
 développement back-end
Tutoriel Python
Comment Python utilise la stratégie de cache LRU pour la mise en cache
développement back-end
Tutoriel Python
Comment Python utilise la stratégie de cache LRU pour la mise en cache
Comment Python utilise la stratégie de cache LRU pour la mise en cache

1. Python Cache
① Le rôle de la mise en cache
Le cache est une technologie d'optimisation qui peut être utilisée dans les applications pour enregistrer en mémoire les données récemment ou fréquemment utilisées. Beaucoup plus élevé que la lecture directe des fichiers disque.
Supposons que nous construisions un site Web d'agrégation d'actualités, similaire à Feedly, qui récupère les actualités de différentes sources, puis les agrège et les affiche. Lorsque l'utilisateur parcourt l'actualité, le programme en arrière-plan télécharge l'article et l'affiche sur l'écran de l'utilisateur. Si la technologie de mise en cache n’est pas utilisée, lorsque les utilisateurs passent plusieurs fois à parcourir le même article, ils doivent le télécharger plusieurs fois, ce qui est inefficace et peu convivial.
Une meilleure approche consiste à stocker le contenu localement après avoir obtenu chaque article, par exemple dans une base de données. Ensuite, lorsque l'utilisateur ouvrira le même article la prochaine fois, le programme en arrière-plan pourra ouvrir le contenu à partir du stockage local, au lieu de En téléchargeant à nouveau le fichier source, cette technique est appelée mise en cache.
② Utilisez le dictionnaire Python pour implémenter la mise en cache
Prenons l'exemple d'un site Web d'agrégation d'actualités. Il n'est pas nécessaire de télécharger le contenu de l'article à chaque fois, il vérifie d'abord si le contenu correspondant existe dans les données du cache uniquement. sinon, le serveur téléchargera-t-il l'article.
L'exemple de programme suivant utilise un dictionnaire Python pour implémenter la mise en cache, en utilisant l'URL de l'article comme clé et son contenu comme valeur après exécution, vous pouvez voir que lorsque la fonction get_article est exécutée pour la deuxième fois, le résultat est renvoyé directement et ne laisse pas le serveur télécharger :
import requests
cache = dict()
def get_article_from_server(url):
print("Fetching article from server...")
response = requests.get(url)
return response.text
def get_article(url):
print("Getting article...")
if url not in cache:
cache[url] = get_article_from_server(url)
return cache[url]
get_article("https://www.escapelife.site/love-python.html")
get_article("https://www.escapelife.site/love-python.html")Enregistrez ce code dans un fichier caching.py, installez la bibliothèque de requêtes et exécutez le script :
# 安装依赖 $ pip install requests # 执行脚本 $ python python_caching.py Getting article... Fetching article from server... Getting article...
Malgré l'appel de get_article() deux fois (lignes 17 et 18), la chaîne " Récupération de l'article depuis le serveur... ", mais ne l'affiche toujours qu'une seule fois. Cela se produit car après avoir accédé à l'article pour la première fois, son URL et son contenu sont placés dans le dictionnaire de cache et la deuxième fois, le code n'a pas besoin de récupérer à nouveau l'élément sur le serveur.
③ Inconvénients de l'utilisation de dictionnaires pour la mise en cache
Il y a un très gros problème avec la mise en œuvre de la mise en cache ci-dessus, c'est-à-dire que le contenu du dictionnaire augmentera à l'infini, c'est-à-dire que lorsqu'un grand nombre d'utilisateurs parcourent continuellement les articles, l'arrière-plan Le programme continuera à ajouter des données au dictionnaire. En encombrant le contenu qui doit être stocké, la mémoire du serveur est remplie, provoquant éventuellement le crash de l'application.
Il y a un très gros problème avec l'implémentation de la mise en cache ci-dessus, c'est-à-dire que le contenu du dictionnaire augmentera à l'infini, c'est-à-dire que lorsqu'un grand nombre d'utilisateurs parcourent continuellement les articles, le programme d'arrière-plan continuera à remplir le contenu qui doit être stocké dans le dictionnaire et la mémoire du serveur est remplie, provoquant finalement le crash de l'application.
Pour résoudre le problème ci-dessus, vous avez besoin d'une stratégie pour décider quels articles doivent rester en mémoire et quels articles doivent être supprimés. Ces stratégies de mise en cache sont en fait des algorithmes qui sont utilisés pour gérer les informations mises en cache et sélectionner les éléments à supprimer. place pour les nouveautés.
