
 Opération et maintenance
Nginx
Comment implémenter la configuration de séparation dynamique et statique Nginx
Opération et maintenance
Nginx
Comment implémenter la configuration de séparation dynamique et statique Nginx
Comment implémenter la configuration de séparation dynamique et statique Nginx

1. Présentation
1.1 La différence entre les pages dynamiques et les pages statiques
Ressources statiques : lorsque les utilisateurs accèdent à cette ressource plusieurs fois, le code source de la ressource ne changera jamais.
Ressource dynamique : lorsqu'un utilisateur accède à cette ressource plusieurs fois, le code source de la ressource peut recevoir des modifications.
1.2 Qu'est-ce que la séparation dynamique et statique ?
La séparation dynamique et statique permet aux pages Web dynamiques des sites Web dynamiques de distinguer les ressources constantes des ressources qui changent fréquemment selon certaines règles. peut mettre en cache les ressources statiques en fonction de leurs caractéristiques. C'est l'idée centrale du traitement statique des sites Web
Le résumé simple de la séparation dynamique et statique est : la séparation des fichiers dynamiques et des fichiers statiques.
Pseudo-statique : si le site Web souhaite être recherché par les moteurs de recherche, la technologie statique de page dynamique freemarker et d'autres technologies de moteur de modèles
1.3 Pourquoi utiliser la séparation dynamique et statique
Dans notre développement de logiciels, certains les requêtes sont celles qui nécessitent un traitement en arrière-plan (tels que : .jsp, .do, etc.), et certaines requêtes n'ont pas besoin de passer par un traitement en arrière-plan (tels que : fichiers css, html, jpg, js, etc.). les fichiers qui n'ont pas besoin de passer par un traitement en arrière-plan sont appelés fichiers statiques, sinon fichiers dynamiques. Par conséquent, notre traitement en arrière-plan ignore les fichiers statiques. Certains diront que si j’ignore les fichiers statiques en arrière-plan, ce sera fini. Bien sûr, cela est possible, mais le nombre de demandes en arrière-plan va considérablement augmenter. Lorsque nous avons des exigences en matière de vitesse de réponse des ressources, nous devons utiliser cette stratégie de séparation dynamique et statique pour résoudre le problème.
La séparation des ressources statiques et dynamiques déploie les ressources statiques du site Web (HTML, JavaScript, CSS, img et autres fichiers) séparément des applications en arrière-plan, améliorant ainsi la vitesse d'accès des utilisateurs au code statique et réduisant l'accès aux applications en arrière-plan. Ici, nous mettons les ressources statiques dans nginx et transmettons les ressources dynamiques au serveur Tomcat.
Par conséquent, pour transférer les ressources dynamiques vers le serveur Tomcat, nous utilisons le proxy inverse mentionné précédemment.
