

Comment SpringBoot intègre la classe d'outils de configuration Kafka

spring-kafka est basé sur l'intégration de la version java du client kafka et de spring. Il fournit KafkaTemplate, qui encapsule diverses méthodes pour une utilisation facile. Il encapsule le client kafka d'Apache et n'a pas besoin d'importer les dépendances du client
<!-- kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>. Configuration YML
kafka:
#bootstrap-servers: server1:9092,server2:9093 #kafka开发地址,
#生产者配置
producer:
# Kafka提供的序列化和反序列化类
key-serializer: org.apache.kafka.common.serialization.StringSerializer #序列化
value-serializer: org.apache.kafka.common.serialization.StringSerializer
retries: 1 # 消息发送重试次数
#acks = 0:设置成 表示 producer 完全不理睬 leader broker 端的处理结果。此时producer 发送消息后立即开启下 条消息的发送,根本不等待 leader broker 端返回结果
#acks= all 或者-1 :表示当发送消息时, leader broker 不仅会将消息写入本地日志,同时还会等待所有其他副本都成功写入它们各自的本地日志后,才发送响应结果给,消息安全但是吞吐量会比较低。
#acks = 1:默认的参数值。 producer 发送消息后 leader broker 仅将该消息写入本地日志,然后便发送响应结果给producer ,而无须等待其他副本写入该消息。折中方案,只要leader一直活着消息就不会丢失,同时也保证了吞吐量
acks: 1 #应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
batch-size: 16384 #批量大小
properties:
linger:
ms: 0 #提交延迟
buffer-memory: 33554432 # 生产端缓冲区大小
# 消费者配置
consumer:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 分组名称
group-id: web
enable-auto-commit: false
#提交offset延时(接收到消息后多久提交offset)
# auto-commit-interval: 1000ms
#当kafka中没有初始offset或offset超出范围时将自动重置offset
# earliest:重置为分区中最小的offset;
# latest:重置为分区中最新的offset(消费分区中新产生的数据);
# none:只要有一个分区不存在已提交的offset,就抛出异常;
auto-offset-reset: latest
properties:
#消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
session.timeout.ms: 15000
#消费请求超时时间
request.timeout.ms: 18000
#批量消费每次最多消费多少条消息
#每次拉取一条,一条条消费,当然是具体业务状况设置
max-poll-records: 1
# 指定心跳包发送频率,即间隔多长时间发送一次心跳包,优化该值的设置可以减少Rebalance操作,默认时间为3秒;
heartbeat-interval: 6000
# 发出请求时传递给服务器的 ID。用于服务器端日志记录 正常使用后解开注释,不然只有一个节点会报错
#client-id: mqtt
listener:
#消费端监听的topic不存在时,项目启动会报错(关掉)
missing-topics-fatal: false
#设置消费类型 批量消费 batch,单条消费:single
type: single
#指定容器的线程数,提高并发量
#concurrency: 3
#手动提交偏移量 manual达到一定数据后批量提交
#ack-mode: manual
ack-mode: MANUAL_IMMEDIATE #手動確認消息
# 认证
#properties:
#security:
#protocol: SASL_PLAINTEXT
#sasl:
#mechanism: SCRAM-SHA-256
#jaas:config: 'org.apache.kafka.common.security.scram.ScramLoginModule required username="username" password="password";'Classe d'outils simple pouvant répondre à une utilisation normale. Le sujet ne peut pas être modifié
@Component
@Slf4j
public class KafkaUtils<K, V> {
@Autowired
private KafkaTemplate kafkaTemplate;
@Value("${spring.kafka.bootstrap-servers}")
String[] servers;
/**
* 获取连接
* @return
*/
private Admin getAdmin() {
Properties properties = new Properties();
properties.put("bootstrap.servers", servers);
// 正式环境需要添加账号密码
return Admin.create(properties);
}
/**
* 增加topic
*
* @param name 主题名字
* @param partition 分区数量
* @param replica 副本数量
* @date 2022-06-23 chens
*/
public R addTopic(String name, Integer partition, Integer replica) {
Admin admin = getAdmin();
if (replica > servers.length) {
return R.error("副本数量不允许超过Broker数量");
}
try {
NewTopic topic = new NewTopic(name, partition, Short.parseShort(replica.toString()));
admin.createTopics(Collections.singleton(topic));
} finally {
admin.close();
}
return R.ok();
}
/**
* 删除主题
*
* @param names 主题名字集合
* @date 2022-06-23 chens
*/
public void deleteTopic(List<String> names) {
Admin admin = getAdmin();
try {
admin.deleteTopics(names);
} finally {
admin.close();
}
}
/**
* 查询所有主题
*
* @date 2022-06-24 chens
*/
public Set<String> queryTopic() {
Admin admin = getAdmin();
try {
ListTopicsResult topics = admin.listTopics();
Set<String> set = topics.names().get();
return set;
} catch (Exception e) {
log.error("查询主题错误!");
} finally {
admin.close();
}
return null;
}
// 向所有分区发送消息
public ListenableFuture<SendResult<K, V>> send(String topic, @Nullable V data) {
return kafkaTemplate.send(topic, data);
}
// 指定key发送消息,相同key保证消息在同一个分区
public ListenableFuture<SendResult<K, V>> send(String topic, K key, @Nullable V data) {
