
 développement back-end
Tutoriel Python
Comment implémenter la copie d'objets et la disposition de la mémoire en Python
développement back-end
Tutoriel Python
Comment implémenter la copie d'objets et la disposition de la mémoire en Python
Comment implémenter la copie d'objets et la disposition de la mémoire en Python

Préface
Connaissez-vous les résultats de sortie de certains des extraits de programme ci-dessous ?
a = [1, 2, 3, 4]
b = a
print(f"{a = } \t|\t {b = }")
a[0] = 100
print(f"{a = } \t|\t {b = }")a = [1, 2, 3, 4]
b = a.copy()
print(f"{a = } \t|\t {b = }")
a[0] = 100
print(f"{a = } \t|\t {b = }")a = [[1, 2, 3], 2, 3, 4]
b = a.copy()
print(f"{a = } \t|\t {b = }")
a[0][0] = 100
print(f"{a = } \t|\t {b = }")a = [[1, 2, 3], 2, 3, 4]
b = copy.copy(a)
print(f"{a = } \t|\t {b = }")
a[0][0] = 100
print(f"{a = } \t|\t {b = }")a = [[1, 2, 3], 2, 3, 4]
b = copy.deepcopy(a)
print(f"{a = } \t|\t {b = }")
a[0][0] = 100
print(f"{a = } \t|\t {b = }")Disposition de la mémoire des objets Python
Comment devons-nous déterminer l'adresse mémoire d'un objet en python ? Python nous fournit une fonction intégrée id() pour obtenir l'adresse mémoire d'un objet :
a = [1, 2, 3, 4]
b = a
print(f"{a = } \t|\t {b = }")
a[0] = 100
print(f"{a = } \t|\t {b = }")
print(f"{id(a) = } \t|\t {id(b) = }")
# 输出结果
# a = [1, 2, 3, 4] | b = [1, 2, 3, 4]
# a = [100, 2, 3, 4] | b = [100, 2, 3, 4]
# id(a) = 4393578112 | id(b) = 4393578112En fait, il y a un problème avec la disposition mémoire de l'objet ci-dessus, ou elle n'est pas assez précise, mais cela peut quand même être exprimé Examinons de plus près la relation entre chaque objet. Dans Cpython, vous pouvez considérer chaque variable comme un pointeur, pointant vers les données représentées. Ce pointeur enregistre l'adresse mémoire de l'objet Python.
En Python, la liste stocke en fait des pointeurs vers chaque objet Python, pas les données réelles. Par conséquent, le petit morceau de code ci-dessus peut être utilisé pour représenter la disposition des objets dans la mémoire comme suit :
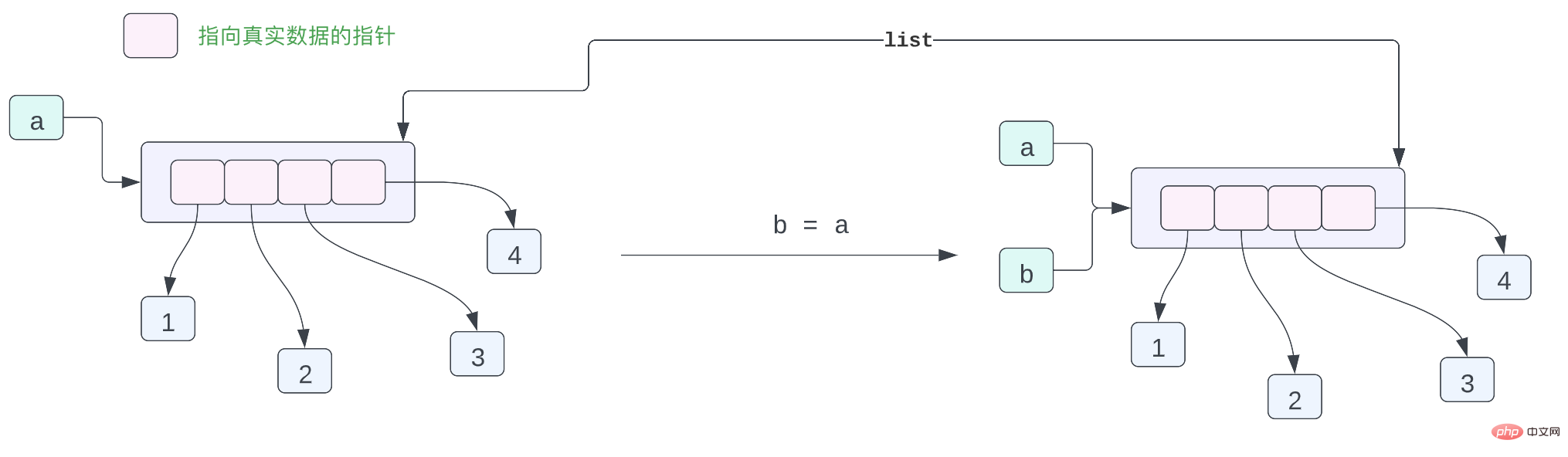
Variables. a pointe vers la liste [1, 2, 3, 4] dans la mémoire. Il y a 4 données dans la liste. Ces quatre données sont des pointeurs, et ces quatre pointeurs pointent vers 1, 2 dans la liste. mémoire 3, 4 ces quatre données. Vous avez peut-être des questions, n'est-ce pas un problème ? Puisqu'il s'agit toutes de données entières, pourquoi ne pas stocker les données entières directement dans la liste. Pourquoi avons-nous besoin d'ajouter un pointeur pour pointer vers ces données ? [1, 2, 3, 4],列表当中有 4 个数据,这四个数据都是指针,而这四个指针指向内存当中 1,2,3,4 这四个数据。可能你会有疑问,这不是有问题吗?都是整型数据为什么不直接在列表当中存放整型数据,为啥还要加一个指针,再指向这个数据呢?
