

Comment SpringBoot démarre et initialise l'exécution des scripts SQL

SpringBoot démarre et initialise l'exécution des scripts SQL
Que devons-nous faire si nous voulons exécuter certains scripts SQL au démarrage du projet SpringBoot nous fournit cette fonction, qui peut exécuter le script au démarrage du projet SpringBoot ? , jetons un oeil ci-dessous.
Jetons d'abord un coup d'œil au code source
boolean createSchema() {
//会从application.properties或application.yml中获取sql脚本列表
List<Resource> scripts = this.getScripts("spring.datasource.schema", this.properties.getSchema(), "schema");
if (!scripts.isEmpty()) {
if (!this.isEnabled()) {
logger.debug("Initialization disabled (not running DDL scripts)");
return false;
}
String username = this.properties.getSchemaUsername();
String password = this.properties.getSchemaPassword();
//运行sql脚本
this.runScripts(scripts, username, password);
}
return !scripts.isEmpty();
}
private List<Resource> getScripts(String propertyName, List<String> resources, String fallback) {
if (resources != null) {
//如果配置文件中配置,则加载配置文件
return this.getResources(propertyName, resources, true);
} else {
//指定schema要使用的Platform(mysql、oracle),默认为all
String platform = this.properties.getPlatform();
List<String> fallbackResources = new ArrayList();
//如果配置文件中没配置,则会去类路径下找名称为schema或schema-platform的文件
fallbackResources.add("classpath*:" + fallback + "-" + platform + ".sql");
fallbackResources.add("classpath*:" + fallback + ".sql");
return this.getResources(propertyName, fallbackResources, false);
}
}
private List<Resource> getResources(String propertyName, List<String> locations, boolean validate) {
List<Resource> resources = new ArrayList();
Iterator var5 = locations.iterator();
while(var5.hasNext()) {
String location = (String)var5.next();
Resource[] var7 = this.doGetResources(location);
int var8 = var7.length;
for(int var9 = 0; var9 < var8; ++var9) {
Resource resource = var7[var9];
//验证文件是否存在
if (resource.exists()) {
resources.add(resource);
} else if (validate) {
throw new InvalidConfigurationPropertyValueException(propertyName, resource, "The specified resource does not exist.");
}
}
}
return resources;
}D'après le code source, nous savons à peu près ce que cela signifie par défaut, SpringBoot trouvera les fichiers de script à partir du chemin de classe, mais seul le nom spécifié peut être placé sous. le chemin de classe : schéma ou fichier de script de plate-forme de schéma, si nous voulons le diviser en plusieurs fichiers de script, alors cette méthode ne convient pas, nous devons alors configurer la liste de scripts dans application.properties ou application.yml, alors cela peut-il le fonctionnement du script d'initialisation doit être configuré dans Quant au contrôle dans le fichier, oui, il existe un attribut de mode d'initialisation, qui peut être défini sur trois valeurs, ce qui signifie toujours effectuer une initialisation, intégré initialise uniquement la base de données mémoire (valeur par défaut), par exemple. comme h3, etc., et ne signifie jamais ne pas effectuer d'initialisation.
