
 Périphériques technologiques
IA
Fuite de documents internes de Google : les grands modèles open source font trop peur, même OpenAI ne peut pas le supporter !
Périphériques technologiques
IA
Fuite de documents internes de Google : les grands modèles open source font trop peur, même OpenAI ne peut pas le supporter !
Fuite de documents internes de Google : les grands modèles open source font trop peur, même OpenAI ne peut pas le supporter !

J'ai vu un article aujourd'hui disant que Google avait divulgué un document "Nous n'avons pas de fossé, et OpenAI non plus." Il décrit le point de vue d'un certain employé de Google (une société non Google) sur l'IA open source. , et le sens général est C'est comme ceci :
Après que ChatGPT soit devenu populaire, tous les grands fabricants affluent vers LLM et investissent follement.
Google travaille également dur, dans l'espoir de faire son retour, mais personne ne peut gagner cette course aux armements car des tiers mangent tranquillement ce gros gâteau.
Ce tiers est un grand modèle open source.
Les grands modèles open source l'ont déjà fait :
1. Exécutez le modèle de base sur le Pixel 6 à une vitesse de 5 jetons par seconde.
2. Vous pouvez affiner l'IA personnalisée sur votre PC en une nuit :
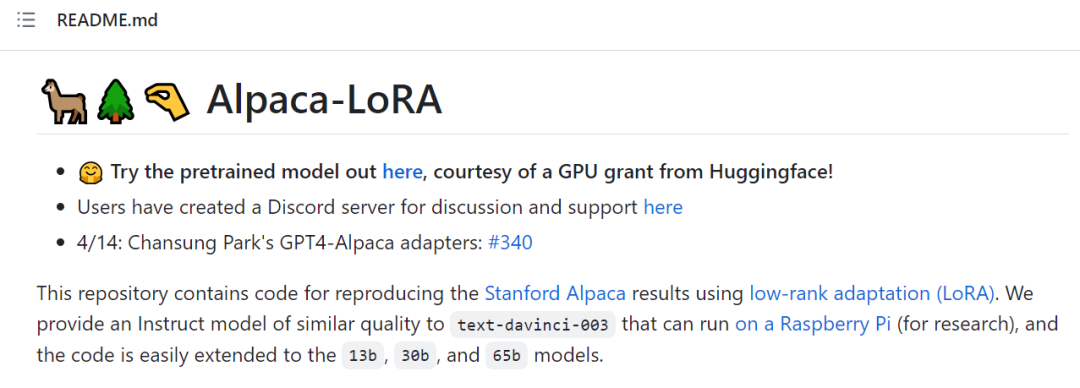
Bien que les modèles OpenAI et Google aient un avantage en termes de qualité, l'écart se réduit à un rythme alarmant :
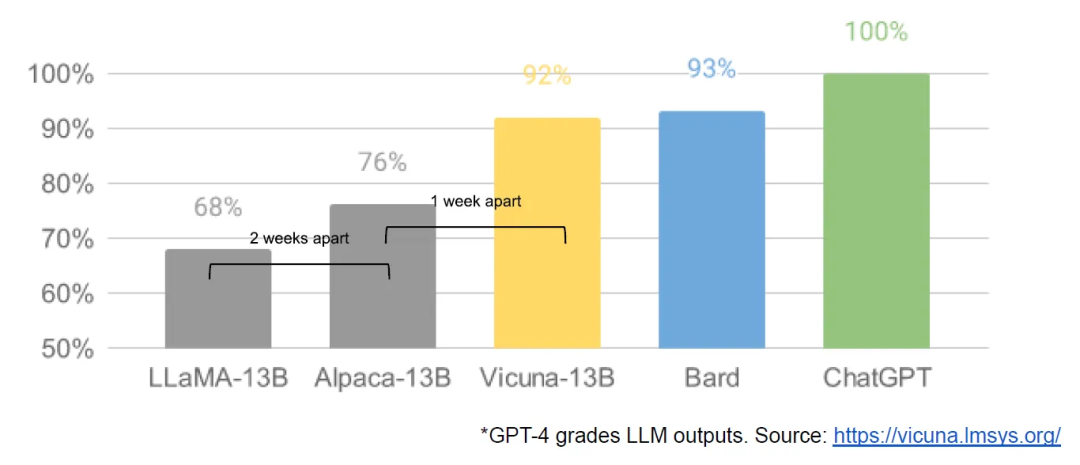
Modèles open source sont plus rapides, personnalisables, plus privés et plus puissants.
Le grand modèle open source fait des choses avec des paramètres de 100 $ et 13 milliards et le fait en quelques semaines ; tandis que Google a du mal avec des paramètres de 10 millions de dollars et 540 milliards en quelques mois ;
Les gens abandonneront définitivement le modèle fermé lorsque les alternatives gratuites et sans restriction seront de qualité comparable au modèle fermé.