2. Nginx réalise la séparation dynamique et statique
2.1 Analyse de l'architecture
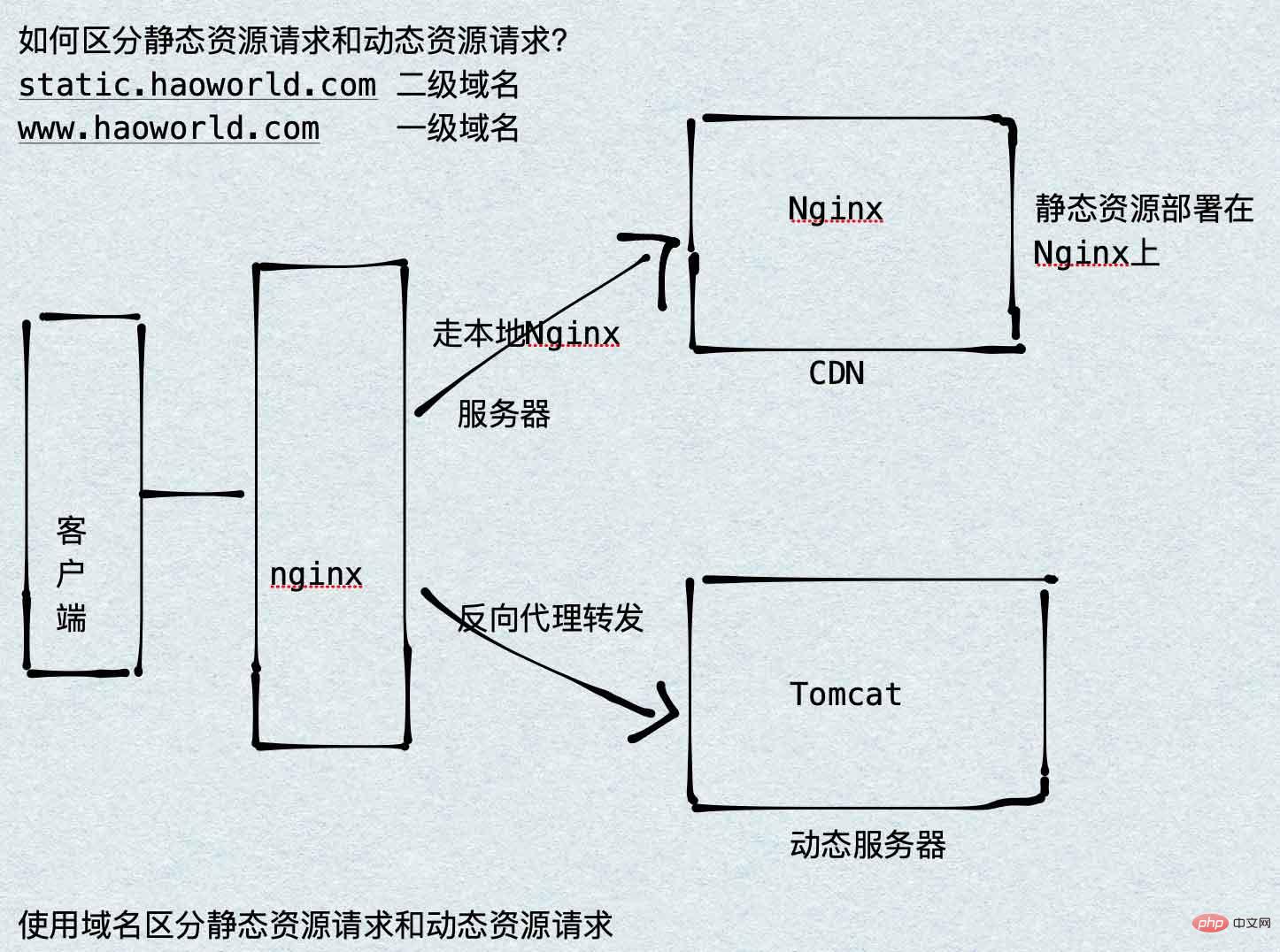
2.2 Configuration
Le principe de la séparation dynamique et statique est très simple, il suffit de faire correspondre l'URL de la requête via l'emplacement, dans /Users/ Hao/Desktop/ Créez /static/imgs sous Test (n'importe quel répertoire) et configurez-le comme suit :
###静态资源访问
server {
listen 80;
server_name static.jb51.com;
location /static/imgs {
root /Users/Hao/Desktop/Test;
index index.html index.htm;
}
}
###动态资源访问
server {
listen 80;
server_name www.jb51.com;
location / {
proxy_pass http://127.0.0.1:8080;
index index.html index.htm;
}
}Un autre type de configuration de ressources par accès
server {
listen 80;
server_name jb51.net;
access_log /data/nginx/logs/jb51.net-access.log main;
error_log /data/nginx/logs/jb51.net-error.log;
#动态访问请求转给tomcat应用处理
location ~ .(jsp|page|do)?$ { #以这些文件结尾的
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_pass http://tomcat地址;
}
#设定访问静态文件直接读取不经过tomcat
location ~ .*.(htm|html|gif|jpg|jpeg|png|bmp|swf|ioc|rar|zip|txt|flv|mid|doc|ppt|pdf|xls|mp3|wma)$ { #以这些文件结尾的
expires 30d;
root /data/web/html ;
}
}3. séparation :
Séparation dynamique et statique des ressources dynamiques et des ressources statiques Séparé et ne sera pas déployé sur le même serveur.
