
 Périphériques technologiques
IA
Vous pouvez jouer simplement en bougeant votre bouche ! Utilisez l'IA pour changer de personnage et attaquer les ennemis : 'Ayaka, utilisez Kamiri-ryu Frost Destruction'
Périphériques technologiques
IA
Vous pouvez jouer simplement en bougeant votre bouche ! Utilisez l'IA pour changer de personnage et attaquer les ennemis : 'Ayaka, utilisez Kamiri-ryu Frost Destruction'
Vous pouvez jouer simplement en bougeant votre bouche ! Utilisez l'IA pour changer de personnage et attaquer les ennemis : 'Ayaka, utilisez Kamiri-ryu Frost Destruction'

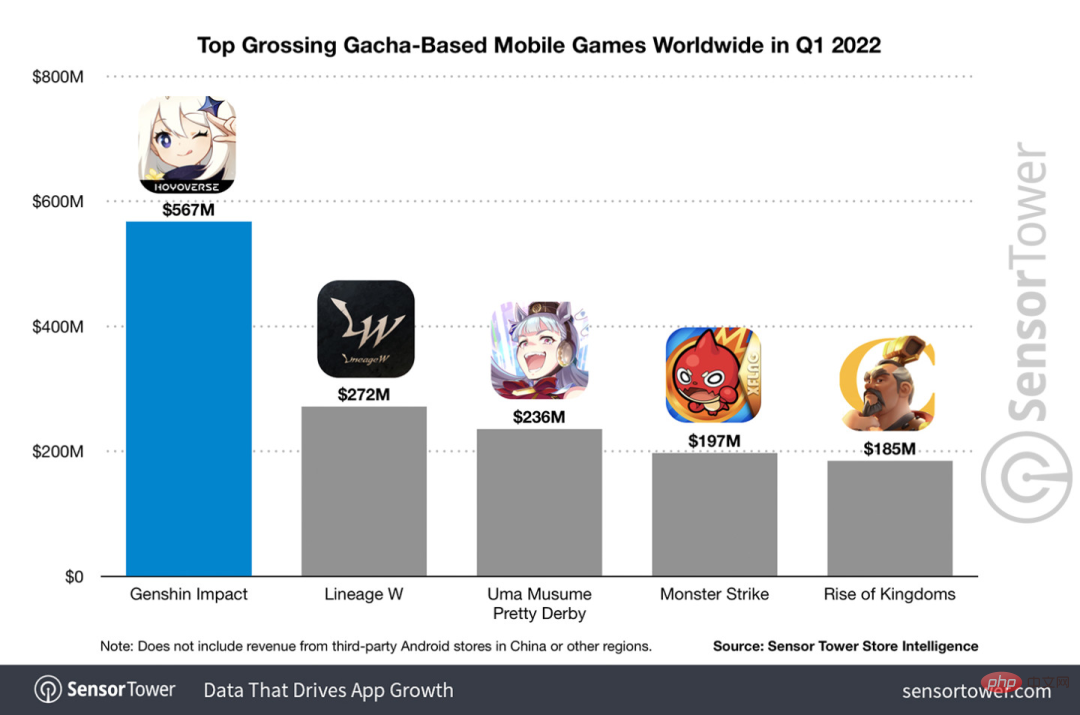
En parlant des jeux nationaux qui sont devenus populaires partout dans le monde au cours des deux dernières années, Genshin Impact prend définitivement les devants.
Selon le rapport d'enquête sur les revenus des jeux mobiles du premier trimestre de cette année publié en mai, « Genshin Impact » a fermement remporté la première place dans le jeu mobile de tirage de cartes avec un avantage absolu de 567 millions de dollars américains. Cela a également annoncé que « Genshin Impact ». » connaît un succès à court terme après son lancement. En seulement 18 mois, le chiffre d'affaires total de la seule plate-forme mobile a dépassé les 3 milliards de dollars américains (environ 13 milliards de RM).
Maintenant, la dernière version 2.8 de l'île avant l'ouverture de Xumi est attendue depuis longtemps. Après une longue période de draft, il y a enfin de nouvelles intrigues et zones à jouer.
Mais je ne sais pas combien il y a d'« Empereurs du foie ». Maintenant que l'île a été entièrement explorée, l'herbe a recommencé à pousser.

