
 Périphériques technologiques
IA
L'équipe chinoise renverse son CV ! SEEM divise parfaitement toutes les explosions et divise 'l'univers instantané' en un seul clic
Périphériques technologiques
IA
L'équipe chinoise renverse son CV ! SEEM divise parfaitement toutes les explosions et divise 'l'univers instantané' en un seul clic
L'équipe chinoise renverse son CV ! SEEM divise parfaitement toutes les explosions et divise 'l'univers instantané' en un seul clic

L’émergence du « Divide Everything » de Meta a amené de nombreuses personnes à s’exclamer que le CV n’existe plus.
Sur la base de ce modèle, de nombreux internautes ont réalisé d'autres travaux, comme Grounded SAM.
En utilisant Stable Diffusion, Whisper et ChatGPT ensemble, vous pouvez transformer un chien en singe par la voix.

Et maintenant, pas seulement la voix, vous pouvez tout segmenter partout à la fois grâce à des invites multimodales.
Comment le faire spécifiquement ?
Cliquez sur la souris pour sélectionner directement le contenu divisé.

Ouvre la bouche.

Glissez-le simplement et le package complet d'émoticônes sera là.

Vous pouvez même diviser la vidéo.

La dernière recherche sur SEEM a été réalisée conjointement par des chercheurs de l'Université du Wisconsin-Madison, de Microsoft Research et d'autres institutions.
Segmentez facilement les images à l'aide de différents types d'indices, d'indices visuels (points, marqueurs, cases, gribouillis et fragments d'images) et d'indices verbaux (texte et audio) avec SEEM.

Adresse papier : https://arxiv.org/pdf/2304.06718.pdf
La chose intéressante à propos du titre de cet article est qu'il est lié à une science-fiction américaine film sorti en 2022 « Everything Everywhere All at Once » porte un nom très similaire.

Jim Fan, scientifique chez NVIDIA, a déclaré que l'Oscar du meilleur titre d'article revient à "Segment Everything Everywhere All at Once"
Avoir une interface de spécification de tâches unifiée et multifonctionnelle est la base de l'expansion La taille du modèle à grande échelle est essentielle. Les invites multimodales sont la voie de l’avenir.

Après avoir lu le journal, les internautes ont déclaré que CV commençait désormais à adopter les grands modèles. Où est l'avenir des étudiants diplômés ?