Séparation du front et du back : modèle d'architecture de site Web, le développement de microservices est basé sur
SOAet est orienté vers le développement de serveur, et le backend et le front-end adoptent tous deux la méthode d'interface d'appel. Divisez un projet en un contrôleWeb(front-end) et une interface (back-end), et enfin utilisez la technologie d'appel à distance rpc. La couche de vue et la couche de logique métier sont divisées et la technologie d'appel à distanceRPCest utilisée au milieuSOA面向于服务器开发,后台和前端都采用调用接口方式。将一个项目拆分成一个控制Web(前端)和接口(后端),最终使用rpc远程调用技术。视图层和业务逻辑层拆分,中间采用RPC远程调用技术
四、一些问题
为什么互联网公司项目中,静态资源
url- Pourquoi les ressources statiques sont-elles
- Solution : Ajouter une spécification d'horodatage t = projet en ligne
- 304 Principe du code d'état du cache local :
- Le cache d'image du navigateur par défaut est de 7 jours.
- Lors du premier téléchargement des ressources, le client enregistre l'heure de la ressource modifiée
- Lors du deuxième téléchargement des ressources, le serveur détermine si l'heure de la dernière modification du client doit renvoyer 200 ou 304
- Lors du deuxième téléchargement des ressources, le serveur détermine si le fichier de ressources actuel et l'heure de dernière modification du client doivent renvoyer 200 ou 304. Le client télécharge les ressources pour la deuxième fois. Dernière heure de modification 2018/6/28 11:07 : 23h
- 4. Quelques questions
url utilisé dans les projets d'entreprises Internet ? Un horodatage sera-t-il ajouté ultérieurement ? Sa fonction : contrôler la mise en cacheCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment autoriser l'accès au réseau externe au serveur Tomcat
Apr 21, 2024 am 07:22 AM
Comment autoriser l'accès au réseau externe au serveur Tomcat
Apr 21, 2024 am 07:22 AM
Pour permettre au serveur Tomcat d'accéder au réseau externe, vous devez : modifier le fichier de configuration Tomcat pour autoriser les connexions externes. Ajoutez une règle de pare-feu pour autoriser l'accès au port du serveur Tomcat. Créez un enregistrement DNS pointant le nom de domaine vers l'adresse IP publique du serveur Tomcat. Facultatif : utilisez un proxy inverse pour améliorer la sécurité et les performances. Facultatif : configurez HTTPS pour une sécurité accrue.
 Comment exécuter thinkphp
Apr 09, 2024 pm 05:39 PM
Comment exécuter thinkphp
Apr 09, 2024 pm 05:39 PM
Étapes pour exécuter ThinkPHP Framework localement : Téléchargez et décompressez ThinkPHP Framework dans un répertoire local. Créez un hôte virtuel (facultatif) pointant vers le répertoire racine ThinkPHP. Configurez les paramètres de connexion à la base de données. Démarrez le serveur Web. Initialisez l'application ThinkPHP. Accédez à l'URL de l'application ThinkPHP et exécutez-la.
 Bienvenue sur nginx !Comment le résoudre ?
Apr 17, 2024 am 05:12 AM
Bienvenue sur nginx !Comment le résoudre ?
Apr 17, 2024 am 05:12 AM
Pour résoudre l'erreur "Bienvenue sur nginx!", vous devez vérifier la configuration de l'hôte virtuel, activer l'hôte virtuel, recharger Nginx, si le fichier de configuration de l'hôte virtuel est introuvable, créer une page par défaut et recharger Nginx, puis le message d'erreur. disparaîtra et le site Web sera affiché normalement.
