
 Opération et maintenance
exploitation et maintenance Linux
Comment utiliser la commande gratuite sous Linux
Opération et maintenance
exploitation et maintenance Linux
Comment utiliser la commande gratuite sous Linux
Comment utiliser la commande gratuite sous Linux

Sous Linux, free est une commande intégrée pour afficher l'état d'utilisation de la mémoire. Elle peut afficher l'utilisation de la mémoire physique du système, de la mémoire virtuelle (partition swap), de la mémoire partagée et du cache système. [option]" ; La sortie de la commande free est très similaire à la partie mémoire de la commande top.
Commande gratuite Linux : Vérifiez l'état d'utilisation de la mémoire
La commande gratuite est utilisée pour afficher l'état de la mémoire système, y compris l'utilisation de la mémoire physique du système, de la mémoire virtuelle (partition d'échange), de la mémoire partagée et du cache système. la sortie est la même que top La partie mémoire de la commande est très similaire. Le format de base de la commande
free est le suivant :
# free [选项]
Le tableau 1 répertorie les options couramment utilisées de cette commande et leurs significations respectives.
| Option | Signification |
| -b | Affiche l'utilisation de la mémoire en octet (octet). |
| -k | Affiche l'utilisation de la mémoire en Ko. Cette option est l'option par défaut de la commande gratuite. |
| -m | Affiche l'utilisation de la mémoire en Mo. |
| -g | Affiche l'utilisation de la mémoire en Go. |
| -t | Dans le résultat final de la sortie, affichez la quantité totale de mémoire et la partition d'échange. |
| -o | Ne pas afficher la colonne du tampon système. |
| -s Secondes d'intervalle | Affiche en continu l'utilisation de la mémoire selon l'intervalle spécifié. |
