

Les grands modèles d'IA générative sont au centre des efforts d'OpenAI. Elle a déjà lancé les modèles d'images générés par du texte DALL-E et DALL-E 2, ainsi que POINT-E, qui génère des modèles 3D basés sur texte plus tôt cette année.
Récemment, l'équipe de recherche OpenAI a mis à niveau le modèle de génération 3D et a lancé le nouveau Shap・E, qui est un outil de synthèse Actifs 3D. Le modèle génératif conditionnel . Actuellement, les poids du modèle, le code d'inférence et les échantillons pertinents sont de source ouverte.


 Il existe aussi des exemples classiques, comme la chaise avocat :
Il existe aussi des exemples classiques, comme la chaise avocat :
#🎜 🎜 #
Bien sûr, vous pouvez également générer des modèles 3D de certains objets courants, comme un bol de légumes : 
#🎜🎜 ## 🎜🎜#Beignets :

#🎜 🎜 #Cet article propose que Shap·E soit un modèle de diffusion latente sur un espace de fonctions implicite 3D qui peut être rendu dans des maillages NeRF et de texture. Étant donné
avec le même ensemble de données, la même architecture de modèle et les mêmes calculs d'entraînement, Shap・E surpasse les modèles de génération explicites similaires 
Différent des modèles générés en 3D Pour Travail qui produit une représentation de sortie unique, Shap-E est capable de générer directement les arguments des fonctions implicites. La formation Shap-E est divisée en deux étapes : premièrement, formation de l'encodeur, qui mappe de manière déterministe les actifs 3D dans les paramètres de la fonction implicite ; deuxièmement, formation du modèle de diffusion conditionnelle sur la sortie de l'encodeur ; Lorsqu’il est entraîné sur un vaste ensemble de données couplées de données 3D et textuelles, le modèle est capable de générer des ressources 3D complexes et diverses en quelques secondes.  Par rapport au modèle de génération explicite de nuages de points Point・E, Shap-E modélise un espace de sortie multi-représentation de haute dimension, converge plus rapidement et obtient une qualité d'échantillon équivalente ou meilleure
Par rapport au modèle de génération explicite de nuages de points Point・E, Shap-E modélise un espace de sortie multi-représentation de haute dimension, converge plus rapidement et obtient une qualité d'échantillon équivalente ou meilleure
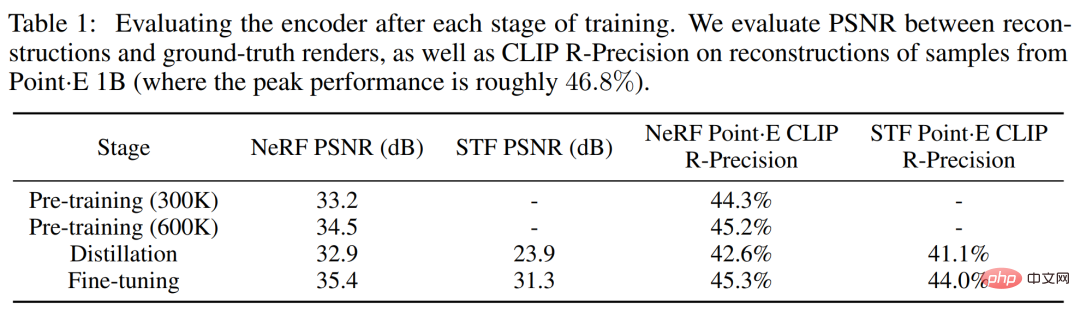
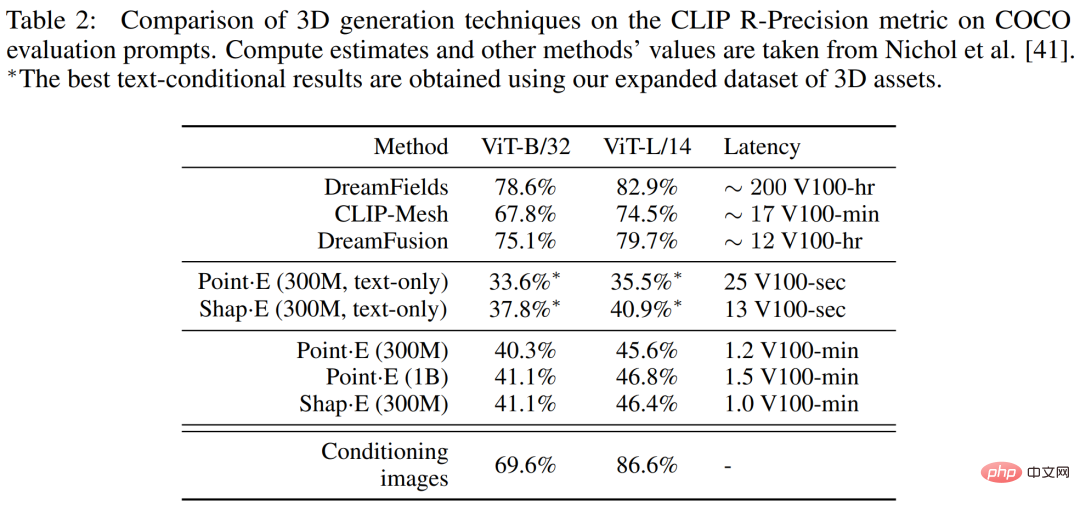
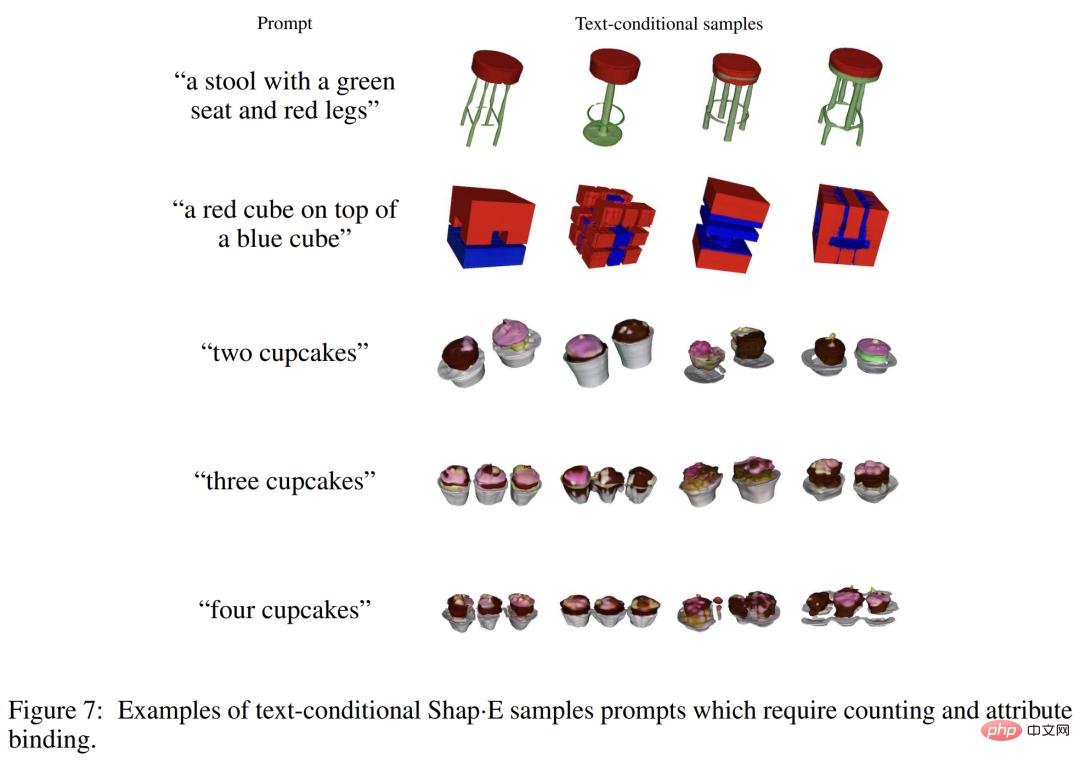
