

En effectuant une ingénierie de fonctionnalités artisanale sur des données brutes, nous pouvons porter la précision et les performances des modèles à de nouveaux niveaux, ouvrant la voie à des prédictions plus précises et à des décisions commerciales plus intelligentes. Les modèles peuvent être optimisés et améliorés comme jamais auparavant.

Les données brutes sont comme un puzzle sans image - mais grâce à l'ingénierie des fonctionnalités, nous pouvons assembler les pièces. Même si disposer de grandes quantités de données constitue en effet un trésor pour les institutions financières qui cherchent à créer des modèles d'apprentissage automatique, elles le sont également. Il est important de reconnaître que toutes les données ne sont pas informatives. De plus, les fonctionnalités manuelles sont conçues manuellement, et les raisons de chaque opération peuvent être expliquées, ce qui apporte également de l'interprétabilité.
L'ingénierie des fonctionnalités ne consiste pas seulement à sélectionner les meilleures fonctionnalités. Cela implique également de réduire le bruit et la redondance des données pour améliorer la capacité de généralisation du modèle. Ceci est crucial car les modèles doivent fonctionner correctement sur des données invisibles pour être vraiment utiles.
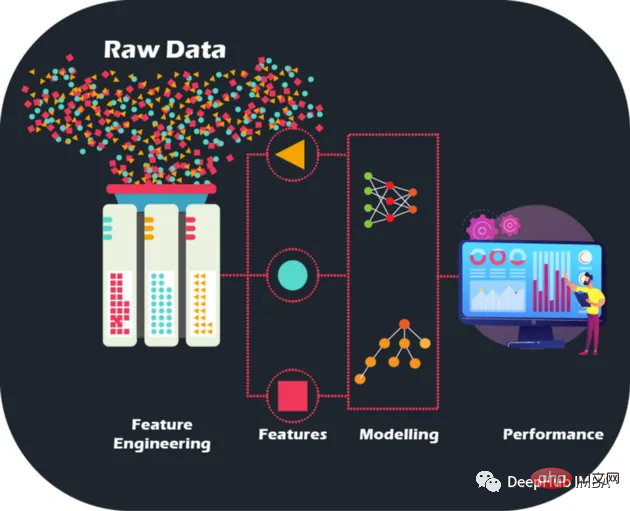
L'ensemble de données décrit dans cet article a été anonymisé et masqué pour maintenir la confidentialité des données clients. Les fonctionnalités peuvent être classées comme suit :
D_* = 拖欠变量 S_* = 支出变量 P_* = 支付变量 B_* = 平衡变量 R_* = 风险变量
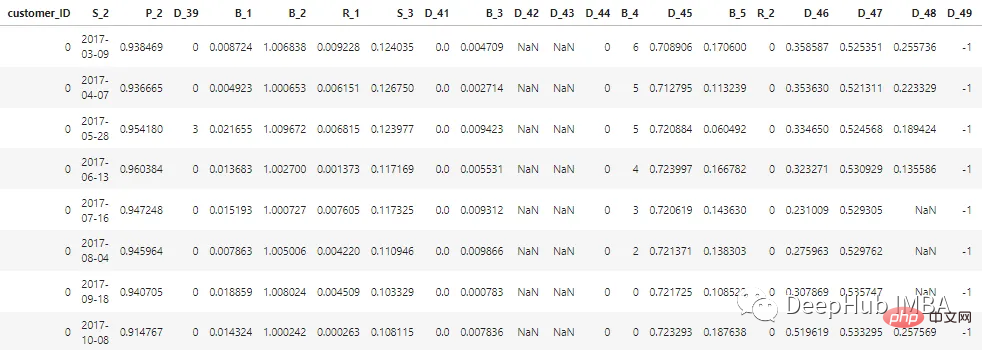
Il existe un total de 100 fonctionnalités entières et 100 fonctionnalités à virgule flottante représentant le statut du client au cours des 12 derniers mois. Cet ensemble de données contient des informations sur les rapports clients allant de 1 à 13. Il peut y avoir un intervalle de 30 à 180 jours entre chacun des relevés de carte de crédit d'un client (c'est-à-dire que le relevé de carte de crédit d'un client peut être manquant). Chaque client est représenté par un identifiant client. Les exemples de données des 5 premiers éléments de clients avec customer_ID=0 sont les suivants :
Parmi les 7 millions de customer_ID, 98 % des étiquettes sont "0" (bons clients, pas de défaut), et 2 % des les étiquettes sont "1" » (mauvais client, par défaut).
