

Comment utiliser des références faibles en Python

Contexte
Avant de commencer à discuter des références faibles (weakref), jetons d'abord un coup d'œil à ce qu'est une référence faible ? Ça fait quoi exactement ?
Supposons que nous ayons un programme multithread qui traite les données d'application simultanément :
# 占用大量资源,创建销毁成本很高\
class Data:\
def __init__(self, key):\
passDonnées d'application Les données sont identifiées de manière unique par une clé et les mêmes données peuvent être consultées par plusieurs threads en même temps. Les données nécessitant beaucoup de ressources système, le coût de création et de consommation est élevé. Nous espérons que Data ne conserve qu'une seule copie dans le programme et ne souhaite pas la créer à plusieurs reprises même si plusieurs threads y accèdent en même temps.
À cette fin, nous essayons de concevoir un middleware de mise en cache Cacher :
import threading
# 数据缓存
class Cacher:
def __init__(self):
self.pool = {}
self.lock = threading.Lock()
def get(self, key):
with self.lock:
data = self.pool.get(key)
if data:
return data
self.pool[key] = data = Data(key)
return dataCacher utilise en interne un objet dict pour mettre en cache la copie de données créée et fournit une méthode get pour obtenir les données de l'application. Lorsque la méthode get obtient des données, elle vérifie d'abord le dictionnaire de cache. Si les données existent déjà, elles seront renvoyées directement ; si les données n'existent pas, elle en créera un et l'enregistrera dans le dictionnaire. Par conséquent, les données sont saisies dans le dictionnaire du cache après leur première création. Si d'autres threads y accèdent en même temps ultérieurement, la même copie dans le cache sera utilisée.
Ça fait du bien ! Mais le problème est que Cacher court un risque de fuite de ressources !
Car une fois les Données créées, elles sont stockées dans le dictionnaire cache et ne seront jamais publiées ! En d’autres termes, les ressources du programme, comme la mémoire, continueront de croître et pourraient éventuellement exploser. Par conséquent, nous espérons qu’une donnée pourra être automatiquement libérée une fois que tous les threads n’y auront plus accès.
Nous pouvons conserver le nombre de références de données dans Cacher, et la méthode get accumule automatiquement ce nombre. Dans le même temps, une nouvelle méthode de suppression est fournie pour libérer les données. Elle décrémente d'abord le nombre de références et supprime les données du champ de cache lorsque le nombre de références tombe à zéro.
Le fil appelle la méthode get pour obtenir les données. Une fois les données épuisées, la méthode delete doit être appelée pour les libérer. Cacher équivaut à implémenter la méthode de comptage de références elle-même, ce qui est trop gênant ! Python n'a-t-il pas un mécanisme de récupération de place intégré ? Pourquoi l’application doit-elle l’implémenter elle-même ?
Le nœud principal du conflit réside dans le dictionnaire de cache de Cacher : en tant que middleware, il n'utilise pas lui-même d'objets de données, donc théoriquement, il ne devrait pas avoir de références aux données. Existe-t-il donc une technologie noire capable de trouver l'objet cible sans générer de référence ? On le sait, les missions génèrent des références !
Utilisation typique
En ce moment, référence faible (faibleref) fait une grande apparition ! Une référence faible est un objet spécial qui peut être associé à l'objet cible sans générer de référence.
# 创建一个数据 >>> d = Data('fasionchan.com') >>> d <__main__.Data object at 0x1018571f0> # 创建一个指向该数据的弱引用 >>> import weakref >>> r = weakref.ref(d) # 调用弱引用对象,即可找到指向的对象 >>> r() <__main__.Data object at 0x1018571f0> >>> r() is d True # 删除临时变量d,Data对象就没有其他引用了,它将被回收 >>> del d # 再次调用弱引用对象,发现目标Data对象已经不在了(返回None) >>> r()
De cette façon, il suffit de changer le dictionnaire du cache Cacher pour sauvegarder les références faibles, et le problème sera résolu !
import threading
import weakref
# 数据缓存
class Cacher:
def __init__(self):
self.pool = {}
self.lock = threading.Lock()
def get(self, key):
with self.lock:
r = self.pool.get(key)
if r:
data = r()
if data:
return data
data = Data(key)
self.pool[key] = weakref.ref(data)
return dataÉtant donné que le dictionnaire de cache n'enregistre que les références faibles à l'objet Data, le Cacher n'affectera pas le nombre de références de l'objet Data. Lorsque tous les threads ont fini d'utiliser les données, le nombre de références tombe à zéro et est libéré.