事实上在 Python 当中,列表当中能够存放任何 Python 对象,比如下面的程序是合法的:
data = [1, {1:2, 3:4}, {'a', 1, 2, 25.0}, (1, 2, 3), "hello world"]在上面的列表当中第一个到最后一个数据的数据类型为:整型数据,字典,集合,元祖,字符串,现在来看为了实现 Python 的这个特性,指针的特性是不是符合要求呢?每个指针所占用的内存是一样的,因此可以使用一个数组去存储 Python 对象的指针,然后再将这个指针指向真正的 Python 对象!
牛刀小试
在经过上面的分析之后,我们来看一下下面的代码,他的内存布局是什么情况:
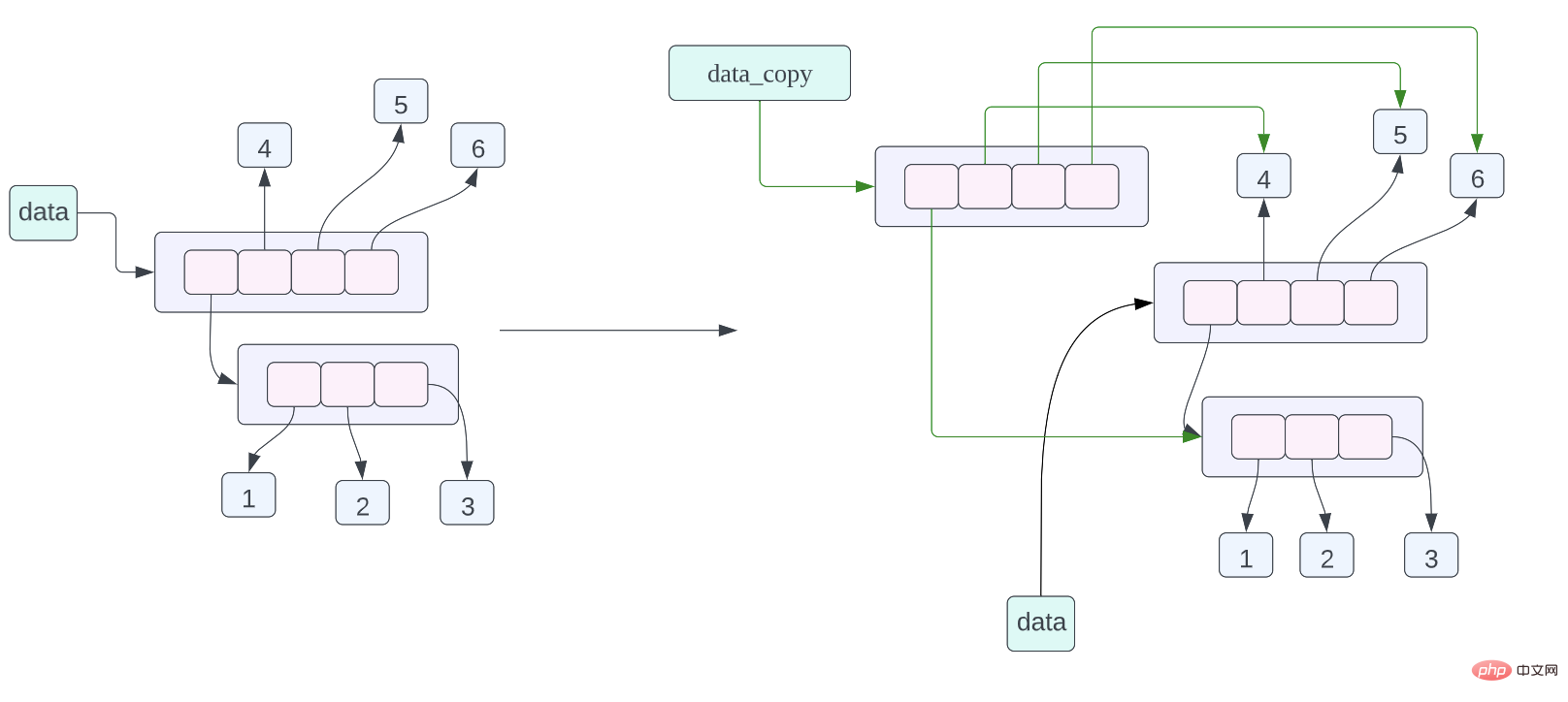
data = [[1, 2, 3], 4, 5, 6] data_assign = data data_copy = data.copy()
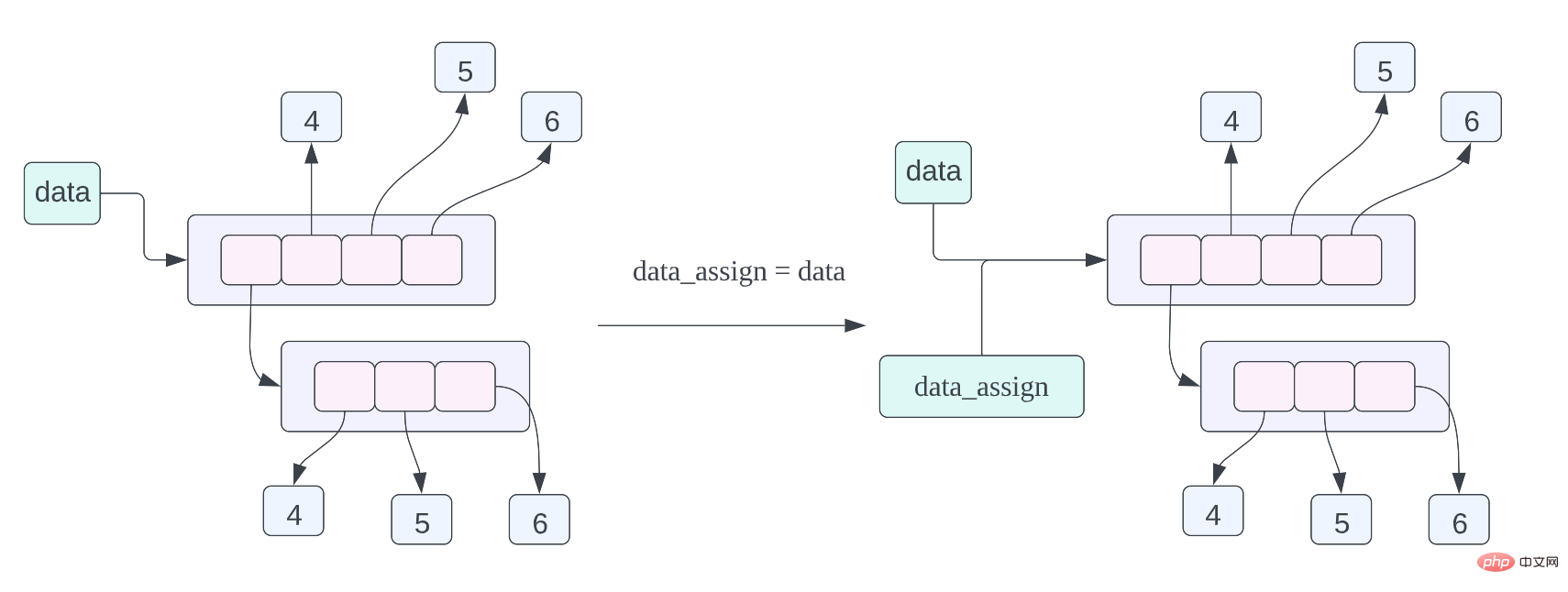
data_assign = data,关于这个赋值语句的内存布局我们在之前已经谈到过了,不过我们也再复习一下,这个赋值语句的含义就是 data_assign 和 data 指向的数据是同一个数据,也就是同一个列表。
En fait, en Python, n'importe quel objet Python peut être stocké dans une liste. Par exemple, le programme suivant est légal :data_copy = data.copy()
a = [1, 2, 3]
b = a