Contexte de rechercheCet article se concentre sur deux représentations neuronales implicites (INR) pour la représentation 3D : #🎜🎜 # Bien que l'INR soit flexible et expressif, il est coûteux d'obtenir l'INR pour chaque échantillon de l'ensemble de données. De plus, chaque INR peut avoir de nombreux paramètres numériques, ce qui peut entraîner des difficultés lors de la formation de modèles génératifs en aval. En résolvant ces problèmes à l'aide d'auto-encodeurs avec des décodeurs implicites, des représentations latentes plus petites peuvent être obtenues, directement modélisées avec les techniques génératives existantes. Une approche alternative consiste à utiliser le méta-apprentissage pour créer un ensemble de données INR qui partage la plupart de ses paramètres, puis à former un modèle de diffusion ou un flux normalisé sur les paramètres libres de ces INR. Il a également été suggéré que le méta-apprentissage basé sur le gradient n'était peut-être pas nécessaire et que l'encodeur Transformer devrait plutôt être entraîné directement pour produire des paramètres NeRF conditionnés sur plusieurs vues d'un objet 3D. Les chercheurs ont combiné et étendu les méthodes ci-dessus et ont finalement obtenu Shap・E, qui est devenu un modèle de génération conditionnelle pour diverses représentations implicites 3D complexes. Générez d’abord les paramètres INR pour l’actif 3D en entraînant un encodeur basé sur un transformateur, puis entraînez un modèle de diffusion sur la sortie de l’encodeur. Contrairement aux approches précédentes, les INR générés représentent à la fois le NeRF et les maillages, ce qui permet de les restituer de différentes manières ou de les importer dans des applications 3D en aval. Lorsqu'il est formé sur un ensemble de données de millions d'actifs 3D, notre modèle est capable de produire une variété d'échantillons identifiables sous condition d'invites textuelles. Shap-E converge plus rapidement que Point·E, un modèle génératif 3D explicite récemment proposé. Il peut obtenir des résultats comparables ou meilleurs avec la même architecture de modèle, le même ensemble de données et le même mécanisme de conditionnement. Le chercheur entraîne d'abord l'encodeur à générer une représentation implicite, puis entraîne le modèle de diffusion sur la représentation latente générée par l'encodeur. Ceci se réalise principalement en deux étapes suivantes : 1. . Entraîner un encodeur, produisant les paramètres d'une fonction implicite étant donné une représentation explicite dense d'un actif 3D connu. L'encodeur produit une représentation latente de l'actif 3D qui est ensuite projetée linéairement pour obtenir les poids du perceptron multicouche (MLP) 2. Appliquez l'encodeur à l'ensemble de données puis entraînez une diffusion préalable sur l'ensemble de données latentes. Le modèle est conditionné par des images ou des descriptions textuelles. Les chercheurs ont entraîné tous les modèles sur un vaste ensemble de données d'actifs 3D à l'aide des rendus, des nuages de points et des légendes de texte