return kafkaTemplate.send(topic, key, data);
}
// 指定分区和key发送。
public ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, K key, @Nullable V data) {
return kafkaTemplate.send(topic, partition, key, data);
}
}Envoyer des messages en mode asynchrone
@GetMapping("/{topic}")
public String test(@PathVariable String topic, @PathVariable Long index) throws ExecutionException, InterruptedException {
ListenableFuture future = null;
Chenshuang user = new Chenshuang(i, "陈爽", "123456", new Date());
String s = JSON.toJSONString(user);
KafkaUtils utils = new KafkaUtils();
future = kafkaUtils.send(topic, s);
// 异步回调,同步get,会等待 不推荐同步!
future.addCallback(new ListenableFutureCallback() {
@Override
public void onFailure(Throwable ex) {
System.out.println("发送失败");
}
@Override
public void onSuccess(Object result) {
System.out.println("发送成功:" + result);
}
});
return "发送成功";
}Créer le sujet
Si le côté courtier configure auto.create.topics. activez sur true (la valeur par défaut est true), le sujet sera créé lorsqu'une demande de métadonnées du client sera reçue.
L'envoi et la consommation vers un sujet inexistant créeront un nouveau sujet. Dans de nombreux cas, la création inattendue d'un sujet entraînera de nombreux problèmes inattendus.
Les thèmes de sujet sont utilisés pour distinguer différents types de messages. En fait, ils conviennent à différents scénarios commerciaux. Par défaut, les messages sont enregistrés pendant une semaine.
Sous le même thème de sujet, la valeur par défaut est une partition. signifie qu'il ne peut y avoir qu'un seul consommateur. Pour consommer, si vous souhaitez améliorer la capacité de consommation, vous devez ajouter des partitions
Pour plusieurs partitions d'un même sujet, il existe trois façons de distribuer les messages (clé, valeur) vers différentes partitions ; , partition désignée, routage HASH, par défaut, identique L'ID du message dans la partition est unique et séquentiel
Lorsque les consommateurs consomment des messages dans la partition, ils utilisent offset pour identifier l'emplacement du message
GroupId est utilisé pour résoudre ; le problème de la consommation répétée sous le même sujet, comme un besoin de consommation. Lorsque plusieurs consommateurs le reçoivent, cela peut être réalisé en définissant différents GroupIds
Le message réel est enregistré en une seule copie, et il ne se distingue qu'en définissant logiquement le. Le système l'enregistrera sous le décalage du sujet –》GroupId group–》 sous la partition pour identifier s'il a été consommé.
Haute disponibilité de l'envoi de messages -
Mode cluster, implémentation multi-copies ; la soumission d'un message peut obtenir une disponibilité différente en définissant l'indicateur acks Lorsque =0, c'est OK si l'envoi est réussi lorsque =1, le maître répond avec succès Seulement OK, quand =tout, plus de la moitié des réponses sont OK (réelle haute disponibilité)
Haute disponibilité des messages consommateurs - Vous pouvez désactiver le mode de décalage d'identification automatique, extraire d'abord le message, puis définir le décalage une fois la consommation terminée Localisation, pour résoudre la haute disponibilité de la consommation
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class KafkaTopic {
// yml自定义主题,项目启动就创建,
@Value("${spring.kafka.topic}")
String topic;
@Value("${spring.kafka.bootstrap-servers}")
String[] server;
/**
* 项目启动 初始化主题,如果存在不会覆盖主题的
*/
@Bean
public NewTopic batchTopic() {
// 最大复制因子 <= 经纪人broker数量.
return new NewTopic(topic, 10, (short) server.length);
}
}Classe d'écoute, un message, un seul consommateur dans chaque groupe le consomme une fois. Si le message est dans la zone 1, l'auditeur de la partition 1 spécifié le sera également. consommez-le
Vous pouvez également écouter différents messages avec la même méthode Sujet, surveillance des déplacements spécifiésLe même groupe consommera uniformément et différents groupes consommeront à plusieurs reprises.