En fait, il est très courant d'utiliser des dictionnaires pour mettre en cache des objets de données. Pour cette raison, le module lowref fournit également deux objets dictionnaire qui enregistrent uniquement les références faibles :
weakref.WeakKeyDictionary, la clé enregistre uniquement la classe de mappage. de références faibles (une fois que la clé n'a plus de référence forte, l'entrée de la paire clé-valeur disparaîtra automatiquement
weakref.WeakValueDictionary, la valeur enregistre uniquement la classe de mappage de référence faible (une fois que la valeur n'a plus) ; une référence forte, l'entrée de la paire clé-valeur disparaîtra automatiquement);
Par conséquent, notre dictionnaire de cache de données peut être implémenté à l'aide de faibleref.WeakValueDictionary, et son interface est exactement la même qu'un dictionnaire ordinaire. De cette façon, nous n'avons plus besoin de maintenir nous-mêmes des objets de référence faibles, et la logique du code est plus concise et claire : le module
import threading
import weakref
# 数据缓存
class Cacher:
def __init__(self):
self.pool = weakref.WeakValueDictionary()
self.lock = threading.Lock()
def get(self, key):
with self.lock:
data = self.pool.get(key)
if data:
return data
self.pool[key] = data = Data(key)
return dataweakref possède également de nombreuses classes d'outils et fonctions d'outils utiles. Veuillez vous référer à la documentation officielle pour plus d'informations. détails et ne sera pas répété ici.
Comment ça marche
Alors, qui est exactement la référence faible, et pourquoi a-t-elle un tel pouvoir magique ? Ensuite, enlevons son voile et voyons sa véritable apparence !
>>> d = Data('fasionchan.com') # weakref.ref 是一个内置类型对象 >>> from weakref import ref >>> ref <class 'weakref'> # 调用weakref.ref类型对象,创建了一个弱引用实例对象 >>> r = ref(d) >>> r <weakref at 0x1008d5b80; to 'Data' at 0x100873d60>
Après les chapitres précédents, nous sommes déjà familiarisés avec la lecture du code source des objets intégrés. Les fichiers de code source pertinents sont les suivants :
Include/weakrefobject.h Le fichier d'en-tête contient la structure de l'objet et certains. définitions de macro ;
Objects/weakrefobject Le fichier source .c contient des objets de type référence faible et leurs définitions de méthode
Jetons d'abord un coup d'œil à la structure de champ de l'objet de référence faible, qui est définie aux lignes 10 ; -41 dans le fichier d'en-tête Include/weakrefobject.h :
typedef struct _PyWeakReference PyWeakReference;
/* PyWeakReference is the base struct for the Python ReferenceType, ProxyType,
* and CallableProxyType.
*/
#ifndef Py_LIMITED_API
struct _PyWeakReference {
PyObject_HEAD
/* The object to which this is a weak reference, or Py_None if none.
* Note that this is a stealth reference: wr_object's refcount is
* not incremented to reflect this pointer.
*/
PyObject *wr_object;
/* A callable to invoke when wr_object dies, or NULL if none. */
PyObject *wr_callback;
/* A cache for wr_object's hash code. As usual for hashes, this is -1
* if the hash code isn't known yet.
*/
Py_hash_t hash;
/* If wr_object is weakly referenced, wr_object has a doubly-linked NULL-
* terminated list of weak references to it. These are the list pointers.
* If wr_object goes away, wr_object is set to Py_None, and these pointers
* have no meaning then.