L'ensemble de données est énorme, nous utilisons donc cudf pour accélérer le traitement, si vous n'avez pas installé cudf, c'est la même chose avec les pandas
# LOAD LIBRARIES
import pandas as pd, numpy as np # CPU libraries
import cudf # GPU libraries
import matplotlib.pyplot as plt, gc, os
df = cudf.read_parquet('./data.parquet')Il existe des centaines d'idées pour générer des fonctionnalités mais nous créons également ; Je suis sûr que ces fonctionnalités contribuent à améliorer les performances du modèle, et l'image ci-dessous montre certaines des méthodes de base utilisées dans l'ingénierie des fonctionnalités :
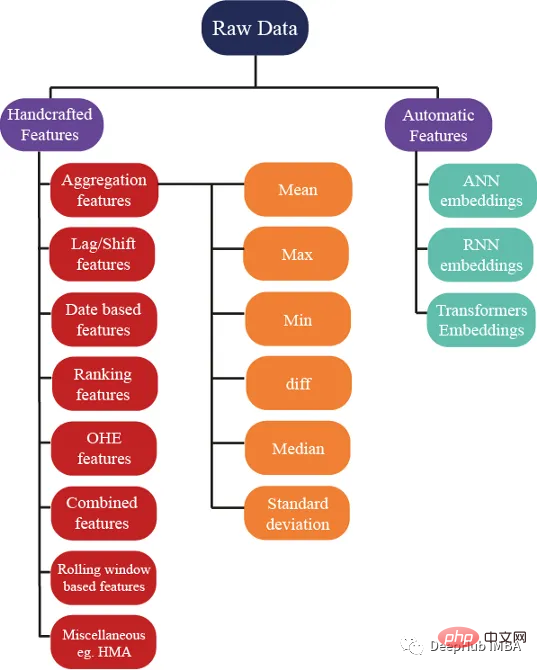
L'agrégation est le secret pour comprendre des données complexes. En calculant des statistiques récapitulatives pour les variables de regroupement catégorielles telles que customer_ID (C_ID) ou la catégorie de produit, ou des agrégations de variables numériques, nous pouvons découvrir des modèles et des tendances invisibles. Grâce à des statistiques récapitulatives telles que la moyenne, le maximum, le minimum, l'écart type et la médiane, nous pouvons créer des modèles prédictifs plus précis et extraire des informations significatives à partir des données client, des données de transaction ou de toute autre donnée numérique.
Ces attributs statistiques peuvent être calculés pour chaque client
cat_features = ["B_1","B_2","D_1","D_2","D_10","P_21","D_126","D_3","D_42","R_66","R_68"]
num_features = [col for col in all_cols if col not in cat_features] #all features accept cateforical features.
test_num_agg = df.groupby("customer_ID")[num_features].agg(['mean', 'std', 'min', 'max', 'last','median']) #grouping by customerID
test_num_agg.columns = ['_'.join(x) for x in test_num_agg.columns]Moyenne : la valeur moyenne d'une variable numérique qui peut donner une idée générale de la tendance centrale des données. La moyenne capture :
Le solde bancaire moyen dont dispose un client.
Écart type (Std) : mesure de la distribution des données autour de la moyenne, qui peut donner un aperçu du degré de variabilité des données. Une grande variabilité des soldes indique que les clients dépensent.