Il y a un total de 182 coffres au trésor + 1 boîte Mora (non incluse)
Il n'y a pas lieu de s'inquiéter de la période de croissance, les travaux de finition ne manquent jamais dans la zone Genshin Impact.
Non, pendant la période des herbes longues, certains joueurs ont utilisé XVLM+wenet+STARK pour réaliser un projet de commande vocale pour jouer à Genshin Impact.
Par exemple, lorsqu'il a dit "Utilisez Tactics 3 pour attaquer les slimes de feu au milieu", Zhongli a d'abord utilisé un bouclier, Ling Hua a fait un pas puis a dit "Désolé", et le groupe a détruit 4 slimes de feu.

De même, après avoir dit "attaquez le grand peuple Qiuqiu au milieu", Diona a utilisé E pour installer un bouclier, Ling Hua a enchaîné avec un E puis 3A a magnifiquement éliminé les deux grands Qiuqiu.

peut être vu en bas à gauche, l'ensemble du processus se fait sans aucune utilisation des mains.
Digest Microbiology a déclaré qu'il était un expert et qu'il économiserait ses mains lors de l'écriture de livres à l'avenir. Il a également déclaré que les mères n'avaient plus à s'inquiéter de la ténosynovite en jouant à Genshin Impact !
Actuellement, le projet est open source sur GitHub :
Lien GitHub :
https://github.com/7eu7d7/genshin_voice_play
Bon Genshin Impact, il a en fait été joué comme un Pokémon
Le Le projet de toute une vie a naturellement attiré l'attention de nombreux joueurs de Genshin Impact.
Par exemple, certains joueurs ont suggéré que le design puisse être plus neutre et utiliser directement le nom du personnage plus le nom de la compétence. Après tout, le public ne peut pas connaître les instructions telles que « Tactiques 3 » du premier coup et « Zhongli, ». utilisez le centre de la terre" Il est facile d'entrer dans l'expérience de jeu.

Certains internautes ont déclaré que puisqu'ils peuvent donner des instructions aux monstres, ils peuvent également donner des commandes vocales aux personnages, telles que "Tortue, utilise Frost Destruction".
turtle daily doutes.jpg
Cependant, pourquoi ces instructions semblent-elles si familières ? 

À ce sujet, le propriétaire du "Chat arc-en-ciel de Schrödinger" a déclaré que la vitesse des compétences de cri pourrait ne pas être en mesure de suivre et que la vitesse d'attaque serait plus lente, il a donc prédéfini un ensemble.

Cependant, les méthodes de sortie de certaines équipes classiques, telles que "Wanda International" et "Lei Jiuwan Ban", sont relativement fixes, et les séquences et modes d'attaque prédéfinis semblent fonctionner.
Bien sûr, en plus de créer des mèmes, les internautes réfléchissent également et proposent de nombreuses suggestions d'optimisation.
Par exemple, utilisez directement « 1Q » pour laisser le personnage en position 1 élargir ses mouvements, utilisez « lourd » pour exprimer des attaques lourdes, et « esquiver » pour esquiver. De cette façon, il sera plus facile et plus rapide de donner des instructions, et il peut aussi être utilisé pour lutter contre l'abîme.

Certains joueurs experts ont également déclaré que cette IA semble « ne pas très bien comprendre l'environnement » et que « la prochaine étape pourrait être d'envisager d'ajouter le SLAM » pour « parvenir à une détection de cible globale à 360 degrés ».

Le propriétaire d'up a déclaré que la prochaine étape consiste à "automatiser entièrement le processus de brossage, de téléportation, de tuer des monstres et de recevoir des récompenses". Il semble que nous puissions également ajouter une fonction pour renforcer automatiquement les reliques sacrées, et formatez l'IA si elle est tordue.

