
 développement back-end
Tutoriel Python
Quelles sont les trois façons de stocker et d'accéder aux images Python ?
développement back-end
Tutoriel Python
Quelles sont les trois façons de stocker et d'accéder aux images Python ?
Quelles sont les trois façons de stocker et d'accéder aux images Python ?

Avant-propos
ImageNet est une base de données d'images publique bien connue utilisée pour former des modèles pour des tâches telles que la classification, la détection et la segmentation d'objets. Elle contient plus de 14 millions d'images.
Lors du traitement de données d'image en Python, par exemple, l'application d'algorithmes tels que le réseau neuronal convolutif (également appelé CNN) peut traiter un grand nombre d'ensembles de données d'image. Ici, vous devez apprendre à stocker et lire des données de la manière la plus simple.
Il devrait y avoir une manière quantitative de comparer le traitement des données d'image, le temps qu'il faudra pour lire et écrire des fichiers et la quantité de mémoire disque qui sera utilisée.
Utilisez différentes méthodes pour traiter et résoudre les problèmes de stockage d'images et d'optimisation des performances.
Préparation des données
Un ensemble de données avec lequel jouer
L'ensemble de données d'images que nous connaissons, CIFAR-10, se compose de 60 000 images couleur de 32 x 32 pixels appartenant à différentes catégories d'objets, telles que les chiens, les chats et les avions. Le CIFAR n’est pas un très grand ensemble de données relativement parlant, mais l’utilisation de l’ensemble de données TinyImages nécessiterait environ 400 Go d’espace disque libre.
L'adresse de téléchargement de l'ensemble de données utilisée par le code dans l'article est l'ensemble de données CIFAR-10.
Ces données sont sérialisées et enregistrées par lots à l'aide de cPickle. Le module pickle peut sérialiser n'importe quel objet en Python sans nécessiter de code ou de conversion supplémentaire. Cependant, le traitement de grandes quantités de données peut présenter des risques de sécurité qui ne peuvent être évalués.
Les images sont chargées dans des tableaux NumPy
import numpy as np
import pickle
from pathlib import Path
# 文件路径
data_dir = Path("data/cifar-10-batches-py/")
# 解码功能
def unpickle(file):
with open(file, "rb") as fo:
dict = pickle.load(fo, encoding="bytes")
return dict
images, labels = [], []
for batch in data_dir.glob("data_batch_*"):
batch_data = unpickle(batch)
for i, flat_im in enumerate(batch_data[b"data"]):
im_channels = []
# 每个图像都是扁平化的,通道按 R, G, B 的顺序排列
for j in range(3):
im_channels.append(
flat_im[j * 1024 : (j + 1) * 1024].reshape((32, 32))
)
# 重建原始图像
images.append(np.dstack((im_channels)))
# 保存标签
labels.append(batch_data[b"labels"][i])
print("加载 CIFAR-10 训练集:")
print(f" - np.shape(images) {np.shape(images)}")
print(f" - np.shape(labels) {np.shape(labels)}")Paramètres pour le stockage des images
Installez la bibliothèque tierce Pillow pour le traitement des images.
pip install Pillow
LMDB
"Lightning Memory Mapped Database" (LMDB) est également connue sous le nom de "Lightning Database" en raison de sa vitesse et de son utilisation de fichiers mappés en mémoire. Il s'agit d'un magasin clé-valeur, pas d'une base de données relationnelle.
Installez la bibliothèque tierce lmdb pour le traitement des images.
pip install lmdb
HDF5
HDF5 signifie Hierarchical Data Format, un format de fichier appelé HDF4 ou HDF5. Ce format de données scientifiques portable et compact provient du National Center for Supercomputing Applications.