free 命令可以显示系统中剩余及已用的物理内存和交换内存,以及共享内存和被核心使用的缓冲区。

如果加上 -h 选项,输出的结果会友好很多:

有时我们需要持续的观察内存的状况,此时可以使用 -s 选项并指定间隔的秒数:
$ free -h -s 3
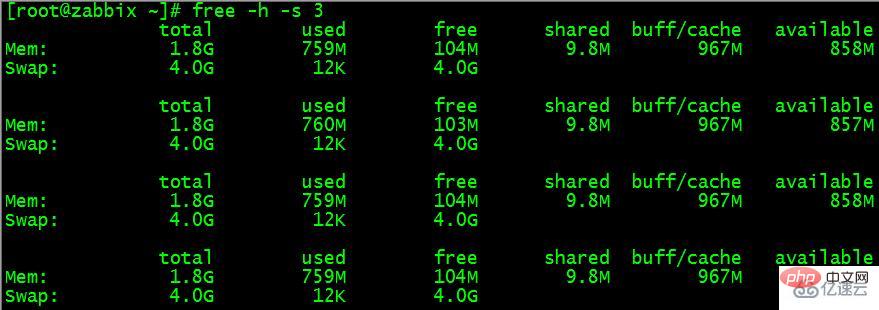
上面的命令每隔 3 秒输出一次内存的使用情况,直到你按下 ctrl + c。
由于 free 命令本身比较简单,所以本文的重点会放在如何通过 free 命令了解系统当前的内存使用状况。
输出简介
下面先解释一下输出的内容:
Mem 行(第二行)是内存的使用情况。
Swap 行(第三行)是交换空间的使用情况。
total 列显示系统总的可用物理内存和交换空间大小。
used 列显示已经被使用的物理内存和交换空间。
free 列显示还有多少物理内存和交换空间可用使用。
shared 列显示被共享使用的物理内存大小。
buff/cache 列显示被 buffer 和 cache 使用的物理内存大小。
available 列显示还可以被应用程序使用的物理内存大小。
我想只有在理解了一些基本概念之后,上面的输出才能帮助我们了解系统的内存状况。
buff/cache
先来提一个问题: buffer 和 cache 应该是两种类型的内存,但是 free 命令为什么会把它们放在一起呢?要回答这个问题需要我们做些准备工作。让我们先来搞清楚 buffer 与 cache 的含义。
buffer 在操作系统中指 buffer cache, 中文一般翻译为 "缓冲区"。要理解缓冲区,必须明确另外两个概念:"扇区" 和 "块"。扇区是设备的最小寻址单元,也叫 "硬扇区" 或 "设备块"。块是操作系统中文件系统的最小寻址单元,也叫 "文件块" 或 "I/O 块"。每个块包含一个或多个扇区,但大小不能超过一个页面,所以一个页可以容纳一个或多个内存中的块。当一个块被调入内存时,它要存储在一个缓冲区中。每个缓冲区与一个块对应,它相当于是磁盘块在内存中的表示(下图来自互联网):
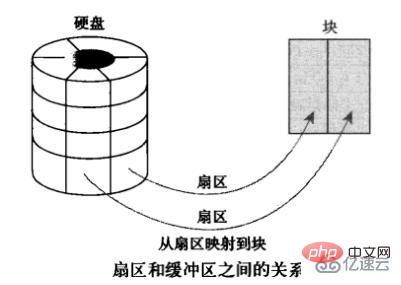
注意,buffer cache 只有块的概念而没有文件的概念,它只是把磁盘上的块直接搬到内存中而不关心块中究竟存放的是什么格式的文件。
cache 在操作系统中指 page cache,中文一般翻译为 "页高速缓存"。页高速缓存是内核实现的磁盘缓存。它主要用来减少对磁盘的 I/O 操作。具体地讲,是通过把磁盘中的数据缓存到物理内存中,把对磁盘的访问变为对物理内存的访问。页高速缓存缓存的是内存页面。缓存中的页来自对普通文件、块设备文件(这个指的就是 buffer cache 呀)和内存映射文件的读写。
页高速缓存对普通文件的缓存我们可以这样理解:当内核要读一个文件(比如
/etc/hosts)时,它会先检查这个文件的数据是不是已经在页高速缓存中了。如果在,就放弃访问磁盘,直接从内存中读取。这个行为称为缓存命中。如果数据不在缓存中,就是未命中缓存,此时内核就要调度块
I/O 操作从磁盘去读取数据。然后内核将读来的数据放入页高速缓存中。这种缓存的目标是文件系统可以识别的文件(比如 /etc/hosts)。
页高速缓存对块设备文件的缓存就是我们在前面介绍的 buffer cahce。因为独立的磁盘块通过缓冲区也被存入了页高速缓存(缓冲区最终是由页高速缓存来承载的)。
到这里我们应该搞清楚了:无论是缓冲区还是页高速缓存,它们的实现方式都是一样的。缓冲区只不过是一种概念上比较特殊的页高速缓存罢了。
那么为什么
free 命令不直接称为 cache 而非要写成 buff/cache? 这是因为缓冲区和页高速缓存的实现并非天生就是统一的。在 linux
内核 2.4
中才将它们统一。更早的内核中有两个独立的磁盘缓存:页高速缓存和缓冲区高速缓存。前者缓存页面,后者缓存缓冲区。当你知道了这些故事之后,输出中列的名称可能已经不再重要了。
free 与 available
在 free 命令的输出中,有一个 free 列,同时还有一个 available 列。这二者到底有何区别?
