
 Périphériques technologiques
IA
Le modèle nouvelle génération d'OpenAI est une explosion open source ! Plus rapide et plus fort que Diffusion, une œuvre de Song Yang, ancien élève de Tsinghua
Périphériques technologiques
IA
Le modèle nouvelle génération d'OpenAI est une explosion open source ! Plus rapide et plus fort que Diffusion, une œuvre de Song Yang, ancien élève de Tsinghua
Le modèle nouvelle génération d'OpenAI est une explosion open source ! Plus rapide et plus fort que Diffusion, une œuvre de Song Yang, ancien élève de Tsinghua

Le domaine de la génération d'images semble à nouveau évoluer.
Tout à l'heure, OpenAI a open source un modèle de cohérence plus rapide et meilleur que le modèle de diffusion :
Vous pouvez générer des images de haute qualité sans entraînement contradictoire !
Dès que cette nouvelle à succès a été publiée, elle a immédiatement fait exploser le cercle académique.

Bien que l'article lui-même ait été publié de manière discrète en mars, à cette époque, on pensait généralement qu'il s'agissait simplement d'une recherche de pointe sur OpenAI et que les détails ne seraient pas vraiment rendus publics.

Je ne m'attendais pas à ce qu'un open source vienne directement cette fois. Certains internautes ont immédiatement commencé à tester l'effet et ont constaté qu'il ne fallait que 3,5 secondes environ pour générer environ 64 images 256×256 :
Game over !

C'est l'effet d'image généré par cet internaute, qui a l'air plutôt bien :

Certains internautes ont plaisanté : Cette fois, OpenAI est enfin ouvert !

Il convient de mentionner que le premier auteur de l'article, le scientifique d'OpenAI Song Yang, est un ancien élève de Tsinghua. À l'âge de 16 ans, il est entré dans la classe de sciences mathématiques et physiques fondamentales de Tsinghua dans le cadre du programme de leadership.
Jetons un coup d'œil au type de recherche qu'OpenAI a réalisée en open source cette fois-ci.
Quels types de recherches à succès ont été open source ?
En tant qu'IA de génération d'images, la plus grande caractéristique du modèle de cohérence est qu'il est rapide et efficace.
Par rapport au modèle de diffusion, il présente deux avantages principaux :
Premièrement, il peut générer directement des échantillons d'images de haute qualité sans formation contradictoire.
Deuxièmement, par rapport au modèle de diffusion, qui peut nécessiter des centaines, voire des milliers d'itérations, le modèle de cohérence n'a besoin que d'une ou deux étapes pour gérer une variété de tâches d'image -
y compris la coloration, le débruitage, le super-scoring, etc. Cela peut se faire en quelques étapes sans nécessiter de formation explicite à ces tâches. (Bien sûr, si un apprentissage en quelques coups est effectué, l'effet de génération sera meilleur)

Alors, comment le modèle de cohérence obtient-il cet effet ?
D'un point de vue principe, la naissance du modèle de cohérence est liée au modèle de diffusion de génération ODE (équation différentielle ordinaire).
Comme on peut le voir sur la figure, ODE convertira d'abord les données d'image en bruit étape par étape, puis effectuera une solution inverse pour apprendre à générer des images à partir du bruit.
Dans ce processus, les auteurs ont essayé de mapper n'importe quel point de la trajectoire ODE (comme Xt, Xt et Xr) à son origine (comme X0) pour une modélisation générative.
Par la suite, ce modèle cartographié a été nommé modèle de cohérence, car leurs sorties sont toutes au même point sur la même trajectoire :

Basé sur cette idée, le modèle de cohérence n'a pas besoin de passer par de longues itérations pour atteindre Générez une image de relativement haute qualité, mais elle peut être générée en une seule étape.
La figure suivante est une comparaison du modèle de cohérence (CD) et du modèle de diffusion (PD) sur l'indice de génération d'image FID.
Parmi eux, PD est l'abréviation de distillation progressive (distillation progressive), une dernière méthode de modèle de diffusion proposée par Stanford et Google Brain l'année dernière, et CD (distillation de consistance) est la méthode de distillation de consistance.
On peut voir que l'effet de génération d'image du modèle de cohérence est meilleur que celui du modèle de diffusion sur presque tous les ensembles de données, la seule exception est l'ensemble de données de pièce 256×256 :

