
 Opération et maintenance
Nginx
Comment optimiser Nginx et Node.js pour les réseaux à forte charge
Opération et maintenance
Nginx
Comment optimiser Nginx et Node.js pour les réseaux à forte charge
Comment optimiser Nginx et Node.js pour les réseaux à forte charge

Réglage du réseau
Si vous ne comprenez pas d'abord les mécanismes de transmission sous-jacents de nginx et node.js et n'effectuez pas une optimisation ciblée, aussi détaillée que soit l'optimisation des deux, ce sera en vain. Normalement, nginx connecte le client et les applications en amont via le socket TCP.
Notre système a de nombreux seuils et restrictions pour TCP, qui sont définis via les paramètres du noyau. Les valeurs par défaut de ces paramètres sont souvent définies à des fins générales et ne peuvent pas répondre aux exigences de trafic élevé et de courte durée de vie des serveurs Web.
Voici quelques paramètres qui peuvent être utilisés comme candidats pour le réglage de TCP. Pour les rendre efficaces, vous pouvez les placer dans le fichier /etc/sysctl.conf ou les placer dans un nouveau fichier de configuration, tel que /etc/sysctl.d/99-tuning.conf, puis exécuter sysctl -p pour laissez le noyau les charger. Nous utilisons sysctl-cookbook pour effectuer ce travail physique.
Il convient de noter que les valeurs répertoriées ici sont sûres à utiliser, mais il est tout de même recommandé d'étudier la signification de chaque paramètre afin de choisir une valeur plus appropriée en fonction de votre charge, de votre matériel et de votre utilisation.
Copier le code Le code est le suivant :
net.ipv4 .tcp_tw_reuse='1'
net.ipv4.tcp_fin_timeout='15'
net.core.netdev_max_backlog='4096'
net.core.rmem_max='16777216'
net.core.somaxconn='4096'
net.core .wmem_max='16777216'
net.ipv4.tcp_max_syn_backlog='20480'
net.ipv4.tcp_max_tw_buckets='400000'
net.ipv4.tcp_no_metrics_save='1'
net.ipv4.tcp_rmem=' 40 96 87380 span>
Soulignez-en quelques-uns. Un important.
net.ipv4.ip_local_port_range
net.ipv4.tcp_tw_reuseLorsque le serveur doit basculer entre un grand nombre de connexions TCP, un grand nombre de connexions dans l'état time_wait seront générées. time_wait signifie que la connexion elle-même est fermée, mais que les ressources n'ont pas été libérées. Définir net_ipv4_tcp_tw_reuse sur 1 permet au noyau d'essayer de recycler les connexions lorsque cela est sûr, ce qui est beaucoup moins cher que de rétablir de nouvelles connexions. net.ipv4.tcp_fin_timeout
Il s'agit du temps minimum qu'une connexion dans l'état time_wait doit attendre avant de recycler. Le rendre plus petit peut accélérer le recyclage.
Comment vérifier l'état de la connexion
Utilisez netstat:
netstat -tan | awk '{print $6}' | (noyau 541)
tcp : 47461 (estab 311, fermé 47135, orphelin 4, synrecv 0, timewait 47135/0), ports 33938transport total ip ipv6
* 541 - -raw 0 0 0
udp 13 10 3
tcp 326 325 1
inet 339 335 4
frag 0 0 0
À mesure que la charge sur le serveur Web augmente progressivement, nous commencerons à rencontrer d'étranges limitations de nginx. La connexion est interrompue et le noyau continue de signaler une inondation de synchronisation. À l'heure actuelle, la charge moyenne et l'utilisation du processeur sont très faibles, et le serveur peut évidemment gérer plus de connexions, ce qui est vraiment frustrant.