Oscar Best Titled Paper
Il a été inspiré par le développement d'interfaces universelles basées sur des invites pour les LLM que les chercheurs ont proposé SEEM.
Comme le montre la figure, le modèle SEEM peut effectuer n'importe quelle tâche de segmentation dans l'ensemble ouvert sans indice, telle que la segmentation sémantique, la segmentation d'instance et la segmentation panoramique.
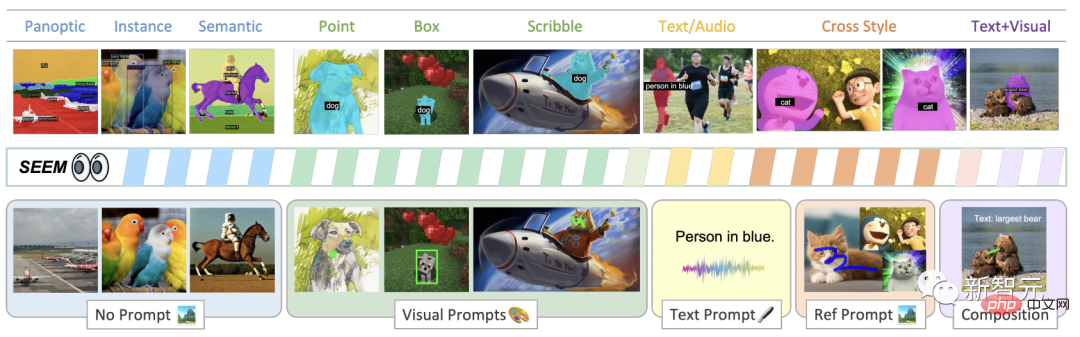
De plus, il prend en charge toute combinaison d'indications visuelles, textuelles et de zones de citation, permettant un fractionnement de devis polyvalent et interactif.
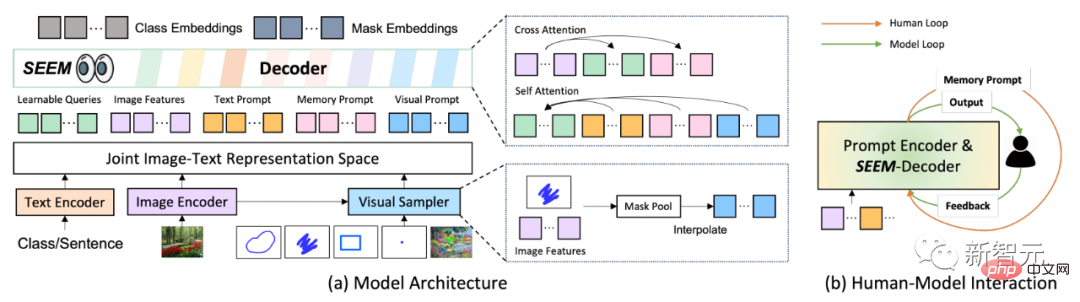
En termes d'architecture de modèle, SEEM adopte une architecture codeur-décodeur commune. Ce qui le rend unique, c'est l'interaction complexe entre les requêtes et les invites.
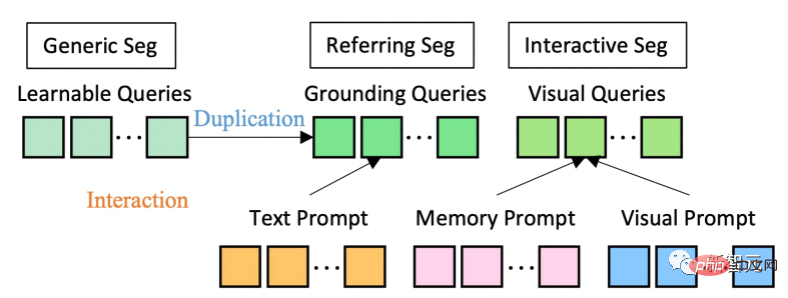
Les caractéristiques et les indices sont codés dans un espace sémantique visuel commun par les encodeurs correspondants, ou échantillonneurs.
La requête apprenable est initialisée de manière aléatoire et le décodeur SEEM accepte la requête apprenable, les fonctionnalités d'image et les indications de texte en entrée et en sortie, y compris les intégrations de classes et de masques pour la prédiction de masque et sémantique.
Il convient de mentionner que le modèle SEEM comporte plusieurs cycles d'interactions. Chaque tour se compose d'un cycle manuel et d'un cycle modèle.
Dans la boucle manuelle, la sortie du masque de l'itération précédente est reçue manuellement et un retour positif pour le prochain cycle de décodage est donné via des repères visuels. Dans la boucle du modèle, le modèle reçoit et met à jour les signaux de mémoire pour les prédictions futures.
Grâce à SEEM, à partir d'une photo du camion d'Optimus Prime, vous pouvez segmenter Optimus Prime sur n'importe quelle image cible.

Générez des masques à partir du texte saisi par l'utilisateur pour une segmentation en un clic.

De plus, SEEM peut segmenter des objets ayant une sémantique similaire sur l'image cible en cliquant ou en griffonnant simplement sur l'image de référence.

De plus, SEEM comprend très bien les relations entre les solutions et l'espace. Une fois les graffitis sur les zèbres de la rangée supérieure gauche, le zèbre le plus à gauche sera également segmenté.

SEEM peut également référencer des images à des masques vidéo, qui peuvent parfaitement segmenter des vidéos sans aucune formation sur les données vidéo.