Le propriétaire inconditionnel du toilettage dans Genshin Impact a également publié le "Tevat Fishing Guide"
Comme l'a dit le magazine Digest, les travaux de toilettage ne manquent pas dans Genshin Impact, et ce propriétaire "L'arc-en-ciel de Schrödinger" " Cat" est probablement le plus "hardcore" d'entre eux.
Du « Placement automatique du labyrinthe de l'IA » aux « Performances automatiques de l'IA », chaque mini-jeu produit par Genshin Impact peut être considéré comme étant aussi IA que possible.
Parmi eux, Digest Fungus a également découvert le projet "AI Automatic Fishing" (le gentil s'avère être vous aussi). Il suffit de démarrer le programme, et tous les poissons de Teyvat peuvent être récoltés.
L'IA de pêche automatique Genshin Impact se compose de deux parties du modèle : YOLOX et DQN :
YOLOX est utilisé pour identifier le positionnement et le type de poisson et le positionnement du point d'atterrissage de la canne à pêche ; Contrôlez de manière adaptative le clic du processus de pêche, gardez l'intensité dans la zone optimale.
De plus, ce projet utilise également l'apprentissage par transfert et l'apprentissage semi-supervisé pour la formation. Le modèle contient également certaines parties non apprenables qui sont implémentées à l'aide de méthodes traditionnelles de traitement d'images numériques telles que opencv.
 Adresse du projet :
Adresse du projet :
https://github.com/7eu7d7/genshin_auto_fish
Si vous avez encore besoin du "Salted Fish Bow" obtenu en pêchant après la mise à jour 3.0, je vous le laisse !
 Ces "artefacts" qui ont transformé Genshin Impact en Pokémon
Ces "artefacts" qui ont transformé Genshin Impact en Pokémon
En tant que personne sérieuse, Dictionary Fungus estime qu'il est nécessaire de présenter à tout le monde certains des "artefacts" utilisés dans ce projet vocal Genshin Impact.
X-VLM est un modèle multi-granularité basé sur le modèle de langage visuel (VLM), composé d'un encodeur d'image, d'un encodeur de texte et d'un encodeur multimodal. L'encodeur multimodal fonctionne entre les fonctionnalités visuelles et les fonctionnalités de langage Cross. -attention modale pour l’apprentissage de l’alignement visuel du langage.
La clé de l'apprentissage de l'alignement multi-granularité est d'optimiser X-VLM : 1) en combinant la perte de régression de la boîte englobante et la perte d'IoU pour localiser les concepts visuels dans les images étant donné le texte associé 2) simultanément, par perte de contraste, perte de correspondance et masquage ; Perte de modélisation linguistique pour l’alignement multigranulaire du texte sur les concepts visuels.
En termes de réglage fin et d'inférence, X-VLM peut tirer parti de l'alignement multi-granularité appris pour effectuer des tâches V+L en aval sans ajouter d'annotations de cadre de délimitation dans l'image d'entrée.