correspondants. Encodeur 3D L'architecture de l'encodeur est illustrée dans la figure 2 ci-dessous. Diffusion latente Le modèle de génération utilise l'architecture de diffusion Point・E basée sur un transformateur, mais utilise des séquences vectorielles latentes au lieu de nuages de points. La séquence de formes de fonctions latentes est de 1 024 × 1 024 et est entrée dans le transformateur sous la forme d'une séquence de 1 024 jetons, chaque jeton correspondant à une ligne différente de la matrice de pondération MLP. Par conséquent, ce modèle est à peu près équivalent sur le plan informatique au modèle de base Point·E (c'est-à-dire qu'il a la même longueur et la même largeur de contexte). Sur cette base, des canaux d'entrée et de sortie sont ajoutés pour générer des échantillons dans un espace de dimension supérieure. Évaluation de l'encodeur Les chercheurs ont suivi deux métriques basées sur le rendu tout au long du processus de formation de l'encodeur. Évaluez d’abord le rapport signal/bruit maximal (PSNR) entre l’image reconstruite et l’image réelle rendue. De plus, pour mesurer la capacité de l'encodeur à capturer les détails sémantiquement pertinents d'un actif 3D, le CLIP R-Precision pour les rendus NeRF et STF reconstruits a été réévalué en codant le maillage produit par le plus grand modèle Point·E. Le tableau 1 ci-dessous suit les résultats de ces deux métriques à différentes étapes de formation. On peut constater que la distillation nuit à la qualité de la reconstruction NeRF, tandis que le réglage fin non seulement restaure mais améliore également légèrement la qualité NeRF tout en améliorant considérablement la qualité du rendu STF. Comparaison avec Point・E Le modèle de diffusion latente proposé par le chercheur a la même architecture, le même ensemble de données d'entraînement et le même modèle conditionnel que Point・E. La comparaison avec Point·E est plus utile pour distinguer les effets de la génération de représentations neuronales implicites plutôt que de représentations explicites. La figure 4 ci-dessous compare ces méthodes sur des mesures d'évaluation basées sur des échantillons. Des échantillons qualitatifs sont présentés dans la figure 5 ci-dessous, et vous pouvez voir que ces modèles génèrent souvent des échantillons de qualité variable pour la même invite de texte. Avant la fin de la formation, la condition du texte Shap·E commence à se détériorer lors de l'évaluation. Les chercheurs ont découvert que Shap·E et Point·E ont tendance à partager des cas d'échec similaires, comme le montre la figure 6 (a) ci-dessous. Cela suggère que les données d'entraînement, l'architecture du modèle et les images conditionnées ont un impact plus important sur les