

La bibliothèque nécessaire au nettoyage des données ici est la bibliothèque pandas. La méthode de téléchargement est toujours en cours d'exécution dans le terminal : pip install pandas.
Nous devons d'abord lire les données
import pandas as pd data = pd.read_csv(r'E:\PYthon\用户价值分析 RFM模型\data.csv') pd.set_option('display.max_columns', 888) # 大于总列数 pd.set_option('display.width', 1000) print(data.head()) print(data.info())
La troisième ligne consiste à lire les données, à l'intérieur du fichier. bibliothèque pandas Appelez simplement la fonction read Le format csv est le plus rapide en lecture et en écriture.
Les lignes 4 et 5 doivent afficher toutes les colonnes pour une lecture en temps réel. S'il y a beaucoup de colonnes, pycharm masquera certaines des colonnes du milieu, nous ajoutons donc ces deux lignes de code pour éviter qu'elles ne soient masquées.
La 6ème ligne montre l'en-tête du tableau. Nous pouvons voir quels sont les champs et les noms des colonnes.
La 7ème ligne montre les informations de base du tableau, la quantité de données contenues dans chaque colonne et le type de données du champ. . Combien de données non vides y a-t-il, donc dans la première étape, nous pouvons voir quelle colonne de base a une valeur nulle.
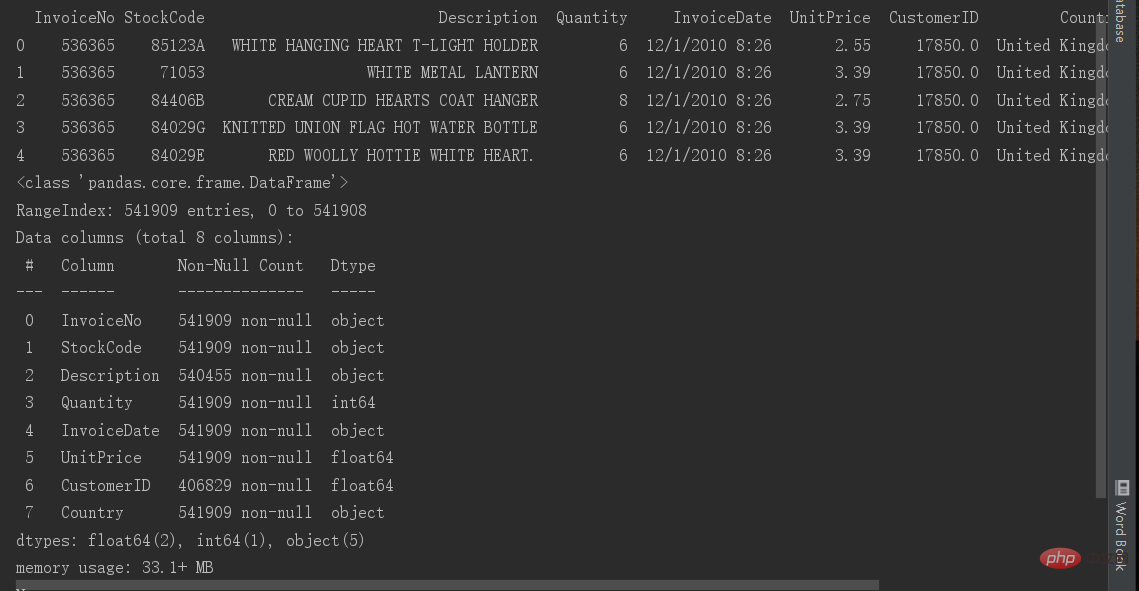
data.info() nous pouvons voir que la plupart des données comportent 541909 lignes, nous devinons donc à peu près qu'il manque des résultats dans les colonnes Description et CustomerID
# 空值处理 print(data.isnull().sum()) # 空值中和,查看每一列的空值 # 空值删除 data.drop(columns=['Description'], inplace=True) print(data.info()) data.isnull()判断是否为空。data.isnumll().sum()计算空值数量。
La 5ème ligne effectue la suppression des valeurs nulles, ici supprimez d'abord la valeur nulle de la colonne Description inplace=True signifie modifier les données. S'il n'y a pas de inplace=True, les données imprimées resteront les mêmes qu'avant. , ou une variable sera redéfinie pour l'affectation.
Comme il y a relativement peu de valeurs nulles dans cette colonne, cette colonne de données n'est pas si importante pour notre analyse de données, nous choisissons donc de supprimer toute cette colonne.
