
 développement back-end
Tutoriel Python
analyse d'un exemple de modélisation mathématique Python
développement back-end
Tutoriel Python
analyse d'un exemple de modélisation mathématique Python
analyse d'un exemple de modélisation mathématique Python

Apprentissage SciPy
''' SciPy 包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、 信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。 ''' # 安装scipy库: # SciPy终端安装命令:pip install SciPy # https://www.runoob.com/w3cnote/python-pip-install-usage.html Python pip 安装与使用 # 查看scipy版本: import scipy print(scipy.__version__) # SciPy模块功能表 ''' 模块 功能 scipy.cluster 聚类分析等 scipy.constants 物理和数学函数 scipy.fftpack 傅里叶变换 scipy.integrate 积分 scipy.interpolate 插值 scipy.io 数据输入和输出 scipy.linalg 线性代数 scipy.ndimage n维图像 scipy.odr 正交距离回归 scipy.optimize 优化 scipy.signal 信号处理 scipy.sparse 稀疏矩阵 scipy.spatial 空间数据结构和算法 scipy.special 特殊函数 scipy.stats 统计 ''' # 使用 dir() 函数来查看 constants 模块包含的常量: from scipy import constants print(dir(constants)) ''' 单位类型 常量模块包含以下几种单位: 公制单位 二进制,以字节为单位 质量单位 角度换算 时间单位 长度单位 压强单位 体积单位 速度单位 温度单位 能量单位 功率单位 力学单位 ''' print() # SciPy 常量模块: # constants 是 scipy 的常量模块 from scipy import constants # 查看一英亩等于多少平方米: print(constants.acre) # 输出 4046.8564223999992 # SciPy 常量模块 constants 提供了许多内置的数学常数 # 圆周率: pi # 黄金比例: golden from scipy import constants print(constants.pi) # 输出 3.141592653589793 【圆周率】 print(constants.golden) # 输出 1.618033988749895 【黄金比例】
Opérations de base SciPy
1-Résoudre des équations non linéaires (ensemble)
1-1
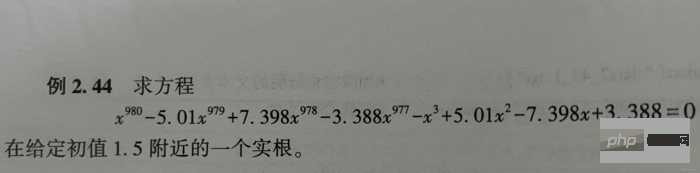
Le code de solution est le suivant :
# scipy.optimize模块的fsolve和root可求非线性方程(组)的解
# 格式:
from scipy.optimize import fsolve
from scipy.optimize import root
# fsolve或root求解非线性方程组时,先把非线性方程组写成 F(x)=0 这样的形式【x:向量;F(x):向量函数】
fx = lambda x: x**980-5.01*x**979-3.388*x**977\
+7.398*x**978-x**3+5.01*x**2-7.398*x+3.388
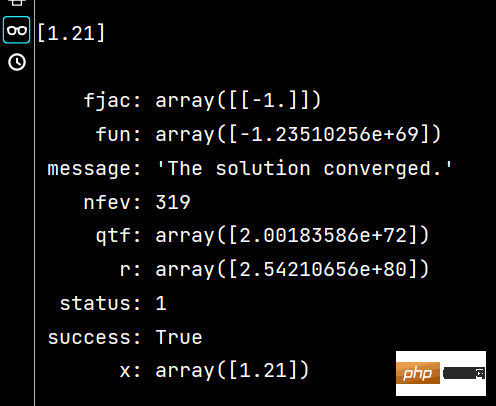
x1 = fsolve(fx, 1.5, maxfev=420) # 函数调用420次【调用小了,会报警告】
x2 = root(fx, 1.5)
print(x1) # 相当于答案
print()
print(x2) # 相当于解题过程Les résultats de exécutant x1 et x2 sont les suivants :