free
是真正尚未被使用的物理内存数量。至于 available 就比较有意思了,它是从应用程序的角度看到的可用内存数量。Linux
内核为了提升磁盘操作的性能,会消耗一部分内存去缓存磁盘数据,就是我们介绍的 buffer 和 cache。所以对于内核来说,buffer 和
cache 都属于已经被使用的内存。当应用程序需要内存时,如果没有足够的 free 内存可以用,内核就会从 buffer 和 cache
中回收内存来满足应用程序的请求。所以从应用程序的角度来说,available = free + buffer + cache。请注意,这只是一个很理想的计算方式,实际中的数据往往有较大的误差。
交换空间(swap space)
swap space 是磁盘上的一块区域,可以是一个分区,也可以是一个文件。所以具体的实现可以是 swap 分区也可以是 swap 文件。当系统物理内存吃紧时,Linux 会将内存中不常访问的数据保存到 swap 上,这样系统就有更多的物理内存为各个进程服务,而当系统需要访问 swap 上存储的内容时,再将 swap 上的数据加载到内存中,这就是常说的换出和换入。交换空间可以在一定程度上缓解内存不足的情况,但是它需要读写磁盘数据,所以性能不是很高。
现在的机器一般都不太缺内存,如果系统默认还是使用了 swap 是不是会拖累系统的性能?理论上是的,但实际上可能性并不是很大。并且内核提供了一个叫做 swappiness 的参数,用于配置需要将内存中不常用的数据移到 swap 中去的紧迫程度。这个参数的取值范围是 0~100,0 告诉内核尽可能的不要将内存数据移到 swap 中,也即只有在迫不得已的情况下才这么做,而 100 告诉内核只要有可能,尽量的将内存中不常访问的数据移到 swap 中。在 ubuntu 系统中,swappiness 的默认值是 60。如果我们觉着内存充足,可以在 /etc/sysctl.conf 文件中设置 swappiness:
vm.swappiness=10
如果系统的内存不足,则需要根据物理内存的大小来设置交换空间的大小。具体的策略网上有很丰富的资料,这里笔者不再赘述。
/proc/meminfo 文件
其实 free 命令中的信息都来自于 /proc/meminfo 文件。/proc/meminfo 文件包含了更多更原始的信息,只是看起来不太直观:
$ cat /proc/meminfo
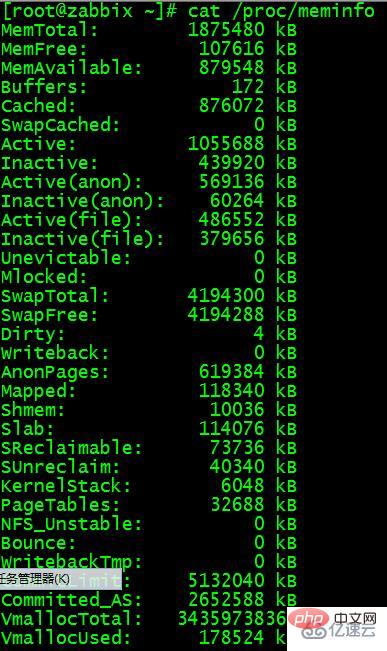
有兴趣的同学可以直接查看这个文件。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment démarrer Apache
Apr 13, 2025 pm 01:06 PM
Comment démarrer Apache
Apr 13, 2025 pm 01:06 PM
Les étapes pour démarrer Apache sont les suivantes: Installez Apache (Commande: Sudo apt-get install Apache2 ou téléchargez-le à partir du site officiel) Start Apache (Linux: Sudo SystemCTL Démarrer Apache2; Windows: Cliquez avec le bouton droit sur le service "APACHE2.4" et SELECT ") Vérifiez si elle a été lancée (Linux: SUDO SYSTEMCTL STATURE APACHE2; (Facultatif, Linux: Sudo SystemCTL
 Que faire si le port Apache80 est occupé
Apr 13, 2025 pm 01:24 PM
Que faire si le port Apache80 est occupé
Apr 13, 2025 pm 01:24 PM
Lorsque le port Apache 80 est occupé, la solution est la suivante: découvrez le processus qui occupe le port et fermez-le. Vérifiez les paramètres du pare-feu pour vous assurer qu'Apache n'est pas bloqué. Si la méthode ci-dessus ne fonctionne pas, veuillez reconfigurer Apache pour utiliser un port différent. Redémarrez le service Apache.