Bien sûr, vous n'avez pas besoin d'implémenter un algorithme pour gérer le cache, il vous suffit d'utiliser différentes stratégies pour supprimer des éléments du cache et l'empêcher de dépasser sa taille maximale. Cinq algorithmes de mise en cache courants sont les suivants :
| Stratégie de mise en cache | Nom anglais | Conditions d'élimination | Quand sont-elles les plus utiles |
|---|---|---|---|
| Algorithme premier entré, premier sorti (FIFO) | Premier entré/premier sorti | Éliminez les entrées les plus anciennes | Les entrées les plus récentes sont les plus susceptibles d'être réutilisées |
| Dernier entré, premier sorti (LIFO) | Dernier entré/premier sorti | Éliminez le entrées les plus récentes | Les entrées les plus anciennes sont les plus susceptibles d'être réutilisées |
| Algorithme du moins récemment utilisé (LRU) | Le moins récemment utilisé | Élimine les entrées les moins récemment utilisées | Les entrées les plus récemment utilisées sont les plus susceptibles d'être réutilisées |
| Algorithme le plus récemment utilisé (MRU) | Le plus récemment utilisé | Élimine les entrées les plus récemment utilisées | Les entrées récemment inutilisées sont les plus susceptibles d'être réutilisées |
| Algorithme le moins récemment atteint (LFU) | Le moins fréquemment utilisé | Élimine les éléments les moins fréquemment consultés | Les éléments avec un taux de réussite élevé sont plus susceptibles d'être réutilisés |
Après avoir lu les cinq algorithmes de mise en cache ci-dessus, êtes-vous un peu confus lorsque vous voyez LRU et LFU La raison principale est qu'il est difficile de comprendre sa véritable signification à travers l'explication correspondante en chinois ? . La différence entre les algorithmes LRU et LFU est la suivante :
LRU a une règle d'élimination basée sur le temps d'accès, qui élimine les données en fonction des enregistrements d'accès historiques aux données. Si les données ont été consultées récemment, la probabilité d'y avoir accès. l'avenir est également plus élevé ;
Les règles d'élimination LFU basées sur le nombre d'accès, éliminent les données en fonction de la fréquence d'accès historique des données. Si les données ont été consultées plusieurs fois dans le passé, elles seront consultées plus fréquemment. dans le futur ;
Par exemple, dix minutes correspondent à la durée pendant laquelle un nœud effectue la planification de page une fois par minute lorsque la direction de page requise est 2 1 2 4 2 3 4 et qu'une interruption de défaut de page se produit lorsque la page 4 est ajustée. ; si l'algorithme LRU est utilisé, la page 1 doit être modifiée (dix minutes, la page 1 n'a pas été utilisée depuis le plus longtemps), mais selon l'algorithme LFU, la page 3 doit être modifiée (la page 3 n'est utilisée qu'une fois dans les dix minutes). ).
2. Compréhension approfondie de l'algorithme LRU
① Visualisez les caractéristiques du cache LRU
Le cache implémenté à l'aide de la stratégie LRU est trié par ordre d'utilisation. À chaque accès à une entrée, l'algorithme LRU se déplace. vers le haut du cache. De cette manière, l’algorithme peut identifier rapidement les entrées qui n’ont pas été utilisées depuis le plus longtemps en regardant en bas de la liste.
Comme indiqué ci-dessous, la politique LRU stocke les enregistrements du premier article demandé par l'utilisateur sur le réseau :
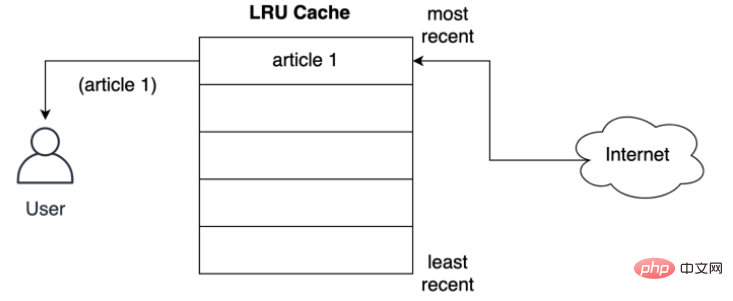
Comment le cache stocke-t-il l'article dans l'emplacement le plus proche avant de le servir à l'utilisateur ? Comme indiqué ci-dessous, que se passe-t-il lorsque l'utilisateur demande le deuxième article, le deuxième article est stocké en première position, c'est-à-dire que le deuxième article prend la position la plus récente, poussant le premier article plus bas dans la liste :
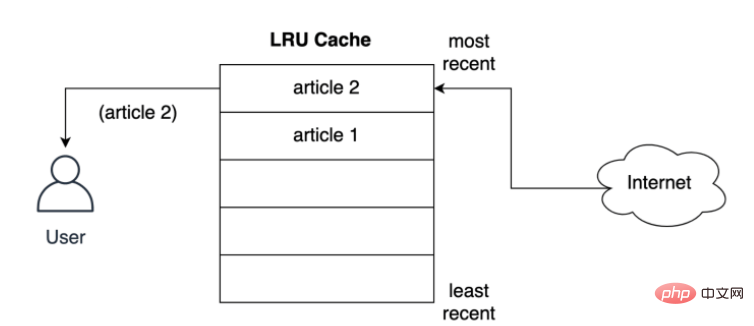
Le LRU La stratégie suppose que plus l'objet utilisé est récent, plus il est probable qu'il soit utilisé dans le futur, elle essaie donc de conserver l'objet dans le cache le plus longtemps possible, c'est-à-dire que si l'expulsion d'une entrée se produit, la première entrée sera expulsée en premier. Un cache d'enregistrements de stockage de documents.
② Afficher la structure du cache LRU
Une façon d'implémenter le cache LRU en Python consiste à utiliser une liste doublement chaînée et une carte de hachage. L'élément principal de la liste doublement chaînée pointera vers l'entrée la plus récemment utilisée. sa queue pointera vers l'entrée la moins récemment utilisée. La structure logique de mise en œuvre du cache LRU est la suivante :
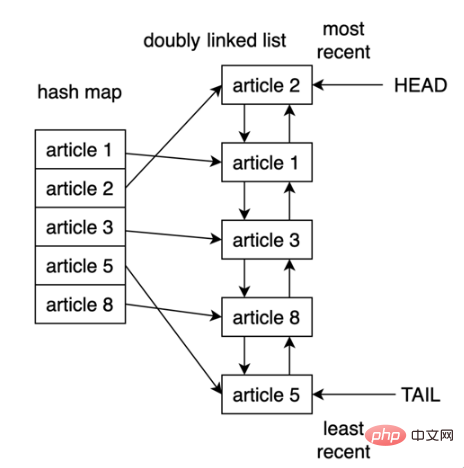
En utilisant une carte de hachage, chaque entrée peut être mappée à un emplacement spécifique dans la liste doublement chaînée, garantissant ainsi l'accès à chaque élément du cache. Cette stratégie est très rapide, l'accès à l'élément le moins récemment utilisé et la mise à jour du cache sont tous deux des opérations O(1).