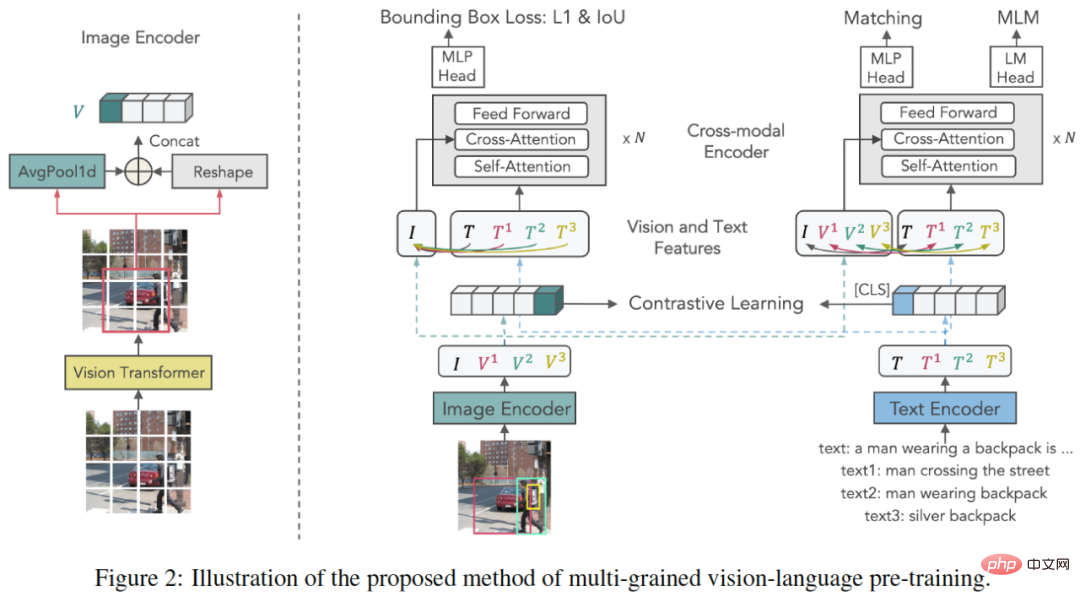 Lien papier :
Lien papier :
https://arxiv.org/abs/2111.08276
WeNet est une boîte à outils de reconnaissance vocale de bout en bout orientée production. Dans un modèle unique, il introduit le système unifié à deux passes. (U2) et runtime intégré pour gérer les modes de décodage en streaming et sans streaming.
Juste au début du mois de juillet de cette année, WeNet a lancé la version 2.0 et a été mis à jour sous 4 aspects :
U2++ : cadre unifié à double canal avec décodeur d'attention bidirectionnel, y compris un décodeur d'attention de droite à gauche Informations contextuelles futures pour améliorer la capacité de représentation de l'encodeur partagé et des performances de l'étape de rescoring ;
Introduction d'un modèle de langage basé sur n-gram et d'un décodeur basé sur WFST pour promouvoir l'utilisation de données textuelles riches dans les scénarios de production ;
Conception d'un cadre de biais de contexte unifié qui exploite le contexte spécifique de l'utilisateur pour fournir une adaptabilité rapide pour la production et améliorer la précision de l'ASR dans les scénarios « avec LM » et « sans LM »
Conception d'une IO unifiée pour prendre en charge des données à grande échelle de manière efficace ; formation sur modèle.
À en juger par les résultats, WeNet 2.0 a obtenu jusqu'à 10 % d'amélioration relative des performances de reconnaissance par rapport au WeNet original sur divers corpus.
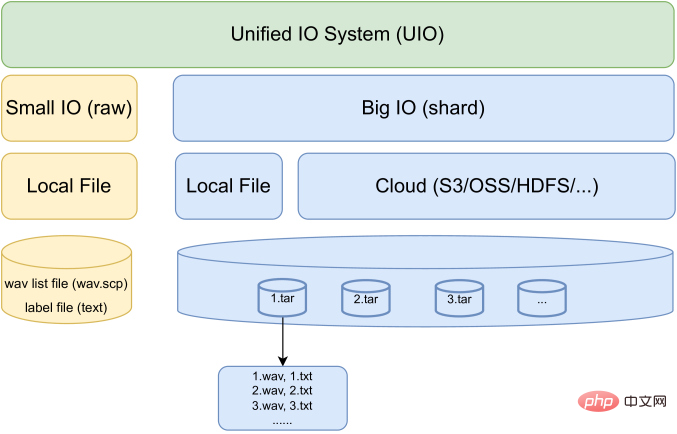
Lien papier : https://arxiv.org/pdf/2203.15455.pdf
STARK est un réseau de transformation spatio-temporelle pour le suivi visuel. Basé sur la ligne de base composée d'un squelette convolutif, d'un convertisseur de codec et d'une tête de prédiction de boîte englobante, STARK a apporté 3 améliorations :
Modèle de mise à jour dynamique : utilisez des images intermédiaires comme modèles dynamiques à ajouter à l'entrée. Les modèles dynamiques peuvent capturer les changements d'apparence et fournir des informations supplémentaires sur le domaine temporel ;
score head : déterminez si le modèle dynamique est actuellement mis à jour
Amélioration de la stratégie d'entraînement : divisez l'entraînement en deux étapes 1) En plus du score head, utilisez la perte de base ; train de fonctions. Assurez-vous que toutes les images de recherche contiennent la cible et permettent au modèle d'avoir des capacités de positionnement ; 2) Utilisez l'entropie croisée pour optimiser uniquement la tête de score et geler les autres paramètres à ce moment pour permettre au modèle d'avoir des capacités de positionnement et de classification.
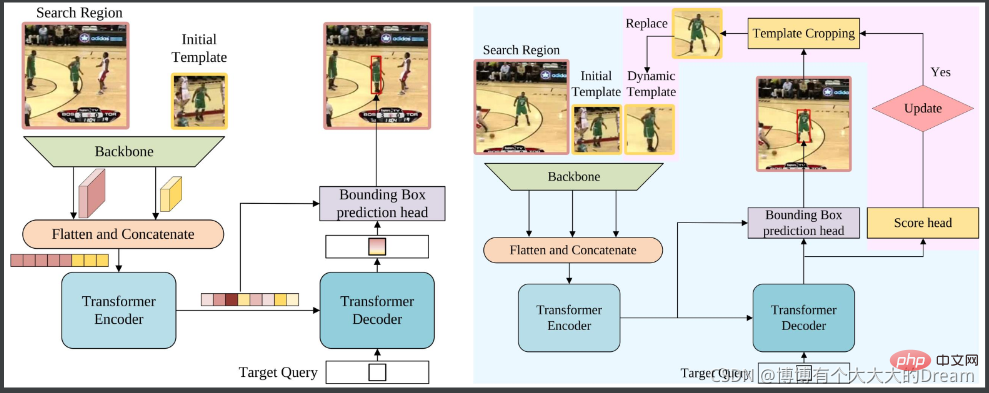
Lien papier :
https://openaccess.thecvf.com/content/ICCV2021/papers/Yan_Learning_Spatio-Temporal_Transformer_for_Visual_Tracking_ICCV_2021_paper.pdf
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