Après enquête, nous avons constaté qu'il existe de nombreuses connexions dans l'état time_wait. Voici le résultat de l'un des serveurs :
Il y a 47 135 connexions time_wait ! De plus, on peut voir d'après ss qu'il s'agit toutes de connexions fermées. Cela indique que le serveur a consommé la plupart des ports disponibles et implique également que le serveur alloue de nouveaux ports pour chaque connexion. Le réglage du réseau a quelque peu aidé à résoudre le problème, mais il n'y avait toujours pas assez de ports.
Après des recherches plus approfondies, j'ai trouvé un document sur la directive keepalive de connexion en amont, qui dit :
Définissez le nombre maximum de connexions keepalive inactives au serveur en amont. Ces connexions seront conservées dans le cache du processus de travail.
Intéressant. En théorie, cette configuration minimise le gaspillage de connexions en transmettant les requêtes via les connexions mises en cache. La documentation mentionne également que nous devons définir proxy_http_version sur "1.1" et effacer l'en-tête "connection". Après des recherches plus approfondies, j'ai trouvé que c'était une bonne idée, car http/1.1 optimise considérablement l'utilisation des connexions TCP par rapport à http1.0 et nginx utilise http/1.0 par défaut.
Après modification comme suggéré dans le document, notre fichier de configuration de liaison montante devient comme ceci :
Copiez le code Le code est le suivant :
upstream backend_nodejs {
server nodejs-3:5016 max_fails=0 fail_timeout=10s;
server nodejs-4:5016 max_fails=0 fail_timeout=10s;
server nodejs-5:5016 max_fails=0 fail_timeout=10s;
server nodejs- 6:5016 max_fails=0 fail_timeout=10s;
keepalive 512;
}
J'ai également modifié les paramètres proxy dans la section serveur comme suggéré. Dans le même temps, un proxy_next_upstream a été ajouté pour ignorer les serveurs défaillants, le keepalive_timeout du client a été ajusté et le journal d'accès a été désactivé. La configuration devient comme ceci :
Copier le code Le code est le suivant :
server {
listen 80;
server_name fast.gosquared.com;
client_max_body_size 16m;
keepalive_timeout 10;
location / {
proxy_next_upstream error timeout http_500 http_50 2 http_503 http_504;
proxy_set_header connection "";
proxy_http_version 1.1;
proxy_pass http://backend_nodejs;
}
access_log off;
error_log /dev/null crit;
}
Après avoir adopté la nouvelle configuration, j'ai trouvé que les sockets occupés par les serveurs ont diminué de 90%. Les requêtes peuvent désormais être transmises en utilisant beaucoup moins de connexions. La nouvelle sortie est la suivante :
ss -s
total : 558 (noyau 604)
tcp : 4675 (estab 485, fermé 4183, orphelin 0, synrecv 0, timewait 4183/0), ports 2768
transport total ip ipv6
* 604 - -
raw 0 0 0
udp 13 10 3
tcp 492 491 1
inet 505 501 4
node.js
Grâce à la conception basée sur les événements qui peut gérer les E/S de manière asynchrone, node.js peut gérer de grandes montants de connexions et de demandes prêtes à l'emploi. Bien qu'il existe d'autres méthodes de réglage, cet article se concentrera principalement sur l'aspect processus de node.js.
Le nœud est monothread et n'utilisera pas automatiquement plusieurs cœurs. En d’autres termes, l’application ne peut pas obtenir automatiquement toutes les capacités du serveur.
Réalisation du clustering des processus de nœuds
Nous pouvons modifier l'application afin qu'elle crée plusieurs threads et reçoive des données sur le même port, permettant ainsi à la charge de s'étendre sur plusieurs cœurs. Node dispose d'un module de cluster qui fournit tous les outils nécessaires pour atteindre cet objectif, mais les ajouter à l'application nécessite beaucoup de travail manuel. Si vous utilisez Express, eBay dispose d'un module appelé cluster2 qui peut être utilisé.