Les valeurs minimales et maximales capturent la richesse d'un client et capturent également des informations sur les dépenses et les risques d'un client.
Médiane : Lorsque les données sont très asymétriques, utiliser la moyenne n'est pas une meilleure idée, donc la médiane peut être utilisée (le milieu des valeurs peut être utilisé.
Les dernières valeurs sont probablement les plus importantes fonctionnalités car elles contiennent des informations sur le dernier relevé de crédit connu émis au client, qui indique l'état actuel du compte du client
Il n'est pas judicieux d'utiliser les propriétés statistiques ci-dessus pour les variables catégorielles car le calcul du minimum est effectué. , le maximum ou l'écart type ne nous donnent aucune information utile. Alors, que devons-nous faire ? Les caractéristiques peuvent être calculées à l'aide de fonctionnalités telles que le nombre et les quantités uniques, et la dernière valeur peut également être utilisée
cat_features = ["B_1","B_2","D_1","D_2","D_10","P_21","D_126","D_3","D_42","R_66","R_68"]
test_cat_agg = df.groupby("customer_ID")[cat_features].agg(['count', 'last', 'nunique'])
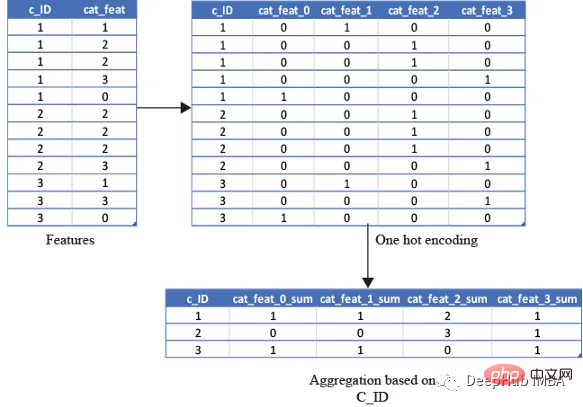
test_cat_agg.columns = ['_'.join(x) for x in test_cat_agg.columns]Mais ces informations ne le seront pas. capturer le client est classé dans une catégorie spécifique. Nous faisons donc cela en codant à chaud la variable, puis en agrégeant les variables comme la moyenne, la somme et enfin
la moyenne capturera le nombre total de fois où le client entre dans cette catégorie/la somme. sera simplement le nombre total de fois où le client entre dans cette catégorie
在预测客户行为方面,基于排名的特征是非常重要的。通过根据收入或支出等特定属性对客户进行排名,我们可以深入了解他们的财务习惯并更好地管理风险。
使用 cudf 的 rank 函数,我们可以轻松计算这些特征并使用它们来为预测提供信息。例如,可以根据客户的消费模式、债务收入比或信用评分对客户进行排名。然后这些特征可用于预测违约或识别有可能拖欠付款的客户。
基于排名的特征还可用于识别高价值客户、目标营销工作和优化贷款优惠。例如,可以根据客户接受贷款提议的可能性对客户进行排名,然后将排名最高的客户作为目标。
df[feat+'_rank']=df[feat].rank(pct=True, method='min')
PCT用于是否做百分位排名。客户的排名也可以基于分类特征来计算。
df[feat+'_rank']=df.groupby([cat_feat]).rank(pct=True, method='min')