 Comment surveiller les performances de Nginx SSL sur Debian
Apr 12, 2025 pm 10:18 PM
Comment surveiller les performances de Nginx SSL sur Debian
Apr 12, 2025 pm 10:18 PM
Cet article décrit comment surveiller efficacement les performances SSL des serveurs Nginx sur les systèmes Debian. Nous utiliserons NginxExporter pour exporter des données d'état NGINX à Prometheus, puis l'afficher visuellement via Grafana. Étape 1: Configuration de Nginx Tout d'abord, nous devons activer le module Stub_Status dans le fichier de configuration NGINX pour obtenir les informations d'état de Nginx. Ajoutez l'extrait suivant dans votre fichier de configuration Nginx (généralement situé dans /etc/nginx/nginx.conf ou son fichier incluant): emplacement / nginx_status {Stub_status
 Comment configurer un bac de recyclage dans le système Debian
Apr 12, 2025 pm 10:51 PM
Comment configurer un bac de recyclage dans le système Debian
Apr 12, 2025 pm 10:51 PM
Cet article présente deux méthodes de configuration d'un bac de recyclage dans un système Debian: une interface graphique et une ligne de commande. Méthode 1: Utilisez l'interface graphique Nautilus pour ouvrir le gestionnaire de fichiers: Recherchez et démarrez le gestionnaire de fichiers Nautilus (généralement appelé "fichier") dans le menu de bureau ou d'application. Trouvez le bac de recyclage: recherchez le dossier de bac de recyclage dans la barre de navigation gauche. S'il n'est pas trouvé, essayez de cliquer sur "Autre emplacement" ou "ordinateur" pour rechercher. Configurer les propriétés du bac de recyclage: cliquez avec le bouton droit sur "Recycler le bac" et sélectionnez "Propriétés". Dans la fenêtre Propriétés, vous pouvez ajuster les paramètres suivants: Taille maximale: Limitez l'espace disque disponible dans le bac de recyclage. Temps de rétention: définissez la préservation avant que le fichier ne soit automatiquement supprimé dans le bac de recyclage
 Comment redémarrer le serveur Apache
Apr 13, 2025 pm 01:12 PM
Comment redémarrer le serveur Apache
Apr 13, 2025 pm 01:12 PM
Pour redémarrer le serveur Apache, suivez ces étapes: Linux / MacOS: Exécutez Sudo SystemCTL Restart Apache2. Windows: Exécutez net stop apache2.4 puis net start apache2.4. Exécuter netstat -a | Findstr 80 pour vérifier l'état du serveur.
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 L'importance de Debian Sniffer dans la surveillance du réseau
Apr 12, 2025 pm 11:03 PM
L'importance de Debian Sniffer dans la surveillance du réseau
Apr 12, 2025 pm 11:03 PM
Bien que les résultats de la recherche ne mentionnent pas directement "Debiansniffer" et son application spécifique dans la surveillance du réseau, nous pouvons en déduire que "Sniffer" se réfère à un outil d'analyse de capture de paquets de réseau, et son application dans le système Debian n'est pas essentiellement différente des autres distributions Linux. La surveillance du réseau est cruciale pour maintenir la stabilité du réseau et l'optimisation des performances, et les outils d'analyse de capture de paquets jouent un rôle clé. Ce qui suit explique le rôle important des outils de surveillance du réseau (tels que Sniffer Running dans Debian Systems): La valeur des outils de surveillance du réseau: Faute-défaut Emplacement: surveillance en temps réel des métriques du réseau, telles que l'utilisation de la bande passante, la latence, le taux de perte de paquets, etc.
 Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Ce guide vous guidera pour apprendre à utiliser Syslog dans Debian Systems. Syslog est un service clé dans les systèmes Linux pour les messages du système de journalisation et du journal d'application. Il aide les administrateurs à surveiller et à analyser l'activité du système pour identifier et résoudre rapidement les problèmes. 1. Connaissance de base de Syslog Les fonctions principales de Syslog comprennent: la collecte et la gestion des messages journaux de manière centralisée; Prise en charge de plusieurs formats de sortie de journal et des emplacements cibles (tels que les fichiers ou les réseaux); Fournir des fonctions de visualisation et de filtrage des journaux en temps réel. 2. Installer et configurer syslog (en utilisant RSYSLOG) Le système Debian utilise RSYSLOG par défaut. Vous pouvez l'installer avec la commande suivante: SudoaptupDatesud