spring:
datasource:
username: root
password: liuzhenyu199577
url: jdbc:mysql://localhost:3306/jdbc
driver-class-name: com.mysql.cj.jdbc.Driver
initialization-mode: alwaysVérifions ces deux méthodes
1. Le fichier script du schéma ou schema-platform est placé par défaut
CREATE TABLE IF NOT EXISTS department (ID VARCHAR(40) NOT NULL, NAME VARCHAR(100), PRIMARY KEY (ID));
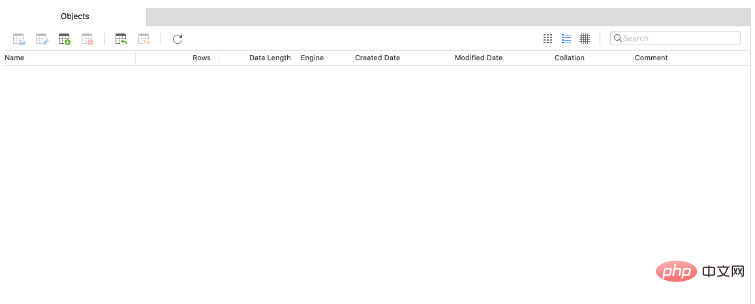
Vérifiez que la base de données n'a pas la table département, puis nous démarrons le programme
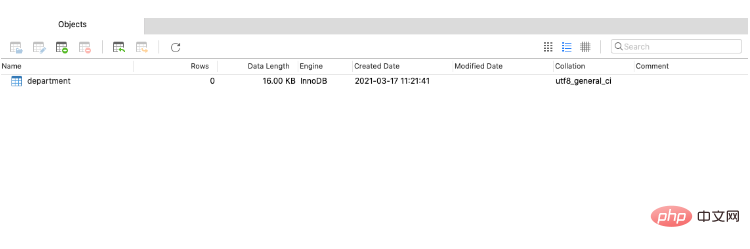
Après avoir démarré, jetons un autre coup d'œil et exécutons-le
2. Plusieurs scripts SQL sont spécifiés dans le fichier de configuration
spring:
datasource:
username: root
password: liuzhenyu199577
url: jdbc:mysql://localhost:3306/jdbc
driver-class-name: com.mysql.cj.jdbc.Driver
initialization-mode: always
schema:
- classpath:department.sql
- classpath:department2.sql
- classpath:department3.sql
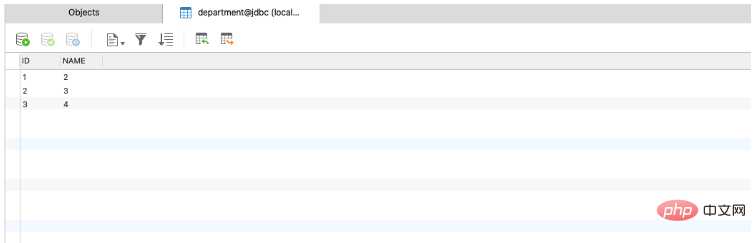
Les trois scripts SQL sont des instructions d'insertion
INSERT INTO department (ID,NAME) VALUES ('1','2') INSERT INTO department (ID,NAME) VALUES ('2','3') INSERT INTO department (ID,NAME) VALUES ('3','4')
Maintenant, il n'y a aucune donnée dans la table, ensuite Après avoir démarré le programme
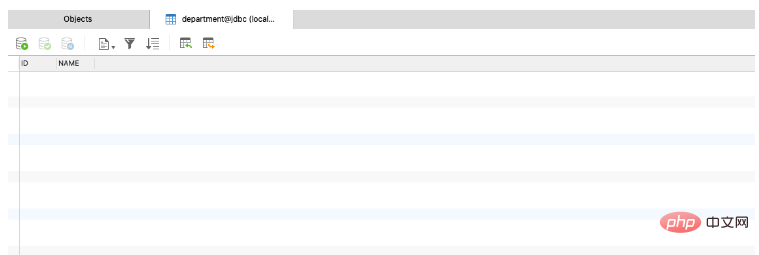
, jetons un coup d'œil à nouveau. Il y a trois éléments de données dans la table
C'est l'étape de démarrage de SpringBoot et d'initialisation du script SQL
Le Le projet SpringBoot exécute le fichier SQL spécifié au démarrage
1. Exécuter au démarrage
Lorsqu'il est nécessaire d'exécuter d'abord l'instruction SQL spécifiée au démarrage du projet, vous pouvez ajouter le fichier SQL qui doit être exécuté sous les ressources L'instruction SQL dans le fichier peut être un script DDL ou un script DML, puis ajoutez simplement la configuration correspondante à la configuration, comme suit :
spring:
datasource:
schema: classpath:schema.sql # schema.sql中一般存放的是DDL脚本,即通常为创建或更新库表的脚本 data: classpath:data.sql # data.sql中一般是DML脚本,即通常为数据插入脚本2. Exécutez plusieurs fichiers SQL
spring.datasource.schema et spring. .datasource.data prennent tous deux en charge la réception d'une liste, donc lorsque vous devez exécuter plusieurs fichiers SQL, vous pouvez utiliser la configuration suivante :
spring:
datasource:
schema: classpath:schema_1.sql, classpath:schema_2.sql data: classpath:data_1.sql, classpath:data_2.sql 或 spring: datasource: schema: - classpath:schema_1.sql - classpath:schema_2.sql data: - classpath:data_1.sql - classpath:data_2.sql3. Différents environnements d'exécution exécutent différents scripts
En général, il y aura plusieurs environnements d'exécution, tels que. comme le développement, les tests, la production, etc. Le SQL qui doit généralement être exécuté dans différents environnements d'exploitation sera différent. Pour résoudre ce problème, des caractères génériques peuvent être utilisés.