print(f"{id(a) = } {id(b) = }")
for i in range(len(a)):
print(f"{i = } {id(a[i]) = } {id(b[i]) = }")Test rapide
Après l'analyse ci-dessus, jetons un œil à la disposition mémoire du code suivant : a = [[1, 2, 3], 4, 5]
b = a.copy()
print(f"{id(a) = } {id(b) = }")
for i in range(len(a)):
print(f"{i = } {id(a[i]) = } {id(b[i]) = }")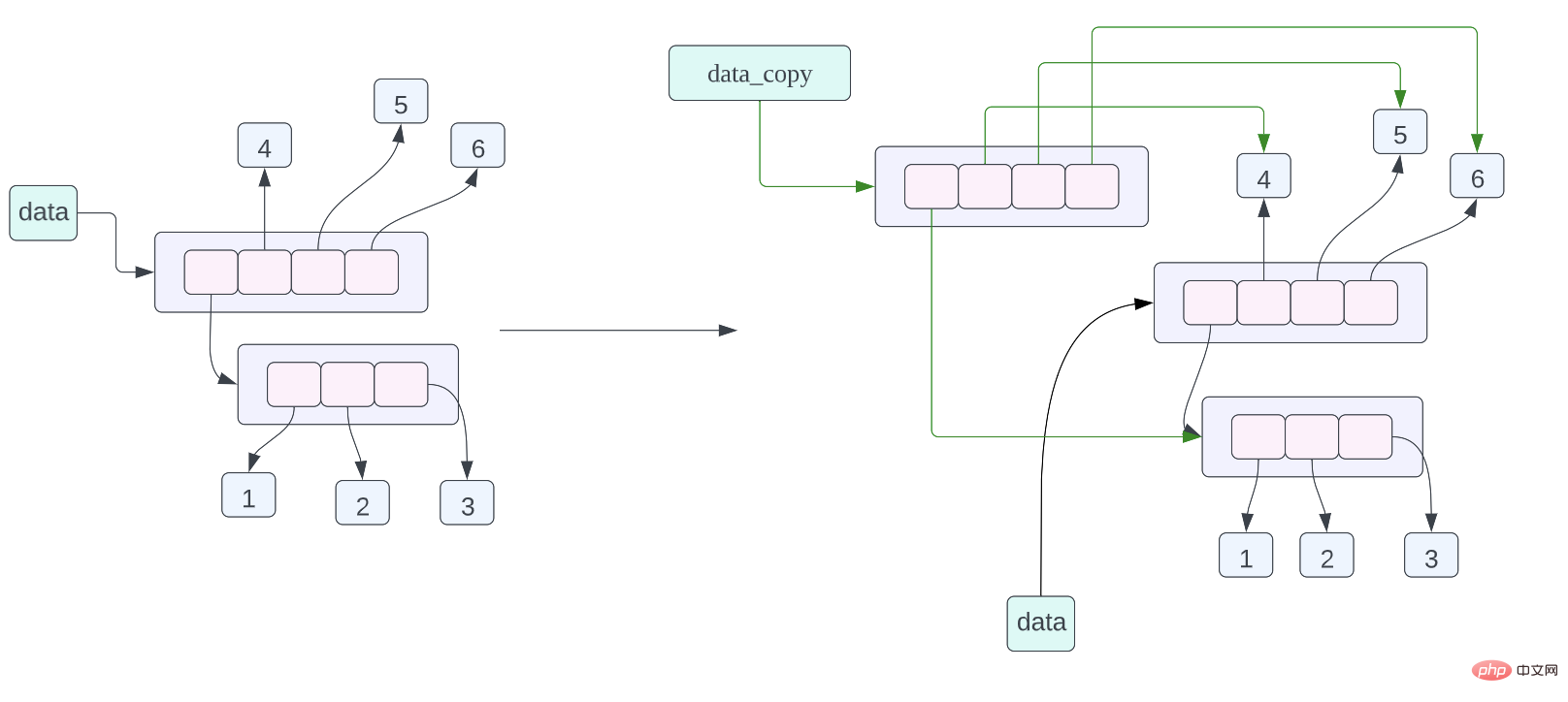
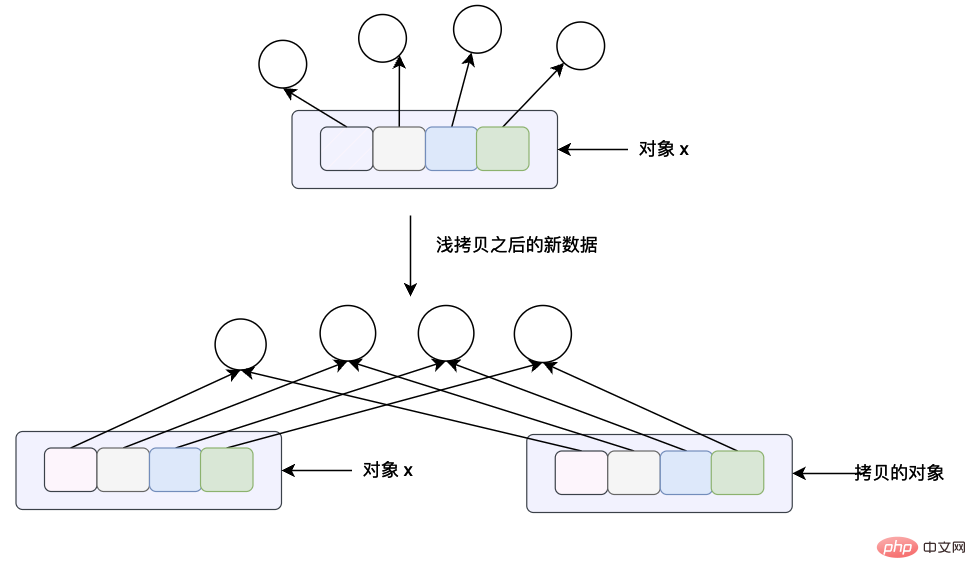
data_assign = data< /code >, nous avons déjà parlé de la disposition de la mémoire de cette instruction d'affectation, mais revoyons-la à nouveau. La signification de cette instruction d'affectation est que les données pointées par data_assign et data sont les mêmes données, c'est-à-dire la même liste. <blockquote><p><li><br/><code>data_copy = data.copy(), la signification de cette instruction d'affectation est de faire une copie superficielle des données pointées par data, puis de laisser data_copy pointer vers les données copiées , la copie superficielle ici Cela signifie que chaque pointeur de la liste est copié, mais les données pointées par le pointeur de la liste sont copiées. À partir du diagramme de disposition de la mémoire de l'objet ci-dessus, nous pouvons voir que data_copy pointe vers une nouvelle liste, mais les données pointées par le pointeur dans la liste sont les mêmes que les données pointées par le pointeur dans la liste de données. représenté par une flèche verte, les données utilisent des flèches noires pour l'indiquer.
