
 Périphériques technologiques
IA
Un article pour comprendre la vision par ordinateur, plein d'informations utiles
Périphériques technologiques
IA
Un article pour comprendre la vision par ordinateur, plein d'informations utiles
Un article pour comprendre la vision par ordinateur, plein d'informations utiles

1. Introduction
La vision par ordinateur (Computer Vision), souvent appelée CV, est un domaine de recherche qui utilise la technologie pour aider les ordinateurs à « voir » et à « comprendre » les images, par exemple en permettant aux ordinateurs de comprendre le contenu de photos ou de vidéos. .
Cet article fournira une introduction générale à la vision par ordinateur. Cet article est divisé en six parties, qui sont :
- Pourquoi la vision par ordinateur est importante
- Qu'est-ce que la vision par ordinateur
- Principes de base de la vision par ordinateur
- Tâches typiques de la vision par ordinateur
- Scénarios d'application de la vision par ordinateur dans la vie quotidienne
- Défis de la vision par ordinateur
2. Pourquoi la vision par ordinateur est importante
Physiologiquement, la génération de la vision commence par l'excitation des cellules sensorielles de l'organe visuel, et le système nerveux visuel traite les informations collectées plus tard. Nous, les humains, utilisons la vision pour comprendre intuitivement la forme et l’état des choses devant nous. La plupart d’entre nous comptent sur la vision pour cuisiner, franchir les obstacles, lire les panneaux de signalisation, regarder des vidéos et d’innombrables autres tâches. En fait, s'il n'y avait pas des groupes particuliers comme les aveugles, la grande majorité des gens obtiennent des informations externes par la vue, et cette proportion atteint 80 % - cette proportion n'est pas sans fondement, selon le célèbre psychologue expérimental Treicher. a confirmé par un grand nombre d'expériences que 83 % des informations que l'homme obtient proviennent de la vision, 11 % de l'ouïe et les 6 % restants proviennent de l'odorat, du toucher et du goût. Par conséquent, pour l’homme, la vision est sans aucun doute le sens le plus important.
Non seulement les humains sont des « animaux visuels », mais pour la plupart des animaux, la vision joue également un rôle très important. Grâce à la vision, les humains et les animaux perçoivent la taille, la lumière et l'ombre, la couleur et le mouvement des objets externes et obtiennent diverses informations importantes pour la survie du corps. Grâce à ces informations, ils peuvent apprendre à quoi ressemble le monde environnant. comment interagir avec le monde.

Avant l'avènement de la vision par ordinateur, les images étaient dans un état de boîte noire pour les ordinateurs. Pour un ordinateur, une image n’est qu’un fichier ou une chaîne de données. L'ordinateur ne sait pas quel est le contenu de l'image. Il sait seulement quelle est sa taille, combien de mémoire elle occupe, dans quel format elle se trouve, etc.
Si les ordinateurs et l'intelligence artificielle veulent jouer un rôle important dans le monde réel, ils doivent comprendre les images ! C'est pourquoi, depuis un demi-siècle, les informaticiens tentent de trouver des moyens de rendre les ordinateurs visibles, ce qui donne naissance au domaine de la « vision par ordinateur ».

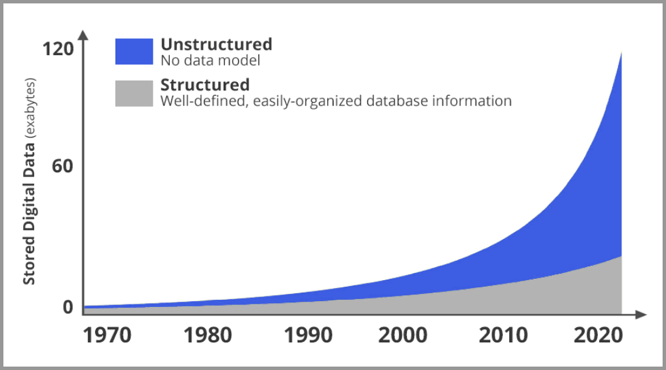
Le développement rapide d'Internet a également rendu la vision par ordinateur particulièrement importante. La figure ci-dessous est un graphique de tendance de la quantité de nouvelles données sur le réseau depuis 2020. Les graphiques gris sont des données structurées, les graphiques bleus sont des données non structurées (principalement des images et des vidéos). Il est évident que le nombre de photos et de vidéos augmente à un rythme exponentiel.