A part ça, les auteurs ont également comparé des modèles tels que le modèle de diffusion, le modèle de cohérence et le GAN sur divers autres ensembles de données :
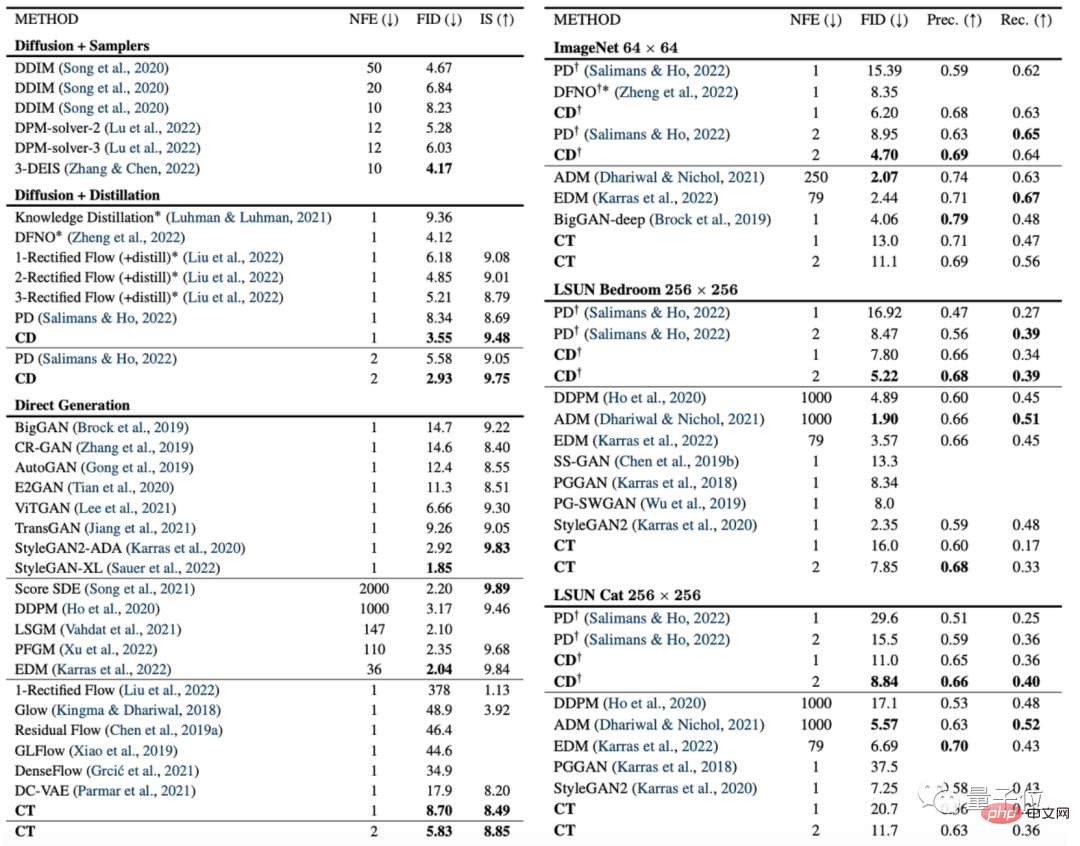
Cependant, certains internautes ont mentionné que les images générées par le modèle de cohérence de l'IA open source cette fois sont encore trop petites :
C'est triste que les images générées par la version open source cette fois soient encore trop petites. peut donner Générer une version open source d'images plus grandes serait certainement passionnant.
Certains internautes ont également émis l'hypothèse qu'OpenAI n'avait peut-être pas encore été formé. Mais peut-être qu'après l'entraînement, nous ne pourrons peut-être pas obtenir le code (tête de chien manuelle).
Mais concernant l'importance de ce travail, TechCrunch a déclaré :
Si vous disposez de plusieurs GPU, utilisez le modèle de diffusion pour itérer plus de 1 500 fois en une minute ou deux, et l'effet de la génération d'images sera bien sûr excellent.
Mais si vous souhaitez générer des images en temps réel sur votre téléphone ou lors d'une conversation chat, alors évidemment le modèle de diffusion n'est pas le meilleur choix.
Le modèle de cohérence est la prochaine étape importante d'OpenAI.
Dans l'attente d'OpenAI open source, une vague d'IA de génération d'images avec une résolution plus élevée ~
Song Yang, ancien élève de Tsinghua, est le premier auteur
Song Yang est le premier auteur de l'article et est actuellement chercheur scientifique à OpenAI.