1. Mode Unicast, il n'y a qu'un seul groupe de consommateurs
(1) Le sujet n'a qu'une seule partition dans le groupe, le message dans la même partition ne peut être envoyé que par un seul membre du groupe. consommation des consommateurs. Lorsque le nombre de consommateurs dépasse le nombre de partitions, les consommateurs excédentaires sont inactifs, comme le montre la figure 1. Le sujet et le test n'ont qu'une seule partition et un seul groupe, G1. Il y a plusieurs consommateurs dans ce groupe et ne peuvent être consommés que par l'un d'entre eux, tandis que les autres sont inactifs.
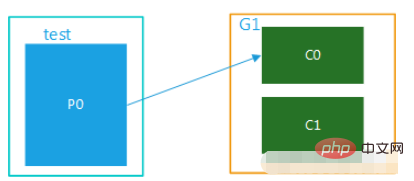 Figure 1
Figure 1
(2) Le sujet a plusieurs partitions et il y a plusieurs consommateurs dans le groupe. Par exemple, test a 3 partitions et il y a 2 consommateurs dans le groupe, alors il peut s'agir de C0 correspondant. consommation p0, les données dans p1, c1 correspondent à la consommation des données de p2 ; s'il y a trois consommateurs, un consommateur correspond à la consommation des données dans une partition ; Les diagrammes sont présentés dans la Figure 2 et la Figure 3. Ce mode est très courant en mode cluster. Par exemple, nous pouvons démarrer 3 services et définir 3 partitions pour le sujet correspondant, afin d'obtenir une consommation parallèle et l'efficacité du traitement des messages. peut être grandement améliorée.
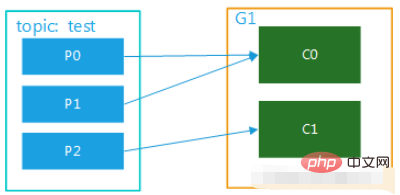 Image 2
Image 2
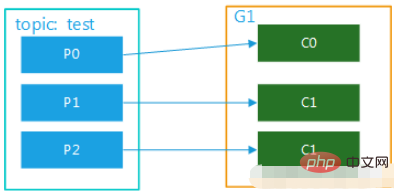 Image 3
Image 3
2. Mode diffusion, plusieurs groupes de consommateurs
Si vous souhaitez mettre en œuvre le mode diffusion, vous devez configurer plusieurs groupes de consommateurs, de sorte que lorsqu'un groupe de consommateurs consomme Après avoir terminé ce message, cela n'affectera pas du tout la consommation des consommateurs des autres groupes. C'est le concept de diffusion.
(1) Plusieurs groupes de consommateurs, 1 partition
Les données de cette rubrique sont consommées par plusieurs groupes de consommateurs en même temps. Lorsqu'un groupe de consommateurs a plusieurs consommateurs, ils ne peuvent être consommés que par un seul consommateur, comme indiqué dans. Figure 4 :
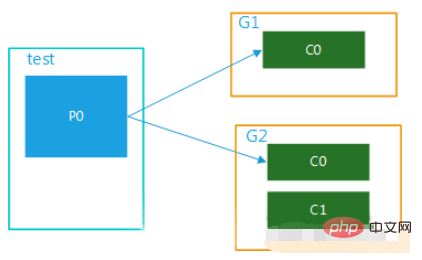 Figure 4
Figure 4
(2) Plusieurs groupes de consommateurs, plusieurs partitions
Les données de cette rubrique peuvent être consommées plusieurs fois par plusieurs groupes de consommateurs, dans un seul consommateur. Au sein du groupe, chaque consommateur peut consommer dans parallèle correspondant à une ou plusieurs partitions au sein du sujet, comme le montre la figure 5 :
注意: 消费者的数量并不能决定一个topic的并行度。它是由分区的数目决定的。
再多的消费者,分区数少,也是浪费!