À partir de Python 3.2, Python a ajouté le décorateur @lru_cache pour implémenter la stratégie LRU. Désormais, vous pouvez utiliser ce décorateur pour décorer les fonctions et mettre en cache leurs résultats de calcul.
3. Utilisez lru_cache decorator
① Principe de mise en œuvre de @lru_cache decorator
Il existe de nombreuses façons d'obtenir une réponse rapide de l'application, et l'utilisation du cache est une méthode très courante. La mise en cache, si elle est utilisée correctement, peut accélérer les réponses et réduire la charge supplémentaire sur les ressources informatiques.
En Python, le module functools est livré avec le décorateur @lru_cache pour la mise en cache, qui peut utiliser la stratégie la moins récemment utilisée (LRU) pour mettre en cache les résultats de calcul de la fonction. Il s'agit d'une technologie simple mais puissante :
Implémentez la. @lru_cache decorator ;
Comprendre le fonctionnement de la politique LRU ;
Utiliser le décorateur @lru_cache pour améliorer les performances
Étendre les fonctionnalités du décorateur @lru_cache et le faire expirer après une heure spécifique ;
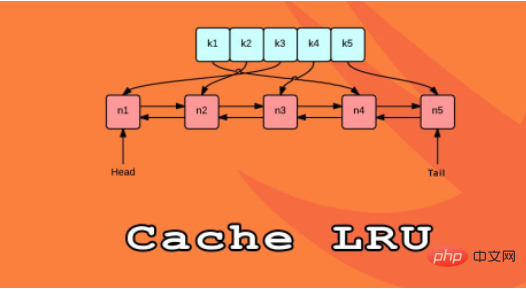
Tout comme la solution de mise en cache précédemment implémentée, le stockage du décorateur @lru_cache en Python utilise également un dictionnaire comme objet de stockage. Il met en cache le résultat de l'exécution de la fonction dans la clé du dictionnaire, qui est composée de. se compose d'appels à la fonction (y compris les paramètres de la fonction), ce qui signifie que les paramètres de ces fonctions doivent être hachables pour que le décorateur fonctionne correctement.
② Séquence de Fibonacci
Nous devrions tous savoir comment calculer la séquence de Fibonacci. La solution courante est d'utiliser la récursion :
0, 1, 1, 2, 3, 5, 8, 13, 21, 34. .. ;
5 est la somme des deux éléments précédents ->
第 35 行导入 steps_to() 的名称,以便 time.com .repeat() 知道如何调用它;
第 36 行用希望到达的楼梯数(在本例中为 30)准备对函数的调用,这是将要执行和计时的语句;
第 37 行使用设置代码和语句调用 time.repeat(),这将调用该函数 10 次,返回每次执行所需的秒数;
第 38 行标识并打印返回的最短时间。 现在再次运行脚本:
从 functools module 导入 @lru_cache 装饰器;
使用 @lru_cache 装饰 steps_to()。
