

1. Installez la bibliothèque de requêtes
Étant donné que le processus d'apprentissage utilise le langage Python, vous devez installer Python à l'avance. J'ai installé Python 3.8. Vous pouvez vérifier la version de Python que vous avez installée en exécutant la commande python --version. Il est recommandé d'installer Python 3. Version X ou supérieure.
Après avoir installé Python, vous pouvez directement installer la bibliothèque de requêtes via la commande suivante.
pip install requests
Ps : Vous pouvez passer à des sources de pip nationales, telles que Alibaba et Douban, qui sont rapides
Afin de démontrer la fonction, j'ai utilisé nginx pour simuler un site Web simple.
Après le téléchargement, exécutez simplement le programme nginx.exe directement dans le répertoire racine (Remarque : sous environnement Windows).
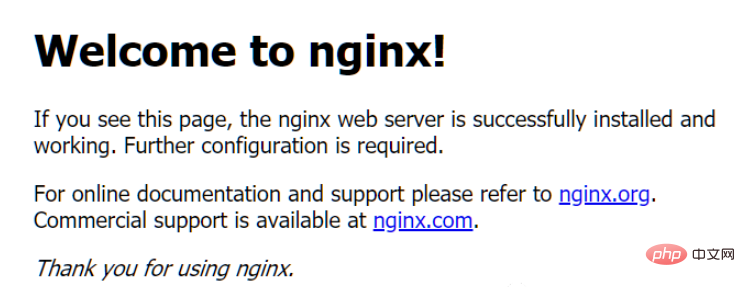
À ce moment-là, lorsque l'ordinateur local accède à : http://127.0.0.1, il entrera dans une page par défaut de nginx.
2. Obtenez la page Web
Ensuite, nous commençons à utiliser des requêtes pour simuler une requête et obtenir le code source de la page.
import requestsr = requests.get('http://127.0.0.1')print(r.text)Les résultats obtenus après l'exécution sont les suivants :
nbsp;html><title>Welcome to nginx!</title><style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; }</style><h2>Welcome to nginx!</h2><p>If you see this page, the nginx web server is successfully installed andworking. Further configuration is required.</p>
<p>For online documentation and support please refer to<a>nginx.org</a>.<br>Commercial support is available at<a>nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>3. À propos des requêtes
Il existe de nombreuses requêtes courantes. Par exemple, l'exemple ci-dessus utilise la requête GET. Voici une introduction détaillée à ces méthodes de requête courantes. .
4. Requête GET
4.1. Initier une requête
Nous utilisons la même méthode pour initier une requête GET :
import requests r = requests.get('http://httpbin.org/get') print(r.text)Le résultat du retour est le suivant :
{"args": {}, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5f846520-19f215aa46213a2b4241c18a" }, "origin": "xxxx", "url": "http://httpbin.org/get"}En renvoyant le résultat, nous pouvons voir le résultat renvoyé Les informations incluses sont : En-têtes, URL, IP, etc.
4.2. Ajouter des paramètres
Habituellement, l'URL que nous visitons contiendra certains paramètres, tels que : l'identifiant est 100, le nom est YOOAO. Pour un accès normal, nous écrirons l'URL d'accès suivante :
http://httpbin.org/get?id=100&name=YOOAO
Évidemment, c'est très gênant, et ce sera sujet aux erreurs lorsqu'il y a de nombreux paramètres. À ce stade, nous pouvons optimiser le contenu d'entrée via le paramètre params.
import requests data = { 'id': '100', 'name': 'YOOAO'} r = requests.get('http://httpbin.org/get', params=data) print(r.text)Voici le résultat renvoyé en exécutant le code comme suit :
{"args": {"id": "100", "name": "YOOAO" }, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5f84658a-1cd0437b4cf34835410d7161" }, "origin": "xxx.xxxx.xxx.xxx", "url": "http://httpbin.org/get?id=100&name=YOOAO"}En renvoyant le résultat, nous pouvons voir que les paramètres transmis via le dictionnaire sont automatiquement construits dans une URL complète, et nous n'avons pas besoin de compléter manuellement le construction nous-mêmes.