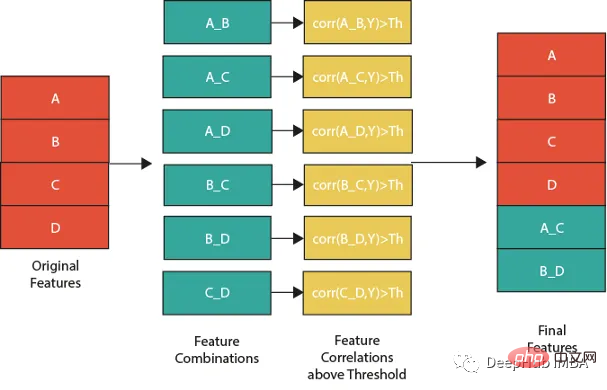
特征组合的一种流行方法是线性或非线性组合。这包括采用两个或多个现有特征,将它们组合在一起创建一个新的复合特征。然后使用这个复合特征来识别单独查看单个特征时可能不可见的模式、趋势和相关性。
例如,假设我们正在分析客户消费习惯的数据集。可以从个人特征开始,比如年龄、收入和地点。但是通过以线性或非线性的方式组合这些特性,可以创建新的复合特性,使我们能够更多地了解客户。可以结合收入和位置来创建一个复合特征,该特征告诉我们某一地区客户的平均支出。
但是并不是所有的特征组合都有用。关键是要确定哪些组合与试图解决的问题最相关,这需要对数据和问题领域有深刻的理解,并仔细分析创建的复合特征和试图预测的目标变量之间的相关性。
下图展示了一个组合特征并将信息用于模型的过程。作为筛选条件,这里只选择那些与目标相关性大于最大值 0.9 的特征。
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features] for feat1 in features: for feat2 in features: th=max(np.corr(feat1,Y)[0],np.corr(feat1,Y)[0]) #calculate threshold feat3=df[feat1]-df[feat2] #difference feature corr3=np.corr(feat3,Y)[0] if(corr3>max(th,0.9)): #if correlation greater than max(th,0.9) we add it as feature df[feat1+'_'+feat2]=feat3
在数据分析方面,基于时间的特征非常重要。通过根据时间属性(例如月份或星期几)对数据进行分组,可以创建强大的特征。这些特征的范围可以从简单的平均值(如收入和支出)到更复杂的属性(如信用评分随时间的变化)。
借助基于时间的特征,还可以识别在孤立地查看数据时可能看不到的模式和趋势。下图演示了如何使用基于时间的特征来创建有用的复合属性。
首先,计算一个月内的值的平均值(可以使用该月的某天或该月的某周等),将获得的DF与原始数据合并,并取各个特征之间的差。
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features]
month_Agg=df.groupby([month])[features].agg('mean')#grouping based on month feature
month_Agg.columns = ['_month_'.join(x) for x in month_Agg.columns]
month_Agg.reset_index(inplace=True)
df=df.groupby(month_Agg,notallow='month')
for feat in features: #create composite features b taking difference
df[feat+'_'+feat+'_month_mean']=df[feat]-df[feat+'_month_mean']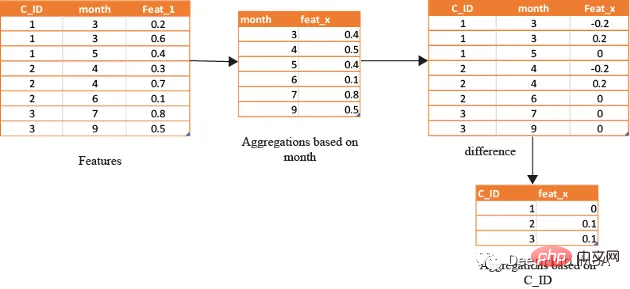
还可以通过使用时间作为分组变量来创建基于排名的特征,如下所示
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features] month_Agg=df.groupby([month])[features].rank(pct=True) #grouping based on month feature month_Agg.columns = ['_month_'.join(x) for x in month_Agg.columns] month_Agg.reset_index(inplace=True) df=pd.concat([df,month_Agg],axis=1) #concat to original dataframe
滞后特征是有效预测金融数据的重要工具。这些特征包括计算时间序列中当前值与之前值之间的差值。通过将滞后特征纳入分析,可以更好地理解数据中的模式和趋势,并做出更准确的预测。
如果滞后特征显示客户连续几个月按时支付信用卡账单,可能会预测他们将来不太可能违约。相反,如果延迟特征显示客户一直延迟或错过付款,可能会预测他们更有可能违约。
# difference function calculate the lag difference for numerical features
#between last value and shift last value.