Tout a commencé lorsque Facebook open source LLaMA début mars, la communauté open source a obtenu ce modèle de base vraiment performant. Bien qu'il n'y ait pas d'instructions, de réglage de conversation ou de RLHF, la communauté a immédiatement réalisé l'importance de cette chose.
L'innovation qui s'ensuit est tout simplement folle, même mesurée en jours :
2-24 : Facebook lance LLaMA, qui pour le moment n'est autorisée qu'aux instituts de recherche et aux organismes gouvernementaux pour son utilisation
3-03 : LLaMA est divulguée sur le Internet, même si aucune utilisation commerciale n'était autorisée, mais du coup, tout le monde pouvait jouer.
3-12 : Exécuter LLaMA sur Raspberry Pi est très lent et peu pratique
3-13 : Stanford a publié Alpaca, qui a ajouté le réglage des instructions pour LLaMA. Ce qui est encore plus « effrayant », c'est qu'Eric J. Wang de Stanford utilise un RTX. 4090, il n'a fallu que 5 heures pour former un modèle équivalent à Alpaca, réduisant ainsi les besoins en puissance de calcul de ces modèles au niveau du consommateur.
3-18 : 5 jours plus tard, Georgi Gerganov utilise la technologie de quantification 4 bits pour exécuter LLaMA sur le processeur du MacBook, qui est la première solution "sans GPU".
3-19 : Un jour plus tard, des chercheurs de l'Université de Californie à Berkeley, de la CMU, de l'Université de Stanford et de l'Université de Californie à San Diego ont lancé conjointement Vicuna, qui prétend avoir atteint plus de 90 % de la qualité de OpenAI ChatGPT et Google Bard, et en même temps, il a atteint plus de 90 % de la qualité % du temps, surclassant d'autres modèles tels que LLaMA et Stanford Alpaca.
3-25 : Nomic a créé GPT4all, qui est à la fois un modèle et un écosystème, et pour la première fois nous voyons plusieurs modèles rassemblés en un seul endroit
...
En seulement un mois Au sein, réglage des instructions, quantification, améliorations de la qualité, évaluations humaines, multimodalité, RLHF, etc. sont apparues.
Plus important encore, la communauté open source a résolu le problème d'évolutivité et le seuil de formation a été abaissé d'une grande entreprise à une personne, une nuit et un ordinateur personnel puissant.
Donc l'auteur a dit à la fin : OpenAI a aussi fait des erreurs comme nous, et il ne peut pas résister à l'impact de l'open source. Nous devons créer un écosystème pour que l'open source fonctionne pour Google.
Google a déjà implémenté ce paradigme sur Android et Chrome avec beaucoup de succès. Vous devez vous établir en tant que leader de l'open source à grande échelle et continuer à consolider votre position de leader d'opinion et de leader.
Pour être honnête, le développement de grands modèles de langage au cours du dernier mois a été vraiment éblouissant et accablant, et je suis bombardé chaque jour.
Cela me rappelle les premières années où Internet commençait à peine. Un site Web passionnant apparaît aujourd'hui et un autre apparaît demain. Et lorsque l'Internet mobile explose, une application est populaire aujourd'hui, et une autre application le sera demain...
Personnellement, je ne veux pas que ces grands modèles de langage soient contrôlés par des géants. On peut seulement « parasiter » ces modèles géants, appeler leurs API, et développer certaines applications. Ce n'est pas content. Il est préférable de laisser éclore une centaine de fleurs et d’être accessible au plus grand nombre, afin que chacun puisse construire son propre modèle privé.
Désormais, le coût de la formation devrait être abordable pour les petites entreprises. Si les programmeurs ont la capacité de se former, cela peut être une bonne opportunité combinée à des secteurs et des domaines spécifiques.
Si les programmeurs veulent maîtriser avec compétence les grands modèles privatisés, en plus des principes, ils doivent encore s'entraîner seuls. Il existe également des dizaines de personnes sur notre planète qui pratiquent en équipe. a considérablement réduit le coût, mais si vous souhaitez former un modèle utile, les exigences en matière d'environnement matériel sont encore trop élevées. La carte graphique est très chère. Le prix de location d'un GPU est pénible. la formation dans le cloud est encore plus incontrôlable. La formation échoue. L'argent est gaspillé en vain. Ce n'est pas comme apprendre un langage ou un framework et télécharger quelques packages d'installation.
J'espère que le seuil sera encore abaissé !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Google Pixel 9 Pro XL est testé avec le mode bureau
Aug 29, 2024 pm 01:09 PM
Google Pixel 9 Pro XL est testé avec le mode bureau
Aug 29, 2024 pm 01:09 PM
Google a introduit le mode alternatif DisplayPort avec la série Pixel 8, et il est présent sur la gamme Pixel 9 récemment lancée. Bien qu'il soit principalement là pour vous permettre de refléter l'affichage de votre smartphone avec un écran connecté, vous pouvez également l'utiliser pour un ordinateur de bureau.