Empêcher le changement de contexte
Lors de l'exécution de plusieurs processus, vous devez vous assurer que chaque cœur de processeur n'est occupé que par un seul processus à la fois. De manière générale, si le processeur possède n cœurs, nous devrions générer n-1 processus d’application. Cela garantit que chaque processus bénéficie d'une tranche de temps raisonnable, laissant un cœur libre pour que le planificateur du noyau puisse exécuter d'autres tâches. Nous devons également nous assurer qu'aucune autre tâche autre que node.js n'est exécutée sur le serveur pour éviter les conflits de processeur.
Nous avons déjà commis une erreur et déployé deux applications node.js sur le serveur, puis chaque application a ouvert n-1 processus. En conséquence, ils se disputent le processeur, ce qui entraîne une forte augmentation de la charge du système. Bien que nos serveurs soient tous des machines à 8 cœurs, la surcharge de performances causée par le changement de contexte peut toujours être clairement ressentie. Le changement de contexte fait référence au phénomène selon lequel le processeur suspend la tâche en cours afin d'effectuer d'autres tâches. Sur un commutateur, le noyau doit suspendre tous les états du processus en cours, puis charger et exécuter un autre processus. Afin de résoudre ce problème, nous avons réduit le nombre de processus démarrés par chaque application et leur avons permis de partager équitablement le processeur. En conséquence, la charge du système a diminué : 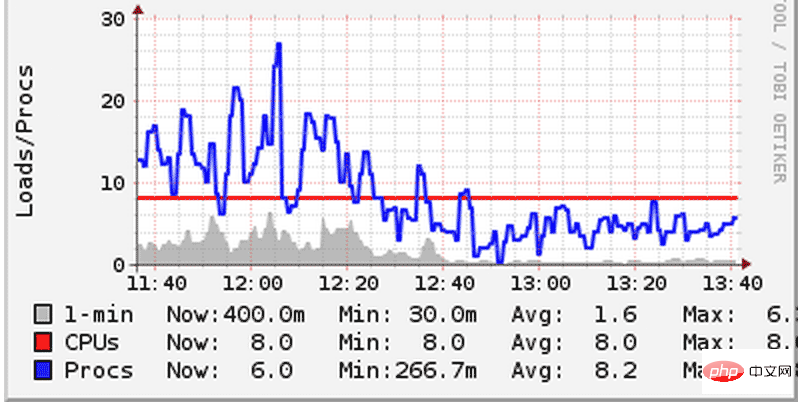
Veuillez prêter attention à l'image ci-dessus pour voir comment le système fonctionne. charge (ligne bleue) tombée en dessous du nombre de cœurs de processeur (ligne rouge). Sur d'autres serveurs, nous avons constaté la même chose. Étant donné que la charge de travail totale reste la même, les améliorations de performances dans le graphique ci-dessus ne peuvent être attribuées qu'à la réduction des changements de contexte.
Sans ordre particulier :
1. Lorsque des problèmes de performances sont rencontrés, si le calcul et le traitement peuvent être effectués au niveau de la couche application, retirez-les de la couche base de données. Le tri et le regroupement sont des exemples classiques. Il est toujours plus facile d’améliorer les performances au niveau de la couche application qu’au niveau de la couche base de données. Tout comme MySQL, SQLite est plus facile à contrôler.
2. Concernant le calcul parallèle, si vous pouvez l'éviter, essayez de l'éviter. Si cela ne peut être évité, rappelez-vous qu’un grand pouvoir implique de grandes responsabilités. Si possible, essayez d’éviter d’opérer directement sur les threads. Opérez à un niveau d’abstraction plus élevé autant que possible. Par exemple, sous iOS, les opérations GCD, de distribution et de file d'attente sont vos amis. Le cerveau humain n’est pas conçu pour analyser des états temporaires infinis – je l’ai appris à mes dépens.
3. Simplifiez l'état autant que possible et localisez-le autant que possible. L’applicabilité vient en premier.
4. Les méthodes courtes et combinables sont vos meilleures amies.
5. Les commentaires de code sont dangereux car ils peuvent facilement être obsolètes ou trompeurs, mais ce n'est pas une raison pour ne pas écrire de commentaires. Ne commentez pas des choses insignifiantes, mais si nécessaire, de longs commentaires stratégiques sont nécessaires à certains endroits particuliers. Votre mémoire vous trahira, peut-être demain matin, peut-être après une tasse de café.