Créez des dossiers pour différents environnements
Créez des dossiers correspondant à différents environnements dans le dossier des ressources, tels que dev/, sit/, prod/.
Configuration
application.yml
spring:
datasource:
schema: classpath:${spring.profiles.active:dev}/schema.sql
data: classpath:${spring.profiles.active:dev}/data.sqlRemarque : le caractère générique ${} prend en charge la valeur par défaut. Par exemple, ${spring.profiles.active:dev} dans la configuration ci-dessus, avant le point-virgule doit prendre la valeur de l'attribut spring.profiles.active, et lorsque la valeur de l'attribut n'existe pas, la valeur après le le point-virgule est utilisé, c'est-à-dire dev.
bootstrap.yml
spring:
profiles:
active: dev # dev/sit/prod等。分别对应开发、测试、生产等不同运行环境。Rappel : La propriété spring.profiles.active est généralement configurée dans bootstrap.yml ou bootstrap.properties.
4. Prise en charge de différentes bases de données
Étant donné que la syntaxe des différentes bases de données est différente, pour obtenir la même fonction, les instructions SQL des différentes bases de données peuvent être différentes, il peut donc y avoir plusieurs fichiers SQL différents. Lorsque vous devez prendre en charge différentes bases de données, vous pouvez utiliser la configuration suivante :
spring:
datasource:
schema: classpath:${spring.profiles.active:dev}/schema-${spring.datasource.platform}.sql
data: classpath:${spring.profiles.active:dev}/data-${spring.datasource.platform}.sql
platform: mysqlRappel : La valeur par défaut de l'attribut de plateforme est "all", utilisez donc uniquement la configuration ci-dessus lors du basculement entre différentes bases de données, car avec la valeur par défaut, Spring Boot détectera automatiquement la base de données actuellement utilisée.
Remarque : à l'heure actuelle, en prenant comme exemple l'environnement de développement autorisé, les fichiers suivants doivent exister dans le dossier resources/dev/ : schema-mysql.sql et data-mysql.sql.
5. Évitez les pièges
5.1 Pièges
Lorsqu'il y a des procédures ou des fonctions stockées dans le fichier SQL exécuté, une erreur sera signalée lors du démarrage du projet.
Par exemple, il existe désormais une telle exigence : lorsque le projet démarre, analysez une certaine table. Lorsque le nombre d'enregistrements dans la table est de 0, insérez plusieurs enregistrements lorsqu'il est supérieur à 0, ignorez-le.
