
 Opération et maintenance
Sécurité
Analyse du processus depuis la saisie de l'URL jusqu'au rendu final du contenu de la page par le navigateur
Opération et maintenance
Sécurité
Analyse du processus depuis la saisie de l'URL jusqu'au rendu final du contenu de la page par le navigateur
Analyse du processus depuis la saisie de l'URL jusqu'au rendu final du contenu de la page par le navigateur

Preparation
Lorsque vous entrez l'URL dans le navigateur (comme www.coder.com) et appuyez sur Entrée, la première chose que fait le navigateur La chose consiste à obtenir l'adresse IP de coder.com. La méthode spécifique consiste à envoyer un paquet UDP au serveur DNS. Le serveur DNS renverra l'adresse IP de coder.com. À ce stade, le navigateur met généralement en cache l'adresse IP. il sera accessible la prochaine fois.
Par exemple, Chrome, vous pouvez le visualiser via chrome://net-internals/#dns.
Avec l'IP du serveur, le navigateur peut initier des requêtes HTTP, mais les requêtes/réponses HTTP doivent être envoyées et reçues sur la "connexion virtuelle" de TCP.
Pour établir une connexion TCP "virtuelle", TCP Postman a besoin de connaître 4 choses : (IP locale, port local, IP du serveur, port du serveur). Maintenant, il ne connaît que l'IP locale, qu'en est-il du serveur). IP et deux ports ?
Le port local est très simple. Le système d'exploitation peut en attribuer un au hasard au navigateur. Le port du serveur est encore plus simple Il utilise un port "connu" est le 80. dites-le directement au facteur TCP.
Après trois handshakes, la connexion TCP entre le client et le serveur est établie ! Enfin nous pouvons envoyer des requêtes HTTP.

La raison pour laquelle la connexion TCP est dessinée en pointillé est parce que cette connexion est virtuelle
Serveur Web
Une requête HTTP GET parcourt des milliers de kilomètres et est transmise par plusieurs routeurs avant d'atteindre finalement le serveur (les paquets HTTP peuvent être fragmentés et transmis par la couche inférieure, qui est omise ) .
Le serveur Web doit démarrer le traitement. Il a trois façons de le gérer :
(1) Un seul thread peut être utilisé pour gérer toutes les requêtes, et un seul thread peut être utilisé à la fois. Cette structure est facile à mettre en œuvre, mais elle peut entraîner de sérieux problèmes de performances.
(2) Un processus/thread peut être alloué pour chaque requête, mais lorsqu'il y a trop de connexions, le processus/thread côté serveur consommera beaucoup de ressources mémoire et de processus /changement de thread Cela surchargera également le processeur.
(3) Pour réutiliser les E/S, de nombreux serveurs Web adoptent une structure de réutilisation. Par exemple, toutes les connexions sont surveillées via epoll lorsque l'état de la connexion change (si les données sont disponibles, Lire). , utilisez un processus/thread pour traiter cette connexion, continuez à surveiller après le traitement et attendez le prochain changement d'état. De cette manière, des milliers de demandes de connexion peuvent être traitées avec un petit nombre de processus/threads.
Nous utilisons Nginx, un serveur web très populaire, pour continuer l'histoire suivante.
Pour la requête HTTP GET, Nginx utilise epoll pour la lire Ensuite, Nginx doit déterminer s'il s'agit d'une requête statique ou d'une requête dynamique ?
S'il s'agit d'une requête statique (fichier HTML, fichier JavaScript, fichier CSS, image, etc.), vous pourrez peut-être la gérer vous-même (bien sûr, cela dépend de la configuration de Nginx et peut être transmis à d'autres serveurs de cache). Lisez les fichiers pertinents sur le disque dur local et revenez directement.
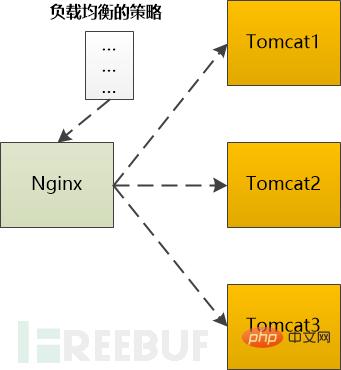
S'il s'agit d'une requête dynamique qui doit être traitée par le serveur backend (tel que Tomcat) avant de pouvoir être renvoyée, elle doit être transmise à Tomcat. dans le backend, il doit être sélectionné selon une certaine stratégie.
Par exemple, Ngnix prend en charge les types suivants :
On voit que Nginx joue le rôle d'un agent dans ce scénario.Polling : transmettre au serveur backend un par un dans l'ordre
Poids : donner à chaque serveur backend un poids attribué à chaque serveur backend, qui équivaut à la probabilité de transfert vers le serveur backend.
ip_hash : effectuez une opération de hachage basée sur l'IP, puis trouvez un serveur pour la transférer. Dans ce cas, la même IP client sera toujours transmise au même serveur back-end.
fair : allouez les requêtes en fonction du temps de réponse du serveur backend et hiérarchisez le délai de réponse. Quel que soit l'algorithme utilisé, un serveur backend est finalement sélectionné, puis Nginx doit transmettre la requête HTTP au backend Tomcat et transmettre la sortie HttpResponse de Tomcat au navigateur.