6. Si vous pensez qu'un scénario d'utilisation pourrait être « correct », il se peut que vous échouiez lamentablement dans votre produit lancé un mois plus tard. Soyez sceptique, testez, vérifiez.
7. En cas de doute, parlez à toutes les personnes concernées de l'équipe.
8. Faites ce qu’il faut – vous savez généralement ce que cela signifie.
9. Vos utilisateurs ne sont pas stupides, ils n’ont tout simplement pas la patience de comprendre vos raccourcis.
10. Si un développeur n'est pas chargé de maintenir le système que vous développez pendant une longue période, méfiez-vous de lui. 80 % du sang, de la sueur et des larmes sont versés après la sortie du logiciel - vous deviendrez alors un misanthrope, mais aussi un « connaisseur » plus intelligent.
11. Les listes de tâches sont votre meilleur ami.
12. Prenez l'initiative de rendre votre travail plus amusant, cela demande parfois des efforts de votre part.
13. Des crises silencieuses dont je me réveille encore de cauchemars. Surveillance, journalisation, alerte. Soyez conscient des diverses fausses alarmes et de l’inévitable émoussement sensoriel. Gardez votre système attentif aux pannes et en temps opportun.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment autoriser l'accès au réseau externe au serveur Tomcat
Apr 21, 2024 am 07:22 AM
Comment autoriser l'accès au réseau externe au serveur Tomcat
Apr 21, 2024 am 07:22 AM
Pour permettre au serveur Tomcat d'accéder au réseau externe, vous devez : modifier le fichier de configuration Tomcat pour autoriser les connexions externes. Ajoutez une règle de pare-feu pour autoriser l'accès au port du serveur Tomcat. Créez un enregistrement DNS pointant le nom de domaine vers l'adresse IP publique du serveur Tomcat. Facultatif : utilisez un proxy inverse pour améliorer la sécurité et les performances. Facultatif : configurez HTTPS pour une sécurité accrue.
 Bienvenue sur nginx !Comment le résoudre ?
Apr 17, 2024 am 05:12 AM
Bienvenue sur nginx !Comment le résoudre ?
Apr 17, 2024 am 05:12 AM
Pour résoudre l'erreur "Bienvenue sur nginx!", vous devez vérifier la configuration de l'hôte virtuel, activer l'hôte virtuel, recharger Nginx, si le fichier de configuration de l'hôte virtuel est introuvable, créer une page par défaut et recharger Nginx, puis le message d'erreur. disparaîtra et le site Web sera affiché normalement.
 Comment générer une URL à partir d'un fichier HTML
Apr 21, 2024 pm 12:57 PM
Comment générer une URL à partir d'un fichier HTML
Apr 21, 2024 pm 12:57 PM
La conversion d'un fichier HTML en URL nécessite un serveur Web, ce qui implique les étapes suivantes : Obtenir un serveur Web. Configurez un serveur Web. Téléchargez le fichier HTML. Créez un nom de domaine. Acheminez la demande.
 Comment déployer le projet nodejs sur le serveur
Apr 21, 2024 am 04:40 AM
Comment déployer le projet nodejs sur le serveur
Apr 21, 2024 am 04:40 AM
Étapes de déploiement de serveur pour un projet Node.js : Préparez l'environnement de déploiement : obtenez l'accès au serveur, installez Node.js, configurez un référentiel Git. Créez l'application : utilisez npm run build pour générer du code et des dépendances déployables. Téléchargez le code sur le serveur : via Git ou File Transfer Protocol. Installer les dépendances : connectez-vous en SSH au serveur et installez les dépendances de l'application à l'aide de npm install. Démarrez l'application : utilisez une commande telle que node index.js pour démarrer l'application ou utilisez un gestionnaire de processus tel que pm2. Configurer un proxy inverse (facultatif) : utilisez un proxy inverse tel que Nginx ou Apache pour acheminer le trafic vers votre application
 Nodejs est-il accessible de l'extérieur ?