échantillons générés que l'espace de représentation choisi. Nous pouvons observer qu'il existe encore quelques différences qualitatives entre les deux modèles de conditions d'image, par exemple dans la première rangée de la figure 6(b) ci-dessous, Point・E ignore le petit espace sur le banc, tandis que Shap・E Essayez de les modéliser. Cet article émet l’hypothèse que cet écart particulier se produit parce que les nuages de points ne représentent pas bien les entités fines ou les espaces. On observe également dans le tableau 1 que l'encodeur 3D réduit légèrement la précision CLIP R lorsqu'il est appliqué aux échantillons Point·E. Comparaison avec d'autres méthodes Dans le tableau 2 ci-dessous, les chercheurs ont comparé shape・E à une gamme plus large de techniques de génération 3D sur la métrique CLIP R-Precision. Bien que Shap-E puisse comprendre de nombreuses invites d'objet unique avec des propriétés simples, il est limité dans sa capacité à combiner des concepts. Comme vous pouvez le voir dans la figure 7 ci-dessous, ce modèle rend difficile la liaison de plusieurs propriétés à différents objets et ne génère pas efficacement le nombre correct d'objets lorsque plus de deux objets sont demandés. Cela peut être dû à des données d'entraînement appariées insuffisantes et peut être résolu en collectant ou en générant un ensemble de données 3D annotées plus grand. De plus, Shap・E produit des ressources 3D reconnaissables, mais celles-ci semblent souvent grossières ou manquent de détails. La figure 3 ci-dessous montre que l'encodeur perd parfois des textures détaillées (telles que les rayures sur un cactus), ce qui suggère qu'un encodeur amélioré pourrait restaurer une partie de la qualité de génération perdue. Veuillez vous référer à l'article original pour plus de détails techniques et expérimentaux.
Aperçu de la méthode
Résultats expérimentaux


Limitations et perspectives

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 utilisation de la fonction de rééchantillonnage
utilisation de la fonction de rééchantillonnage
 Solution d'erreur inattendue IIS 0x8ffe2740
Solution d'erreur inattendue IIS 0x8ffe2740
 Utilisation de la fonction SetTimer
Utilisation de la fonction SetTimer
 Comment changer phpmyadmin en chinois
Comment changer phpmyadmin en chinois
 Que sont les éditeurs de texte Java ?
Que sont les éditeurs de texte Java ?
 Que signifie le contexte ?
Que signifie le contexte ?
 Le rôle du Serverlet en Java
Le rôle du Serverlet en Java
 Quels sont les problèmes liés à l'utilisation de php
Quels sont les problèmes liés à l'utilisation de php
 Qu'est-ce qu'une procédure stockée MYSQL ?
Qu'est-ce qu'une procédure stockée MYSQL ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