4.3. Traitement du résultat de retour
Le résultat de retour est au format json, nous pouvons donc utiliser la méthode d'appel de json pour analyser. Si le contenu renvoyé n'est pas au format json, cet appel signalera une erreur.
import requests
r = requests.get('http://httpbin.org/get') print(type(r.text)) print(type(r.json()))Résultats de retour :
<class><class></class></class>
4.4. Capture de contenu
Ici, nous utilisons des expressions régulières simples pour capturer le contenu de toutes les balises Récupération des résultats :
import requestsimport re
r = requests.get('http://127.0.0.1')pattern = re.compile('<a.>(.*?)', re.S)a_content = re.findall(pattern, r.text)print(a_content)</a.>Une simple acquisition de page et une exploration du contenu sont terminées ici,
4.5, téléchargement du fichier de donnéesL'exemple ci-dessus renvoie toutes les informations de la page, si nous voulons obtenir les informations de la page pour les images, l'audio et la vidéo fichiers, nous devons apprendre à capturer les données binaires de la page. Nous pouvons utiliser la méthode open pour terminer le téléchargement de fichiers binaires tels que des images. Exemple de code :
['nginx.org', 'nginx.com']
Dans la méthode open, son premier paramètre est le nom du fichier, et le deuxième paramètre signifie l'ouvrir sous forme binaire, et vous pouvez écrire dans le fichier Entrez les données binaires.
Une fois l'opération terminée, les images téléchargées seront enregistrées dans le même dossier du fichier en cours d'exécution. En utilisant le même principe, nous pouvons traiter des fichiers vidéo et audio.
4.6. Ajouter des en-têtesDans l'exemple ci-dessus, nous avons directement lancé la requête sans ajouter d'en-têtes. Certains sites Web provoquent des exceptions d'accès car les requêtes ne comportent pas d'en-têtes de requête. Ici, nous pouvons ajouter manuellement le contenu des en-têtes et simuler l'ajout de l'Uer. -Code de contenu de l'agent dans les en-têtes :
import requests
r = requests.get('http://tu.ossfiles.cn:9186/group3/M00/09/FB/rBpVfl8QFLOAYhhcAAC-pTdNj7g471.jpg')with open('image.jpg', 'wb') as f: f.write(r.content)print('下载完成')Résultat de l'exécution :
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36'}r = requests.get('http://httpbin.org/get', headers=headers)print(r.text)Le résultat peut être vu que la valeur de User-Agent a changé. Pas le précédent : python-requests/2.23.0.
5. Requête POSTMaintenant que nous avons entendu parler de la requête GET, parlons d'une autre méthode de requête courante : la requête POST.
使用 requests 实现 POST 请求的代码如下:
import requestsdata = { 'id': '100', 'name': 'YOOAO'}
r = requests.post("http://httpbin.org/post", data=data)print(r.text)结果如下
{"args": {}, "data": "", "files": {}, "form": {"id": "100", "name": "YOOAO" }, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "17", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5ec8f4a0-affca27a05e320a84ca6535a" }, "json": null, "origin": "xxxx", "url": "http://httpbin.org/post"}从 form 中我们看到了自己提交的数据,可见我们的 POST 请求访问成功。
6、响应
访问URL时,有请求就会有响应,上面的示例使用 text 和 content 获取了响应的内容。除此以外,还有很多属性和方法可以用来获取其他信息,比如状态码、响应头、Cookies 等。
import requests
r = requests.get('http://127.0.0.1/')print(type(r.status_code), r.status_code)print(type(r.headers), r.headers)print(type(r.cookies), r.cookies)print(type(r.url), r.url)print(type(r.history), r.history)关于状态码,requests 还提供了一个内置的状态码查询对象 requests.codes,用法示例如下:
import requestsr = requests.get('http://127.0.0.1/')exit() if not r.status_code == requests.codes.ok else print('Request Successfully')==========执行结果==========Request Successfully这里通过比较返回码和内置的成功的返回码,来保证请求得到了正常响应,输出成功请求的消息,否则程序终止。
这里我们用 requests.codes.ok 得到的是成功的状态码 200。
这样的话,我们就不用再在程序里面写状态码对应的数字了,用字符串表示状态码会显得更加直观。
下面是响应码和查询条件对照信息:
# 信息性状态码 100: ('continue',), 101: ('switching_protocols',), 102: ('processing',), 103: ('checkpoint',), 122: ('uri_too_long', 'request_uri_too_long'),
# 成功状态码 200: ('ok', 'okay', 'all_ok', 'all_okay', 'all_good', '\\o/', '✓'), 201: ('created',), 202: ('accepted',), 203: ('non_authoritative_info', 'non_authoritative_information'), 204: ('no_content',), 205: ('reset_content', 'reset'), 206: ('partial_content', 'partial'), 207: ('multi_status', 'multiple_status', 'multi_stati', 'multiple_stati'), 208: ('already_reported',), 226: ('im_used',),
# 重定向状态码 300: ('multiple_choices',), 301: ('moved_permanently', 'moved', '\\o-'), 302: ('found',), 303: ('see_other', 'other'), 304: ('not_modified',), 305: ('use_proxy',), 306: ('switch_proxy',), 307: ('temporary_redirect', 'temporary_moved', 'temporary'), 308: ('permanent_redirect', 'resume_incomplete', 'resume',), # These 2 to be removed in 3.0
# 客户端错误状态码 400: ('bad_request', 'bad'), 401: ('unauthorized',), 402: ('payment_required', 'payment'), 403: ('forbidden',), 404: ('not_found', '-o-'), 405: ('method_not_allowed', 'not_allowed'), 406: ('not_acceptable',), 407: ('proxy_authentication_required', 'proxy_auth', 'proxy_authentication'), 408: ('request_timeout', 'timeout'), 409: ('conflict',), 410: ('gone',), 411: ('length_required',), 412: ('precondition_failed', 'precondition'), 413: ('request_entity_too_large',), 414: ('request_uri_too_large',), 415: ('unsupported_media_type', 'unsupported_media', 'media_type'), 416: ('requested_range_not_satisfiable', 'requested_range', 'range_not_satisfiable'), 417: ('expectation_failed',), 418: ('im_a_teapot', 'teapot', 'i_am_a_teapot'), 421: ('misdirected_request',), 422: ('unprocessable_entity', 'unprocessable'), 423: ('locked',), 424: ('failed_dependency', 'dependency'), 425: ('unordered_collection', 'unordered'), 426: ('upgrade_required', 'upgrade'), 428: ('precondition_required', 'precondition'), 429: ('too_many_requests', 'too_many'), 431: ('header_fields_too_large', 'fields_too_large'), 444: ('no_response', 'none'), 449: ('retry_with', 'retry'), 450: ('blocked_by_windows_parental_controls', 'parental_controls'), 451: ('unavailable_for_legal_reasons', 'legal_reasons'), 499: ('client_closed_request',),
# 服务端错误状态码 500: ('internal_server_error', 'server_error', '/o\\', '✗'), 501: ('not_implemented',), 502: ('bad_gateway',), 503: ('service_unavailable', 'unavailable'), 504: ('gateway_timeout',), 505: ('http_version_not_supported', 'http_version'), 506: ('variant_also_negotiates',), 507: ('insufficient_storage',), 509: ('bandwidth_limit_exceeded', 'bandwidth'), 510: ('not_extended',), 511: ('network_authentication_required', 'network_auth', 'network_authentication')7、SSL 证书验证
现在很多网站都会验证证书,我们可以设置参数来忽略证书的验证。
import requests
response = requests.get('https://XXXXXXXX', verify=False)print(response.status_code)或者制定本地证书作为客户端证书:
import requests
response = requests.get('https://xxxxxx', cert=('/path/server.crt', '/path/server.key'))print(response.status_code)注意:本地私有证书的 key 必须是解密状态,加密状态的 key 是不支持的。
8、设置超时
很多时候我们需要设置超时时间来控制访问的效率,遇到访问慢的链接直接跳过。
示例代码:
import requests# 设置超时时间为 10 秒r = requests.get('https://httpbin.org/get', timeout=10)print(r.status_code)将连接时间和读取时间分开计算:
r = requests.get('https://httpbin.org/get', timeout=(3, 10))不添加参数,默认不设置超时时间,等同于:
r = requests.get('https://httpbin.org/get', timeout=None)9、身份认证
遇到一些网站需要输入用户名和密码,我们可以通过 auth 参数进行设置。
import requests from requests.auth import HTTPBasicAuth # 用户名为 admin ,密码为 admin r = requests.get('https://xxxxxx/', auth=HTTPBasicAuth('admin', 'admin')) print(r.status_code)简化写法:
import requests
r = requests.get('https://xxxxxx', auth=('admin', 'admin'))print(r.status_code)10、设置代理
如果频繁的访问某个网站时,后期会被一些反爬程序识别,要求输入验证信息,或者其他信息,甚至IP被封无法再次访问,这时候,我们可以通过设置代理来避免这样的问题。
import requests
proxies = { "http": "http://10.10.1.10:3128", "https": "http://10.10.1.10:1080",}
requests.get("http://example.org", proxies=proxies)若你的代理需要使用HTTP Basic Auth,可以使用
http://user:password@host/ 语法:
proxies = { "http": "http://user:pass@10.10.1.10:3128/",}要为某个特定的连接方式或者主机设置代理,使用 scheme://hostname 作为 key, 它会针对指定的主机和连接方式进行匹配。
proxies = {'http://10.20.1.128': 'http://10.10.1.10:5323'}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