Installez la bibliothèque tierce h6py pour le traitement des images.
pip install h6py
Stockage d'une seule image
3 façons différentes d'effectuer des opérations de lecture de données
from pathlib import Path
disk_dir = Path("data/disk/")
lmdb_dir = Path("data/lmdb/")
hdf5_dir = Path("data/hdf5/")Les données chargées en même temps peuvent être créées et enregistrées séparément dans des dossiers
disk_dir.mkdir(parents=True, exist_ok=True) lmdb_dir.mkdir(parents=True, exist_ok=True) hdf5_dir.mkdir(parents=True, exist_ok=True)
Stockées sur le disque
Utilisez Pillow pour terminer la saisie en un seul image image , en mémoire sous forme de tableau NumPy, et nommée avec l'ID d'image unique image_id.
Image unique enregistrée sur le disque
from PIL import Image
import csv
def store_single_disk(image, image_id, label):
""" 将单个图像作为 .png 文件存储在磁盘上。
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
Image.fromarray(image).save(disk_dir / f"{image_id}.png")
with open(disk_dir / f"{image_id}.csv", "wt") as csvfile:
writer = csv.writer(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
writer.writerow([label])Store sur LMDB
LMDB est un système de stockage de paires clé-valeur où chaque entrée est enregistrée sous forme de tableau d'octets, la clé sera l'identifiant unique de chaque image et la valeur sera l'image lui-même.
Les clés et les valeurs doivent être des chaînes. Une utilisation courante consiste à sérialiser la valeur dans une chaîne, puis à la désérialiser lors de sa relecture.
La taille de l'image utilisée pour la reconstruction. Certains ensembles de données peuvent contenir des images de différentes tailles et cette méthode sera utilisée.
class CIFAR_Image:
def __init__(self, image, label):
self.channels = image.shape[2]
self.size = image.shape[:2]
self.image = image.tobytes()
self.label = label
def get_image(self):
""" 将图像作为 numpy 数组返回 """
image = np.frombuffer(self.image, dtype=np.uint8)
return image.reshape(*self.size, self.channels)Image unique enregistrée dans LMDB
import lmdb
import pickle
def store_single_lmdb(image, image_id, label):
""" 将单个图像存储到 LMDB
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
map_size = image.nbytes * 10
# Create a new LMDB environment
env = lmdb.open(str(lmdb_dir / f"single_lmdb"), map_size=map_size)
# Start a new write transaction
with env.begin(write=True) as txn:
# All key-value pairs need to be strings
value = CIFAR_Image(image, label)
key = f"{image_id:08}"
txn.put(key.encode("ascii"), pickle.dumps(value))
env.close()Stockage HDF5
Un fichier HDF5 peut contenir plusieurs ensembles de données. Deux ensembles de données peuvent être créés, un pour les images et un pour les métadonnées.
import h6py
def store_single_hdf5(image, image_id, label):
""" 将单个图像存储到 HDF5 文件
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
# 创建一个新的 HDF5 文件
file = h6py.File(hdf5_dir / f"{image_id}.h6", "w")
# 在文件中创建数据集
dataset = file.create_dataset(
"image", np.shape(image), h6py.h6t.STD_U8BE, data=image
)
meta_set = file.create_dataset(
"meta", np.shape(label), h6py.h6t.STD_U8BE, data=label
)
file.close()Comparaison de stockage
Placez les trois fonctions qui enregistrent une seule image dans un dictionnaire.
_store_single_funcs = dict(
disk=store_single_disk,
lmdb=store_single_lmdb,
hdf5=store_single_hdf5
)Stockez la première image dans CIFAR et ses balises correspondantes de trois manières différentes.
from timeit import timeit
store_single_timings = dict()
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_store_single_funcs[method](image, 0, label)",
setup="image=images[0]; label=labels[0]",
number=1,
globals=globals(),
)
store_single_timings[method] = t
print(f"存储方法: {method}, 使用耗时: {t}")Jetons un coup d'œil à la comparaison.
| Méthode de stockage | Durée de stockage | Utilisation de la mémoire |
|---|---|---|
| Disque | 2,1 ms | 8 K |
| LMDB | 1,7 ms | 32K |
| HDF5 | 8,1 ms | 8 K |
Stockage de plusieurs images
Semblable à la méthode de stockage d'image unique, modifiez le code pour stocker plusieurs données d'image.
