

Effet d'exécution du programme
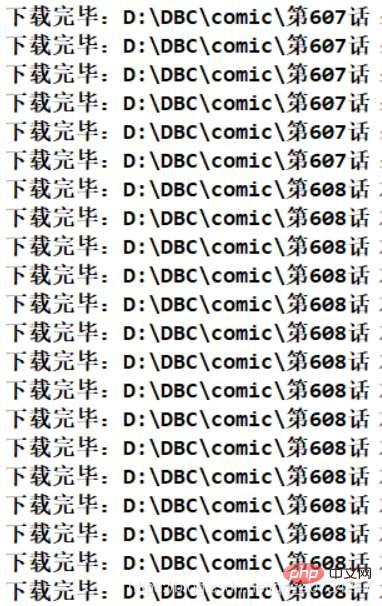
Informations sur le répertoire de fichiers obtenues
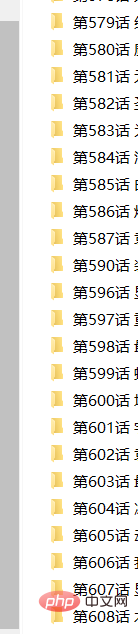
Informations totales du fichier

Remarque : Voici un petit Le Le problème est que certains des fichiers obtenus peuvent ne pas avoir de noms de suffixe, mais ils peuvent être ouverts et visualisés sous forme d'images. Je ne connais pas la raison spécifique, puisque cela ne l'affecte pas, je m'en fiche. (Ou utilisez votre propre code pour renommer le fichier.)
Voici une bande dessinée à titre d'exemple. Tout d'abord, regardez le numéro ci-dessus. Ce numéro représente la page de table des matières de la bande dessinée. Il est très important que sur cette page il y ait une Table des matières. Cliquez ensuite sur les chapitres du répertoire un par un pour voir les informations BD de chaque chapitre.


Cette pagination ici est très étrange, car le nombre de pages dans chaque chapitre n'est pas le même, mais elle est bel et bien directement sélectionnable, indiquant qu'il faut la charger à l'avance ou de manière asynchrone (en fait je ne le fais pas) Je ne connais pas les connaissances front-end, je viens d'en entendre parler.) Plus tard, en regardant la source (Je l'ai découvert de mes yeux), j'ai découvert que c'était bien le lien pour charger toutes les pages de BD à l'avance. Il n'est pas chargé de manière asynchrone.
Ici, je clique sur l'image de la bande dessinée pour obtenir l'adresse de l'image, puis je la compare avec le lien que j'ai trouvé, puis je peux la voir. Ensuite, je colle l'URL et j'obtiens tous les liens.
Dans la page du chapitre correspondant, utilisez la source de vue du navigateur pour trouver un tel script. Après analyse, les informations du tableau dans le script sont les informations correspondant à chaque page de la bande dessinée.

La capture d'écran ci-dessus est une information de structure approximative, donc le processus d'acquisition est le suivant : Page de contenu–>Page de chapitre–>Page de bande dessinée
Pour ici, récupérez ce script sous forme de chaîne, puis utilisez "[ " et "]" pour obtenir la chaîne, puis utilisez fastjson pour la convertir en une collection List.
// 获取的script 无法直接解析,必须先将 page url 取出来,
// 这里以 [ ] 为界限,分割字符串。
String pageUrls = script.data();
int start = pageUrls.indexOf("[");
int end = pageUrls.indexOf("]") + 1;
String urls = pageUrls.substring(start, end);
//json 转 集合,这个可以总结一下,不熟悉。
List<String> urlList = JSONArray.parseArray(urls, String.class);Un point à souligner ici : la méthode texte de l'objet Element consiste à obtenir des informations visibles, tandis que la méthode data consiste à obtenir des informations invisibles. Les informations du script ne sont pas directement visibles, j'utilise donc la méthode data pour les obtenir. Ce qu'on appelle visible et invisible fait référence aux informations qui peuvent être affichées sur la page Web et peuvent être obtenues en visualisant la source. Par exemple, les caractères d'échappement deviennent des caractères d'échappement lorsqu'ils sont obtenus via text ext.