hits=52 是 @lru_cache 直接从内存中返回的调用数,因为它们存在于缓存中;
misses =30 是被计算的不是来自内存的调用数,因为试图找到到达第 30 级楼梯的台阶数,所以每次调用都在第一次调用时错过了缓存是有道理的;
maxsize =16 是用装饰器的 maxsize 属性定义的缓存的大小;
currsize =16 是当前缓存的大小,在本例中它表明缓存已满。
第 6 行和第 7 行:当 feedparser 试图访问通过 HTTPS 提供的内容时,这是一个解决方案;
第 16 行:monitor() 将无限循环;
第 18 行:使用 feedparser,代码从真正的 Python 加载并解析提要;
第 20 行:循环遍历列表中的前 5 个条目;
第 21 到 31 行:如果单词 python 是标题的一部分,那么代码将连同文章的长度一起打印它;
第 33 行:代码在继续之前休眠了 5 秒钟;
第 35 行:这一行通过将 Real Python 提要的 URL 传递给 monitor() 来启动监视过程。
递归的计算简洁并且直观,但是由于存在大量重复计算,实际运行效率很低,并且会占用较多的内存。但是这里并不是需要关注的重点,只是来作为演示示例而已:
# 匿名函数 fib = lambda n: 1 if n <= 1 else fib(n-1) + fib(n-2) # 将时间复杂度降低到线性 fib = lambda n, a=1, b=1: a if n == 0 else fib(n-1, b, a+b) # 保证了匿名函数的匿名性 fib = lambda n, fib: 1 if n <= 1 else fib(n-1, fib) + fib(n-2, fib)
③ 使用 @lru_cache 缓存输出结果
使用 @lru_cache 装饰器来缓存的话,可以将函数调用结果存储在内存中,以便再次请求时直接返回结果:
from functools import lru_cache
@lru_cache
def fib(n):
if n==1 or n==2:
return 1
else:
return fib(n-1) + fib(n-2)④ 限制 @lru_cache 装饰器大小
Python 的 @lru_cache 装饰器提供了一个 maxsize 属性,该属性定义了在缓存开始淘汰旧条目之前的最大条目数,默认情况下,maxsize 设置为 128。
如果将 maxsize 设置为 None 的话,则缓存将无限期增长,并且不会驱逐任何条目。
from functools import lru_cache
@lru_cache(maxsize=16)
def fib(n):
if n==1 or n==2:
return 1
else:
return fib(n-1) + fib(n-2)# 查看缓存列表 >>> print(steps_to.cache_info()) CacheInfo(hits=52, misses=30, maxsize=16, currsize=16)
⑤ 使用 @lru_cache 实现 LRU 缓存
就像在前面实现的缓存解决方案一样,@lru_cache 在底层使用一个字典,它将函数的结果缓存在一个键下,该键包含对函数的调用,包括提供的参数。这意味着这些参数必须是可哈希的,才能让 decorator 工作。
示例:玩楼梯:
想象一下,你想通过一次跳上一个、两个或三个楼梯来确定到达楼梯中的一个特定楼梯的所有不同方式,到第四个楼梯有多少条路?所有不同的组合如下所示:
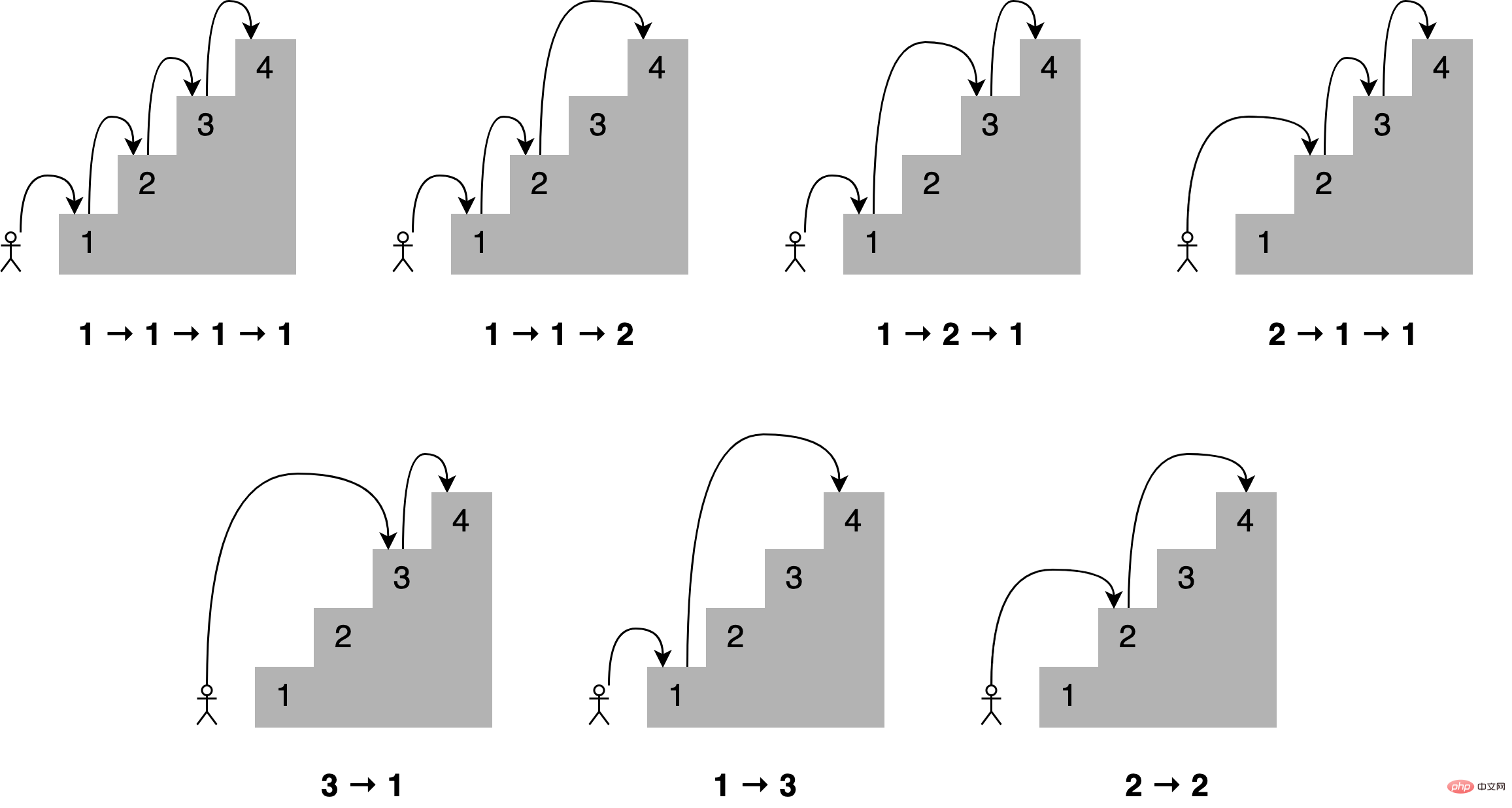
可以这样描述,为了到达当前的楼梯,你可以从下面的一个、两个或三个楼梯跳下去,将能够到达这些点的跳跃组合的数量相加,便能够获得到达当前位置的所有可能方法。
例如到达第四个楼梯的组合数量将等于你到达第三、第二和第一个楼梯的不同方式的总数。如下所示,有七种不同的方法可以到达第四层楼梯:
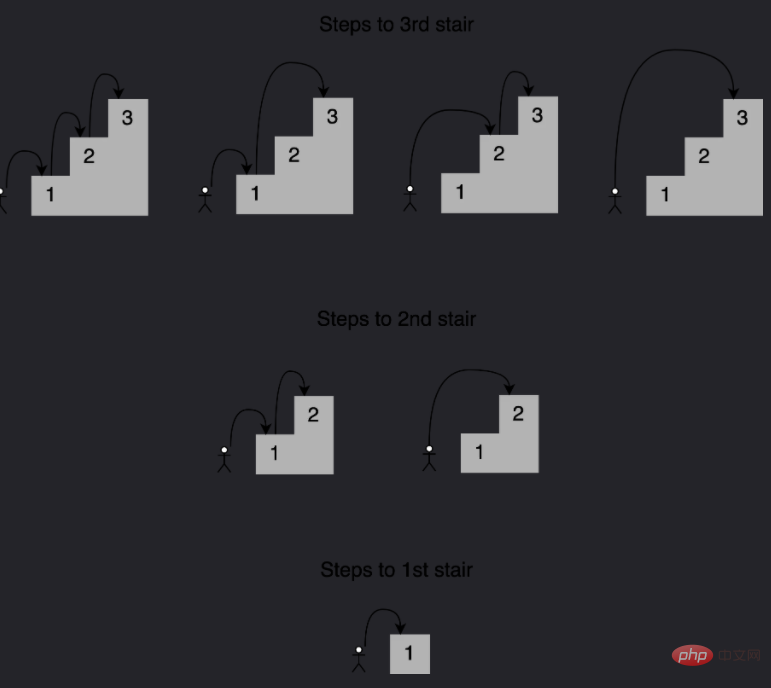
注意给定阶梯的解是如何建立在较小子问题的答案之上的,在这种情况下,为了确定到达第四个楼梯的不同路径,可以将到达第三个楼梯的四种路径、到达第二个楼梯的两种路径以及到达第一个楼梯的一种路径相加。 这种方法称为递归,下面是一个实现这个递归的函数:
def steps_to(stair):
if stair == 1:
# You can reach the first stair with only a single step
# from the floor.
return 1
elif stair == 2:
# You can reach the second stair by jumping from the
# floor with a single two-stair hop or by jumping a single
# stair a couple of times.
return 2