Apr 21, 2024 am 04:43 AM
Nodejs est-il accessible de l'extérieur ?
Apr 21, 2024 am 04:43 AM
Oui, Node.js est accessible de l’extérieur. Vous pouvez utiliser les méthodes suivantes : Utilisez Cloud Functions pour déployer la fonction et la rendre accessible au public. Utilisez le framework Express pour créer des itinéraires et définir des points de terminaison. Utilisez Nginx pour inverser les requêtes de proxy vers les applications Node.js. Utilisez des conteneurs Docker pour exécuter des applications Node.js et les exposer via le mappage de ports.
 Comment déployer et maintenir un site Web en utilisant PHP
May 03, 2024 am 08:54 AM
Comment déployer et maintenir un site Web en utilisant PHP
May 03, 2024 am 08:54 AM
Pour déployer et maintenir avec succès un site Web PHP, vous devez effectuer les étapes suivantes : Sélectionnez un serveur Web (tel qu'Apache ou Nginx) Installez PHP Créez une base de données et connectez PHP Téléchargez le code sur le serveur Configurez le nom de domaine et la maintenance du site Web de surveillance DNS les étapes comprennent la mise à jour de PHP et des serveurs Web, la sauvegarde du site Web, la surveillance des journaux d'erreurs et la mise à jour du contenu.
 Comment utiliser Fail2Ban pour protéger votre serveur contre les attaques par force brute
Apr 27, 2024 am 08:34 AM
Comment utiliser Fail2Ban pour protéger votre serveur contre les attaques par force brute
Apr 27, 2024 am 08:34 AM
Une tâche importante pour les administrateurs Linux est de protéger le serveur contre les attaques ou les accès illégaux. Par défaut, les systèmes Linux sont livrés avec des pare-feu bien configurés, tels que iptables, Uncomplicated Firewall (UFW), ConfigServerSecurityFirewall (CSF), etc., qui peuvent empêcher diverses attaques. Toute machine connectée à Internet est une cible potentielle d'attaques malveillantes. Il existe un outil appelé Fail2Ban qui peut être utilisé pour atténuer les accès illégaux sur le serveur. Qu’est-ce que Fail2Ban ? Fail2Ban[1] est un logiciel de prévention des intrusions qui protège les serveurs des attaques par force brute. Il est écrit en langage de programmation Python
 Venez avec moi apprendre Linux et installer Nginx
Apr 28, 2024 pm 03:10 PM
Venez avec moi apprendre Linux et installer Nginx
Apr 28, 2024 pm 03:10 PM
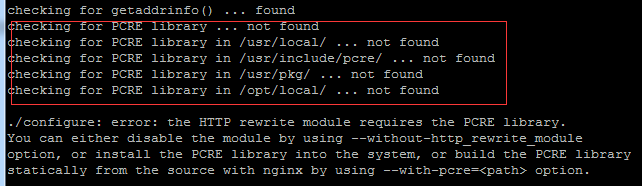
Aujourd'hui, je vais vous amener à installer Nginx dans l'environnement Linux. Le système Linux utilisé ici est CentOS7.2 Préparez les outils d'installation 1. Téléchargez Nginx depuis le site officiel de Nginx. La version utilisée ici est : 1.13.6.2 Téléchargez le Nginx téléchargé sur Linux Ici, le répertoire /opt/nginx est utilisé comme exemple. Exécutez "tar-zxvfnginx-1.13.6.tar.gz" pour décompresser. 3. Basculez vers le répertoire /opt/nginx/nginx-1.13.6 et exécutez ./configure pour la configuration initiale. Si l'invite suivante apparaît, cela signifie que PCRE n'est pas installé sur la machine et que Nginx doit