Application Server
 La requête HTTP est enfin arrivée sur Tomcat, qui est un serveur Java Un conteneur écrit pour gérer Servlet/JSP, notre code s'exécute dans ce conteneur.
La requête HTTP est enfin arrivée sur Tomcat, qui est un serveur Java Un conteneur écrit pour gérer Servlet/JSP, notre code s'exécute dans ce conteneur.
Comme le serveur Web, Tomcat peut également allouer un thread pour chaque requête à traiter, ce qui est communément appelé mode BIO (Blocking I/O mode). Il est également possible d'utiliser la technologie de multiplexage d'E/S et de n'utiliser que quelques threads pour gérer toutes les requêtes, c'est-à-dire le mode NIO.
Quelle que soit la méthode utilisée, la requête HTTP sera transmise à un servlet pour traitement, et le servlet convertira la requête HTTP dans le format de paramètre utilisé par le framework, puis la distribuera à un contrôleur (si vous utilisez Spring) ou une action (si vous utilisez Struts).
Le reste de l'histoire est relativement simple (non, pour les codeurs, c'est en fait la partie la plus compliquée), qui consiste à exécuter la logique d'ajout, de suppression, de modification et de recherche souvent écrite par les codeurs. Dans ce processus, c'est très. susceptibles d'interagir avec les caches, les bases de données, etc. Les composants back-end interagissent les uns avec les autres et renvoient finalement une réponse HTTP. Étant donné que les détails dépendent de la logique métier, ils sont omis.
Selon notre exemple, cette réponse HTTP doit être une page HTML.
Homecoming
Tomcat a joyeusement envoyé la réponse Http à Ngnix.
Ngnix est également heureux d'envoyer une réponse Http au navigateur.

La connexion TCP peut-elle être fermée après l'envoi ?
Si vous utilisez HTTP1.1, cette connexion est persistante par défaut, ce qui signifie qu'elle ne peut pas être fermée.
Si vous utilisez HTTP1.0, vérifiez s'il y a Connection:keep-alive dans la requête HTTP précédente ; En-tête. Si oui, il ne peut pas être fermé.
Le navigateur fonctionne à nouveau
Le navigateur a reçu la réponse HTTP, a lu la page HTML et a commencé à se préparer à afficher la page.
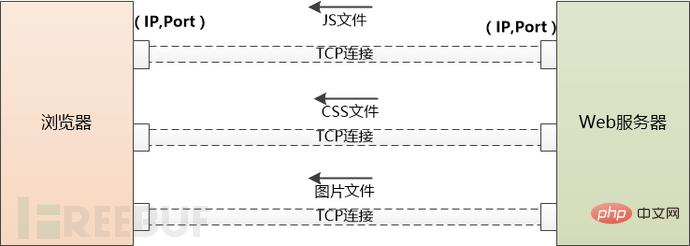
Mais cette page HTML peut référencer un grand nombre d'autres ressources, comme des fichiers js, des fichiers CSS, des images, etc. Ces ressources se trouvent également côté serveur et peuvent se trouver sous un autre nom de domaine, comme static.coder .com.
Le navigateur n'a d'autre choix que de les télécharger un par un. En commençant par utiliser DNS pour obtenir l'IP, les choses qui ont été faites auparavant doivent être refaites. La différence est qu'il n'y aura plus d'intervention de serveurs d'applications comme Tomcat.
S'il y a trop de ressources externes à télécharger, le navigateur créera plusieurs connexions TCP et les téléchargera en parallèle.
Mais le nombre de requêtes sur le même nom de domaine en même temps ne peut pas être trop important, sinon le trafic du serveur sera trop important et ce sera insupportable. Les navigateurs doivent donc se limiter. Par exemple, Chrome ne peut télécharger que 6 ressources en parallèle sous Http1.1.
Lorsque le serveur envoie des fichiers JS et CSS au navigateur, il indiquera au navigateur quand ces fichiers expireront (en utilisant Cache-Control ou Expire). Le navigateur peut mettre les fichiers en cache localement et attendre la deuxième demande. Pour un même fichier, s’il n’expire pas, vous pouvez simplement le récupérer depuis la zone locale.
S'il expire, le navigateur peut demander au serveur si le fichier a été modifié ? (En fonction du Last-Modified et de l'ETag envoyés par le dernier serveur), s'il n'a pas été modifié (304 Not Modified), vous pouvez également utiliser la mise en cache. Sinon, le serveur renverra le dernier fichier au navigateur.