 Google Tensor G4 du Pixel 9 Pro XL est en retard sur Tensor G2 en Genshin Impact
Aug 24, 2024 am 06:43 AM
Google Tensor G4 du Pixel 9 Pro XL est en retard sur Tensor G2 en Genshin Impact
Aug 24, 2024 am 06:43 AM
Google a récemment répondu aux problèmes de performances concernant le Tensor G4 de la gamme Pixel 9. La société a déclaré que le SoC n'était pas conçu pour battre les benchmarks. Au lieu de cela, l'équipe s'est concentrée sur sa performance dans les domaines où Google souhaite que le c
 Les smartphones Google Pixel 9 ne seront pas lancés avec Android 15 malgré un engagement de mise à jour de sept ans
Aug 01, 2024 pm 02:56 PM
Les smartphones Google Pixel 9 ne seront pas lancés avec Android 15 malgré un engagement de mise à jour de sept ans
Aug 01, 2024 pm 02:56 PM
La série Pixel 9 est presque là, sa sortie étant prévue pour le 13 août. D'après des rumeurs récentes, les Pixel 9, Pixel 9 Pro et Pixel 9 Pro XL refléteront les Pixel 8 et Pixel 8 Pro (749 $ sur Amazon) en commençant par 128 Go de stockage.
 Le nouveau mode de bureau Google Pixel présenté dans une nouvelle vidéo comme alternative possible à Motorola Ready For et Samsung DeX
Aug 08, 2024 pm 03:05 PM
Le nouveau mode de bureau Google Pixel présenté dans une nouvelle vidéo comme alternative possible à Motorola Ready For et Samsung DeX
Aug 08, 2024 pm 03:05 PM
Quelques mois se sont écoulés depuis qu'Android Authority a démontré un nouveau mode de bureau Android que Google avait caché dans Android 14 QPR3 Beta 2.1. Arrivant juste après Google, il ajoute la prise en charge du mode Alt DisplayPort pour les Pixel 8 et Pixel 8.
 Google ouvre AI Test Kitchen & Imagen 3 à la plupart des utilisateurs
Sep 12, 2024 pm 12:17 PM
Google ouvre AI Test Kitchen & Imagen 3 à la plupart des utilisateurs
Sep 12, 2024 pm 12:17 PM
AI Test Kitchen de Google, qui comprend une suite d'outils de conception d'IA avec lesquels les utilisateurs peuvent jouer, est désormais ouvert aux utilisateurs dans plus de 100 pays à travers le monde. Cette décision marque la première fois que de nombreuses personnes dans le monde pourront utiliser Imagen 3, Google
 Le nouveau Chromecast « TV Streamer » de Google serait lancé avec la connectivité Ethernet et Thread
Aug 01, 2024 am 10:21 AM
Le nouveau Chromecast « TV Streamer » de Google serait lancé avec la connectivité Ethernet et Thread
Aug 01, 2024 am 10:21 AM
Google est à environ quinze jours de révéler complètement le nouveau matériel. Comme d'habitude, d'innombrables sources ont divulgué des détails sur les nouveaux appareils Pixel, qu'il s'agisse des smartphones Pixel Watch 3, Pixel Buds Pro 2 ou Pixel 9. Il semble également que l'entreprise
 Google Pixel 9 Pro XL se classe 2e dans le classement « mondial » des appareils photo pour smartphone de DxOMark
Aug 23, 2024 am 06:42 AM
Google Pixel 9 Pro XL se classe 2e dans le classement « mondial » des appareils photo pour smartphone de DxOMark
Aug 23, 2024 am 06:42 AM
La nouvelle série Pixel 9 de Google a introduit une nouvelle variante qui n'était pas présente dans les gammes précédentes, le Pixel 9 Pro XL. Il est essentiellement identique à la variante non XL (précommande sur Amazon), mais comme son nom l'indique, il dispose d'un écran plus grand. Les deux e
 La comparaison des caméras Pixel 9 Pro XL et iPhone 15 Pro Max révèle des victoires surprenantes de Google en termes de performances vidéo et de zoom
Aug 24, 2024 pm 12:32 PM
La comparaison des caméras Pixel 9 Pro XL et iPhone 15 Pro Max révèle des victoires surprenantes de Google en termes de performances vidéo et de zoom
Aug 24, 2024 pm 12:32 PM
Les Google Pixel 9 Pro et Pro XL sont les réponses de Google aux Samsung Galaxy S24 Ultra et aux Apple iPhone 15 Pro et Pro Max. Daniel Sin sur YouTube (regarder ci-dessous) a comparé le Google Pixel 9 Pro XL à l'iPhone 15 Pro Max avec certains