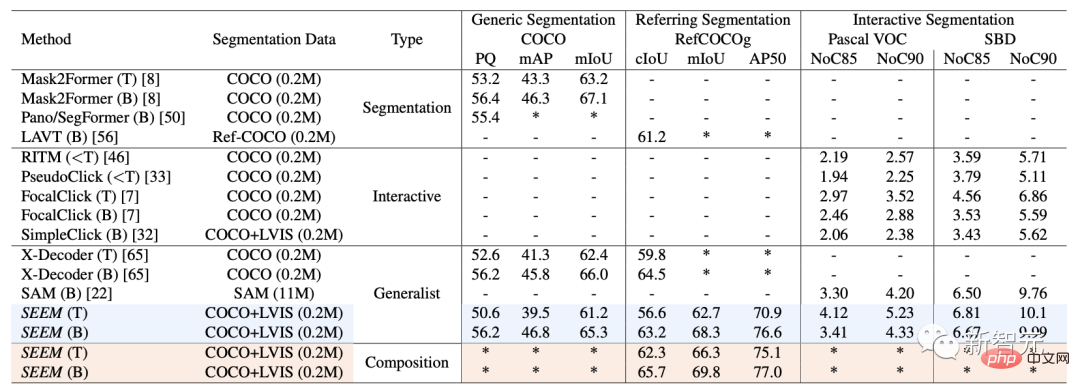
Sur les jeux de données et les paramètres, SEEM a été formé sur trois jeux de données : la segmentation panoramique, la segmentation de référence et la segmentation interactive.
Segmentation interactive
Sur la segmentation interactive, les chercheurs ont comparé SEEM avec des modèles de segmentation interactive de pointe.
En tant que modèle général, SEEM a atteint des performances comparables à RITM, SimpleClick, etc. Et il atteint des performances très similaires à celles de SAM. SAM utilise également 50 données segmentées supplémentaires pour la formation.
Contrairement aux modèles interactifs existants, SEEM est le premier à prendre en charge non seulement les tâches de segmentation classiques, mais également un large éventail d'entrées multimodales, notamment du texte, des points, des gribouillages, des cadres de délimitation et des images offrant de puissantes capacités de combinaison.
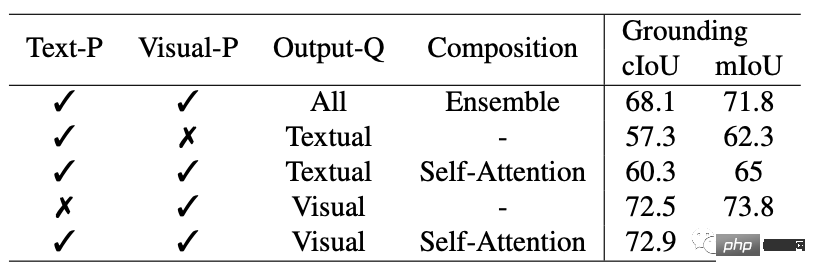
Segmentation universelle
Avec un ensemble de paramètres pré-entraînés pour toutes les tâches de segmentation, les chercheurs peuvent évaluer directement ses performances sur des ensembles de données de segmentation universelle.
SEEM permet d'obtenir de meilleures performances de vue panoramique, d'instance et de segmentation sémantique.
Les chercheurs ont quatre objectifs attendus pour SEEM :
1. Polyvalence : en introduisant un moteur d'invite multifonctionnel pour gérer différents types d'invites, notamment des points, des cases, des graffitis, des masques et du texte. et une région de référence d'une autre image ;
2. Composite : en apprenant un espace visuel-sémantique commun pour combiner des requêtes instantanées d'indices visuels et textuels pour le raisonnement ;
3. préserver les informations de l'historique des conversations via une attention croisée guidée par un masque ;
4. Activez la segmentation ouverte du vocabulaire en utilisant un encodeur de texte pour encoder les requêtes de texte et les balises de masque. La différence entre
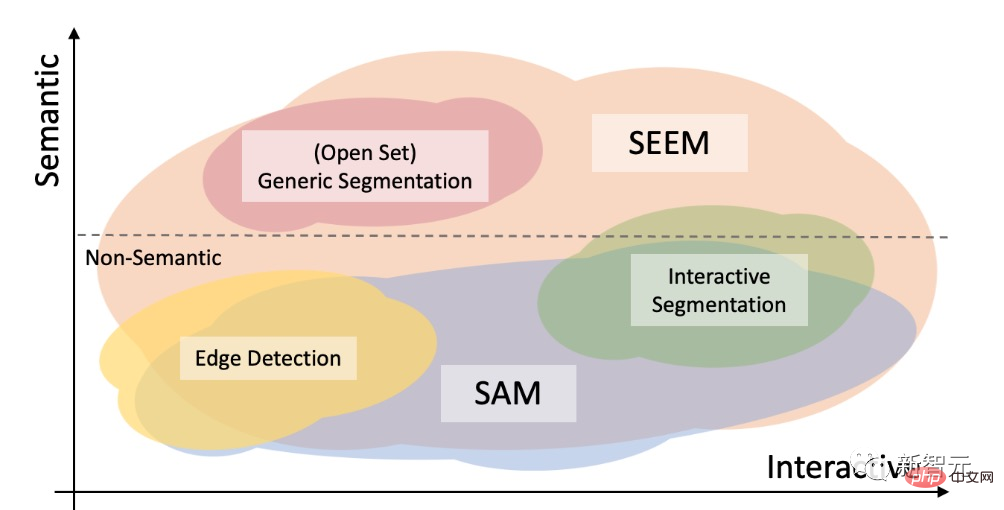
et SAM
Le modèle SAM proposé par Meta peut spécifier un point, un cadre de délimitation et une phrase dans un encodeur d'invite de cadre unifié pour segmenter les objets en un seul clic.