Notre table est utilisée pour filtrer les clients, donc en fonction de l'ID client, les autres colonnes sont supprimées de force
# CustomerID有空值 # 删除所有列的空值 data.dropna(inplace=True) # print(data.info()) print(data.isnull().sum()) # 由于CustomerID为必须字段,所以强制删除其他列,以CustomerID为准
Ici, nous effectuons d'abord la conversion de type sur d'autres champs
Conversion de type
# 转换为日期类型 data['InvoiceDate'] = pd.to_datetime(data['InvoiceDate']) # CustomerID 转换为整型 data['CustomerID'] = data['CustomerID'].astype('int') print(data.info())
Nous avons traité des valeurs nulles ci-dessus , Nous traitons ensuite des valeurs aberrantes.
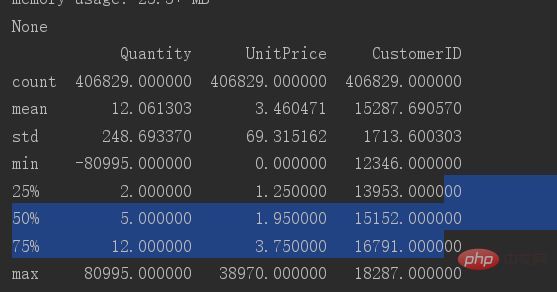
Pour afficher la distribution des données de base du tableau, vous pouvez utiliser décrire
print(data.describe())
Vous pouvez voir que la valeur minimale dans la colonne Quantité de données est -80995. Cette colonne a évidemment des valeurs aberrantes, donc cette colonne doit le faire. être filtré pour les valeurs aberrantes.
Seules les valeurs supérieures à 0 sont obligatoires.
data = data[data['Quantity'] > 0] print(data)
Une fois imprimé, il n'y a que 397924 lignes.
# 查看重复值 print(data[data.duplicated()])
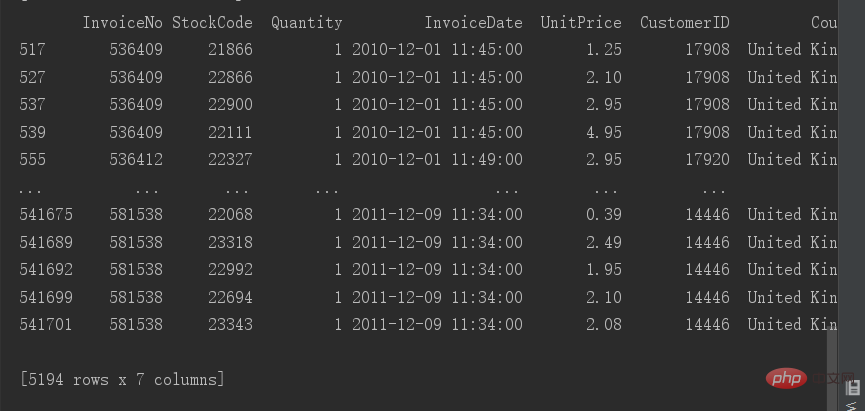
Il y a 5194 lignes de valeurs en double ici sont complètement dupliquées, nous pouvons donc les supprimer en tant que données inutiles.
# 删除重复值 data.drop_duplicates(inplace=True) print(data.info())
Enregistrez la table d'origine après la suppression, puis vérifiez les informations de base de la table
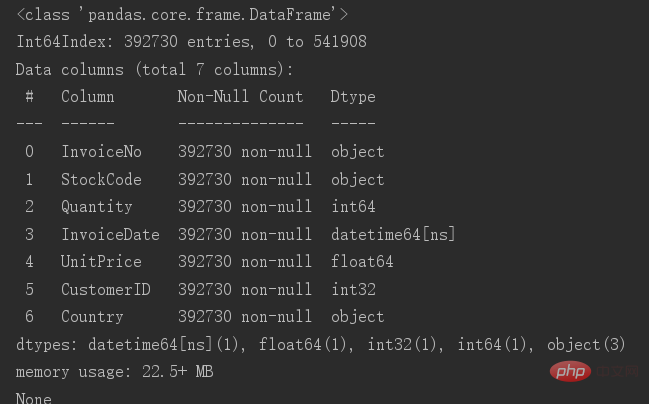
Il reste maintenant 392730 éléments de données. A cette étape, le nettoyage des données est terminé.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