Afficher l'adresse mémoire de l'objetDans l'article précédent, nous avons principalement analysé la disposition de la mémoire de l'objet. Dans cette section, nous utilisons python pour nous fournir un outil très efficace pour le vérifier. En python, nous pouvons utiliser id() pour afficher l'adresse mémoire d'un objet. id(a) consiste à afficher l'adresse mémoire de l'objet pointé par l'objet a. Regardez le résultat du programme ci-dessous : 🎜🎜Selon notre analyse précédente, a et b pointent vers la même mémoire, ce qui signifie que les deux variables pointent vers le même objet Python, donc ce qui précède a l'identifiant de sortie The les résultats a et b sont les mêmes. Le résultat ci-dessus est le suivant : 🎜🎜🎜id(a) = 4392953984 id(b) = 4392953984🎜i = 0 id(a[i]) = 4312613104 id(b[i]) = 4312613104🎜i = 1 id (a [i]) = 4312613136 id (b [i]) = 4312613136🎜i = 2 id (a [i]) = 4312613168 id (b [i]) = 4312613168🎜🎜 🎜look Voici l'adresse mémoire de la copie superficielle : 🎜id(a) = 4392953984 id(b) = 4393050112 # 两个对象的输出结果不相等 i = 0 id(a[i]) = 4393045632 id(b[i]) = 4393045632 # 指向的是同一个内存对象因此内存地址相等 下同 i = 1 id(a[i]) = 4312613200 id(b[i]) = 4312613200 i = 2 id(a[i]) = 4312613232 id(b[i]) = 4312613232
Copier après la connexionCopier après la connexion🎜Selon notre analyse précédente, la méthode de copie pour appeler la liste elle-même consiste à effectuer une copie superficielle de la liste. Elle copie uniquement les données du pointeur de la liste et ne copie pas. les données réelles pointées par le pointeur dans la liste. Par conséquent, si nous parcourons les données de la liste pour obtenir l'adresse de l'objet pointé, les résultats renvoyés par la liste a et la liste b sont les mêmes, mais en quoi ils sont différents des résultats. L'exemple précédent est que les adresses des listes pointées par a et b sont différentes (les données étant copiées, vous pouvez vous référer aux résultats de la copie superficielle ci-dessous pour comprendre). 🎜a = 10 a = 100 a = "hello" a = "world"
Copier après la connexionCopier après la connexion
可以结合下面的输出结果和上面的文字进行理解:
id(a) = 4392953984 id(b) = 4393050112 # 两个对象的输出结果不相等 i = 0 id(a[i]) = 4393045632 id(b[i]) = 4393045632 # 指向的是同一个内存对象因此内存地址相等 下同 i = 1 id(a[i]) = 4312613200 id(b[i]) = 4312613200 i = 2 id(a[i]) = 4312613232 id(b[i]) = 4312613232
Copier après la connexionCopier après la connexioncopy模块
在 python 里面有一个自带的包 copy ,主要是用于对象的拷贝,在这个模块当中主要有两个方法 copy.copy(x) 和 copy.deepcopy()。
copy.copy(x) 方法主要是用于浅拷贝,这个方法的含义对于列表来说和列表本身的 x.copy() 方法的意义是一样的,都是进行浅拷贝。这个方法会构造一个新的 python 对象并且会将对象 x 当中所有的数据引用(指针)拷贝一份。
copy.deepcopy(x) 这个方法主要是对对象 x 进行深拷贝,这里的深拷贝的含义是会构造一个新的对象,会递归的查看对象 x 当中的每一个对象,如果递归查看的对象是一个不可变对象将不会进行拷贝,如果查看到的对象是可变对象的话,将重新开辟一块内存空间,将原来的在对象 x 当中的数据拷贝的新的内存当中。(关于可变和不可变对象我们将在下一个小节仔细分析)
根据上面的分析我们可以知道深拷贝的花费是比浅拷贝多的,尤其是当一个对象当中有很多子对象的时候,会花费很多时间和内存空间。
对于 python 对象来说进行深拷贝和浅拷贝的区别主要在于复合对象(对象当中有子对象,比如说列表,元祖、类的实例等等)。这一点主要是和下一小节的可变和不可变对象有关系。
可变和不可变对象与对象拷贝
在 python 当中主要有两大类对象,可变对象和不可变对象,所谓可变对象就是对象的内容可以发生改变,不可变对象就是对象的内容不能够发生改变。
可变对象:比如说列表(list),字典(dict),集合(set),字节数组(bytearray),类的实例对象。
不可变对象:整型(int),浮点型(float),复数(complex),字符串,元祖(tuple),不可变集合(frozenset),字节(bytes)。
看到这里你可能会有疑问了,整数和字符串不是可以修改吗?