SAM a une grande polyvalence, c'est-à-dire qu'il a la capacité de transfert sans échantillon, ce qui est suffisant pour couvrir divers cas d'utilisation. Il ne nécessite pas de formation supplémentaire et peut être utilisé immédiatement. dans de nouveaux champs d'image, qu'il s'agisse d'une photo sous-marine ou d'un microscope cellulaire.

Les chercheurs ont comparé SEEM et SAM en termes de capacités interactives et sémantiques pour trois tâches de segmentation (détection de contours, ensemble ouvert et segmentation interactive).
La segmentation en ensemble ouvert nécessite également une sémantique de haut niveau et ne nécessite pas d'interaction.
Par rapport à SAM, SEEM couvre un plus large éventail d'interactions et de niveaux sémantiques.
SAM ne prend en charge que des types d'interaction limités, tels que les points et les cadres de délimitation, et ignore les tâches sémantiques élevées car il ne génère pas lui-même d'étiquettes sémantiques.
Pour SEEM, les chercheurs ont mis en évidence deux points forts :
Premièrement, SEEM dispose d'un encodeur de signaux unifié qui encode tous les signaux visuels et linguistiques dans un espace de représentation commun. Par conséquent, SEEM peut prendre en charge une utilisation plus générale et peut potentiellement être étendu à des invites personnalisées.
Deuxièmement, SEEM fait un excellent travail de masquage de texte et de génération de prédictions sémantiques.
Introduction à l'auteur
La première auteure de l'article Xueyan Zou
Elle est actuellement doctorante au Département d'informatique de l'Université du Wisconsin-Madison, et son superviseur est le professeur Yong Jae Lee.
Avant cela, Zou a passé trois ans à l'Université de Californie à Davis, sous la direction du même mentor et a travaillé en étroite collaboration avec le Dr Fanyi Xiao.
Elle a obtenu son baccalauréat de l'Université baptiste de Hong Kong, supervisé par le professeur PC Yuen et le professeur Chu Xiaowen.

Jianwei Yang

Yang est chercheur principal au sein du groupe d'apprentissage profond de Microsoft Research à Redmond, supervisé par le Dr Jianfeng Gao.
Les recherches de Yang se concentrent principalement sur la vision par ordinateur, la vision et le langage, ainsi que sur l’apprentissage automatique. Il se concentre sur différents niveaux de compréhension visuelle structurée et sur la manière dont ils peuvent être exploités davantage pour une interaction intelligente avec les humains à travers le langage et l'incarnation environnementale.
Avant de rejoindre Microsoft en mars 2020, Yang a obtenu son doctorat en informatique de la School of Interactive Computing de Georgia Tech, où son conseiller était le professeur Devi Parikh, et il a également travaillé en étroite collaboration avec le professeur Dhruv Batra.
Gao Jianfeng