elif stair == 3:
# You can reach the third stair using four possible
# combinations:
# 1. Jumping all the way from the floor
# 2. Jumping two stairs, then one
# 3. Jumping one stair, then two
# 4. Jumping one stair three times
return 4
else:
# You can reach your current stair from three different places:
# 1. From three stairs down
# 2. From two stairs down
# 2. From one stair down
#
# If you add up the number of ways of getting to those
# those three positions, then you should have your solution.
return (
steps_to(stair - 3)
+ steps_to(stair - 2)
+ steps_to(stair - 1)
)
print(steps_to(4))将此代码保存到一个名为 stairs.py 的文件中,并使用以下命令运行它:
$ python stairs.py 7
太棒了,这个代码适用于 4 个楼梯,但是数一下要走多少步才能到达楼梯上更高的地方呢?将第 33 行中的楼梯数更改为 30,并重新运行脚本:
$ python stairs.py 53798080
可以看到结果超过 5300 万个组合,这可真的有点多。
时间代码:
当找到第 30 个楼梯的解决方案时,脚本花了相当多的时间来完成。要获得基线,可以度量代码运行的时间,要做到这一点,可以使用 Python 的 timeit module,在第 33 行之后添加以下代码:
setup_code = "from __main__ import steps_to"
36stmt = "steps_to(30)"
37times = repeat(setup=setup_code, stmt=stmt, repeat=3, number=10)
38print(f"Minimum execution time: {min(times)}")还需要在代码的顶部导入 timeit module:
from timeit import repeat
以下是对这些新增内容的逐行解释:
$ python stairs.py 53798080 Minimum execution time: 40.014977024000004
可以看到的秒数取决于特定硬件,在我的系统上,脚本花了 40 秒,这对于 30 级楼梯来说是相当慢的。
使用记忆来改进解决方案:
这种递归实现通过将其分解为相互构建的更小的步骤来解决这个问题,如下所示是一个树,其中每个节点表示对 steps_to() 的特定调用:
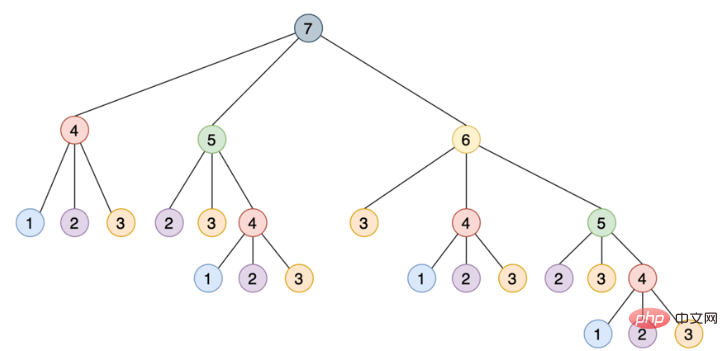
注意需要如何使用相同的参数多次调用 steps_to(),例如 steps_to(5) 计算两次,steps_to(4) 计算四次,steps_to(3) 计算七次,steps_to(2) 计算六次,多次调用同一个函数会增加不必要的计算周期,结果总是相同的。
为了解决这个问题,可以使用一种叫做记忆的技术,这种方法将函数的结果存储在内存中,然后在需要时引用它,从而确保函数不会为相同的输入运行多次,这个场景听起来像是使用 Python 的 @lru_cache 装饰器的绝佳机会。
只要做两个改变,就可以大大提高算法的运行时间:
下面是两个更新后的脚本顶部的样子:
from functools import lru_cache from timeit import repeat @lru_cache def steps_to(stair): if stair == 1:
运行更新后的脚本产生如下结果:
$ python stairs.py 53798080 Minimum execution time: 7.999999999987184e-07
缓存函数的结果会将运行时从 40 秒降低到 0.0008 毫秒,这是一个了不起的进步。@lru_cache 装饰器存储了每个不同输入的 steps_to() 的结果,每次代码调用带有相同参数的函数时,它都直接从内存中返回正确的结果,而不是重新计算一遍答案,这解释了使用 @lru_cache 时性能的巨大提升。
⑥ 解包 @lru_cache 的功能
有了@lru_cache 装饰器,就可以将每个调用和应答存储在内存中,以便以后再次请求时进行访问,但是在内存耗尽之前,可以节省多少次调用呢?