1-2
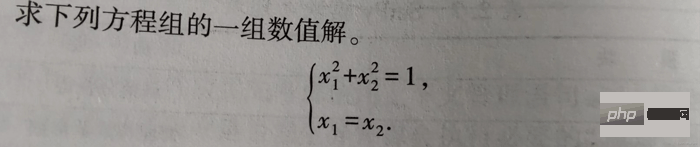
Le code de la solution est le suivant :
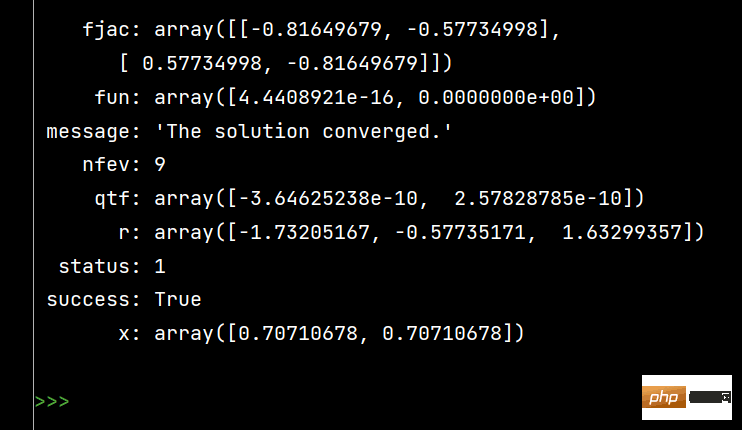
from scipy.optimize import fsolve, root fs2 = lambda s: [s[0]**2+s[1]**2-1, s[0]-s[1]] s1 = fsolve(fs2, [1, 1]) print() s2 = root(fs2, [1, 1]) print(s1) # 输出 [0.70710678 0.70710678] print() print(s2)
L'effet de l'exécution de s2 est le suivant :
2 -Points
scipy.integrate module fournit plusieurs modes de points.
Integral se divise principalement dans les deux catégories suivantes :
Intégration numérique d'une fonction donnée
Intégration numérique d'un point discret donné, la fonction a des pièges
Question :
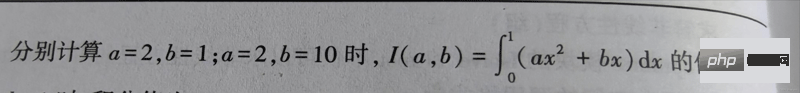
'''
函数 说明
quad(func, a, b, args) 计算一重数值积分
dblquad(func, a, b, gfun, hfun, args) 计算二重数值积分
tplquad(func, a, b, gfun, hfun, qfun, rfun) 计算三重数值积分
nquad(func, ranges, args) 计算多变量积分
'''
from scipy.integrate import quad
def func(x, a, b):
return a*x**2+b*x
z1 = quad(func, 0, 1, args=(2, 1))
z2 = quad(func, 0, 1, args=(2, 10))
print(z1) # 输出 (1.1666666666666665, 1.2952601953960159e-14)
print(z2) # 输出 (5.666666666666667, 6.291263806209221e-14)
# 注:输出的后一个值为积分值的绝对误差Solution des 3 moindres carrés

# 最小二乘解 # scipy.optimize 模块求非线性方程组最小二乘解格式: ''' from scipy.optimize import least_squares least_squares(fun, x0) 注:用到loadtxt需自行准备好文件【准备文件】 ''' from scipy.optimize import least_squares import numpy as np s = np.loadtxt('data.txt') x0 = s[0] y0 = s[1] d = s[2] fs = lambda x: np.sqrt((x0-s[0])**2+(y0-s[1])**2-d) xc = least_squares(fs, np.random.rand(2)) print(xc) print() print(xc.s)
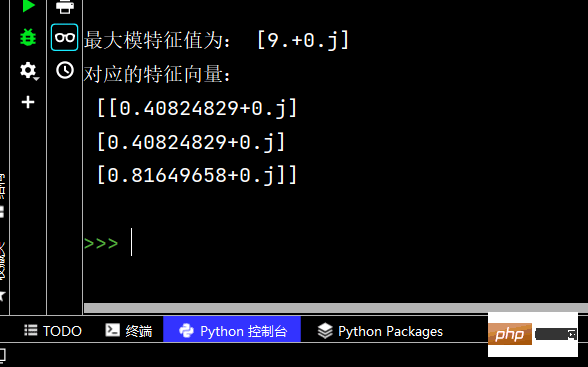
4-valeur propre modulaire maximale et vecteur propre correspondant
Question :

# 4-最大模特征值及对应的特征向量
# 题目描述:求下列矩阵的最大模特征值及对应的特征向量:
from scipy.sparse.linalg import eigs
import numpy as np
m = np.array([
[1, 2, 3],
[2, 1, 3],
[3, 3, 6]
], dtype=float)
a, b = np.linalg.eig(m)
c, d = eigs(m, 1)
print('最大模特征值为:', c) # 输出 最大模特征值为: [9.+0.j]
print('对应的特征向量:\n', d)Les résultats en cours sont les suivants suit :
Apprentissage Numpy (suite)