Gao Jianfeng est un scientifique distingué et vice-président de Microsoft Research, membre de l'IEEE et membre distingué de l'ACM.
Actuellement, Gao Jianfeng dirige le groupe d'apprentissage profond. La mission du groupe est de faire progresser l'état de l'art de l'apprentissage profond et ses applications dans la compréhension du langage naturel et des images, et de faire progresser les modèles et méthodes de conversation.
La recherche comprend principalement des modèles de langage neuronal pour la compréhension et la génération du langage naturel, l'informatique symbolique neuronale, la fondation et la compréhension du langage visuel, l'intelligence artificielle conversationnelle, etc.
De 2014 à 2018, Gao Jianfeng a été responsable de recherche partenaire pour l'intelligence artificielle commerciale au sein du département d'intelligence artificielle et de recherche de Microsoft et du Deep Learning Technology Center (DLTC) de Redmond Microsoft Research.
De 2006 à 2014, Gao Jianfeng a été chercheur en chef du groupe de traitement du langage naturel.
Yong Jae Lee

Lee est professeur agrégé au département d'informatique de l'Université de Washington, Madison.
Il a passé un an en tant qu'instructeur invité en intelligence artificielle à Cruise avant de rejoindre l'UW-Madison à l'automne 2021, et avant cela, il a passé 6 ans en tant qu'assistant et professeur associé à l'Université de Californie à Davis.
Il a également passé un an en tant que chercheur postdoctoral à l'Institut de robotique de l'Université Carnegie Mellon.
Il a obtenu son doctorat de l'Université du Texas à Austin en mai 2012, étudiant avec Kristen Grauman, et son BA de l'Université de l'Illinois à Urbana-Champaign en mai 2006.
Il a également travaillé comme stagiaire d'été chez Microsoft Research avec Larry Zitnick et Michael Cohen.
Actuellement, les recherches de Lee se concentrent sur la vision par ordinateur et l’apprentissage automatique. Lee est particulièrement intéressé par la création de puissants systèmes de reconnaissance visuelle capables de comprendre les données visuelles avec une supervision humaine minimale.
Actuellement, SEEM a ouvert une démo :
https://huggingface.co/spaces/xdecoder/SEEM
Dépêchez-vous et essayez-la.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1207
24
52
1207
24