Code de réglage d'images multiples
Enregistrer plusieurs images sous forme de fichiers .png peut être considéré comme appelant la méthode store_single_method() plusieurs fois. Cette approche n'est pas possible avec LMDB ou HDF5 car chaque image existe dans un fichier de base de données différent.
Stocker un ensemble d'images sur le disque
store_many_disk(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
# 一张一张保存所有图片
for i, image in enumerate(images):
Image.fromarray(image).save(disk_dir / f"{i}.png")
# 将所有标签保存到 csv 文件
with open(disk_dir / f"{num_images}.csv", "w") as csvfile:
writer = csv.writer(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
for label in labels:
writer.writerow([label])Stocker un ensemble d'images sur LMDB
def store_many_lmdb(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
map_size = num_images * images[0].nbytes * 10
# 为所有图像创建一个新的 LMDB 数据库
env = lmdb.open(str(lmdb_dir / f"{num_images}_lmdb"), map_size=map_size)
# 在一个事务中写入所有图像
with env.begin(write=True) as txn:
for i in range(num_images):
# 所有键值对都必须是字符串
value = CIFAR_Image(images[i], labels[i])
key = f"{i:08}"
txn.put(key.encode("ascii"), pickle.dumps(value))
env.close()Stocker un ensemble d'images sur HDF5
def store_many_hdf5(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
# 创建一个新的 HDF5 文件
file = h6py.File(hdf5_dir / f"{num_images}_many.h6", "w")
# 在文件中创建数据集
dataset = file.create_dataset(
"images", np.shape(images), h6py.h6t.STD_U8BE, data=images
)
meta_set = file.create_dataset(
"meta", np.shape(labels), h6py.h6t.STD_U8BE, data=labels
)
file.close()Préparer la comparaison des ensembles de données
Utiliser 100 000 images pour les tests
cutoffs = [10, 100, 1000, 10000, 100000] images = np.concatenate((images, images), axis=0) labels = np.concatenate((labels, labels), axis=0) # 确保有 100,000 个图像和标签 print(np.shape(images)) print(np.shape(labels))
Créer un calcul pour la comparaison
_store_many_funcs = dict(
disk=store_many_disk, lmdb=store_many_lmdb, hdf5=store_many_hdf5
)
from timeit import timeit
store_many_timings = {"disk": [], "lmdb": [], "hdf5": []}
for cutoff in cutoffs:
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_store_many_funcs[method](images_, labels_)",