*/
PyWeakReference *wr_prev;
PyWeakReference *wr_next;
};
#endifOn peut voir que la structure PyWeakReference est le corps physique de l'objet de référence faible. C'est un objet de longueur fixe avec 5 champs en plus de l'en-tête fixe :

wr_object , pointeur d'objet, pointant vers l'objet référencé, une référence faible peut trouver l'objet référencé en fonction de ce champ, mais ne le fera pas être généré Référence ;
wr_callback, pointant vers un objet appelable, qui sera appelé lorsque l'objet référencé est détruit
;hash ,缓存被引用对象的哈希值;
wr_prev 和 wr_next 分别是前后向指针,用于将弱引用对象组织成双向链表;
结合代码中的注释,我们知道:

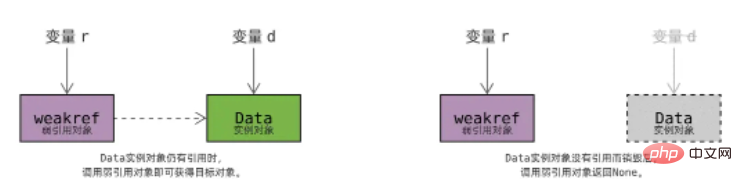
弱引用对象通过 wr_object 字段关联被引用的对象,如上图虚线箭头所示;
一个对象可以同时被多个弱引用对象关联,图中的 Data 实例对象被两个弱引用对象关联;
所有关联同一个对象的弱引用,被组织成一个双向链表,链表头保存在被引用对象中,如上图实线箭头所示;
当一个对象被销毁后,Python 将遍历它的弱引用链表,逐一处理:
将 wr_object 字段设为 None ,弱引用对象再被调用将返回 None ,调用者便知道对象已经被销毁了;
执行回调函数 wr_callback (如有);
由此可见,弱引用的工作原理其实就是设计模式中的 观察者模式( Observer )。当对象被销毁,它的所有弱引用对象都得到通知,并被妥善处理。
实现细节
掌握弱引用的基本原理,足以让我们将其用好。如果您对源码感兴趣,还可以再深入研究它的一些实现细节。
前面我们提到,对同一对象的所有弱引用,被组织成一个双向链表,链表头保存在对象中。由于能够创建弱引用的对象类型是多种多样的,很难由一个固定的结构体来表示。因此,Python 在类型对象中提供一个字段 tp_weaklistoffset ,记录弱引用链表头指针在实例对象中的偏移量。

由此一来,对于任意对象 o ,我们只需通过 ob_type 字段找到它的类型对象 t ,再根据 t 中的 tp_weaklistoffset 字段即可找到对象 o 的弱引用链表头。
Python 在 Include/objimpl.h 头文件中提供了两个宏定义:
/* Test if a type supports weak references */
#define PyType_SUPPORTS_WEAKREFS(t) ((t)->tp_weaklistoffset > 0)
#define PyObject_GET_WEAKREFS_LISTPTR(o) \
((PyObject **) (((char *) (o)) + Py_TYPE(o)->tp_weaklistoffset))PyType_SUPPORTS_WEAKREFS 用于判断类型对象是否支持弱引用,仅当 tp_weaklistoffset 大于零才支持弱引用,内置对象 list 等都不支持弱引用;
PyObject_GET_WEAKREFS_LISTPTR 用于取出一个对象的弱引用链表头,它先通过 Py_TYPE 宏找到类型对象 t ,再找通过 tp_weaklistoffset 字段确定偏移量,最后与对象地址相加即可得到链表头字段的地址;
我们创建弱引用时,需要调用弱引用类型对象 weakref 并将被引用对象 d 作为参数传进去。弱引用类型对象 weakref 是所有弱引用实例对象的类型,是一个全局唯一的类型对象,定义在 Objects/weakrefobject.c 中,即:_PyWeakref_RefType(第 350 行)。

根据对象模型中学到的知识,Python 调用一个对象时,执行的是其类型对象中的 tp_call 函数。因此,调用弱引用类型对象 weakref 时,执行的是 weakref 的类型对象,也就是 type 的 tp_call 函数。tp_call 函数则回过头来调用 weakref 的 tp_new 和 tp_init 函数,其中 tp_new 为实例对象分配内存,而 tp_init 则负责初始化实例对象。
回到 Objects/weakrefobject.c 源文件,可以看到 PyWeakref_RefType 的 tp_new 字段被初始化成 *weakref___new_* (第 276 行)。该函数的主要处理逻辑如下:
解析参数,得到被引用的对象(第 282 行);
调用 PyType_SUPPORTS_WEAKREFS 宏判断被引用的对象是否支持弱引用,不支持就抛异常(第 286 行);
调用 GET_WEAKREFS_LISTPTR 行取出对象的弱引用链表头字段,为方便插入返回的是一个二级指针(第 294 行);
调用 get_basic_refs 取出链表最前那个 callback 为空 基础弱引用对象(如有,第 295 行);
如果 callback 为空,而且对象存在 callback 为空的基础弱引用,则复用该实例直接将其返回(第 296 行);
如果不能复用,调用 tp_alloc 函数分配内存、完成字段初始化,并插到对象的弱引用链表(第 309 行);
Si le rappel est vide, insérez-le directement au début de la liste chaînée pour faciliter la réutilisation ultérieure (voir point 4)
Si le rappel n'est pas vide, insérez-le dans l'objet de référence faible de base (); le cas échéant) Après cela, assurez-vous que la référence faible de base est située en tête de la liste chaînée pour un accès facile
Lorsqu'un objet est recyclé, la fonction tp_dealloc appellera la fonction PyObject_ClearWeakRefs pour nettoyer ses références faibles ; . Cette fonction supprime la liste de références faibles de l'objet, puis la parcourt une par une, nettoie le champ wr_object et exécute la fonction de rappel wr_callback (le cas échéant). Les détails spécifiques ne seront pas développés. Si vous êtes intéressé, vous pouvez vérifier le code source dans Objects/weakrefobject.c, situé à la ligne 880.