Python 的 @lru_cache 装饰器提供了一个 maxsize 属性,它定义了在缓存开始清除旧条目之前的最大条目数,缺省情况下,maxsize 设置为 128,如果将 maxsize 设置为 None,那么缓存将无限增长,并且不会驱逐任何条目。如果在内存中存储大量不同的调用,这可能会成为一个问题。
如下是 @lru_cache 使用 maxsize 属性:
from functools import lru_cache
from timeit import repeat
@lru_cache(maxsize=16)
def steps_to(stair):
if stair == 1:在本例中,将缓存限制为最多 16 个条目,当一个新调用传入时,decorator 的实现将会从现有的 16 个条目中删除最近最少使用的条目,为新条目腾出位置。
要查看添加到代码中的新内容会发生什么,可以使用 @lru_cache 装饰器提供的 cache_info() 来检查命中和未命中的次数以及当前缓存的大小。为了清晰起见,删除乘以函数运行时的代码,以下是修改后的最终脚本:
from functools import lru_cache
from timeit import repeat
@lru_cache(maxsize=16)
def steps_to(stair):
if stair == 1:
# You can reach the first stair with only a single step
# from the floor.
return 1
elif stair == 2:
# You can reach the second stair by jumping from the
# floor with a single two-stair hop or by jumping a single
# stair a couple of times.
return 2
elif stair == 3:
# You can reach the third stair using four possible
# combinations:
# 1. Jumping all the way from the floor
# 2. Jumping two stairs, then one
# 3. Jumping one stair, then two
# 4. Jumping one stair three times
return 4
else:
# You can reach your current stair from three different places:
# 1. From three stairs down
# 2. From two stairs down
# 2. From one stair down
#
# If you add up the number of ways of getting to those
# those three positions, then you should have your solution.
return (
steps_to(stair - 3)
+ steps_to(stair - 2)
+ steps_to(stair - 1)
)
print(steps_to(30))
print(steps_to.cache_info())如果再次调用脚本,可以看到如下结果:
$ python stairs.py 53798080 CacheInfo(hits=52, misses=30, maxsize=16, currsize=16)
可以使用 cache_info() 返回的信息来了解缓存是如何执行的,并对其进行微调,以找到速度和存储之间的适当平衡。下面是 cache_info() 提供的属性的详细说明:
如果需要从缓存中删除所有条目,那么可以使用 @lru_cache 提供的 cache_clear()。
四、添加缓存过期
假设想要开发一个脚本来监视 Real Python 并在任何包含单词 Python 的文章中打印字符数。真正的 Python 提供了一个 Atom feed,因此可以使用 feedparser 库来解析提要,并使用请求库来加载本文的内容。
如下是监控脚本的实现:
import feedparser
import requests
import ssl
import time
if hasattr(ssl, "_create_unverified_context"):
ssl._create_default_https_context = ssl._create_unverified_context
def get_article_from_server(url):
print("Fetching article from server...")
response = requests.get(url)
return response.text
def monitor(url):
maxlen = 45
while True:
print("\nChecking feed...")
feed = feedparser.parse(url)
for entry in feed.entries[:5]:
if "python" in entry.title.lower():
truncated_title = (
entry.title[:maxlen] + "..."
if len(entry.title) > maxlen
else entry.title
)
print(
"Match found:",
truncated_title,
len(get_article_from_server(entry.link)),
)
time.sleep(5)
monitor("https://realpython.com/atom.xml")将此脚本保存到一个名为 monitor.py 的文件中,安装 feedparser 和请求库,然后运行该脚本,它将持续运行,直到在终端窗口中按 Ctrl+C 停止它:
$ pip install feedparser requests $ python monitor.py Checking feed... Fetching article from server... The Real Python Podcast – Episode #28: Using ... 29520 Fetching article from server... Python Community Interview With David Amos 54256 Fetching article from server... Working With Linked Lists in Python 37099 Fetching article from server... Python Practice Problems: Get Ready for Your ... 164888 Fetching article from server... The Real Python Podcast – Episode #27: Prepar... 30784 Checking feed... Fetching article from server... The Real Python Podcast – Episode #28: Using ... 29520 Fetching article from server... Python Community Interview With David Amos 54256 Fetching article from server... Working With Linked Lists in Python 37099 Fetching article from server... Python Practice Problems: Get Ready for Your ... 164888 Fetching article from server... The Real Python Podcast – Episode #27: Prepar... 30784
代码解释:
每当脚本加载一篇文章时,“Fetching article from server…”的消息就会打印到控制台,如果让脚本运行足够长的时间,那么将看到这条消息是如何反复显示的,即使在加载相同的链接时也是如此。
这是一个很好的机会来缓存文章的内容,并避免每五秒钟访问一次网络,可以使用 @lru_cache 装饰器,但是如果文章的内容被更新,会发生什么呢?第一次访问文章时,装饰器将存储文章的内容,并在以后每次返回相同的数据;如果更新了帖子,那么监视器脚本将永远无法实现它,因为它将提取存储在缓存中的旧副本。要解决这个问题,可以将缓存条目设置为过期。
from functools import lru_cache, wraps
from datetime import datetime, timedelta
def timed_lru_cache(seconds: int, maxsize: int = 128):
def wrapper_cache(func):
func = lru_cache(maxsize=maxsize)(func)
func.lifetime = timedelta(seconds=seconds)
func.expiration = datetime.utcnow() + func.lifetime
@wraps(func)
def wrapped_func(*args, **kwargs):
if datetime.utcnow() >= func.expiration:
func.cache_clear()
func.expiration = datetime.utcnow() + func.lifetime
return func(*args, **kwargs)
return wrapped_func
return wrapper_cache
@timed_lru_cache(10)
def get_article_from_server(url):
...代码解释:
第 4 行:@timed_lru_cache 装饰器将支持缓存中条目的生命周期(以秒为单位)和缓存的最大大小;
第 6 行:代码用 lru_cache 装饰器包装了装饰函数,这允许使用 lru_cache 已经提供的缓存功能;
第 7 行和第 8 行:这两行用两个表示缓存生命周期和它将过期的实际日期的属性来修饰函数;
第 12 到 14 行:在访问缓存中的条目之前,装饰器检查当前日期是否超过了过期日期,如果是这种情况,那么它将清除缓存并重新计算生存期和过期日期。