 Où sont stockés les fichiers vidéo dans le cache du navigateur ?
Feb 19, 2024 pm 05:09 PM
Où sont stockés les fichiers vidéo dans le cache du navigateur ?
Feb 19, 2024 pm 05:09 PM
Dans quel dossier le navigateur met-il la vidéo en cache ? Lorsque nous utilisons le navigateur Internet quotidiennement, nous regardons souvent diverses vidéos en ligne, comme regarder des clips vidéo sur YouTube ou regarder des films sur Netflix. Ces vidéos seront mises en cache par le navigateur pendant le processus de chargement afin qu'elles puissent être chargées rapidement lors d'une nouvelle lecture ultérieure. La question est donc de savoir dans quel dossier ces vidéos mises en cache sont réellement stockées ? Différents navigateurs stockent les dossiers vidéo mis en cache à différents emplacements. Ci-dessous, nous présenterons plusieurs navigateurs courants et leurs
 Est-ce une infraction de publier des vidéos d'autres personnes sur Douyin ? Comment éditer des vidéos sans infraction ?
Mar 21, 2024 pm 05:57 PM
Est-ce une infraction de publier des vidéos d'autres personnes sur Douyin ? Comment éditer des vidéos sans infraction ?
Mar 21, 2024 pm 05:57 PM
Avec l'essor des plateformes de vidéos courtes, Douyin est devenu un élément indispensable de la vie quotidienne de chacun. Sur TikTok, nous pouvons voir des vidéos intéressantes du monde entier. Certaines personnes aiment publier les vidéos d’autres personnes, ce qui soulève une question : Douyin enfreint-il la publication de vidéos d’autres personnes ? Cet article abordera ce problème et vous expliquera comment éditer des vidéos sans infraction et comment éviter les problèmes d'infraction. 1. Cela porte-t-il atteinte à la publication par Douyin de vidéos d'autres personnes ? Selon les dispositions de la loi sur le droit d'auteur de mon pays, l'utilisation non autorisée des œuvres du titulaire du droit d'auteur sans l'autorisation du titulaire du droit d'auteur constitue une infraction. Par conséquent, publier des vidéos d’autres personnes sur Douyin sans l’autorisation de l’auteur original ou du titulaire des droits d’auteur constitue une infraction. 2. Comment monter une vidéo sans contrefaçon ? 1. Utilisation de contenu du domaine public ou sous licence : Public
 Comment supprimer le filigrane vidéo dans Wink
Feb 23, 2024 pm 07:22 PM
Comment supprimer le filigrane vidéo dans Wink
Feb 23, 2024 pm 07:22 PM
Comment supprimer les filigranes des vidéos dans Wink ? Il existe un outil pour supprimer les filigranes des vidéos dans winkAPP, mais la plupart des amis ne savent pas comment supprimer les filigranes des vidéos dans Wink. Voici ensuite l'image de la façon de supprimer les filigranes des vidéos dans Wink. apporté par l'éditeur Tutoriel texte, les utilisateurs intéressés viennent y jeter un oeil ! Comment supprimer le filigrane vidéo dans Wink 1. Ouvrez d'abord l'application Wink et sélectionnez la fonction [Supprimer le filigrane] dans la zone de la page d'accueil ; 2. Sélectionnez ensuite la vidéo dont vous souhaitez supprimer le filigrane dans l'album ; dans le coin supérieur droit après avoir édité la vidéo [√] ; 4. Enfin, cliquez sur [Imprimer en un clic] comme indiqué dans la figure ci-dessous, puis cliquez sur [Traiter].
 Comment gagner de l'argent en publiant des vidéos sur Douyin ? Comment un débutant peut-il gagner de l'argent sur Douyin ?
Mar 21, 2024 pm 08:17 PM
Comment gagner de l'argent en publiant des vidéos sur Douyin ? Comment un débutant peut-il gagner de l'argent sur Douyin ?
Mar 21, 2024 pm 08:17 PM
Douyin, la plateforme nationale de courtes vidéos, nous permet non seulement de profiter d'une variété de courtes vidéos intéressantes et originales pendant notre temps libre, mais nous donne également une scène pour nous montrer et réaliser nos valeurs. Alors, comment gagner de l’argent en postant des vidéos sur Douyin ? Cet article répondra à cette question en détail et vous aidera à gagner plus d’argent sur TikTok. 1. Comment gagner de l’argent en publiant des vidéos sur Douyin ? Après avoir posté une vidéo et obtenu un certain nombre de vues sur Douyin, vous aurez la possibilité de participer au plan de partage publicitaire. Cette méthode de revenus est l’une des plus connues des utilisateurs de Douyin et constitue également la principale source de revenus pour de nombreux créateurs. Douyin décide d'offrir ou non des opportunités de partage de publicités en fonction de divers facteurs tels que le poids du compte, le contenu vidéo et les commentaires du public. La plateforme TikTok permet aux téléspectateurs de soutenir leurs créateurs préférés en envoyant des cadeaux,