 Comment générer une URL à partir d'un fichier HTML
Apr 21, 2024 pm 12:57 PM
Comment générer une URL à partir d'un fichier HTML
Apr 21, 2024 pm 12:57 PM
La conversion d'un fichier HTML en URL nécessite un serveur Web, ce qui implique les étapes suivantes : Obtenir un serveur Web. Configurez un serveur Web. Téléchargez le fichier HTML. Créez un nom de domaine. Acheminez la demande.
 Comment déployer le projet nodejs sur le serveur
Apr 21, 2024 am 04:40 AM
Comment déployer le projet nodejs sur le serveur
Apr 21, 2024 am 04:40 AM
Étapes de déploiement de serveur pour un projet Node.js : Préparez l'environnement de déploiement : obtenez l'accès au serveur, installez Node.js, configurez un référentiel Git. Créez l'application : utilisez npm run build pour générer du code et des dépendances déployables. Téléchargez le code sur le serveur : via Git ou File Transfer Protocol. Installer les dépendances : connectez-vous en SSH au serveur et installez les dépendances de l'application à l'aide de npm install. Démarrez l'application : utilisez une commande telle que node index.js pour démarrer l'application ou utilisez un gestionnaire de processus tel que pm2. Configurer un proxy inverse (facultatif) : utilisez un proxy inverse tel que Nginx ou Apache pour acheminer le trafic vers votre application
 Quelles sont les instructions les plus courantes dans un fichier docker
Apr 07, 2024 pm 07:21 PM
Quelles sont les instructions les plus courantes dans un fichier docker
Apr 07, 2024 pm 07:21 PM
Les instructions les plus couramment utilisées dans Dockerfile sont : FROM : créer une nouvelle image ou dériver une nouvelle image RUN : exécuter des commandes (installer le logiciel, configurer le système) COPY : copier des fichiers locaux dans l'image ADD : similaire à COPY, il peut automatiquement décompresser tar ou obtenir des fichiers URL CMD : Spécifiez la commande au démarrage du conteneur EXPOSE : Déclarez le port d'écoute du conteneur (mais pas public) ENV : Définissez la variable d'environnement VOLUME : Montez le répertoire hôte ou le volume anonyme WORKDIR : Définissez le répertoire de travail dans le conteneur ENTRYPOINT : spécifiez ce qu'il faut exécuter lorsque le conteneur démarre. Fichier exécutable (similaire à CMD, mais ne peut pas être écrasé)
 Nodejs est-il accessible de l'extérieur ?
Apr 21, 2024 am 04:43 AM
Nodejs est-il accessible de l'extérieur ?
Apr 21, 2024 am 04:43 AM
Oui, Node.js est accessible de l’extérieur. Vous pouvez utiliser les méthodes suivantes : Utilisez Cloud Functions pour déployer la fonction et la rendre accessible au public. Utilisez le framework Express pour créer des itinéraires et définir des points de terminaison. Utilisez Nginx pour inverser les requêtes de proxy vers les applications Node.js. Utilisez des conteneurs Docker pour exécuter des applications Node.js et les exposer via le mappage de ports.
 Comment déployer et maintenir un site Web en utilisant PHP
May 03, 2024 am 08:54 AM
Comment déployer et maintenir un site Web en utilisant PHP
May 03, 2024 am 08:54 AM
Pour déployer et maintenir avec succès un site Web PHP, vous devez effectuer les étapes suivantes : Sélectionnez un serveur Web (tel qu'Apache ou Nginx) Installez PHP Créez une base de données et connectez PHP Téléchargez le code sur le serveur Configurez le nom de domaine et la maintenance du site Web de surveillance DNS les étapes comprennent la mise à jour de PHP et des serveurs Web, la sauvegarde du site Web, la surveillance des journaux d'erreurs et la mise à jour du contenu.