# NumPy 广播(Broadcast)
# 广播是 numpy 对不同形状的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。
# 如果两个数组 a 和 b 形状相同,即满足 a.shape == b.shape,那么 a*b 的结果就是 a 与 b 数组对应位相乘。
# 这要求维数相同,且各维度的长度相同。
'''
对两个数组,分别比较他们的每一个维度(若其中一个数组没有当前维度则忽略),满足:
数组拥有相同形状。
当前维度的值相等。
当前维度的值有一个是 1。
若条件不满足,抛出 "ValueError: frames are not aligned" 异常
'''
import numpy as np
a = np.array([3, 6, 9])
b = np.array([2, 4, 6])
c = a * b
print(c) # 输出 [ 6 24 54]
# 若形状不同时,numpy 将自动触发广播机制
import numpy as np
x = np.array([
[4, 2, 5],
[5, 2, 0],
[2, 6, 1],
[1, 4, 5]
])
y = np.array([3, 1, 2])
print(x+y)
yy = np.tile(y, (4, 1)) # 重复b的各个维度
print(x+yy)1 Fonctions mathématiques Numpy
1-1 fonction trigonométrique
# NumPy 数学函数 # NumPy 包含大量的各种数学运算的函数,包括三角函数,算术运算的函数,复数处理函数等。 # 1-三角函数 # NumPy 提供了标准的三角函数:sin()、cos()、tan()。 import numpy as np lxw = np.array([0, 30, 45, 60, 90]) # sin() zx = np.sin(lxw*np.pi/180) print(zx) # 计算角度的反正弦【单位:弧度】 fzx = np.arcsin(zx) print(fzx) # 检查结果【通过转化为角度制】 jg = np.degrees(fzx) print(jg) # 输出 [ 0. 30. 45. 60. 90.] # cos() yx = np.cos(lxw*np.pi/180) print(yx) # 反余弦 fyx = np.arccos(yx) print(fyx) # 检查结果: jg2 = np.degrees(fyx) print(jg2) # 输出 [ 0. 30. 45. 60. 90.] # tan() zq = np.tan(lxw*np.pi/180) print(zq) # 反正切 fzq = np.arctan(zq) print(fzq) # 检查结果: jg3 = np.degrees(fzq) print(jg3) # 输出 [ 0. 30. 45. 60. 90.]
2 fonctions d'arrondi
2-1 numpy.around()
# 2-舍入函数 # 2-1 numpy.around() ''' numpy.around() 函数返回指定数字的四舍五入值。 格式: numpy.around(a,decimals) 参数说明: a: 数组 decimals: 舍入的小数位数。 默认值为0。 如果为负,整数将四舍五入到小数点左侧的位置 ''' import numpy as np bl = np.array([15.222, 22.6555, 13.71111]) print(np.around(bl)) # 输出 [15. 23. 14.] print(np.around(bl, 2)) # 输出 [15.22 22.66 13.71] print(np.around(bl, -1)) # 输出 [20. 20. 10.]
2-2 numpy.floor()
# 2-2 numpy.floor() # numpy.floor() 返回小于或者等于指定表达式的最大整数,即向下取整 import numpy as np xx = np.array([23.3, 13.43, 2.9]) print(np.floor(xx)) # 输出 [23. 13. 2.]
2-3 numpy.ceil()
# 2-3 numpy.ceil() # numpy.ceil() 返回大于或者等于指定表达式的最小整数,即向上取整 import numpy as np xs = np.array([23.1, 23.5, 54.9]) print(np.ceil(xs)) # 输出 [24. 24. 55.]