Internet est composé de texte et d'images. La recherche de texte est relativement simple, mais pour rechercher des images, l'algorithme doit savoir ce que contient l'image. Pendant longtemps, les humains ne disposaient pas de suffisamment de technologie pour comprendre le contenu des images et des vidéos et ne pouvaient s’appuyer que sur des annotations manuelles pour obtenir des descriptions d’images ou de vidéos. Comment permettre aux ordinateurs de mieux comprendre ces informations d'image est un défi majeur auquel est confrontée la technologie informatique d'aujourd'hui. Afin d'utiliser pleinement les données d'image ou de vidéo, vous devez laisser l'ordinateur « voir » l'image ou la vidéo et en comprendre le contenu.
3. Qu'est-ce que la vision par ordinateur ?
La vision par ordinateur est une branche importante dans le domaine de l'intelligence artificielle. En termes simples, le problème qu'elle résout est de permettre aux ordinateurs de comprendre le contenu des images ou des vidéos. Par exemple : l'animal sur la photo est-il un chat ou un chien ? La personne sur la photo est-elle Lao Zhang ou Lao Wang ? Que font les personnes dans la vidéo ? En outre, la vision par ordinateur fait référence à l'utilisation de caméras et d'ordinateurs au lieu des yeux humains pour identifier, suivre et mesurer des cibles, ainsi que pour effectuer un traitement graphique afin d'obtenir des images plus adaptées à l'observation de l'œil humain ou à la transmission à des instruments de détection. En tant que discipline scientifique, la vision par ordinateur étudie les théories et technologies connexes, en essayant de construire des systèmes d'intelligence artificielle capables d'obtenir des informations de haut niveau à partir d'images ou de données multidimensionnelles. D'un point de vue technique, il cherche à tirer parti des systèmes automatisés pour imiter le système visuel humain afin d'accomplir des tâches. Le but ultime de la vision par ordinateur est de permettre aux ordinateurs d’observer et de comprendre le monde à travers la vision comme le font les humains, et d’avoir la capacité de s’adapter à l’environnement de manière autonome. Mais il est très difficile de réaliser réellement qu'un ordinateur peut percevoir le monde à travers une caméra, car même si les images capturées par la caméra sont les mêmes que celles que nous voyons habituellement, pour l'ordinateur, toute image n'est qu'un arrangement et une combinaison de pixels. valeurs. Un tas de nombres rigides. Comment permettre aux ordinateurs de lire des indices visuels significatifs à partir de ces nombres rigides est un problème que la vision par ordinateur devrait résoudre.
4. Principes de base de la vision par ordinateur
Tous ceux qui ont utilisé un appareil photo ou un téléphone portable savent que les ordinateurs sont doués pour prendre des photos avec une fidélité et des détails incroyables. Dans une certaine mesure, la « vision » artificielle des ordinateurs est meilleure que celle des ordinateurs. les humains. La capacité visuelle est beaucoup plus forte depuis la naissance. Mais comme on dit habituellement « entendre ne veut pas dire comprendre », « voir » ne veut pas dire « comprendre ». Si l’on veut qu’un ordinateur « comprenne » vraiment les images, ce n’est pas simple. Une image est une grande grille de pixels, et chaque pixel a une couleur, qui est une combinaison de trois couleurs primaires : rouge, vert et bleu. En combinant les intensités de trois couleurs - appelées valeurs RVB - nous pouvons obtenir n'importe quelle couleur. L'algorithme de vision par ordinateur le plus simple et le plus approprié pour commencer est le suivant : pour suivre un objet coloré, comme une balle rose, nous notons d'abord la couleur de la balle, enregistrons la valeur RVB du pixel central, puis transmettons l'image au programme , laissant le programme trouver le pixel le plus proche de cette couleur. L'algorithme peut commencer par le coin supérieur gauche, examiner chaque pixel et calculer la différence par rapport à la couleur cible. Après avoir vérifié chaque pixel, la partie la plus proche des pixels est probablement le pixel où se trouve la balle. Cet algorithme ne se limite pas à s'exécuter sur