
 Périphériques technologiques
IA
Google panique ! Si vous souhaitez publier un article, vous devez obtenir l'approbation et donner la priorité au développement de produits : ChatGPT est-il un chant du cygne dans le domaine de l'intelligence artificielle ?
Périphériques technologiques
IA
Google panique ! Si vous souhaitez publier un article, vous devez obtenir l'approbation et donner la priorité au développement de produits : ChatGPT est-il un chant du cygne dans le domaine de l'intelligence artificielle ?
Google panique ! Si vous souhaitez publier un article, vous devez obtenir l'approbation et donner la priorité au développement de produits : ChatGPT est-il un chant du cygne dans le domaine de l'intelligence artificielle ?

Le développement rapide de l'IA au cours des dix dernières années a bénéficié de la coopération des universités, des entreprises et des développeurs individuels, ce qui a fait que le domaine de l'intelligence artificielle regorge de codes open source, de données et de tutoriels.
Google a toujours été un leader dans l'industrie de l'IA. Il a publié des articles dans de nombreux domaines tels que le traitement du langage naturel, la vision par ordinateur et l'apprentissage par renforcement. Il a contribué à l'industrie de nombreux modèles et modèles de base. comme Transformer, Bert, PaLM, etc. Architecture .
Mais OpenAI a brisé les règles du jeu. Non seulement il a développé ChatGPT avec Transformer, mais il s'est également appuyé sur les avantages d'une start-up, comme être moins affecté par la loi et l'opinion publique , pas besoin de divulguer les données de formation, la taille du modèle, l'architecture et d'autres informations, et même débauché de nombreux employés de grandes entreprises telles que Google, faisant perdre du terrain à Google.
Face à OpenAI, qui n'a aucune éthique martiale, Google ne peut être battu que passivement.
Selon des informations fournies par des sources anonymes, en février de cette année, Jeff Dean, responsable de l'IA de Google, a déclaré lors d'une réunion :
Google profiterait de ses propres découvertes en matière d'IA, en partageant des articles seulement après le travail en laboratoire. ont été transformés en produits
Google utilisera ses propres réalisations en matière d'intelligence artificielle et ne partagera les articles qu'une fois que les résultats du laboratoire auront été transformés en produits.
Google, qui s'est transformé en un « État défensif », espère peut-être se débarrasser de toutes les sociétés d'IA similaires et mieux protéger son activité principale de recherche et le cours de ses actions.
Mais si l'IA n'a pas l'esprit open source de ces grandes entreprises et se tourne vers le monopole, les miracles de développement précédents dans le domaine de l'intelligence artificielle se produiront-ils encore ?
Google a été volé parce qu'il était "trop responsable"Pour une entreprise comme Google avec des milliards d'utilisateurs, même une expérience à petite échelle peut affecter des millions de personnes et subir des réactions négatives de l'opinion publique, c'est pourquoi Google a été réticent lancer des chatbots et s’en tenir à l’objectif d’une « IA responsable ».
En 2015, Google Photos a lancé une fonction de classification d'images et a classé à tort un homme noir comme Gorilles. Google est immédiatement tombé dans une crise de relations publiques et s'est rapidement excusé et a apporté des corrections.
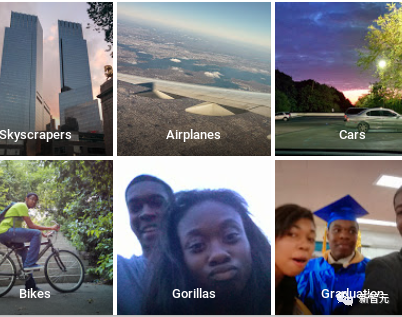
La mesure de rectification de Google consiste à supprimer directement la balise Gorillas, et même à supprimer des catégories telles que caniche, chimpanzé et singe.
Le résultat est que le classificateur d'images ne reconnaît plus les personnes noires comme des orangs-outans, mais il ne peut pas non plus reconnaître les vrais orangs-outans.
Bien que Google investisse beaucoup d'argent dans le développement de la technologie d'intelligence artificielle depuis de nombreuses années, en raison de l'ininterprétabilité des réseaux neuronaux dans la boîte noire, Google ne peut pas garantir pleinement la contrôlabilité après la production et nécessite une période de test de sécurité plus longue. , l’avantage du premier arrivé est perdu.