Utilisez le pool de connexions HttpClient pour gérer les connexions, mais je n'ai pas utilisé le multi-threading car je n'ai qu'une seule adresse IP. Si elle est bloquée, ce sera très gênant. Le temps de fil reste acceptable. Après tout, une bande dessinée ne dure qu'une dizaine de minutes. (Prenez le chapitre 600 comme exemple)
package com.comic;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
public class HttpClientUtil {
private static final int TIME_OUT = 10 * 1000;
private static PoolingHttpClientConnectionManager pcm; //HttpClient 连接池管理类
private static RequestConfig requestConfig;
static {
requestConfig = RequestConfig.custom()
.setConnectionRequestTimeout(TIME_OUT)
.setConnectTimeout(TIME_OUT)
.setSocketTimeout(TIME_OUT).build();
pcm = new PoolingHttpClientConnectionManager();
pcm.setMaxTotal(50);
pcm.setDefaultMaxPerRoute(10); //这里可能用不到这个东西。
}
public static CloseableHttpClient getHttpClient() {
return HttpClients.custom()
.setConnectionManager(pcm)
.setDefaultRequestConfig(requestConfig)
.build();
}
}La classe la plus importante, utilisée pour analyser les pages HTML pour obtenir des données de lien. Remarque : Le DIR_PATH ici est un chemin codé en dur, donc si vous souhaitez tester, veuillez créer vous-même le répertoire approprié.
package com.comic;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.Collectors;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.config.CookieSpecs;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.alibaba.fastjson.JSONArray;
public class ComicSpider {
private static final String DIR_PATH = "D:/DBC/comic/";
private String url;
private String root;
private CloseableHttpClient httpClient;
public ComicSpider(String url, String root) {
this.url = url;
// 这里不做非空校验,或者使用下面这个。
// Objects.requireNonNull(root);
if (root.charAt(root.length()-1) == '/') {
root = root.substring(0, root.length()-1);
}
this.root = root;
this.httpClient = HttpClients.createDefault();
}
public void start() {
try {
String html = this.getHtml(url); //获取漫画主页数据
List<Chapter> chapterList = this.mapChapters(html); //解析数据,得到各话的地址
this.download(chapterList); //依次下载各话。
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 从url中获取原始的网页数据
* @throws IOException
* @throws ClientProtocolException
* */
private String getHtml(String url) throws ClientProtocolException, IOException {
HttpGet get = new HttpGet(url);
//下面这两句,是因为总是报一个 Invalid cookie header,然后我在网上找到的解决方法。(去掉的话,不影响使用)。
RequestConfig defaultConfig = RequestConfig.custom().setCookieSpec(CookieSpecs.STANDARD).build();
get.setConfig(defaultConfig);
//因为是初学,而且我这里只是请求一次数据即可,这里就简单设置一下 UA
get.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36");
HttpEntity entity = null;
String html = null;
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
entity = response.getEntity();
if (entity != null) {
html = EntityUtils.toString(entity, "UTF-8");
}
}
}
return html;
}
//获取章节名 链接地址
private List<Chapter> mapChapters(String html) {
Document doc = Jsoup.parse(html, "UTF-8");
Elements name_urls = doc.select("#chapter-list-1 > li > a");
/* 不采用直接返回map的方式,封装一下。
return name_urls.stream()
.collect(Collectors.toMap(Element::text,
name_url->root+name_url.attr("href")));
*/
return name_urls.stream()
.map(name_url->new Chapter(name_url.text(),
root+name_url.attr("href")))
.collect(Collectors.toList());
}
/**
* 依次下载对应的章节
* 我使用当线程来下载,这种网站,多线程一般容易引起一些问题。
* 方法说明:
* 使用循环迭代的方法,以 name 创建文件夹,然后依次下载漫画。
* */
public void download(List<Chapter> chapterList) {
chapterList.forEach(chapter->{
//按照章节创建文件夹,每一个章节一个文件夹存放。
File dir = new File(DIR_PATH, chapter.getName());
if (!dir.exists()) {
if (!dir.mkdir()) {
try {
throw new FileNotFoundException("无法创建指定文件夹"+dir);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
//开始按照章节下载
try {
List<ComicPage> urlList = this.getPageUrl(chapter);
urlList.forEach(page->{
SinglePictureDownloader downloader = new SinglePictureDownloader(page, dir.getAbsolutePath());
downloader.download();
});
} catch (IOException e) {
e.printStackTrace();
}
}
});
}
//获取每一个页漫画的位置
private List<ComicPage> getPageUrl(Chapter chapter) throws IOException {
String html = this.getHtml(chapter.getUrl());
Document doc = Jsoup.parse(html, "UTF-8");
Element script = doc.getElementsByTag("script").get(2); //获取第三个脚本的数据
// 获取的script 无法直接解析,必须先将 page url 取出来,
// 这里以 [ ] 为界限,分割字符串。
String pageUrls = script.data();
int start = pageUrls.indexOf("[");
int end = pageUrls.indexOf("]") + 1;
String urls = pageUrls.substring(start, end);
//json 转 集合,这个可以总结一下,不熟悉。
List<String> urlList = JSONArray.parseArray(urls, String.class);
AtomicInteger index=new AtomicInteger(0); //我无法使用索引,这是别人推荐的方式
return urlList.stream() //注意这里拼接的不是 root 路径,而是一个新的路径
.map(url->new ComicPage(index.getAndIncrement(),"https://restp.dongqiniqin.com//"+url))
.collect(Collectors.toList());
}
}Remarque : Mon idée ici est que toutes les bandes dessinées sont stockées dans le répertoire DIR_PATH. Ensuite, chaque chapitre est un sous-répertoire (nommé d'après le nom du chapitre), puis les bandes dessinées de chaque chapitre sont placées dans un répertoire, mais il y a un problème ici. Parce que les bandes dessinées sont en fait lues page par page, il y a un problème avec l'ordre des bandes dessinées (après tout, une pile de bandes dessinées dans le désordre semble très laborieuse, même si je ne suis pas ici pour lire des bandes dessinées). J'ai donc donné un numéro à chaque page de bande dessinée et je l'ai numérotée selon l'ordre indiqué dans le script ci-dessus. Mais comme j'utilise les expressions Lambda de Java8, je ne peux pas utiliser l'index. (Cela implique un autre problème). La solution ici est celle que j'ai vue recommandée par d'autres : vous pouvez augmenter la valeur de l'index à chaque fois que vous appelez la méthode getAndIncrement de l'index, ce qui est très pratique.