3 Fonctions arithmétiques Numpy
Les fonctions arithmétiques NumPy incluent des additions, soustractions, multiplications et divisions simples : add(), soustract(), multiplie() et diviser()
-
reciprocal :reciprocal()
power: power()
rest: mod() |rest()
Remarque : Les tableaux doivent avoir la même forme ou < /code>Respecter les règles de diffusion du tableau<code>注:数组必须具有相同的形状或符合数组广播规则
相关代码如下:
import numpy as np sz = np.arange(9, dtype=np.float_).reshape(3, 3) sz2 = np.array([5, 2, 1]) # 注:如果相除,这里是被除数的话,里面不能有0 # 数组相加 xj = np.add(sz, sz2) print(xj) # 数组相减 xj2 = np.subtract(sz, sz2) print(xj2) # 数组相乘 xc = np.multiply(sz, sz2) print(xc) # 数组相除 xc2 = np.divide(sz, sz2) print(xc2) print() # numpy.power() # numpy.power() 函数将第一个输入数组中的元素作为底数,计算它与第二个输入数组中相应元素的幂 import numpy as np m = np.array([1, 4, 8]) # 数组1 mc = np.power(m, 3) # 数组1所有元素对应的3次方 print(mc) # 输出 [ 1 64 512] m2 = np.array([1, 2, 3]) # 数组2 mc2 = np.power(m, m2) # 数组1作为底数,数组2作为幂 print(mc2) # 输出 [ 1 16 512] print() # numpy.mod() # numpy.mod() 计算输入数组中相应元素的相除后的余数 # 函数 numpy.remainder() 也产生相同的结果 import numpy as np sz1 = np.array([23, 45, 67]) sz2 = np.array([2, 3, 5]) print(np.mod(sz1, sz2)) # 输出 [1 0 2] print(np.remainder(sz1, sz2)) # 输出 [1 0 2]
Pandas学习(续)
# pandas的SettingWithCopyWarning
# pandas的SettingWithCopyWarning报警复现、原因、解决方案 # 读取数据 import pandas as pd df = pd.read_csv('nba.csv') print(df.head()) # 核心解决问题:pandas的dataframe的修改写操作,只允许在源dataframe上进行,一步到位 # 解决方法(两种): ''' 1-将get+set的两步操作,改成set的一步操作 2-若须处理筛选数据做后续的处理分析,使用copy复制dataframe ''' # pandas不允许先筛选子dataframe,在进行修改写入
【注意先准备好csv文件
Le code pertinent est le suivant :
# Pandas 数据排序
'''
Series的排序:
Series.sort_values(ascending=True, inplace=False)
参数说明:
· ascending: 默认为True升序排序,False为False
· inplace: 是否修改原始Series
DataFrame的排序:
DataFrame.sort_values(by, ascending=True, inplace=False)