cette seule image, nous pouvons exécuter l'algorithme sur chaque image de la vidéo pour suivre la position de la balle. Bien sûr, en raison de l'influence de la lumière, de l'ombre et d'autres facteurs, la couleur de la balle changera. Elle ne sera pas exactement la même que la valeur RVB que nous avons enregistrée, mais elle en sera très proche. Cependant, dans certains cas extrêmes, comme un match de football de nuit, l'effet de suivi peut être très faible ; et si l'un des maillots des équipes est de la même couleur que le ballon, l'algorithme sera complètement « évanoui ». Par conséquent, à moins que l’environnement ne puisse être strictement contrôlé, de tels algorithmes de suivi des couleurs sont rarement utilisés en pratique. De nos jours, les algorithmes de vision par ordinateur les plus utilisés impliquent généralement des méthodes et des technologies de « Deep Learning ». Parmi elles, le réseau neuronal convolutif (CNN) est le plus largement utilisé en raison de ses performances supérieures. Les connaissances impliquées dans le « deep learning » étant trop étendues, cet article ne les décrira pas plus en détail. Si vous souhaitez en savoir plus sur le "deep learning", vous pouvez également consulter le cours d'introduction à l'IA - "Intel® OpenVINO™ Tool Suite Elementary Course". Il commence par les concepts de base de l'IA, présente des connaissances pertinentes sur les applications d'intelligence artificielle et de vision, et aide les utilisateurs à comprendre rapidement les concepts de base et les scénarios d'application de la suite d'outils Intel® OpenVINO™. L'ensemble du cours comprend le traitement vidéo, les connaissances liées à l'apprentissage profond, l'accélération d'inférence pour les applications d'intelligence artificielle et des démonstrations de démonstration de la suite d'outils Intel® OpenVINO™. Il vous guide étape par étape pour maîtriser l'apprentissage profond, du plus superficiel au plus profond.
5. Tâches typiques de la vision par ordinateur
- Classification d'images
La classification d'images consiste à distinguer différentes catégories d'images en fonction de leurs informations sémantiques. Elle est au cœur de la vision par ordinateur et est la détection d'objets, la segmentation d'images, le suivi d'objets. et analyse du comportement, reconnaissance faciale et autres tâches visuelles de haut niveau. Par exemple, dans l'image ci-dessous, grâce à la classification des images, l'ordinateur reconnaît la personne, l'arbre, l'herbe et le ciel dans l'image.

La classification d'images est largement utilisée dans de nombreux domaines, tels que : la reconnaissance faciale et l'analyse vidéo intelligente dans le domaine de la sécurité, la reconnaissance de scènes de circulation dans le domaine des transports, la récupération d'images basée sur le contenu et la classification automatique des albums photos sur Internet. domaine, Reconnaissance d'images dans le domaine médical, etc.
- Détection d'objets
Le but de la tâche de détection d'objet est de donner une image ou une image vidéo et de laisser l'ordinateur trouver les positions de tous les objets qu'il contient et donner la catégorie spécifique de chaque objet. Comme le montre la figure ci-dessous, en prenant comme exemple la reconnaissance et la détection de personnes, les bordures sont utilisées pour marquer la position de toutes les personnes dans l'image.

Dans la détection de cibles multi-catégories, des bordures de différentes couleurs sont généralement utilisées pour marquer les emplacements des différents objets détectés, comme le montre la figure ci-dessous.

- Segmentation sémantique
La segmentation sémantique est une tâche fondamentale en vision par ordinateur. Dans la segmentation sémantique, nous devons diviser l'entrée visuelle en différentes catégories sémantiquement interprétables. Il divise l'image entière en groupes de pixels, qui sont ensuite étiquetés et classés. Par exemple, nous pourrions avoir besoin de distinguer tous les pixels d’une image qui appartiennent à des voitures et de colorer ces pixels en bleu. Comme indiqué ci-dessous, l'image est divisée en étiquettes de personnes (rouge), d'arbres (vert foncé), d'herbe (vert clair) et de ciel (bleu).