En avril de cette année, le PDG de Google, Sundar Pichai, a encore clairement indiqué lors de l'émission « 60 Minutes » que les gens doivent être prudents à l'égard de l'intelligence artificielle. Elle peut causer de graves dommages à la société, comme les images et vidéos falsifiées, etc.
Si Google choisit d'être « moins responsable », cela attirera inévitablement l'attention d'un plus grand nombre d'agences de réglementation, de chercheurs en intelligence artificielle et de chefs d'entreprise.
Mais le co-fondateur de DeepMind, Mustafa Suleyman, a déclaré que ce n'est pas parce qu'ils sont trop prudents, mais parce qu'ils ne veulent pas perturber les sources de revenus et les modèles commerciaux existants. Ils ne commenceront qu'en cas de véritable menace extérieure.
Et cette menace est déjà venue.
Le temps presse pour GoogleDepuis 2010, Google a commencé à acquérir des start-ups d'intelligence artificielle et à intégrer progressivement les technologies associées dans ses propres produits.
En 2013, Google a invité Hinton, pionnier du deep learning et lauréat du prix Turing, à se joindre à nous (qui venait de démissionner) un an plus tard, Google a également acquis la startup DeepMind pour 625 millions de dollars américains
Après sa nomination ; en tant que PDG de Google Peu de temps après l'annonce officielle, Pichai a annoncé que Google adopterait « l'IA d'abord » comme stratégie de base et intégrerait la technologie de l'intelligence artificielle dans tous ses produits.
Des années de travail intensif ont également permis à l'équipe de recherche en intelligence artificielle de Google de réaliser de nombreuses percées, mais en même temps, certaines startups plus petites ont également réalisé des progrès dans le domaine de l'intelligence artificielle.
OpenAI a été créée à l'origine pour contrebalancer le monopole des grandes entreprises technologiques sur l'acquisition d'entreprises dans le domaine de l'intelligence artificielle. Avec les avantages des petites entreprises, OpenAI est soumise à moins de contrôle et de supervision, et est plus disposée à le faire rapidement. livrer des modèles d’intelligence artificielle entre les mains des utilisateurs ordinaires.
La course aux armements en matière d'intelligence artificielle s'intensifie donc sans encadrement. Face à la concurrence, la « responsabilité » des grandes entreprises pourrait progressivement s'affaiblir.
Les dirigeants de Google doivent également choisir les perspectives des concepts généraux d'intelligence artificielle tels que la « correspondance technologique de l'intelligence artificielle » et « l'intelligence surhumaine » soutenus par DeepMind.
Le 21 avril de cette année, Pichai a annoncé la fusion de Google Brain, initialement dirigé par Jeff Dean, et de DeepMind, précédemment acquis, et l'a confié à Demis Hassabis, co-fondateur et PDG de DeepMind, pour accélérer le développement de Google dans le domaine de l’intelligence artificielle.
Hassabis estime que d’ici quelques années, le niveau de l’intelligence artificielle pourrait être plus proche du niveau de l’intelligence humaine que ne le prédisent la plupart des experts.
Google est entré en « état de préparation à la guerre »
Selon des entretiens menés par des médias étrangers avec 11 employés actuels et anciens de Google, ces derniers mois, Google a mené une réforme globale de son activité d'intelligence artificielle, avec pour objectif principal de lancer rapidement des produits. Réduire les obstacles au déploiement d’outils d’IA expérimentaux auprès de petites bases d’utilisateurs et développer un nouvel ensemble de mesures et de priorités d’évaluation dans des domaines tels que l’équité.
Frère Pichai a souligné que la tentative de Google d’accélérer la recherche et le développement ne signifie pas rogner sur les raccourcis.
Nous mettons en place un nouveau département visant à construire des systèmes plus performants, plus sûrs et plus responsables pour assurer le développement responsable de l'intelligence artificielle générale.
L'ancien chercheur en intelligence artificielle de Google Brain, Brian Kihoon Lee, a été licencié lors d'une vague de licenciements massifs en janvier de cette année. Il a décrit ce changement comme la transition de Google du « temps de paix » au « temps de guerre » une fois que la concurrence deviendra féroce. changement. En temps de guerre, les gains de parts de marché des concurrents sont également essentiels.