a = 10 a = 100 a = "hello" a = "world"
Copier après la connexionCopier après la connexion比如下面的代码是正确的,并不会发生错误,但是事实上其实 a 指向的对象是发生了变化的,第一个对象指向整型或者字符串的时候,如果重新赋一个新的不同的整数或者字符串对象的话,python 会创建一个新的对象,我们可以使用下面的代码进行验证:
a = 10 print(f"{id(a) = }") a = 100 print(f"{id(a) = }") a = "hello" print(f"{id(a) = }") a = "world" print(f"{id(a) = }")Copier après la connexion上面的程序的输出结果如下所示:
id(a) = 4365566480
id(a) = 4365569360
id(a) = 4424109232
id(a) = 4616350128可以看到的是当重新赋值之后变量指向的内存对象是发生了变化的(因为内存地址发生了变化),这就是不可变对象,虽然可以对变量重新赋值,但是得到的是一个新对象并不是在原来的对象上进行修改的!
我们现在来看一下可变对象列表发生修改之后内存地址是怎么发生变化的:
data = [] print(f"{id(data) = }") data.append(1) print(f"{id(data) = }") data.append(1) print(f"{id(data) = }") data.append(1) print(f"{id(data) = }") data.append(1) print(f"{id(data) = }")Copier après la connexion上面的代码输出结果如下所示:
id(data) = 4614905664
id(data) = 4614905664
id(data) = 4614905664
id(data) = 4614905664
id(data) = 4614905664从上面的输出结果来看可以知道,当我们往列表当中加入新的数据之后(修改了列表),列表本身的地址并没有发生变化,这就是可变对象。
我们在前面谈到了深拷贝和浅拷贝,我们现在来分析一下下面的代码:
data = [1, 2, 3] data_copy = copy.copy(data) data_deep = copy.deepcopy(data) print(f"{id(data ) = } | {id(data_copy) = } | {id(data_deep) = }") print(f"{id(data[0]) = } | {id(data_copy[0]) = } | {id(data_deep[0]) = }") print(f"{id(data[1]) = } | {id(data_copy[1]) = } | {id(data_deep[1]) = }") print(f"{id(data[2]) = } | {id(data_copy[2]) = } | {id(data_deep[2]) = }")Copier après la connexion上面的代码输出结果如下所示:
id(data ) = 4620333952 | id(data_copy) = 4619860736 | id(data_deep) = 4621137024
id(data[0]) = 4365566192 | id(data_copy[0]) = 4365566192 | id(data_deep[0]) = 4365566192
id(data[1]) = 4365566224 | id(data_copy[1]) = 4365566224 | id(data_deep[1]) = 4365566224
id(data[2]) = 4365566256 | id(data_copy[2]) = 4365566256 | id(data_deep[2]) = 4365566256看到这里你肯定会非常疑惑,为什么深拷贝和浅拷贝指向的内存对象是一样的呢?前列我们可以理解,因为浅拷贝拷贝的是引用,因此他们指向的对象是同一个,但是为什么深拷贝之后指向的内存对象和浅拷贝也是一样的呢?这正是因为列表当中的数据是整型数据,他是一个不可变对象,如果对 data 或者 data_copy 指向的对象进行修改,那么将会指向一个新的对象并不会直接修改原来的对象,因此对于不可变对象其实是不用开辟一块新的内存空间在重新赋值的,因为这块内存中的对象是不会发生改变的。
我们再来看一个可拷贝的对象:
data = [[1], [2], [3]] data_copy = copy.copy(data) data_deep = copy.deepcopy(data) print(f"{id(data ) = } | {id(data_copy) = } | {id(data_deep) = }") print(f"{id(data[0]) = } | {id(data_copy[0]) = } | {id(data_deep[0]) = }") print(f"{id(data[1]) = } | {id(data_copy[1]) = } | {id(data_deep[1]) = }") print(f"{id(data[2]) = } | {id(data_copy[2]) = } | {id(data_deep[2]) = }")Copier après la connexion上面的代码输出结果如下所示:
id(data ) = 4619403712 | id(data_copy) = 4617239424 | id(data_deep) = 4620032640
id(data[0]) = 4620112640 | id(data_copy[0]) = 4620112640 | id(data_deep[0]) = 4620333952
id(data[1]) = 4619848128 | id(data_copy[1]) = 4619848128 | id(data_deep[1]) = 4621272448
id(data[2]) = 4620473280 | id(data_copy[2]) = 4620473280 | id(data_deep[2]) = 4621275840从上面程序的输出结果我们可以看到,当列表当中保存的是一个可变对象的时候,如果我们进行深拷贝将创建一个全新的对象(深拷贝的对象内存地址和浅拷贝的不一样)。
代码片段分析
经过上面的学习对于在本篇文章开头提出的问题对于你来说应该是很简单的,我们现在来分析一下这几个代码片段:
a = [1, 2, 3, 4] b = a print(f"{a = } \t|\t {b = }") a[0] = 100 print(f"{a = } \t|\t {b = }")Copier après la connexionCopier après la connexion这个很简单啦,a 和 b 不同的变量指向同一个列表,a 中间的数据发生变化,那么 b 的数据也会发生变化,输出结果如下所示:
a = [1, 2, 3, 4] | b = [1, 2, 3, 4]
a = [100, 2, 3, 4] | b = [100, 2, 3, 4]
id(a) = 4614458816 | id(b) = 4614458816我们再来看一下第二个代码片段
a = [1, 2, 3, 4] b = a.copy() print(f"{a = } \t|\t {b = }") a[0] = 100 print(f"{a = } \t|\t {b = }")Copier après la connexionCopier après la connexion因为 b 是 a 的一个浅拷贝,所以 a 和 b 指向的是不同的列表,但是列表当中数据的指向是相同的,但是由于整型数据是不可变数据,当a[0] 发生变化的时候,并不会修改原来的数据,而是会在内存当中创建一个新的整型数据,因此列表 b 的内容并不会发生变化。因此上面的代码输出结果如下所示:
a = [1, 2, 3, 4] | b = [1, 2, 3, 4] a = [100, 2, 3, 4] | b = [1, 2, 3, 4]
Copier après la connexion再来看一下第三个片段:
a = [[1, 2, 3], 2, 3, 4] b = a.copy() print(f"{a = } \t|\t {b = }") a[0][0] = 100 print(f"{a = } \t|\t {b = }")Copier après la connexionCopier après la connexion这个和第二个片段的分析是相似的,但是 a[0] 是一个可变对象,因此进行数据修改的时候,a[0] 的指向没有发生变化,因此 a 修改的内容会影响 b。
a = [[1, 2, 3], 2, 3, 4] | b = [[1, 2, 3], 2, 3, 4] a = [[100, 2, 3], 2, 3, 4] | b = [[100, 2, 3], 2, 3, 4]
Copier après la connexion最后一个片段:
a = [[1, 2, 3], 2, 3, 4] b = copy.deepcopy(a) print(f"{a = } \t|\t {b = }") a[0][0] = 100 print(f"{a = } \t|\t {b = }")Copier après la connexionCopier après la connexion深拷贝会在内存当中重新创建一个和a[0]相同的对象,并且让 b[0] 指向这个对象,因此修改 a[0],并不会影响 b[0],因此输出结果如下所示:
a = [[1, 2, 3], 2, 3, 4] | b = [[1, 2, 3], 2, 3, 4] a = [[100, 2, 3], 2, 3, 4] | b = [[1, 2, 3], 2, 3, 4]
Copier après la connexion撕开 Python 对象的神秘面纱
我们现在简要看一下 Cpython 是如何实现 list 数据结构的,在 list 当中到底定义了一些什么东西:
typedef struct { PyObject_VAR_HEAD /* Vector of pointers to list elements. list[0] is ob_item[0], etc. */ PyObject **ob_item; /* ob_item contains space for 'allocated' elements. The number * currently in use is ob_size. * Invariants: * 0 <= ob_size <= allocated * len(list) == ob_size * ob_item == NULL implies ob_size == allocated == 0 * list.sort() temporarily sets allocated to -1 to detect mutations. * * Items must normally not be NULL, except during construction when * the list is not yet visible outside the function that builds it. */ Py_ssize_t allocated; } PyListObject;Copier après la connexion在上面定义的结构体当中 :
allocated 表示分配的内存空间的数量,也就是能够存储指针的数量,当所有的空间用完之后需要再次申请内存空间。
ob_item 指向内存当中真正存储指向 python 对象指针的数组,比如说我们想得到列表当中第一个对象的指针的话就是 list->ob_item[0],如果要得到真正的数据的话就是 *(list->ob_item[0])。
PyObject_VAR_HEAD 是一个宏,会在结构体当中定一个子结构体,这个子结构体的定义如下:
typedef struct { PyObject ob_base; Py_ssize_t ob_size; /* Number of items in variable part */ } PyVarObject;Copier après la connexion这里我们不去谈对象 PyObject 了,主要说一下 ob_size,他表示列表当中存储了多少个数据,这个和 allocated 不一样,allocated 表示 ob_item 指向的数组一共有多少个空间,ob_size 表示这个数组存储了多少个数据 ob_size
在了解列表的结构体之后我们现在应该能够理解之前的内存布局了,所有的列表并不存储真正的数据而是存储指向这些数据的指针。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 La vitesse de conversion est-elle rapide lors de la conversion du XML en PDF sur le téléphone mobile?
Apr 02, 2025 pm 10:09 PM
La vitesse de conversion est-elle rapide lors de la conversion du XML en PDF sur le téléphone mobile?