D'accord, après avoir étudié cette section, nous maîtrisons parfaitement les connaissances liées aux références faibles. Les références faibles peuvent gérer l'objet cible sans générer de décompte de références et sont souvent utilisées dans les frameworks et les middlewares. Les références faibles semblent magiques, mais en réalité, le principe de conception est un modèle d’observation très simple. Une fois l'objet de référence faible créé, il est inséré dans une liste chaînée maintenue par l'objet cible, et l'événement de destruction de l'objet est observé (souscrit).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: Une base de données Python évolutive de haut niveau légère HaDIDB (HaDIDB) est une base de données légère écrite en Python, avec un niveau élevé d'évolutivité. Installez HaDIDB à l'aide de l'installation PIP: PiPinStallHaDIDB User Management Créer un utilisateur: CreateUser () pour créer un nouvel utilisateur. La méthode Authentication () authentifie l'identité de l'utilisateur. FromHadidb.OperationMportUserUser_OBJ = User ("Admin", "Admin") User_OBJ.
 MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL peut s'exécuter sans connexions réseau pour le stockage et la gestion des données de base. Cependant, la connexion réseau est requise pour l'interaction avec d'autres systèmes, l'accès à distance ou l'utilisation de fonctionnalités avancées telles que la réplication et le clustering. De plus, les mesures de sécurité (telles que les pare-feu), l'optimisation des performances (choisissez la bonne connexion réseau) et la sauvegarde des données sont essentielles pour se connecter à Internet.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 MySQL Workbench peut-il se connecter à MariaDB
Apr 08, 2025 pm 02:33 PM
MySQL Workbench peut-il se connecter à MariaDB
Apr 08, 2025 pm 02:33 PM
MySQL Workbench peut se connecter à MARIADB, à condition que la configuration soit correcte. Sélectionnez d'abord "MariADB" comme type de connecteur. Dans la configuration de la connexion, définissez correctement l'hôte, le port, l'utilisateur, le mot de passe et la base de données. Lorsque vous testez la connexion, vérifiez que le service MARIADB est démarré, si le nom d'utilisateur et le mot de passe sont corrects, si le numéro de port est correct, si le pare-feu autorise les connexions et si la base de données existe. Dans une utilisation avancée, utilisez la technologie de mise en commun des connexions pour optimiser les performances. Les erreurs courantes incluent des autorisations insuffisantes, des problèmes de connexion réseau, etc. Lors des erreurs de débogage, analysez soigneusement les informations d'erreur et utilisez des outils de débogage. L'optimisation de la configuration du réseau peut améliorer les performances
 MySQL a-t-il besoin d'un serveur
Apr 08, 2025 pm 02:12 PM
MySQL a-t-il besoin d'un serveur
Apr 08, 2025 pm 02:12 PM
Pour les environnements de production, un serveur est généralement nécessaire pour exécuter MySQL, pour des raisons, notamment les performances, la fiabilité, la sécurité et l'évolutivité. Les serveurs ont généralement un matériel plus puissant, des configurations redondantes et des mesures de sécurité plus strictes. Pour les petites applications à faible charge, MySQL peut être exécutée sur des machines locales, mais la consommation de ressources, les risques de sécurité et les coûts de maintenance doivent être soigneusement pris en considération. Pour une plus grande fiabilité et sécurité, MySQL doit être déployé sur le cloud ou d'autres serveurs. Le choix de la configuration du serveur approprié nécessite une évaluation en fonction de la charge d'application et du volume de données.