Le porte-parole de Google, Brian Gabriel, a déclaré : En 2018, Google a établi une structure de gestion interne et un processus d'examen complet, et a jusqu'à présent mené des centaines d'examens dans divers domaines de produits. Google continuera d'appliquer ce processus à l'ensemble des technologies basées sur l'IA, et garantir que l'IA qu'ils développent de manière responsable reste une priorité absolue pour l'entreprise.
Cependant, l'évolution des normes permettant de déterminer quand les produits d'intelligence artificielle sont prêts à être commercialisés a également provoqué un malaise parmi les employés. Par exemple, après que Google a décidé de publier Bard, il a abaissé les normes de résultats aux tests pour les produits expérimentaux d'intelligence artificielle, ce qui a provoqué. tensions internes. Objections des employés.
Début 2023, Google a annoncé une vingtaine de politiques établies par deux équipes d'intelligence artificielle (Innovation responsable et IA responsable) autour de Bard. Les employés pensaient généralement que ces réglementations étaient assez claires et complètes.
Certains employés pensent que ces normes s'apparentent davantage à une performance pour le monde extérieur. Il est préférable de rendre publics les données de formation ou les modèles open source afin que les utilisateurs puissent avoir une meilleure compréhension des capacités des modèles.
La publication d'articles nécessite une approbation
La décision de Google d'accélérer la recherche et le développement est une bénédiction mitigée pour les employés.
La bonne nouvelle est que les employés occupant des postes de recherche non scientifiques sont généralement optimistes et estiment que cette décision peut aider Google à reprendre le dessus.
Mais pour les chercheurs, la nécessité d'obtenir des approbations supplémentaires avant de publier des résultats de recherche pertinents sur l'intelligence artificielle peut signifier que les chercheurs passeront à côté de premières opportunités dans le domaine en développement rapide de l'intelligence artificielle générative.
On craint également que Google puisse supprimer discrètement des articles controversés, comme une étude de 2020 sur les dangers des grands modèles de langage, dirigée par l'équipe Ethical AI de Google et co-écrite par Timnit Gebru et Margaret Mitchell.
De nombreux chercheurs de haut niveau en intelligence artificielle ont été débauchés par des startups au cours de l’année écoulée, en partie à cause de l’inattention de Google et de l’examen excessif des résultats des chercheurs scientifiques.
Faire approuver un article peut nécessiter des itérations rigoureuses de la part de chercheurs expérimentés, explique un ancien chercheur de Google. Google a engagé de nombreux chercheurs afin qu'ils puissent continuer à participer à des sujets de recherche plus larges dans le domaine, et les restrictions de publication pourraient forcer un autre groupe de chercheurs à partir.
Faut-il ralentir la R&D en IA ?
Alors que Google accélère son développement, certaines voix ne semblent pas si harmonieuses. Elles appellent les principaux fabricants d'intelligence artificielle à ralentir la vitesse de développement et estiment que la vitesse de développement de cette technologie a dépassé les attentes du secteur. inventeur.
Geoffrey Hinton, un pionnier de l'apprentissage profond, a quitté Google en raison d'inquiétudes quant au danger potentiel d'une IA superintelligente qui pourrait échapper au contrôle humain.
Les consommateurs commencent progressivement à comprendre les risques et les limites des grands modèles de langage, tels que la tendance de l'intelligence artificielle à fabriquer des faits, etc. Cependant, la clause de non-responsabilité en petits caractères sur ChatGPT n'énonce pas clairement ses limites.
Les applications en aval basées sur ChatGPT ont révélé davantage de problèmes. Par exemple, le professeur de l'Université de Stanford, Percy Liang, a mené une étude et a découvert que seulement 70 % des références fournies par New Bing sont correctes.
Le 4 mai, la Maison Blanche a invité les PDG de Google, OpenAI et Microsoft à se rencontrer pour discuter des préoccupations du public concernant la technologie de l'IA et la manière de réglementer l'IA.
Le président américain Biden a clairement indiqué dans la lettre d'invitation que les entreprises d'IA doivent garantir la sécurité de leurs produits avant de pouvoir les ouvrir au public.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