请注意,当条目过期时,此装饰器如何清除与该函数关联的整个缓存,生存期适用于整个缓存,而不适用于单个项目,此策略的更复杂实现将根据条目的单个生存期将其逐出。
在程序中,如果想要实现不同缓存策略,可以查看 cachetools 这个库,该库提供了几个集合和修饰符,涵盖了一些最流行的缓存策略。
使用新装饰器缓存文章:
现在可以将新的 @timed_lru_cache 装饰器与监视器脚本一起使用,以防止每次访问时获取文章的内容。为了简单起见,把代码放在一个脚本中,可以得到以下结果:
import feedparser
import requests
import ssl
import time
from functools import lru_cache, wraps
from datetime import datetime, timedelta
if hasattr(ssl, "_create_unverified_context"):
ssl._create_default_https_context = ssl._create_unverified_context
def timed_lru_cache(seconds: int, maxsize: int = 128):
def wrapper_cache(func):
func = lru_cache(maxsize=maxsize)(func)
func.lifetime = timedelta(seconds=seconds)
func.expiration = datetime.utcnow() + func.lifetime
@wraps(func)
def wrapped_func(*args, **kwargs):
if datetime.utcnow() >= func.expiration:
func.cache_clear()
func.expiration = datetime.utcnow() + func.lifetime
return func(*args, **kwargs)
return wrapped_func
return wrapper_cache
@timed_lru_cache(10)
def get_article_from_server(url):
print("Fetching article from server...")
response = requests.get(url)
return response.text
def monitor(url):
maxlen = 45
while True:
print("\nChecking feed...")
feed = feedparser.parse(url)
for entry in feed.entries[:5]:
if "python" in entry.title.lower():
truncated_title = (
entry.title[:maxlen] + "..."
if len(entry.title) > maxlen
else entry.title
)
print(
"Match found:",
truncated_title,
len(get_article_from_server(entry.link)),
)
time.sleep(5)
monitor("https://realpython.com/atom.xml")请注意第 30 行如何使用 @timed_lru_cache 装饰 get_article_from_server() 并指定 10 秒的有效性。在获取文章后的 10 秒内,任何试图从服务器访问同一篇文章的尝试都将从缓存中返回内容,而不会到达网络。
运行脚本并查看结果:
$ python monitor.py Checking feed... Fetching article from server... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Fetching article from server... Match found: Python Community Interview With David Amos 54254 Fetching article from server... Match found: Working With Linked Lists in Python 37100 Fetching article from server... Match found: Python Practice Problems: Get Ready for Your ... 164887 Fetching article from server... Match found: The Real Python Podcast – Episode #27: Prepar... 30783 Checking feed... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Match found: Python Community Interview With David Amos 54254 Match found: Working With Linked Lists in Python 37100 Match found: Python Practice Problems: Get Ready for Your ... 164887 Match found: The Real Python Podcast – Episode #27: Prepar... 30783 Checking feed... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Match found: Python Community Interview With David Amos 54254 Match found: Working With Linked Lists in Python 37100 Match found: Python Practice Problems: Get Ready for Your ... 164887 Match found: The Real Python Podcast – Episode #27: Prepar... 30783 Checking feed... Fetching article from server... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Fetching article from server... Match found: Python Community Interview With David Amos 54254 Fetching article from server... Match found: Working With Linked Lists in Python 37099 Fetching article from server... Match found: Python Practice Problems: Get Ready for Your ... 164888 Fetching article from server... Match found: The Real Python Podcast – Episode #27: Prepar... 30783
请注意,代码在第一次访问匹配的文章时是如何打印“Fetching article from server…”这条消息的。之后,根据网络速度和计算能力,脚本将从缓存中检索文章一两次,然后再次访问服务器。
该脚本试图每 5 秒访问这些文章,缓存每 10 秒过期一次。对于实际的应用程序来说,这些时间可能太短,因此可以通过调整这些配置来获得显著的改进。
五、@lru_cache 装饰器的官方实现
简单理解,其实就是一个装饰器:
def lru_cache(maxsize=128, typed=False):
if isinstance(maxsize, int):
if maxsize < 0:
maxsize = 0
elif callable(maxsize) and isinstance(typed, bool):
user_function, maxsize = maxsize, 128
wrapper = _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo)
return update_wrapper(wrapper, user_function)
elif maxsize is not None:
raise TypeError('Expected first argument to be an integer, a callable, or None')
def decorating_function(user_function):
wrapper = _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo)
return update_wrapper(wrapper, user_function)
return decorating_function_CacheInfo = namedtuple("CacheInfo", ["hits", "misses", "maxsize", "currsize"])
def _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo):
sentinel = object() # unique object used to signal cache misses
make_key = _make_key # build a key from the function arguments
PREV, NEXT, KEY, RESULT = 0, 1, 2, 3 # names for the link fields
cache = {} # 存储也使用的字典
hits = misses = 0
full = False
cache_get = cache.get
cache_len = cache.__len__
lock = RLock() # 因为双向链表的更新不是线程安全的所以需要加锁
root = [] # 双向链表
root[:] = [root, root, None, None] # 初始化双向链表
if maxsize == 0:
def wrapper(*args, **kwds):
# No caching -- just a statistics update
nonlocal misses