setup="images_=images[:cutoff]; labels_=labels[:cutoff]",
number=1,
globals=globals(),
)
store_many_timings[method].append(t)
# 打印出方法、截止时间和使用时间
print(f"Method: {method}, Time usage: {t}")PLOT Afficher un seul tracé avec plusieurs ensembles de données et légendes correspondantes
import matplotlib.pyplot as plt
def plot_with_legend(
x_range, y_data, legend_labels, x_label, y_label, title, log=False
):
""" 参数:
--------------
x_range 包含 x 数据的列表
y_data 包含 y 值的列表
legend_labels 字符串图例标签列表
x_label x 轴标签
y_label y 轴标签
"""
plt.style.use("seaborn-whitegrid")
plt.figure(figsize=(10, 7))
if len(y_data) != len(legend_labels):
raise TypeError(
"数据集的数量与标签的数量不匹配"
)
all_plots = []
for data, label in zip(y_data, legend_labels):
if log:
temp, = plt.loglog(x_range, data, label=label)
else:
temp, = plt.plot(x_range, data, label=label)
all_plots.append(temp)
plt.title(title)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.legend(handles=all_plots)
plt.show()
# Getting the store timings data to display
disk_x = store_many_timings["disk"]
lmdb_x = store_many_timings["lmdb"]
hdf5_x = store_many_timings["hdf5"]
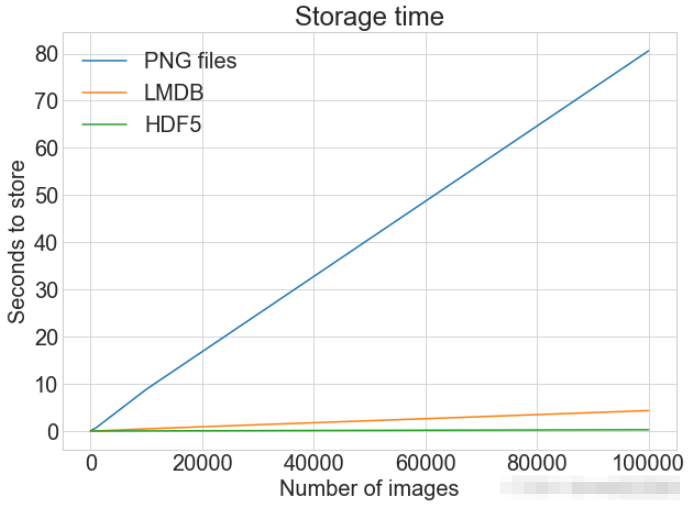
plot_with_legend(
cutoffs,
[disk_x, lmdb_x, hdf5_x],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to store",
"Storage time",
log=False,
)
plot_with_legend(
cutoffs,
[disk_x, lmdb_x, hdf5_x],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to store",
"Log storage time",
log=True,
)
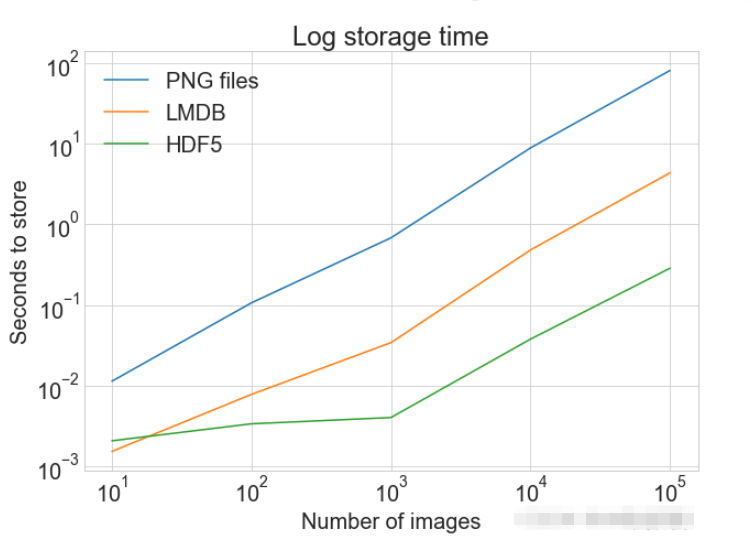
Lecture d'une seule image
Lecture à partir du disque
def read_single_disk(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
image = np.array(Image.open(disk_dir / f"{image_id}.png"))
with open(disk_dir / f"{image_id}.csv", "r") as csvfile:
reader = csv.reader(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
label = int(next(reader)[0])
return image, labelLecture à partir de LMDB
def read_single_lmdb(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
# 打开 LMDB 环境
env = lmdb.open(str(lmdb_dir / f"single_lmdb"), readonly=True)
# 开始一个新的事务
with env.begin() as txn:
# 进行编码
data = txn.get(f"{image_id:08}".encode("ascii"))
# 加载的 CIFAR_Image 对象
cifar_image = pickle.loads(data)
# 检索相关位
image = cifar_image.get_image()
label = cifar_image.label
