez les mots de passe, le texte, les chiffres, les binaires... Convient pour l'intégration dans des applications basées sur Spring, API ouverte, pour une utilisation avec n'importe quel fournisseur JCE... Ajoutez la dépendance suivante : com.github.ulisesbocchiojasypt-spring-boot-starter2 1.1. Les avantages de Jasypt protègent la sécurité de notre système. Même en cas de fuite du code, la source de données peut être garantie.
 Comment SpringBoot intègre Redisson pour implémenter la file d'attente différée
May 30, 2023 pm 02:40 PM
Comment SpringBoot intègre Redisson pour implémenter la file d'attente différée
May 30, 2023 pm 02:40 PM
Scénario d'utilisation 1. La commande a été passée avec succès mais le paiement n'a pas été effectué dans les 30 minutes. Le paiement a expiré et la commande a été automatiquement annulée 2. La commande a été signée et aucune évaluation n'a été effectuée pendant 7 jours après la signature. Si la commande expire et n'est pas évaluée, le système donne par défaut une note positive. 3. La commande est passée avec succès. Si le commerçant ne reçoit pas la commande pendant 5 minutes, la commande est annulée. 4. Le délai de livraison expire et. un rappel par SMS est envoyé... Pour les scénarios avec des délais longs et de faibles performances en temps réel, nous pouvons utiliser la planification des tâches pour effectuer un traitement d'interrogation régulier. Par exemple : xxl-job Aujourd'hui, nous allons choisir
 Comment utiliser Redis pour implémenter des verrous distribués dans SpringBoot
Jun 03, 2023 am 08:16 AM
Comment utiliser Redis pour implémenter des verrous distribués dans SpringBoot
Jun 03, 2023 am 08:16 AM
1. Redis implémente le principe du verrouillage distribué et pourquoi les verrous distribués sont nécessaires. Avant de parler de verrous distribués, il est nécessaire d'expliquer pourquoi les verrous distribués sont nécessaires. Le contraire des verrous distribués est le verrouillage autonome. Lorsque nous écrivons des programmes multithreads, nous évitons les problèmes de données causés par l'utilisation d'une variable partagée en même temps. Nous utilisons généralement un verrou pour exclure mutuellement les variables partagées afin de garantir l'exactitude de celles-ci. les variables partagées. Son champ d’utilisation est dans le même processus. S’il existe plusieurs processus qui doivent exploiter une ressource partagée en même temps, comment peuvent-ils s’exclure mutuellement ? Les applications métier d'aujourd'hui sont généralement une architecture de microservices, ce qui signifie également qu'une application déploiera plusieurs processus si plusieurs processus doivent modifier la même ligne d'enregistrements dans MySQL, afin d'éviter les données sales causées par des opérations dans le désordre, les besoins de distribution. à introduire à ce moment-là. Le style est verrouillé. Vous voulez marquer des points
 Comment résoudre le problème selon lequel Springboot ne peut pas accéder au fichier après l'avoir lu dans un package jar
Jun 03, 2023 pm 04:38 PM
Comment résoudre le problème selon lequel Springboot ne peut pas accéder au fichier après l'avoir lu dans un package jar
Jun 03, 2023 pm 04:38 PM
Springboot lit le fichier, mais ne peut pas accéder au dernier développement après l'avoir empaqueté dans un package jar. Il existe une situation dans laquelle Springboot ne peut pas lire le fichier après l'avoir empaqueté dans un package jar. La raison en est qu'après l'empaquetage, le chemin virtuel du fichier. n’est pas valide et n’est accessible que via le flux Read. Le fichier se trouve sous les ressources publicvoidtest(){Listnames=newArrayList();InputStreamReaderread=null;try{ClassPathResourceresource=newClassPathResource("name.txt");Input
 Comparaison et analyse des différences entre SpringBoot et SpringMVC
Dec 29, 2023 am 11:02 AM
Comparaison et analyse des différences entre SpringBoot et SpringMVC
Dec 29, 2023 am 11:02 AM
SpringBoot et SpringMVC sont tous deux des frameworks couramment utilisés dans le développement Java, mais il existe des différences évidentes entre eux. Cet article explorera les fonctionnalités et les utilisations de ces deux frameworks et comparera leurs différences. Tout d’abord, découvrons SpringBoot. SpringBoot a été développé par l'équipe Pivotal pour simplifier la création et le déploiement d'applications basées sur le framework Spring. Il fournit un moyen rapide et léger de créer des fichiers exécutables autonomes.
 Comment implémenter Springboot+Mybatis-plus sans utiliser d'instructions SQL pour ajouter plusieurs tables
Jun 02, 2023 am 11:07 AM
Comment implémenter Springboot+Mybatis-plus sans utiliser d'instructions SQL pour ajouter plusieurs tables
Jun 02, 2023 am 11:07 AM
Lorsque Springboot+Mybatis-plus n'utilise pas d'instructions SQL pour effectuer des opérations d'ajout de plusieurs tables, les problèmes que j'ai rencontrés sont décomposés en simulant la réflexion dans l'environnement de test : Créez un objet BrandDTO avec des paramètres pour simuler le passage des paramètres en arrière-plan. qu'il est extrêmement difficile d'effectuer des opérations multi-tables dans Mybatis-plus. Si vous n'utilisez pas d'outils tels que Mybatis-plus-join, vous pouvez uniquement configurer le fichier Mapper.xml correspondant et configurer le ResultMap malodorant et long, puis. écrivez l'instruction SQL correspondante Bien que cette méthode semble lourde, elle est très flexible et nous permet de
 Comment SpringBoot personnalise Redis pour implémenter la sérialisation du cache
Jun 03, 2023 am 11:32 AM
Comment SpringBoot personnalise Redis pour implémenter la sérialisation du cache
Jun 03, 2023 am 11:32 AM
1. Personnalisez RedisTemplate1.1, mécanisme de sérialisation par défaut RedisAPI. L'implémentation du cache Redis basée sur l'API utilise le modèle RedisTemplate pour les opérations de mise en cache des données. Ici, ouvrez la classe RedisTemplate et affichez les informations sur le code source de la classe. Déclarer la clé, diverses méthodes de sérialisation de la valeur, la valeur initiale est vide @NullableprivateRedisSe
 Comment obtenir la valeur dans application.yml au Springboot
Jun 03, 2023 pm 06:43 PM
Comment obtenir la valeur dans application.yml au Springboot
Jun 03, 2023 pm 06:43 PM
Dans les projets, certaines informations de configuration sont souvent nécessaires. Ces informations peuvent avoir des configurations différentes dans l'environnement de test et dans l'environnement de production, et peuvent devoir être modifiées ultérieurement en fonction des conditions commerciales réelles. Nous ne pouvons pas coder en dur ces configurations dans le code. Il est préférable de les écrire dans le fichier de configuration. Par exemple, vous pouvez écrire ces informations dans le fichier application.yml. Alors, comment obtenir ou utiliser cette adresse dans le code ? Il existe 2 méthodes. Méthode 1 : Nous pouvons obtenir la valeur correspondant à la clé dans le fichier de configuration (application.yml) via le ${key} annoté avec @Value. Cette méthode convient aux situations où il y a relativement peu de microservices. Méthode 2 : En réalité. projets, Quand les affaires sont compliquées, la logique