一个组的最大并行度将等于该主题的分区数。
@Component
@Slf4j
public class Consumer {
// 监听主题 分组a
@KafkaListener(topics =("${spring.kafka.topic}") ,groupId = "a")
public void getMessage(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
// 监听主题 分组a
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "a")
public void getMessage2(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
// 监听主题 分组b
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "b")
public void getMessage3(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息//确认收到消息
ack.acknowledge();
}
// 监听主题 分组b
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "b")
public void getMessage4(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息//确认收到消息
ack.acknowledge();
}
// 指定监听分区1的消息
@KafkaListener(topicPartitions = {@TopicPartition(topic = ("${spring.kafka.topic}"),partitions = {"1"})})
public void getMessage5(ConsumerRecord message, Acknowledgment ack) {
Long id = JSONObject.parseObject(message.value().toString()).getLong("id");
//确认收到消息//确认收到消息
ack.acknowledge();
}
/**
* @Title 指定topic、partition、offset消费
* @Description 同时监听topic1和topic2,监听topic1的0号分区、topic2的 "0号和1号" 分区,指向1号分区的offset初始值为8
* 注意:topics和topicPartitions不能同时使用;
**/
@KafkaListener(id = "c1",groupId = "c",topicPartitions = {
@TopicPartition(topic = "t1", partitions = { "0" }),
@TopicPartition(topic = "t2", partitions = "0", partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "8"))})
public void getMessage6(ConsumerRecord record,Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
/**
* 批量消费监听goods变更消息
* yml配置listener:type 要改为batch
* ymk配置consumer:max-poll-records: ??(每次拉取多少条数据消费)
* concurrency = "2" 启动多少线程执行,应小于等于broker数量,避免资源浪费
*/
@KafkaListener(id="sync-modify-goods", topics = "${spring.kafka.topic}",concurrency = "4")
public void getMessage7(List<ConsumerRecord<String, String>> records){
for (ConsumerRecord<String, String> msg:records) {
GoodsChangeMsg changeMsg = null;
try {
changeMsg = JSONObject.parseObject(msg.value(), GoodsChangeMsg.class);
syncGoodsProcessor.handle(changeMsg);
}catch (Exception exception) {
log.error("解析失败{}", msg, exception);
}
}
}
}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment mettre en œuvre une analyse boursière en temps réel à l'aide de PHP et Kafka
Jun 28, 2023 am 10:04 AM
Comment mettre en œuvre une analyse boursière en temps réel à l'aide de PHP et Kafka
Jun 28, 2023 am 10:04 AM
Avec le développement d’Internet et de la technologie, l’investissement numérique est devenu un sujet de préoccupation croissant. De nombreux investisseurs continuent d’explorer et d’étudier des stratégies d’investissement, dans l’espoir d’obtenir un retour sur investissement plus élevé. Dans le domaine du trading d'actions, l'analyse boursière en temps réel est très importante pour la prise de décision, et l'utilisation de la file d'attente de messages en temps réel Kafka et de la technologie PHP constitue un moyen efficace et pratique. 1. Introduction à Kafka Kafka est un système de messagerie distribué de publication et d'abonnement à haut débit développé par LinkedIn. Les principales fonctionnalités de Kafka sont
 Comparaison et analyse des différences entre SpringBoot et SpringMVC
Dec 29, 2023 am 11:02 AM
Comparaison et analyse des différences entre SpringBoot et SpringMVC
Dec 29, 2023 am 11:02 AM
SpringBoot et SpringMVC sont tous deux des frameworks couramment utilisés dans le développement Java, mais il existe des différences évidentes entre eux. Cet article explorera les fonctionnalités et les utilisations de ces deux frameworks et comparera leurs différences. Tout d’abord, découvrons SpringBoot. SpringBoot a été développé par l'équipe Pivotal pour simplifier la création et le déploiement d'applications basées sur le framework Spring. Il fournit un moyen rapide et léger de créer des fichiers exécutables autonomes.