env.close()
return image, labelLecture à partir de HDF5
def read_single_hdf5(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
# 打开 HDF5 文件
file = h6py.File(hdf5_dir / f"{image_id}.h6", "r+")
image = np.array(file["/image"]).astype("uint8")
label = int(np.array(file["/meta"]).astype("uint8"))
return image, labelMéthode de lecture comparaison
from timeit import timeit
read_single_timings = dict()
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_read_single_funcs[method](0)",
setup="image=images[0]; label=labels[0]",
number=1,
globals=globals(),
)
read_single_timings[method] = t
print(f"读取方法: {method}, 使用耗时: {t}")| Méthode de stockage | Durée de stockage |
|---|---|
| Disque | 1,7 ms |
| LMDB | 4,4 ms |
| HDF5 | 2,3 ms |
多个图像的读取
可以将多个图像保存为.png文件,这等价于多次调用 read_single_method()。这并不适用于 LMDB 或 HDF5,因为每个图像都储存在不同的数据库文件中。
多图像调整代码
从磁盘中读取多个都图像
def read_many_disk(num_images):
""" 参数:
---------------
num_images 要读取的图像数量
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
images, labels = [], []
# 循环遍历所有ID,一张一张地读取每张图片
for image_id in range(num_images):
images.append(np.array(Image.open(disk_dir / f"{image_id}.png")))
with open(disk_dir / f"{num_images}.csv", "r") as csvfile:
reader = csv.reader(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
for row in reader:
labels.append(int(row[0]))
return images, labels从LMDB中读取多个都图像
def read_many_lmdb(num_images):
""" 参数:
---------------
num_images 要读取的图像数量
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
images, labels = [], []
env = lmdb.open(str(lmdb_dir / f"{num_images}_lmdb"), readonly=True)
# 开始一个新的事务
with env.begin() as txn:
# 在一个事务中读取,也可以拆分成多个事务分别读取
for image_id in range(num_images):
data = txn.get(f"{image_id:08}".encode("ascii"))
# CIFAR_Image 对象,作为值存储
cifar_image = pickle.loads(data)
# 检索相关位
images.append(cifar_image.get_image())
labels.append(cifar_image.label)
env.close()
return images, labels从HDF5中读取多个都图像
def read_many_hdf5(num_images):
""" 参数:
---------------
num_images 要读取的图像数量
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
images, labels = [], []
# 打开 HDF5 文件
file = h6py.File(hdf5_dir / f"{num_images}_many.h6", "r+")
images = np.array(file["/images"]).astype("uint8")
labels = np.array(file["/meta"]).astype("uint8")