Le script du fichier schema.sql est le suivant :
-- 当存储过程`p1`存在时,删除。 drop procedure if exists p1; -- 创建存储过程`p1` create procedure p1() begin declare row_num int; select count(*) into row_num from `t_user`; if row_num = 0 then INSERT INTO `t_user`(`username`, `password`) VALUES ('zhangsan', '123456'); end if; end; -- 调用存储过程`p1` call p1(); drop procedure if exists p1;
Démarrez le projet et signalez une erreur, la raison est la suivante :
Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'create procedure p1() begin declare row_num int' at line 1
大致的意思是:'create procedure p1() begin declare row_num int'这一句出现语法错误。刚看到这一句,我一开始是懵逼的,吓得我赶紧去比对mysql存储过程的写法,对了好久都发现没错,最后看到一篇讲解spring boot配置启动时执行sql脚本的文章,发现其中多了一项配置:spring.datasource.separator=$$。然后看源码发现,spring boot在解析sql脚本时,默认是以';'作为断句的分隔符的。看到这里,不难看出报错的原因,即:spring boot把'create procedure p1() begin declare row_num int'当成是一条普通的sql语句。而我们需要的是创建一个存储过程。
5.2 解决方案
修改sql脚本的断句分隔符。如:spring.datasource.separator=$$。然后把脚本改成:
-- 当存储过程`p1`存在时,删除。 drop procedure if exists p1;$$ -- 创建存储过程`p1` create procedure p1() begin declare row_num int; select count(*) into row_num from `t_user`; if row_num = 0 then INSERT INTO `t_user`(`username`, `password`) VALUES ('zhangsan', '123456'); end if; end;$$ -- 调用存储过程`p1` call p1();$$ drop procedure if exists p1;$$
5.3 不足
因为sql脚本的断句分隔符从';'变成'$$',所以可能需要在DDL、DML语句的';'后加'$$',不然可能会出现将整个脚本当成一条sql语句来执行的情况。比如:
-- DDL CREATE TABLE `table_name` ( -- 字段定义 ... ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;$$ -- DML INSERT INTO `table_name` VALUE(...);$$
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle est la différence entre HQL et SQL dans le framework Hibernate ?
Apr 17, 2024 pm 02:57 PM
Quelle est la différence entre HQL et SQL dans le framework Hibernate ?
Apr 17, 2024 pm 02:57 PM
HQL et SQL sont comparés dans le framework Hibernate : HQL (1. Syntaxe orientée objet, 2. Requêtes indépendantes de la base de données, 3. Sécurité des types), tandis que SQL exploite directement la base de données (1. Normes indépendantes de la base de données, 2. Exécutable complexe requêtes et manipulation de données).
 Utilisation de l'opération de division dans Oracle SQL
Mar 10, 2024 pm 03:06 PM
Utilisation de l'opération de division dans Oracle SQL
Mar 10, 2024 pm 03:06 PM
"Utilisation de l'opération de division dans OracleSQL" Dans OracleSQL, l'opération de division est l'une des opérations mathématiques courantes. Lors de l'interrogation et du traitement des données, les opérations de division peuvent nous aider à calculer le rapport entre les champs ou à dériver la relation logique entre des valeurs spécifiques. Cet article présentera l'utilisation de l'opération de division dans OracleSQL et fournira des exemples de code spécifiques. 1. Deux méthodes d'opérations de division dans OracleSQL Dans OracleSQL, les opérations de division peuvent être effectuées de deux manières différentes.
 Comparaison et différences de syntaxe SQL entre Oracle et DB2
Mar 11, 2024 pm 12:09 PM
Comparaison et différences de syntaxe SQL entre Oracle et DB2
Mar 11, 2024 pm 12:09 PM
Oracle et DB2 sont deux systèmes de gestion de bases de données relationnelles couramment utilisés, chacun possédant sa propre syntaxe et ses propres caractéristiques SQL. Cet article comparera et différera la syntaxe SQL d'Oracle et de DB2, et fournira des exemples de code spécifiques. Connexion à la base de données Dans Oracle, utilisez l'instruction suivante pour vous connecter à la base de données : CONNECTusername/password@database Dans DB2, l'instruction pour vous connecter à la base de données est la suivante : CONNECTTOdataba.