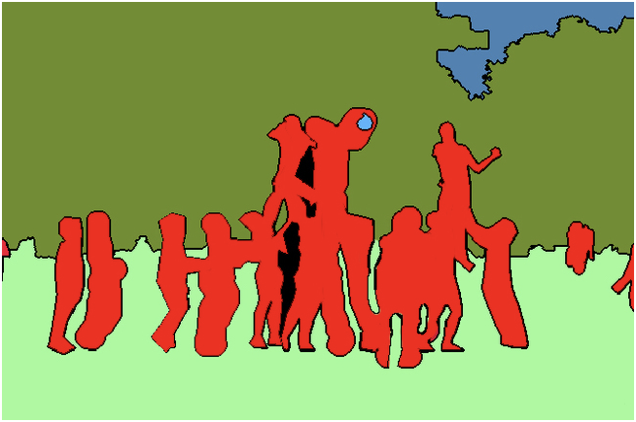
La segmentation d'instance est une combinaison de détection de cible et de segmentation sémantique. La cible est détectée dans l'image (détection de cible), puis chaque pixel est étiqueté (segmentation sémantique). En comparant les figures ci-dessus et ci-dessous, nous pouvons voir que si des cibles humaines sont utilisées, la segmentation sémantique ne distingue pas les différentes instances appartenant à la même catégorie (toutes les personnes sont marquées en rouge), tandis que la segmentation des instances distingue les différentes instances d'une même catégorie (différentes les couleurs sont utilisées pour distinguer différentes personnes).

Suivi des cibles Le suivi des cibles fait référence à la détection, à l'extraction, à l'identification et au suivi de cibles en mouvement dans des séquences d'images, à l'obtention des paramètres de mouvement des cibles en mouvement, au traitement et à l'analyse, et à la compréhension comportementale des cibles en mouvement pour en savoir plus. Tâches de détection de niveau supérieur.
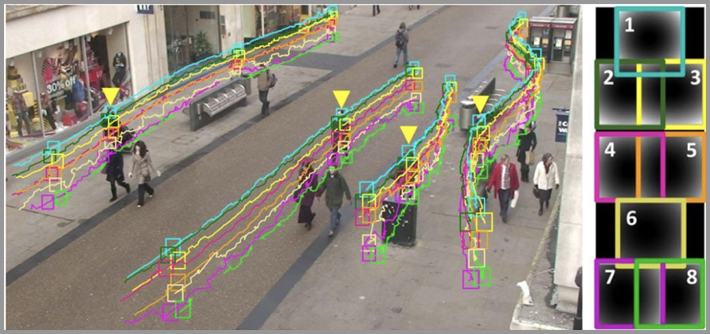
6. Scénarios d'application de la vision par ordinateur dans la vie quotidienne
Les scénarios d'application de la vision par ordinateur sont très larges. Voici quelques scénarios d'application courants dans la vie. ·Reconnaissance faciale sur le contrôle d'accès et Alipay

- Reconnaissance des plaques d'immatriculation dans les parkings et les péages

- Identification des risques lors du téléchargement de vidéos sur des sites Web ou des applications

- Tik Tok Waiting pour divers accessoires de selfie sur l'APP (la position du visage doit d'abord être reconnue)
7. Défis rencontrés par la vision par ordinateur
Actuellement, la technologie de vision par ordinateur se développe rapidement et a atteint une échelle industrielle préliminaire. Le développement futur de la technologie de vision par ordinateur est principalement confronté aux défis suivants : Premièrement, comment mieux la combiner avec d'autres technologies dans différents domaines d'application. La vision par ordinateur peut utiliser largement le Big Data pour résoudre certains problèmes. Elle a progressivement mûri et peut être utilisée. surpasser les humains. Cependant, il est impossible d'atteindre une grande précision sur certaines questions : la seconde est de savoir comment réduire le temps de développement et les coûts de main-d'œuvre des algorithmes de vision par ordinateur. Actuellement, les algorithmes de vision par ordinateur nécessitent une grande quantité de données et d'annotations manuelles. un long cycle de recherche et de développement pour répondre aux exigences du domaine d'application. La précision requise et le temps requis ; le troisième est de savoir comment accélérer la conception et le développement de nouveaux algorithmes. Avec l'émergence de nouveaux matériels d'imagerie et de puces d'intelligence artificielle, la conception et le développement d’algorithmes de vision par ordinateur pour différentes puces et équipements d’acquisition de données constituent également l’un des défis.