return images, labels
_read_many_funcs = dict(
disk=read_many_disk, lmdb=read_many_lmdb, hdf5=read_many_hdf5
)准备数据集对比
创建一个计算方式进行对比
from timeit import timeit
read_many_timings = {"disk": [], "lmdb": [], "hdf5": []}
for cutoff in cutoffs:
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_read_many_funcs[method](num_images)",
setup="num_images=cutoff",
number=1,
globals=globals(),
)
read_many_timings[method].append(t)
# Print out the method, cutoff, and elapsed time
print(f"读取方法: {method}, No. images: {cutoff}, 耗时: {t}")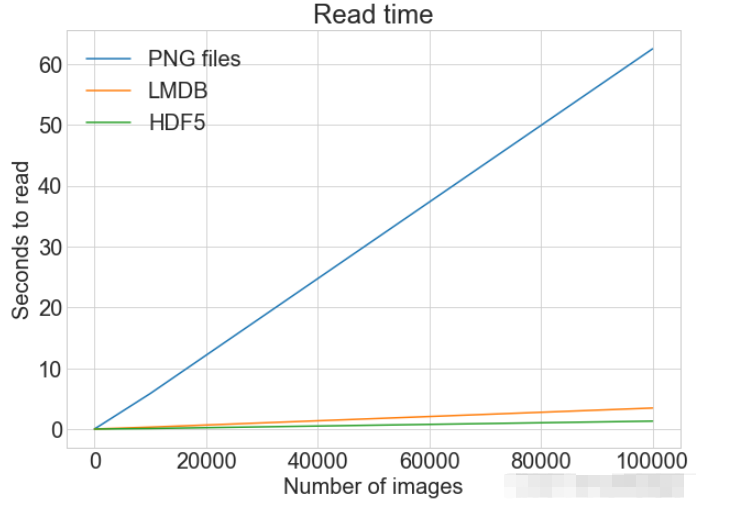
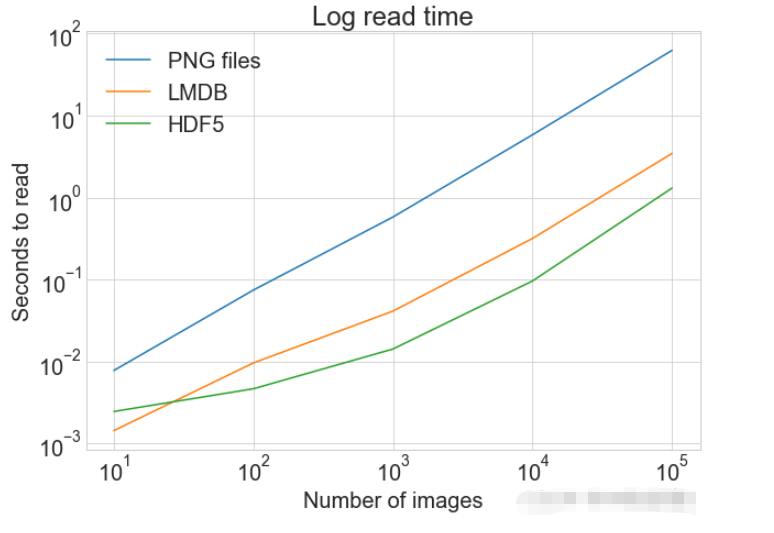
读写操作综合比较
数据对比
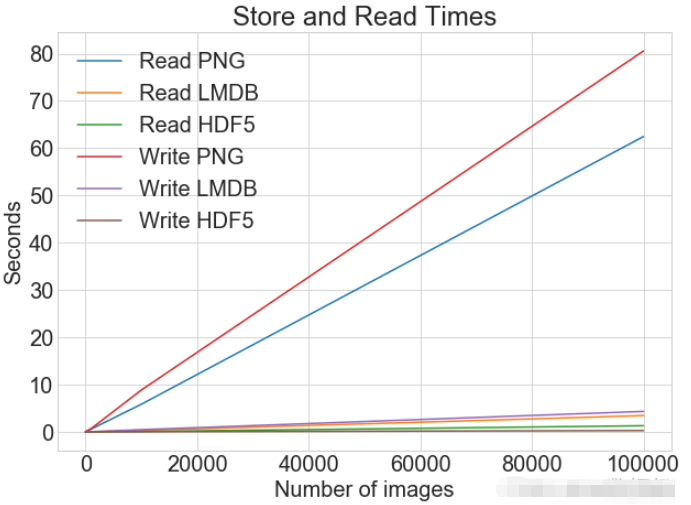
同一张图表上查看读取和写入时间
plot_with_legend(
cutoffs,
[disk_x_r, lmdb_x_r, hdf5_x_r, disk_x, lmdb_x, hdf5_x],
[
"Read PNG",
"Read LMDB",
"Read HDF5",
"Write PNG",
"Write LMDB",
"Write HDF5",
],
"Number of images",
"Seconds",
"Log Store and Read Times",
log=False,
)
各种存储方式使用磁盘空间
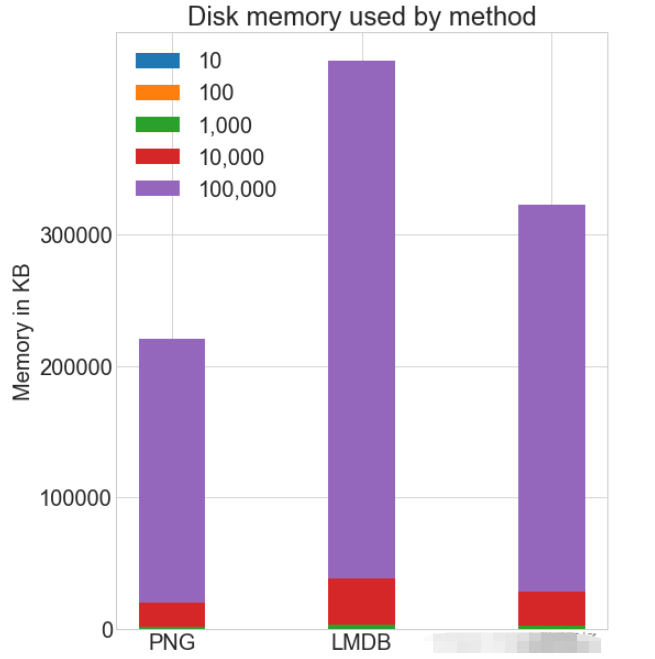
虽然 HDF5 和 LMDB 都占用更多的磁盘空间。需要注意的是 LMDB 和 HDF5 磁盘的使用和性能在很大程度上取决于各种因素,包括操作系统,更重要的是存储的数据大小。
并行操作
通常对于大的数据集,可以通过并行化来加速操作。 也就是我们经常说的并发处理。
作为.png 文件存储到磁盘实际上允许完全并发。可通过使用不同的图像名称,实现从多个线程读取多个图像,或一次性写入多个文件。
如果将所有 CIFAR 分成十组,那么可以为一组中的每个读取设置十个进程,并且相应的处理时间可以减少到原来的10%左右。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Dans VS Code, vous pouvez exécuter le programme dans le terminal via les étapes suivantes: Préparez le code et ouvrez le terminal intégré pour vous assurer que le répertoire de code est cohérent avec le répertoire de travail du terminal. Sélectionnez la commande Run en fonction du langage de programmation (tel que Python de Python your_file_name.py) pour vérifier s'il s'exécute avec succès et résoudre les erreurs. Utilisez le débogueur pour améliorer l'efficacité du débogage.
 Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
VS Code peut être utilisé pour écrire Python et fournit de nombreuses fonctionnalités qui en font un outil idéal pour développer des applications Python. Il permet aux utilisateurs de: installer des extensions Python pour obtenir des fonctions telles que la réalisation du code, la mise en évidence de la syntaxe et le débogage. Utilisez le débogueur pour suivre le code étape par étape, trouver et corriger les erreurs. Intégrez Git pour le contrôle de version. Utilisez des outils de mise en forme de code pour maintenir la cohérence du code. Utilisez l'outil de liaison pour repérer les problèmes potentiels à l'avance.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