 Explication détaillée de la fonction Définir la balise dans les balises SQL dynamiques MyBatis
Feb 26, 2024 pm 07:48 PM
Explication détaillée de la fonction Définir la balise dans les balises SQL dynamiques MyBatis
Feb 26, 2024 pm 07:48 PM
Interprétation des balises SQL dynamiques MyBatis : explication détaillée de l'utilisation des balises Set MyBatis est un excellent cadre de couche de persistance. Il fournit une multitude de balises SQL dynamiques et peut construire de manière flexible des instructions d'opération de base de données. Parmi elles, la balise Set est utilisée pour générer la clause SET dans l'instruction UPDATE, qui est très couramment utilisée dans les opérations de mise à jour. Cet article expliquera en détail l'utilisation de la balise Set dans MyBatis et démontrera ses fonctionnalités à travers des exemples de code spécifiques. Qu'est-ce que Set tag Set tag est utilisé dans MyBati
 Que signifie l'attribut d'identité dans SQL ?
Feb 19, 2024 am 11:24 AM
Que signifie l'attribut d'identité dans SQL ?
Feb 19, 2024 am 11:24 AM
Qu'est-ce que l'identité en SQL ? Des exemples de code spécifiques sont nécessaires. En SQL, l'identité est un type de données spécial utilisé pour générer des nombres à incrémentation automatique. Il est souvent utilisé pour identifier de manière unique chaque ligne de données dans une table. La colonne Identité est souvent utilisée conjointement avec la colonne clé primaire pour garantir que chaque enregistrement possède un identifiant unique. Cet article détaillera comment utiliser Identity et quelques exemples de code pratiques. La manière de base d'utiliser Identity consiste à utiliser Identit lors de la création d'une table.
 Comparaison et analyse des différences entre SpringBoot et SpringMVC
Dec 29, 2023 am 11:02 AM
Comparaison et analyse des différences entre SpringBoot et SpringMVC
Dec 29, 2023 am 11:02 AM
SpringBoot et SpringMVC sont tous deux des frameworks couramment utilisés dans le développement Java, mais il existe des différences évidentes entre eux. Cet article explorera les fonctionnalités et les utilisations de ces deux frameworks et comparera leurs différences. Tout d’abord, découvrons SpringBoot. SpringBoot a été développé par l'équipe Pivotal pour simplifier la création et le déploiement d'applications basées sur le framework Spring. Il fournit un moyen rapide et léger de créer des fichiers exécutables autonomes.
 Comment utiliser les instructions SQL pour l'agrégation de données et les statistiques dans MySQL ?
Dec 17, 2023 am 08:41 AM
Comment utiliser les instructions SQL pour l'agrégation de données et les statistiques dans MySQL ?
Dec 17, 2023 am 08:41 AM
Comment utiliser les instructions SQL pour l'agrégation de données et les statistiques dans MySQL ? L'agrégation des données et les statistiques sont des étapes très importantes lors de l'analyse des données et des statistiques. En tant que puissant système de gestion de bases de données relationnelles, MySQL fournit une multitude de fonctions d'agrégation et de statistiques, qui peuvent facilement effectuer des opérations d'agrégation de données et de statistiques. Cet article présentera la méthode d'utilisation des instructions SQL pour effectuer l'agrégation de données et les statistiques dans MySQL, et fournira des exemples de code spécifiques. 1. Utilisez la fonction COUNT pour compter. La fonction COUNT est la plus couramment utilisée.
 Comment résoudre l'erreur 5120 dans SQL
Mar 06, 2024 pm 04:33 PM
Comment résoudre l'erreur 5120 dans SQL
Mar 06, 2024 pm 04:33 PM
Solution : 1. Vérifiez si l'utilisateur connecté dispose des autorisations suffisantes pour accéder ou utiliser la base de données, et assurez-vous que l'utilisateur dispose des autorisations appropriées ; 2. Vérifiez si le compte du service SQL Server est autorisé à accéder au fichier spécifié ou ; dossier et assurez-vous que le compte dispose des autorisations suffisantes pour lire et écrire le fichier ou le dossier ; 3. Vérifiez si le fichier de base de données spécifié a été ouvert ou verrouillé par d'autres processus, essayez de fermer ou de libérer le fichier et réexécutez la requête ; . Essayez en tant qu'administrateur, exécutez Management Studio en tant que etc.