def difference(groups,num_features,shift):
data=(groups[num_features].nth(-1)-groups[num_features].nth(-1*shift)).rename(columns={f: f"{f}_diff{shift}" for f in num_features})
return data
#calculate diff features for last -2nd last, last -3rd last, last- 4th last
def get_difference(data,num_features):
print("diff features...")
groups=data.groupby('customer_ID')
df1=difference(groups,num_features,2).fillna(0)
df2=difference(groups,num_features,3).fillna(0)
df3=difference(groups,num_features,4).fillna(0)
df1=pd.concat([df1,df2,df3],axis=1)
df1.reset_index(inplace=True)
df1.sort_values(by='customer_ID')
del df2,df3
gc.collect()
return df1train_diff = get_difference(df, num_features)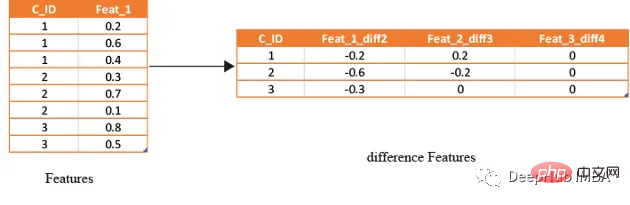
这些特征只是取最后3(4,5,…x)值的平均值,这取决于数据,因为基于时间的最新值携带了关于客户最新状态的信息。
xth=3 #define the window size
df["cumulative"]=df.groupby('customer_ID').sort_values(by=['time'],ascending=False).cumcount()
last_info=df[df["cumulative"]<=xth]
last_info = last_info.groupby("customer_ID")[num_features].agg(['mean', 'std', 'min', 'max', 'last','median']) #grouping by customerID
last_info.columns = ['_'.join(x) for x in last_info.columns]上面的方法已经创建了足够多的特征来构建一个很棒的模型。但是根据数据的性质,还可以创建更多的特征。例如:可以创建像null计数这样的特征,它可以计算客户当前的总null值,从而帮助捕获基于树的算法无法理解的特征分布。
def calc_nan(df,features):
print("calculating nan_info...")
df_nan = (df[features].mul(0) + 1).fillna(0) #marke non_null values as 1 and null as zero
df_nan['customer_ID'] = df['customer_ID']
nan_sum = df_nan.groupby("customer_ID").sum().sum(axis=1) #total unknown values for a customer
nan_last = df_nan.groupby("customer_ID").last().sum(axis=1)#how many last values that are not known
del df_nan
gc.collect()
return nan_sum,nan_last这里可以不使用平均值,而是使用修正的平均值,如基于时间的加权平均值或 HMA(hull moving average)。
Dans cet article, nous avons présenté certaines des stratégies de fonctionnalités artisanales les plus couramment utilisées dans le monde réel pour prédire le risque de défaut. Mais il existe toujours des façons nouvelles et innovantes de concevoir des fonctionnalités, et la méthode de définition manuelle des fonctionnalités prend du temps et est laborieuse. Nous présenterons donc comment utiliser les outils de génération automatique de fonctionnalités dans un article ultérieur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 ppt en mot
ppt en mot
 Introduction aux types d'interfaces
Introduction aux types d'interfaces
 Commandes communes OGG
Commandes communes OGG
 Le rôle de l'outil formatfactory
Le rôle de l'outil formatfactory
 La différence entre les cours Python et les cours C+
La différence entre les cours Python et les cours C+
 Logiciel antivirus
Logiciel antivirus
 Solution aux propriétés du dossier Win7 ne partageant pas la page à onglet
Solution aux propriétés du dossier Win7 ne partageant pas la page à onglet
 Utilisation du nœud d'arbre
Utilisation du nœud d'arbre
 Comment définir les numéros de page dans Word
Comment définir les numéros de page dans Word








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