 Comment créer des applications de traitement de données en temps réel à l'aide de React et Apache Kafka
Sep 27, 2023 pm 02:25 PM
Comment créer des applications de traitement de données en temps réel à l'aide de React et Apache Kafka
Sep 27, 2023 pm 02:25 PM
Comment utiliser React et Apache Kafka pour créer des applications de traitement de données en temps réel Introduction : Avec l'essor du Big Data et du traitement de données en temps réel, la création d'applications de traitement de données en temps réel est devenue la priorité de nombreux développeurs. La combinaison de React, un framework front-end populaire, et d'Apache Kafka, un système de messagerie distribué hautes performances, peut nous aider à créer des applications de traitement de données en temps réel. Cet article expliquera comment utiliser React et Apache Kafka pour créer des applications de traitement de données en temps réel, et
 Tutoriel pratique de développement SpringBoot+Dubbo+Nacos
Aug 15, 2023 pm 04:49 PM
Tutoriel pratique de développement SpringBoot+Dubbo+Nacos
Aug 15, 2023 pm 04:49 PM
Cet article écrira un exemple détaillé pour parler du développement réel de dubbo+nacos+Spring Boot. Cet article ne couvrira pas trop de connaissances théoriques, mais écrira l'exemple le plus simple pour illustrer comment dubbo peut être intégré à nacos pour créer rapidement un environnement de développement.
 Cinq sélections d'outils de visualisation pour explorer Kafka
Feb 01, 2024 am 08:03 AM
Cinq sélections d'outils de visualisation pour explorer Kafka
Feb 01, 2024 am 08:03 AM
Cinq options pour les outils de visualisation Kafka ApacheKafka est une plateforme de traitement de flux distribué capable de traiter de grandes quantités de données en temps réel. Il est largement utilisé pour créer des pipelines de données en temps réel, des files d'attente de messages et des applications basées sur des événements. Les outils de visualisation de Kafka peuvent aider les utilisateurs à surveiller et gérer les clusters Kafka et à mieux comprendre les flux de données Kafka. Ce qui suit est une introduction à cinq outils de visualisation Kafka populaires : ConfluentControlCenterConfluent
 Analyse comparative des outils de visualisation kafka : Comment choisir l'outil le plus approprié ?
Jan 05, 2024 pm 12:15 PM
Analyse comparative des outils de visualisation kafka : Comment choisir l'outil le plus approprié ?
Jan 05, 2024 pm 12:15 PM
Comment choisir le bon outil de visualisation Kafka ? Analyse comparative de cinq outils Introduction : Kafka est un système de file d'attente de messages distribué à haute performance et à haut débit, largement utilisé dans le domaine du Big Data. Avec la popularité de Kafka, de plus en plus d'entreprises et de développeurs ont besoin d'un outil visuel pour surveiller et gérer facilement les clusters Kafka. Cet article présentera cinq outils de visualisation Kafka couramment utilisés et comparera leurs caractéristiques et fonctions pour aider les lecteurs à choisir l'outil qui répond à leurs besoins. 1. KafkaManager
 Comment installer Apache Kafka sur Rocky Linux ?
Mar 01, 2024 pm 10:37 PM
Comment installer Apache Kafka sur Rocky Linux ?
Mar 01, 2024 pm 10:37 PM
Pour installer ApacheKafka sur RockyLinux, vous pouvez suivre les étapes suivantes : Mettre à jour le système : Tout d'abord, assurez-vous que votre système RockyLinux est à jour, exécutez la commande suivante pour mettre à jour les packages système : sudoyumupdate Installer Java : ApacheKafka dépend de Java, vous vous devez d'abord installer JavaDevelopmentKit (JDK). OpenJDK peut être installé via la commande suivante : sudoyuminstalljava-1.8.0-openjdk-devel Télécharger et décompresser : Visitez le site officiel d'ApacheKafka () pour télécharger le dernier package binaire. Choisissez une version stable
 La pratique du go-zero et Kafka+Avro : construire un système de traitement de données interactif performant
Jun 23, 2023 am 09:04 AM
La pratique du go-zero et Kafka+Avro : construire un système de traitement de données interactif performant
Jun 23, 2023 am 09:04 AM
Ces dernières années, avec l'essor du Big Data et des communautés open source actives, de plus en plus d'entreprises ont commencé à rechercher des systèmes de traitement de données interactifs hautes performances pour répondre aux besoins croissants en matière de données. Dans cette vague de mises à niveau technologiques, le go-zero et Kafka+Avro suscitent l’attention et sont adoptés par de plus en plus d’entreprises. go-zero est un framework de microservices développé sur la base du langage Golang. Il présente les caractéristiques de hautes performances, de facilité d'utilisation, d'extension facile et de maintenance facile. Il est conçu pour aider les entreprises à créer rapidement des systèmes d'applications de microservices efficaces. sa croissance rapide