Quand il avait 14 ans, il a été sélectionné dans le « Programme de leadership du nouveau centenaire de l'Université Tsinghua » avec les votes unanimes de 17 juges. Lors de l'examen d'entrée à l'université l'année suivante, il est devenu le meilleur score en sciences de la ville de Lianyungang et a été admis avec succès à l'Université Tsinghua.
En 2016, Song Yang est diplômé du cours de base de mathématiques et de physique de l'Université Tsinghua, puis est allé à Stanford pour poursuivre ses études. En 2022, Song Yang a obtenu un doctorat en informatique à Stanford puis a rejoint OpenAI.
Au cours de son doctorat, son premier article « Modélisation générative basée sur les scores à travers des équations différentielles stochastiques » a également remporté le prix ICLR 2021 Outstanding Paper Award.

Selon les informations figurant sur sa page d'accueil personnelle, Song Yang rejoindra officiellement le Département d'électronique et de sciences mathématiques computationnelles du California Institute of Technology en tant que professeur assistant à partir de janvier 2024.
Adresse du projet :
https://www.php.cn/link/4845b84d63ea5fa8df6268b8d1616a8f
Adresse papier :
https://www.php.cn/link/5f25fbe144e4a81a1 b0080b6c1032778
Lien de référence :
[1]https://twitter.com/alfredplpl/status/1646217811898011648
[2]https://twitter.com/_akhaliq/status/1646168119658831874
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Lien du projet écrit devant : https://nianticlabs.github.io/mickey/ Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle. Cet article propose MicKey, un processus de correspondance de points clés capable de prédire les correspondances métriques dans l'espace d'une caméra 3D. En apprenant la correspondance des coordonnées 3D entre les images, nous sommes en mesure de déduire des métriques relatives.
 Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Le FP8 et la précision de quantification inférieure en virgule flottante ne sont plus le « brevet » du H100 ! Lao Huang voulait que tout le monde utilise INT8/INT4, et l'équipe Microsoft DeepSpeed a commencé à exécuter FP6 sur A100 sans le soutien officiel de NVIDIA. Les résultats des tests montrent que la quantification FP6 de la nouvelle méthode TC-FPx sur A100 est proche ou parfois plus rapide que celle de INT4, et a une précision supérieure à celle de cette dernière. En plus de cela, il existe également une prise en charge de bout en bout des grands modèles, qui ont été open source et intégrés dans des cadres d'inférence d'apprentissage profond tels que DeepSpeed. Ce résultat a également un effet immédiat sur l'accélération des grands modèles : dans ce cadre, en utilisant une seule carte pour exécuter Llama, le débit est 2,65 fois supérieur à celui des cartes doubles. un
 Docker achève le déploiement local du grand modèle open source LLama3 en trois minutes
Apr 26, 2024 am 10:19 AM
Docker achève le déploiement local du grand modèle open source LLama3 en trois minutes
Apr 26, 2024 am 10:19 AM
LLaMA-3 (LargeLanguageModelMetaAI3) est un modèle d'intelligence artificielle générative open source à grande échelle développé par Meta Company. Il ne présente aucun changement majeur dans la structure du modèle par rapport à la génération précédente LLaMA-2. Le modèle LLaMA-3 est divisé en différentes versions, notamment petite, moyenne et grande, pour répondre aux différents besoins d'application et ressources informatiques. La taille des paramètres des petits modèles est de 8B, la taille des paramètres des modèles moyens est de 70B et la taille des paramètres des grands modèles atteint 400B. Cependant, lors de la formation, l'objectif est d'atteindre une fonctionnalité multimodale et multilingue, et les résultats devraient être comparables à GPT4/GPT4V. Installer OllamaOllama est un grand modèle de langage open source (LL