参数说明:
· by:字符串或者List<字符串>,单列排序或者多列排序
· ascending: bool或者List,升序还是降序
· inplace: 是否修改原始DataFrame
'''
# Series的排序:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head()) # 输出前五行
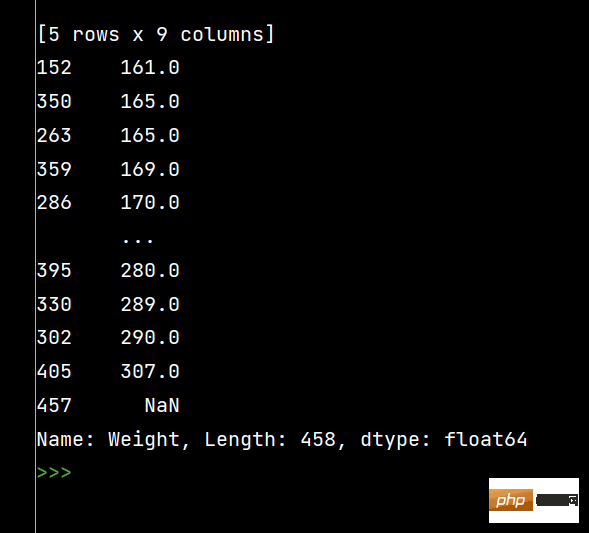
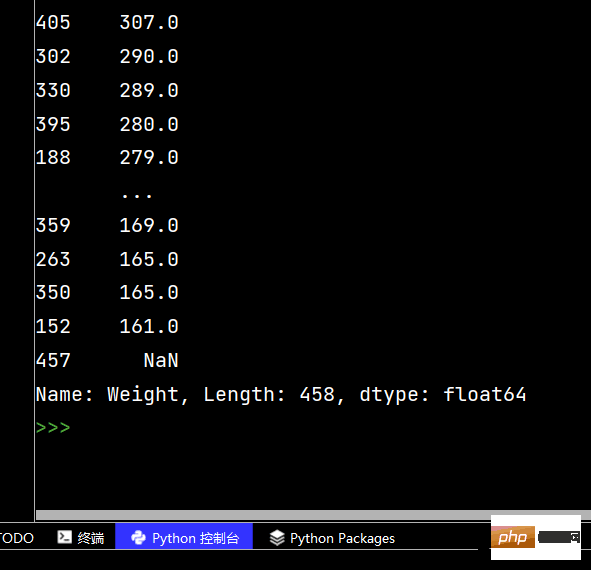
print(df['Weight'].sort_values()) # 升序排序
print(df['Weight'].sort_values(ascending=False)) # 降序排序# SettingWithCopyAvertissement des pandas
# DataFrame的排序 # 单列排序: print(df.sort_values(by='Weight'))
Attention à préparer le csv d'abord] 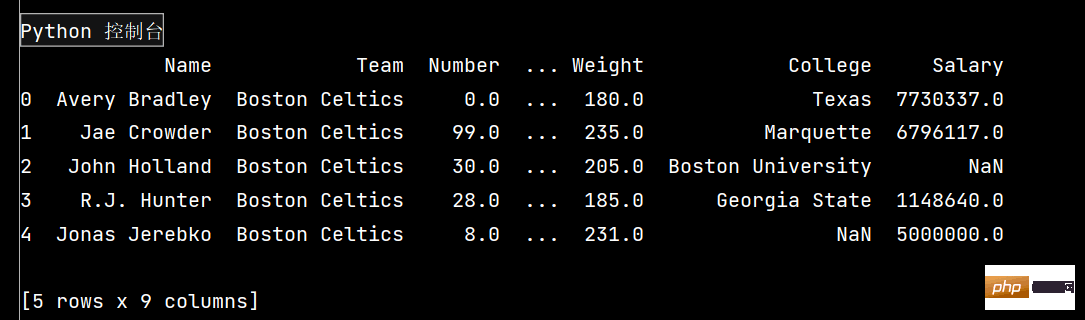 Tri des données Pandas
Tri des données Pandas
 Tri des séries :
Tri des séries :
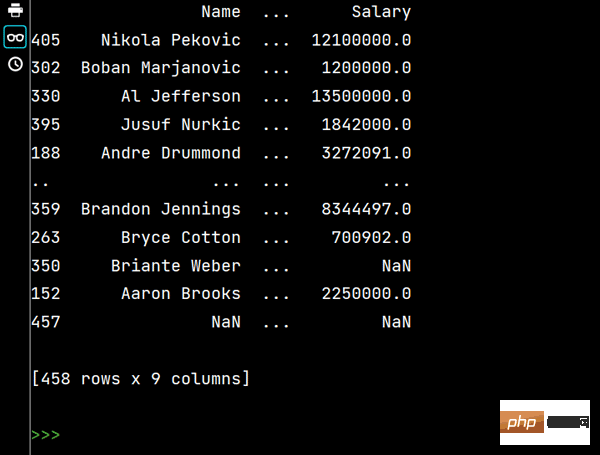
print(df.sort_values(by="Weight", ascending=False)) # 降序排序
 Les résultats en cours sont les suivants :
Les résultats en cours sont les suivants : 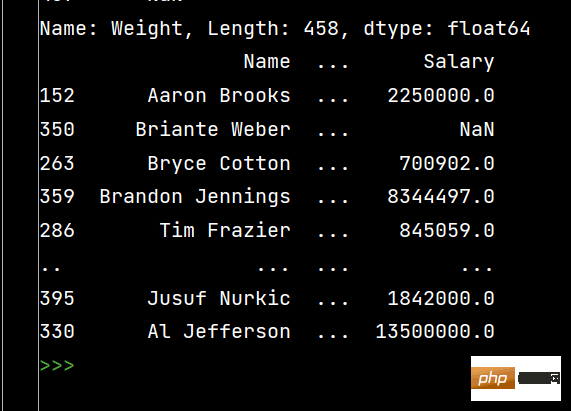
# 多列排序: print(df.sort_values(by=['Age', 'Weight']))
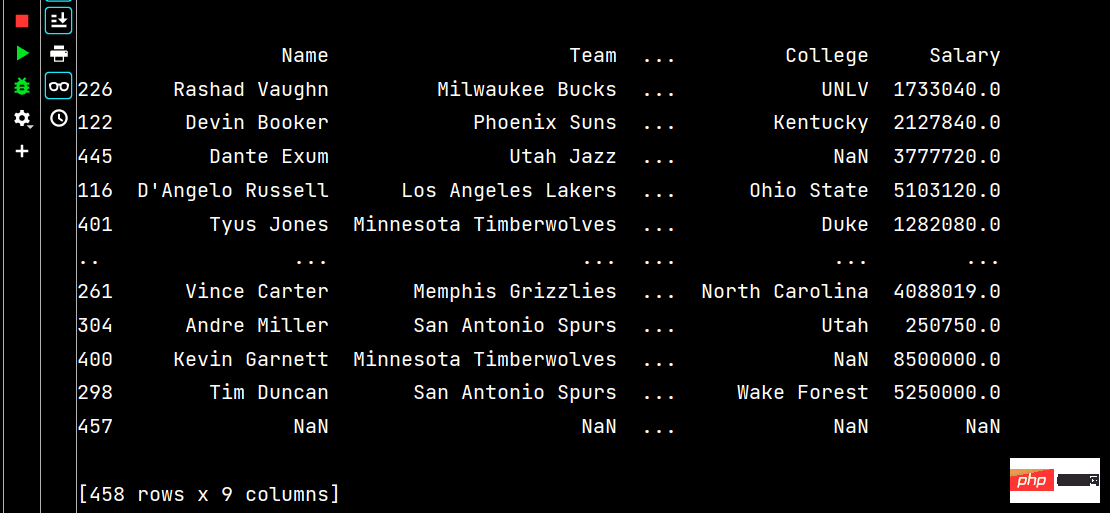 Courir partie Les résultats sont les suivants :
Courir partie Les résultats sont les suivants : 
# 两个字段都是降序排序 print(df.sort_values(by=['Age', 'Weight'], ascending=False))
# 分别指定升序还是降序 print(df.sort_values(by=['Age', 'Weight'], ascending=[False, True]))
df['lrl'].str.replace("%", "").astype("int32")
# Pandas字符串处理: ''' 1-使用方法:先获取Series的属性,然后再属性上调用函数 2-只能在字符串列上使用,不能再数字列上使用 3-DataFrame没有str属性和使用 4-Series.str并不是原生Python字符串,它是封装的一套方法 ''' # 获取Series的属性 # print(df['Salary'].str) # 报错【示范】 # AttributeError: Can only use .str accessor with string values! # AttributeError:只能使用。带字符串值的str访问器! # 一定得是字符串列 print(df['College'].str) # 运行结果为: <pandas.core.strings.accessor.StringMethods object at 0x00000204444EBC48> # 判断是不是数字列 print(df['College'].str.isnumeric()) # print(df['College'].len) # 报错【示范】 # AttributeError: 'Series' object has no attribute 'len' # AttributeError:“Series”对象没有属性“len”
 Traitement des chaînes Pandas