8. Conclusion
La vision par ordinateur est l'une des technologies les plus dynamiques et les plus utilisées dans le domaine de l'intelligence artificielle. Elle est comme les « yeux » de l'intelligence artificielle, capturant et analysant plus d'informations pour tous les horizons. Avec le changement d'algorithmes, la mise à niveau de la puissance de calcul du matériel, l'explosion des données et le réseau à haut débit provoqué par le développement de la technologie 5G à l'avenir, la vision par ordinateur disposera également d'un espace de développement plus large en termes d'applications. Attendons et voyons !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Publication du classement national CSRankings 2024 en informatique ! La CMU domine la liste, le MIT sort du top 5
Mar 25, 2024 pm 06:01 PM
Publication du classement national CSRankings 2024 en informatique ! La CMU domine la liste, le MIT sort du top 5
Mar 25, 2024 pm 06:01 PM
Les classements majeurs nationaux en informatique 2024CSRankings viennent d’être publiés ! Cette année, dans le classement des meilleures universités CS aux États-Unis, l'Université Carnegie Mellon (CMU) se classe parmi les meilleures du pays et dans le domaine de CS, tandis que l'Université de l'Illinois à Urbana-Champaign (UIUC) a été classé deuxième pendant six années consécutives. Georgia Tech s'est classée troisième. Ensuite, l’Université de Stanford, l’Université de Californie à San Diego, l’Université du Michigan et l’Université de Washington sont à égalité au quatrième rang mondial. Il convient de noter que le classement du MIT a chuté et est sorti du top cinq. CSRankings est un projet mondial de classement des universités dans le domaine de l'informatique initié par le professeur Emery Berger de la School of Computer and Information Sciences de l'Université du Massachusetts Amherst. Le classement est basé sur des objectifs
 Le Bureau à distance ne peut pas authentifier l'identité de l'ordinateur distant
Feb 29, 2024 pm 12:30 PM
Le Bureau à distance ne peut pas authentifier l'identité de l'ordinateur distant
Feb 29, 2024 pm 12:30 PM
Le service Bureau à distance Windows permet aux utilisateurs d'accéder aux ordinateurs à distance, ce qui est très pratique pour les personnes qui doivent travailler à distance. Cependant, des problèmes peuvent survenir lorsque les utilisateurs ne peuvent pas se connecter à l'ordinateur distant ou lorsque Remote Desktop ne peut pas authentifier l'identité de l'ordinateur. Cela peut être dû à des problèmes de connexion réseau ou à un échec de vérification du certificat. Dans ce cas, l'utilisateur devra peut-être vérifier la connexion réseau, s'assurer que l'ordinateur distant est en ligne et essayer de se reconnecter. De plus, s'assurer que les options d'authentification de l'ordinateur distant sont correctement configurées est essentiel pour résoudre le problème. De tels problèmes avec les services Bureau à distance Windows peuvent généralement être résolus en vérifiant et en ajustant soigneusement les paramètres. Le Bureau à distance ne peut pas vérifier l'identité de l'ordinateur distant en raison d'un décalage d'heure ou de date. Veuillez vous assurer que vos calculs
 Impossible d'ouvrir l'objet Stratégie de groupe sur cet ordinateur
Feb 07, 2024 pm 02:00 PM
Impossible d'ouvrir l'objet Stratégie de groupe sur cet ordinateur
Feb 07, 2024 pm 02:00 PM
Parfois, le système d'exploitation peut mal fonctionner lors de l'utilisation d'un ordinateur. Le problème que j'ai rencontré aujourd'hui était que lors de l'accès à gpedit.msc, le système indiquait que l'objet de stratégie de groupe ne pouvait pas être ouvert car les autorisations appropriées pouvaient faire défaut. L'objet de stratégie de groupe sur cet ordinateur n'a pas pu être ouvert. Solution : 1. Lors de l'accès à gpedit.msc, le système indique que l'objet de stratégie de groupe sur cet ordinateur ne peut pas être ouvert en raison d'un manque d'autorisations. Détails : Le système ne parvient pas à localiser le chemin spécifié. 2. Une fois que l'utilisateur a cliqué sur le bouton de fermeture, la fenêtre d'erreur suivante apparaît. 3. Vérifiez immédiatement les enregistrements du journal et combinez les informations enregistrées pour découvrir que le problème réside dans le fichier C:\Windows\System32\GroupPolicy\Machine\registry.pol.
 Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
L'article de StableDiffusion3 est enfin là ! Ce modèle est sorti il y a deux semaines et utilise la même architecture DiT (DiffusionTransformer) que Sora. Il a fait beaucoup de bruit dès sa sortie. Par rapport à la version précédente, la qualité des images générées par StableDiffusion3 a été considérablement améliorée. Il prend désormais en charge les invites multithèmes, et l'effet d'écriture de texte a également été amélioré et les caractères tronqués n'apparaissent plus. StabilityAI a souligné que StableDiffusion3 est une série de modèles avec des tailles de paramètres allant de 800M à 8B. Cette plage de paramètres signifie que le modèle peut être exécuté directement sur de nombreux appareils portables, réduisant ainsi considérablement l'utilisation de l'IA.
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
Cet article explore le problème de la détection précise d'objets sous différents angles de vue (tels que la perspective et la vue à vol d'oiseau) dans la conduite autonome, en particulier comment transformer efficacement les caractéristiques de l'espace en perspective (PV) en vue à vol d'oiseau (BEV). implémenté via le module Visual Transformation (VT). Les méthodes existantes sont globalement divisées en deux stratégies : la conversion 2D en 3D et la conversion 3D en 2D. Les méthodes 2D vers 3D améliorent les caractéristiques 2D denses en prédisant les probabilités de profondeur, mais l'incertitude inhérente aux prévisions de profondeur, en particulier dans les régions éloignées, peut introduire des inexactitudes. Alors que les méthodes 3D vers 2D utilisent généralement des requêtes 3D pour échantillonner des fonctionnalités 2D et apprendre les poids d'attention de la correspondance entre les fonctionnalités 3D et 2D via un transformateur, ce qui augmente le temps de calcul et de déploiement.
 Impossible de copier les données du bureau distant vers l'ordinateur local
Feb 19, 2024 pm 04:12 PM
Impossible de copier les données du bureau distant vers l'ordinateur local
Feb 19, 2024 pm 04:12 PM
Si vous rencontrez des problèmes pour copier des données d'un poste de travail distant vers votre ordinateur local, cet article peut vous aider à les résoudre. La technologie de bureau à distance permet à plusieurs utilisateurs d'accéder à des bureaux virtuels sur un serveur central, assurant ainsi la protection des données et la gestion des applications. Cela contribue à garantir la sécurité des données et permet aux entreprises de gérer leurs applications plus efficacement. Les utilisateurs peuvent être confrontés à des difficultés lors de l'utilisation du bureau à distance, notamment l'impossibilité de copier les données du bureau distant vers l'ordinateur local. Cela peut être dû à différents facteurs. Par conséquent, cet article fournira des conseils pour résoudre ce problème. Pourquoi ne puis-je pas copier depuis le poste de travail distant vers mon ordinateur local ? Lorsque vous copiez un fichier sur votre ordinateur, il est temporairement stocké dans un emplacement appelé presse-papiers. Si vous ne pouvez pas utiliser cette méthode pour copier les données du poste de travail distant vers votre ordinateur local
 'Minecraft' se transforme en une ville IA et les habitants des PNJ jouent comme de vraies personnes
Jan 02, 2024 pm 06:25 PM
'Minecraft' se transforme en une ville IA et les habitants des PNJ jouent comme de vraies personnes
Jan 02, 2024 pm 06:25 PM
Veuillez noter que cet homme carré fronça les sourcils, pensant à l'identité des « invités non invités » devant lui. Il s’est avéré qu’elle se trouvait dans une situation dangereuse, et une fois qu’elle s’en est rendu compte, elle a rapidement commencé une recherche mentale pour trouver une stratégie pour résoudre le problème. Finalement, elle a décidé de fuir les lieux, de demander de l'aide le plus rapidement possible et d'agir immédiatement. En même temps, la personne de l'autre côté pensait la même chose qu'elle... Il y avait une telle scène dans "Minecraft" où tous les personnages étaient contrôlés par l'intelligence artificielle. Chacun d’eux a un cadre identitaire unique. Par exemple, la jeune fille mentionnée précédemment est une coursière de 17 ans mais intelligente et courageuse. Ils ont la capacité de se souvenir, de penser et de vivre comme des humains dans cette petite ville de Minecraft. Ce qui les anime est une toute nouvelle,