AtomicInteger index=new AtomicInteger(0); //我无法使用索引,这是别人推荐的方式 return urlList.stream() //注意这里拼接的不是 root 路径,而是一个新的路径 .map(url->new ComicPage(index.getAndIncrement(),"https://restp.dongqiniqin.com//"+url)) .collect(Collectors.toList());
Deux classes d'entités, parce qu'elles sont orientées objet, j'ai conçu deux classes d'entités simples pour encapsuler les informations, ce qui rend l'opération plus pratique.
La classe Chapter représente les informations de chaque chapitre de l'annuaire, le nom du chapitre et le lien vers le chapitre. La classe ComicPage représente chaque page d'informations sur la bande dessinée dans chaque chapitre, le numéro et l'adresse du lien de chaque page.
package com.comic;
public class Chapter {
private String name; //章节名
private String url; //对应章节的链接
public Chapter(String name, String url) {
this.name = name;
this.url = url;
}
public String getName() {
return name;
}
public String getUrl() {
return url;
}
@Override
public String toString() {
return "Chapter [name=" + name + ", url=" + url + "]";
}
}package com.comic;
public class ComicPage {
private int number; //每一页的序号
private String url; //每一页的链接
public ComicPage(int number, String url) {
this.number = number;
this.url = url;
}
public int getNumber() {
return number;
}
public String getUrl() {
return url;
}
}因为前几天使用多线程下载类爬取图片,发现速度太快了,ip 好像被封了,所以就又写了一个当线程的下载类。 它的逻辑很简单,主要是获取对应的漫画页链接,然后使用get请求,将它保存到对应的文件夹中。(它的功能大概和获取网络中的一张图片类似,既然你可以获取一张,那么成千上百也没有问题了。)
package com.comic;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.Random;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.util.EntityUtils;
import com.m3u8.HttpClientUtil;
public class SinglePictureDownloader {
private CloseableHttpClient httpClient;
private ComicPage page;
private String filePath;
private String[] headers = {
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11",
"Opera/9.25 (Windows NT 5.1; U; en)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12",
"Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9",
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
};
public SinglePictureDownloader(ComicPage page, String filePath) {
this.httpClient = HttpClientUtil.getHttpClient();
this.page = page;
this.filePath = filePath;
}
public void download() {
HttpGet get = new HttpGet(page.getUrl());
String url = page.getUrl();
//取文件的扩展名
String prefix = url.substring(url.lastIndexOf("."));
Random rand = new Random();
//设置请求头
get.setHeader("User-Agent", headers[rand.nextInt(headers.length)]);
HttpEntity entity = null;
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
entity = response.getEntity();
if (entity != null) {
File picFile = new File(filePath, page.getNumber()+prefix);
try (OutputStream out = new BufferedOutputStream(new FileOutputStream(picFile))) {
entity.writeTo(out);
System.out.println("下载完毕:" + picFile.getAbsolutePath());
}
}
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
//关闭实体,关于 httpClient 的关闭资源,有点不太了解。
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}package com.comic;
public class Main {
public static void main(String[] args) {
String root = "https://www.manhuaniu.com/"; //网站根路径,用于拼接字符串
String url = "https://www.manhuaniu.com/manhua/5830/"; //第一张第一页的url
ComicSpider spider = new ComicSpider(url, root);
spider.start();
}
}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