Bien sûr, si vous appuyez sur Ctrl+F5, une requête GET sera émise de force, ignorant complètement le cache.
Remarque : Sous Chrome, vous pouvez visualiser le cache via la commande chrome://view-http-cache/.
Maintenant, le navigateur obtient trois choses importantes :
1.HTML, le navigateur le transforme en arbre DOM
2 CSS, le navigateur le transforme en arbre de règles CSS
3. peut être modifié
Le navigateur générera ce qu'on appelle « l'arbre de rendu » via l'arbre DOM et l'arbre de règles CSS, calculera la position/taille de chaque élément, la disposition, puis appellera l'API du système d'exploitation pour le dessin. un processus très complexe est omis et non représenté.
Jusqu'à présent, nous voyons enfin le contenu de www.coder.com dans le navigateur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment personnaliser le symbole de redimensionnement via CSS et le rendre uniforme avec la couleur d'arrière-plan?
Apr 05, 2025 pm 02:30 PM
Comment personnaliser le symbole de redimensionnement via CSS et le rendre uniforme avec la couleur d'arrière-plan?
Apr 05, 2025 pm 02:30 PM
La méthode de personnalisation des symboles de redimension dans CSS est unifiée avec des couleurs d'arrière-plan. Dans le développement quotidien, nous rencontrons souvent des situations où nous devons personnaliser les détails de l'interface utilisateur, tels que l'ajustement ...
 Pourquoi les feuilles de style personnalisées peuvent-elles prendre effet sur les pages Web locales de Safari mais pas sur les pages Baidu?
Apr 05, 2025 pm 05:15 PM
Pourquoi les feuilles de style personnalisées peuvent-elles prendre effet sur les pages Web locales de Safari mais pas sur les pages Baidu?
Apr 05, 2025 pm 05:15 PM
Discussion sur l'utilisation de styles de style personnalisés dans Safari aujourd'hui, nous allons discuter d'une question sur l'application de feuilles de style personnalisées pour le navigateur Safari. Novice frontal ...
 Comment afficher correctement le 'Jingnan Mai Round Body' installé localement sur la page Web?
Apr 05, 2025 pm 10:33 PM
Comment afficher correctement le 'Jingnan Mai Round Body' installé localement sur la page Web?
Apr 05, 2025 pm 10:33 PM
En utilisant récemment des fichiers de police installés localement dans les pages Web, j'ai téléchargé une police gratuite à partir d'Internet et je l'ai installée avec succès dans mon système. Maintenant...
 Comment contrôler le haut et la fin des pages dans les paramètres d'impression du navigateur via JavaScript ou CSS?
Apr 05, 2025 pm 10:39 PM
Comment contrôler le haut et la fin des pages dans les paramètres d'impression du navigateur via JavaScript ou CSS?
Apr 05, 2025 pm 10:39 PM
Comment utiliser JavaScript ou CSS pour contrôler le haut et la fin de la page dans les paramètres d'impression du navigateur. Dans les paramètres d'impression du navigateur, il existe une option pour contrôler si l'écran est ...
 Comment utiliser des fichiers de police installés localement sur les pages Web?
Apr 05, 2025 pm 10:57 PM
Comment utiliser des fichiers de police installés localement sur les pages Web?
Apr 05, 2025 pm 10:57 PM
Comment utiliser des fichiers de police installés localement sur les pages Web avez-vous rencontré cette situation dans le développement de pages Web: vous avez installé une police sur votre ordinateur ...
 Pourquoi les marges négatives ne prennent-elles pas effet dans certains cas? Comment résoudre ce problème?
Apr 05, 2025 pm 10:18 PM
Pourquoi les marges négatives ne prennent-elles pas effet dans certains cas? Comment résoudre ce problème?
Apr 05, 2025 pm 10:18 PM
Pourquoi les marges négatives ne prennent-elles pas effet dans certains cas? Pendant la programmation, les marges négatives dans CSS (négatif ...
 Le texte sous la disposition Flex est omis mais le conteneur est ouvert? Comment le résoudre?
Apr 05, 2025 pm 11:00 PM
Le texte sous la disposition Flex est omis mais le conteneur est ouvert? Comment le résoudre?
Apr 05, 2025 pm 11:00 PM
Le problème de l'ouverture des conteneurs en raison d'une omission excessive du texte sous disposition flexible et de solutions est utilisé ...
 Comment extraire efficacement le code JavaScript pour les diagrammes de carrousel Web?
Apr 05, 2025 pm 12:18 PM
Comment extraire efficacement le code JavaScript pour les diagrammes de carrousel Web?
Apr 05, 2025 pm 12:18 PM
En commençant par le Code du carrousel de la page d'accueil de Baidu News, de nombreuses personnes espèrent extraire le code JavaScript des pages Web pour obtenir des effets de page Web similaires, tels que Baidu New ...