Apr 02, 2025 pm 10:09 PM
La vitesse du XML mobile à PDF dépend des facteurs suivants: la complexité de la structure XML. Méthode de conversion de configuration du matériel mobile (bibliothèque, algorithme) Méthodes d'optimisation de la qualité du code (sélectionnez des bibliothèques efficaces, optimiser les algorithmes, les données de cache et utiliser le multi-threading). Dans l'ensemble, il n'y a pas de réponse absolue et elle doit être optimisée en fonction de la situation spécifique.
 Comment convertir les fichiers XML en PDF sur votre téléphone?
Apr 02, 2025 pm 10:12 PM
Comment convertir les fichiers XML en PDF sur votre téléphone?
Apr 02, 2025 pm 10:12 PM
Il est impossible de terminer la conversion XML à PDF directement sur votre téléphone avec une seule application. Il est nécessaire d'utiliser les services cloud, qui peuvent être réalisés via deux étapes: 1. Convertir XML en PDF dans le cloud, 2. Accédez ou téléchargez le fichier PDF converti sur le téléphone mobile.
 Quelle est la fonction de la somme du langage C?
Apr 03, 2025 pm 02:21 PM
Quelle est la fonction de la somme du langage C?
Apr 03, 2025 pm 02:21 PM
Il n'y a pas de fonction de somme intégrée dans le langage C, il doit donc être écrit par vous-même. La somme peut être obtenue en traversant le tableau et en accumulant des éléments: Version de boucle: la somme est calculée à l'aide de la longueur de boucle et du tableau. Version du pointeur: Utilisez des pointeurs pour pointer des éléments de tableau, et un résumé efficace est réalisé grâce à des pointeurs d'auto-incitation. Allouer dynamiquement la version du tableau: allouer dynamiquement les tableaux et gérer la mémoire vous-même, en veillant à ce que la mémoire allouée soit libérée pour empêcher les fuites de mémoire.
 Comment convertir XML en PDF sur votre téléphone?
Apr 02, 2025 pm 10:18 PM
Comment convertir XML en PDF sur votre téléphone?
Apr 02, 2025 pm 10:18 PM
Il n'est pas facile de convertir XML en PDF directement sur votre téléphone, mais il peut être réalisé à l'aide des services cloud. Il est recommandé d'utiliser une application mobile légère pour télécharger des fichiers XML et recevoir des PDF générés, et de les convertir avec des API Cloud. Les API Cloud utilisent des services informatiques sans serveur et le choix de la bonne plate-forme est crucial. La complexité, la gestion des erreurs, la sécurité et les stratégies d'optimisation doivent être prises en compte lors de la gestion de l'analyse XML et de la génération de PDF. L'ensemble du processus nécessite que l'application frontale et l'API back-end fonctionnent ensemble, et il nécessite une certaine compréhension d'une variété de technologies.
 Comment convertir XML en images
Apr 03, 2025 am 07:39 AM
Comment convertir XML en images
Apr 03, 2025 am 07:39 AM
XML peut être converti en images en utilisant un convertisseur XSLT ou une bibliothèque d'images. Convertisseur XSLT: Utilisez un processeur XSLT et une feuille de style pour convertir XML en images. Bibliothèque d'images: utilisez des bibliothèques telles que PIL ou ImageMagick pour créer des images à partir de données XML, telles que des formes de dessin et du texte.
 Qui est payé plus de python ou de javascript?
Apr 04, 2025 am 12:09 AM
Qui est payé plus de python ou de javascript?
Apr 04, 2025 am 12:09 AM
Il n'y a pas de salaire absolu pour les développeurs Python et JavaScript, selon les compétences et les besoins de l'industrie. 1. Python peut être davantage payé en science des données et en apprentissage automatique. 2. JavaScript a une grande demande dans le développement frontal et complet, et son salaire est également considérable. 3. Les facteurs d'influence comprennent l'expérience, la localisation géographique, la taille de l'entreprise et les compétences spécifiques.
 Comment convertir XML en mp3
Apr 03, 2025 am 09:00 AM
Comment convertir XML en mp3
Apr 03, 2025 am 09:00 AM
Les étapes pour convertir XML en MP3 incluent: Extraire les données audio de XML: analyser le fichier XML, trouver la chaîne de codage Base64 contenant les données audio et les décoder en format binaire. Encoder les données audio à MP3: Installez l'encodeur MP3 et définissez les paramètres de codage, encodez les données audio binaires au format MP3 et enregistrez-les dans un fichier.
 Comment changer le format de XML
Apr 03, 2025 am 08:42 AM
Comment changer le format de XML
Apr 03, 2025 am 08:42 AM
Il existe plusieurs façons de modifier les formats XML: édition manuellement avec un éditeur de texte tel que le bloc-notes; Formatage automatique avec des outils de mise en forme XML en ligne ou de bureau tels que XMLBeautifier; Définir les règles de conversion à l'aide d'outils de conversion XML tels que XSLT; ou analyser et fonctionner à l'aide de langages de programmation tels que Python. Soyez prudent lorsque vous modifiez et sauvegardez les fichiers d'origine.