 2 façons de supprimer le ralenti des vidéos sur iPhone
Mar 04, 2024 am 10:46 AM
2 façons de supprimer le ralenti des vidéos sur iPhone
Mar 04, 2024 am 10:46 AM
Sur les appareils iOS, l'application Appareil photo vous permet de filmer des vidéos au ralenti, voire à 240 images par seconde si vous possédez le dernier iPhone. Cette capacité vous permet de capturer une action à grande vitesse avec des détails riches. Mais parfois, vous souhaiterez peut-être lire des vidéos au ralenti à vitesse normale afin de mieux apprécier les détails et l'action de la vidéo. Dans cet article, nous expliquerons toutes les méthodes pour supprimer le ralenti des vidéos existantes sur iPhone. Comment supprimer le ralenti des vidéos sur iPhone [2 méthodes] Vous pouvez utiliser l'application Photos ou l'application iMovie pour supprimer le ralenti des vidéos sur votre appareil. Méthode 1 : ouvrir sur iPhone à l’aide de l’application Photos
 Comment publier les œuvres vidéo de Xiaohongshu ? À quoi dois-je faire attention lorsque je publie des vidéos ?
Mar 23, 2024 pm 08:50 PM
Comment publier les œuvres vidéo de Xiaohongshu ? À quoi dois-je faire attention lorsque je publie des vidéos ?
Mar 23, 2024 pm 08:50 PM
Avec l'essor des plateformes de vidéos courtes, Xiaohongshu est devenue une plateforme permettant à de nombreuses personnes de partager leur vie, de s'exprimer et de gagner du trafic. Sur cette plateforme, la publication d’œuvres vidéo est un moyen d’interaction très prisé. Alors, comment publier les œuvres vidéo de Xiaohongshu ? 1. Comment publier les œuvres vidéo de Xiaohongshu ? Tout d’abord, assurez-vous d’avoir un contenu vidéo prêt à partager. Vous pouvez utiliser votre téléphone portable ou un autre équipement photo pour prendre des photos, mais vous devez faire attention à la qualité de l'image et à la clarté du son. 2. Editer la vidéo : Afin de rendre le travail plus attrayant, vous pouvez éditer la vidéo. Vous pouvez utiliser un logiciel de montage vidéo professionnel, tel que Douyin, Kuaishou, etc., pour ajouter des filtres, de la musique, des sous-titres et d'autres éléments. 3. Choisissez une couverture : La couverture est la clé pour inciter les utilisateurs à cliquer. Choisissez une image claire et intéressante comme couverture pour inciter les utilisateurs à cliquer dessus.
 Comment convertir des vidéos téléchargées par le navigateur UC en vidéos locales
Feb 29, 2024 pm 10:19 PM
Comment convertir des vidéos téléchargées par le navigateur UC en vidéos locales
Feb 29, 2024 pm 10:19 PM
Comment transformer les vidéos téléchargées par le navigateur UC en vidéos locales ? De nombreux utilisateurs de téléphones mobiles aiment utiliser UC Browser. Ils peuvent non seulement naviguer sur le Web, mais également regarder diverses vidéos et programmes télévisés en ligne et télécharger leurs vidéos préférées sur leurs téléphones mobiles. En fait, nous pouvons convertir des vidéos téléchargées en vidéos locales, mais beaucoup de gens ne savent pas comment le faire. Par conséquent, l'éditeur vous propose spécialement une méthode pour convertir les vidéos mises en cache par le navigateur UC en vidéos locales. J'espère que cela pourra vous aider. Méthode pour convertir les vidéos mises en cache du navigateur uc en vidéos locales 1. Ouvrez le navigateur uc et cliquez sur l'option "Menu". 2. Cliquez sur « Télécharger/Vidéo ». 3. Cliquez sur « Vidéo mise en cache ». 4. Appuyez longuement sur n'importe quelle vidéo, lorsque les options apparaissent, cliquez sur « Ouvrir le répertoire ». 5. Cochez ceux que vous souhaitez télécharger
 Comment publier des vidéos sur Weibo sans compresser la qualité de l'image_Comment publier des vidéos sur Weibo sans compresser la qualité de l'image
Mar 30, 2024 pm 12:26 PM
Comment publier des vidéos sur Weibo sans compresser la qualité de l'image_Comment publier des vidéos sur Weibo sans compresser la qualité de l'image
Mar 30, 2024 pm 12:26 PM
1. Ouvrez d'abord Weibo sur votre téléphone mobile et cliquez sur [Moi] dans le coin inférieur droit (comme indiqué sur l'image). 2. Cliquez ensuite sur [Gear] dans le coin supérieur droit pour ouvrir les paramètres (comme indiqué sur l'image). 3. Ensuite, recherchez et ouvrez [Paramètres généraux] (comme indiqué sur l'image). 4. Entrez ensuite l'option [Video Follow] (comme indiqué sur l'image). 5. Ensuite, ouvrez le paramètre [Résolution de téléchargement vidéo] (comme indiqué sur l'image). 6. Enfin, sélectionnez [Qualité d'image originale] pour éviter la compression (comme indiqué sur l'image).