misses += 1
result = user_function(*args, **kwds)
return result
elif maxsize is None:
def wrapper(*args, **kwds):
# Simple caching without ordering or size limit
nonlocal hits, misses
key = make_key(args, kwds, typed)
result = cache_get(key, sentinel)
if result is not sentinel:
hits += 1
return result
misses += 1
result = user_function(*args, **kwds)
cache[key] = result
return result
else:
def wrapper(*args, **kwds):
# Size limited caching that tracks accesses by recency
nonlocal root, hits, misses, full
key = make_key(args, kwds, typed)
with lock:
link = cache_get(key)
if link is not None:
# Move the link to the front of the circular queue
link_prev, link_next, _key, result = link
link_prev[NEXT] = link_next
link_next[PREV] = link_prev
last = root[PREV]
last[NEXT] = root[PREV] = link
link[PREV] = last
link[NEXT] = root
hits += 1
return result
misses += 1
result = user_function(*args, **kwds)
with lock:
if key in cache:
pass
elif full:
oldroot = root
oldroot[KEY] = key
oldroot[RESULT] = result
root = oldroot[NEXT]
oldkey = root[KEY]
oldresult = root[RESULT]
root[KEY] = root[RESULT] = None
del cache[oldkey]
cache[key] = oldroot
else:
last = root[PREV]
link = [last, root, key, result]
last[NEXT] = root[PREV] = cache[key] = link
full = (cache_len() >= maxsize)
return result
def cache_info():
"""Report cache statistics"""
with lock:
return _CacheInfo(hits, misses, maxsize, cache_len())
def cache_clear():
"""Clear the cache and cache statistics"""
nonlocal hits, misses, full
with lock:
cache.clear()
root[:] = [root, root, None, None]
hits = misses = 0
full = False
wrapper.cache_info = cache_info
wrapper.cache_clear = cache_clear
return wrapperCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution
Apr 08, 2025 am 11:21 AM
Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution
Apr 08, 2025 am 11:21 AM
Le fichier de téléchargement mysql est corrompu, que dois-je faire? Hélas, si vous téléchargez MySQL, vous pouvez rencontrer la corruption des fichiers. Ce n'est vraiment pas facile ces jours-ci! Cet article expliquera comment résoudre ce problème afin que tout le monde puisse éviter les détours. Après l'avoir lu, vous pouvez non seulement réparer le package d'installation MySQL endommagé, mais aussi avoir une compréhension plus approfondie du processus de téléchargement et d'installation pour éviter de rester coincé à l'avenir. Parlons d'abord de la raison pour laquelle le téléchargement des fichiers est endommagé. Il y a de nombreuses raisons à cela. Les problèmes de réseau sont le coupable. L'interruption du processus de téléchargement et l'instabilité du réseau peut conduire à la corruption des fichiers. Il y a aussi le problème avec la source de téléchargement elle-même. Le fichier serveur lui-même est cassé, et bien sûr, il est également cassé si vous le téléchargez. De plus, la numérisation excessive "passionnée" de certains logiciels antivirus peut également entraîner une corruption des fichiers. Problème de diagnostic: déterminer si le fichier est vraiment corrompu
 MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL peut s'exécuter sans connexions réseau pour le stockage et la gestion des données de base. Cependant, la connexion réseau est requise pour l'interaction avec d'autres systèmes, l'accès à distance ou l'utilisation de fonctionnalités avancées telles que la réplication et le clustering. De plus, les mesures de sécurité (telles que les pare-feu), l'optimisation des performances (choisissez la bonne connexion réseau) et la sauvegarde des données sont essentielles pour se connecter à Internet.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
MySQL a refusé de commencer? Ne paniquez pas, vérifions-le! De nombreux amis ont découvert que le service ne pouvait pas être démarré après avoir installé MySQL, et ils étaient si anxieux! Ne vous inquiétez pas, cet article vous emmènera pour le faire face calmement et découvrez le cerveau derrière! Après l'avoir lu, vous pouvez non seulement résoudre ce problème, mais aussi améliorer votre compréhension des services MySQL et vos idées de problèmes de dépannage, et devenir un administrateur de base de données plus puissant! Le service MySQL n'a pas réussi et il y a de nombreuses raisons, allant des erreurs de configuration simples aux problèmes système complexes. Commençons par les aspects les plus courants. Connaissances de base: une brève description du processus de démarrage du service MySQL Service Startup. Autrement dit, le système d'exploitation charge les fichiers liés à MySQL, puis démarre le démon mysql. Cela implique la configuration
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