Les extensions de code vs posent des risques malveillants, tels que la cachette de code malveillant, l'exploitation des vulnérabilités et la masturbation comme des extensions légitimes. Les méthodes pour identifier les extensions malveillantes comprennent: la vérification des éditeurs, la lecture des commentaires, la vérification du code et l'installation avec prudence. Les mesures de sécurité comprennent également: la sensibilisation à la sécurité, les bonnes habitudes, les mises à jour régulières et les logiciels antivirus.
 Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code peut fonctionner sur Windows 8, mais l'expérience peut ne pas être excellente. Assurez-vous d'abord que le système a été mis à jour sur le dernier correctif, puis téléchargez le package d'installation VS Code qui correspond à l'architecture du système et l'installez comme invité. Après l'installation, sachez que certaines extensions peuvent être incompatibles avec Windows 8 et doivent rechercher des extensions alternatives ou utiliser de nouveaux systèmes Windows dans une machine virtuelle. Installez les extensions nécessaires pour vérifier si elles fonctionnent correctement. Bien que le code VS soit possible sur Windows 8, il est recommandé de passer à un système Windows plus récent pour une meilleure expérience de développement et une meilleure sécurité.
 Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python excelle dans l'automatisation, les scripts et la gestion des tâches. 1) Automatisation: La sauvegarde du fichier est réalisée via des bibliothèques standard telles que le système d'exploitation et la fermeture. 2) Écriture de script: utilisez la bibliothèque PSUTIL pour surveiller les ressources système. 3) Gestion des tâches: utilisez la bibliothèque de planification pour planifier les tâches. La facilité d'utilisation de Python et la prise en charge de la bibliothèque riche en font l'outil préféré dans ces domaines.