Traitement des chaînes Pandas
J'ai déjà eu quelques problèmes avec ce problème de traitement de chaîne (mais j'ai résolu c'est ça jour) [Regardez-le aujourd'hui Regardez], c'est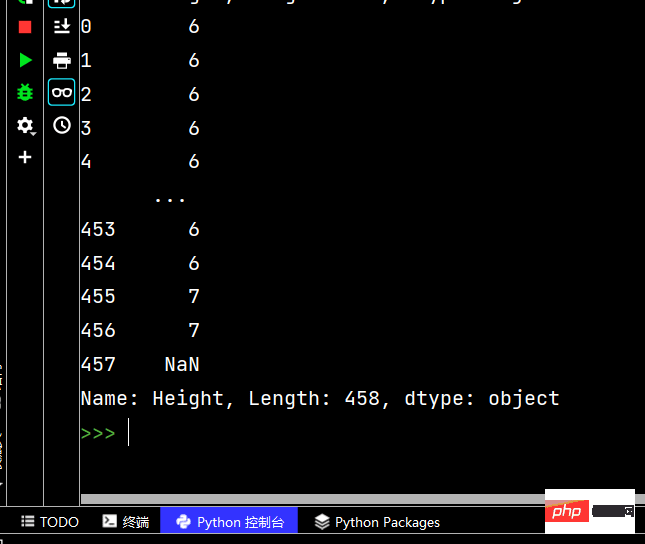
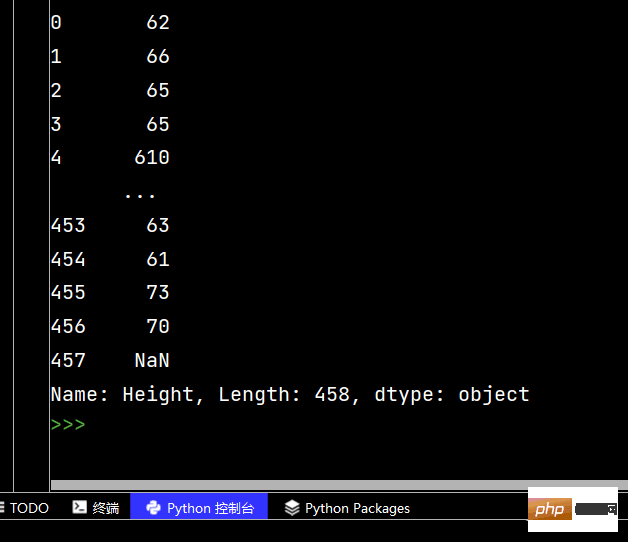
# 使用str的startswith、contains等得到bool的Series可以做条件查询
tj = df['Height'].str.startswith("6-2")
print(tj)# 去掉Height中间的“-”
print(df['Height'].str.replace("-", ""))# 取第一位数
print(df['Height'].str.replace("-", "").str.slice(0, 1))
# 同上
print(df['Height'].str.replace("-", "").str[0:1])Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution
Apr 08, 2025 am 11:21 AM
Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution
Apr 08, 2025 am 11:21 AM
Le fichier de téléchargement mysql est corrompu, que dois-je faire? Hélas, si vous téléchargez MySQL, vous pouvez rencontrer la corruption des fichiers. Ce n'est vraiment pas facile ces jours-ci! Cet article expliquera comment résoudre ce problème afin que tout le monde puisse éviter les détours. Après l'avoir lu, vous pouvez non seulement réparer le package d'installation MySQL endommagé, mais aussi avoir une compréhension plus approfondie du processus de téléchargement et d'installation pour éviter de rester coincé à l'avenir. Parlons d'abord de la raison pour laquelle le téléchargement des fichiers est endommagé. Il y a de nombreuses raisons à cela. Les problèmes de réseau sont le coupable. L'interruption du processus de téléchargement et l'instabilité du réseau peut conduire à la corruption des fichiers. Il y a aussi le problème avec la source de téléchargement elle-même. Le fichier serveur lui-même est cassé, et bien sûr, il est également cassé si vous le téléchargez. De plus, la numérisation excessive "passionnée" de certains logiciels antivirus peut également entraîner une corruption des fichiers. Problème de diagnostic: déterminer si le fichier est vraiment corrompu
 MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL peut s'exécuter sans connexions réseau pour le stockage et la gestion des données de base. Cependant, la connexion réseau est requise pour l'interaction avec d'autres systèmes, l'accès à distance ou l'utilisation de fonctionnalités avancées telles que la réplication et le clustering. De plus, les mesures de sécurité (telles que les pare-feu), l'optimisation des performances (choisissez la bonne connexion réseau) et la sauvegarde des données sont essentielles pour se connecter à Internet.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
MySQL a refusé de commencer? Ne paniquez pas, vérifions-le! De nombreux amis ont découvert que le service ne pouvait pas être démarré après avoir installé MySQL, et ils étaient si anxieux! Ne vous inquiétez pas, cet article vous emmènera pour le faire face calmement et découvrez le cerveau derrière! Après l'avoir lu, vous pouvez non seulement résoudre ce problème, mais aussi améliorer votre compréhension des services MySQL et vos idées de problèmes de dépannage, et devenir un administrateur de base de données plus puissant! Le service MySQL n'a pas réussi et il y a de nombreuses raisons, allant des erreurs de configuration simples aux problèmes système complexes. Commençons par les aspects les plus courants. Connaissances de base: une brève description du processus de démarrage du service MySQL Service Startup. Autrement dit, le système d'exploitation charge les fichiers liés à MySQL, puis démarre le démon mysql. Cela implique la configuration
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
