

Recherche binaire est un algorithme de recherche permettant de trouver un élément spécifique dans un tableau ordonné. Le processus de recherche commence à partir de l'élément du milieu du tableau, et si l'élément du milieu s'avère être l'élément à trouver, le processus de recherche se termine si un élément spécifique est supérieur ou inférieur à l'élément du milieu, la recherche est effectuée dans ; la moitié du tableau qui est supérieure ou inférieure à l'élément du milieu, et tout comme au début, démarrez la comparaison à partir de l'élément du milieu. Si le tableau est vide à une certaine étape, cela signifie qu'il est introuvable. Cet algorithme de recherche réduit la plage de recherche de moitié à chaque comparaison.
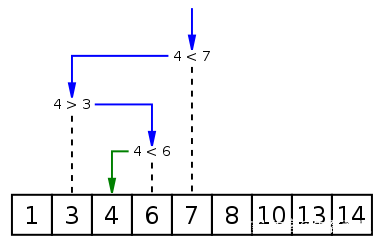
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
Résultat de l'exécution :
Veuillez saisir l'élément : 4
L'index de l'élément dans le tableau est 2
Veuillez saisir l'élément : 5
L'élément n'est pas dans le tableau
Recherche linéaire : fait référence à la vérification de chaque élément du tableau dans un certain ordre jusqu'à ce que la valeur spécifique que vous recherchez soit trouvée.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
Résultats d'exécution :
Veuillez saisir l'élément que vous recherchez : A
L'index de l'élément dans le tableau est 0
Veuillez saisir l'élément que vous recherchez : a
L'élément est pas dans le tableau
Tri par insertion : C'est un algorithme de tri simple et intuitif. Il fonctionne en construisant une séquence ordonnée pour les données non triées, il parcourt la séquence triée d'avant en arrière, trouve la position correspondante et l'insère.
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
Résultat d'exécution :
tableau trié :
[5, 6, 7, 9, 9, 11, 12, 13, 17]
Bien sûr, cela peut aussi être écrit comme ceci, ce qui est plus concis
1 2 3 4 5 6 |
|
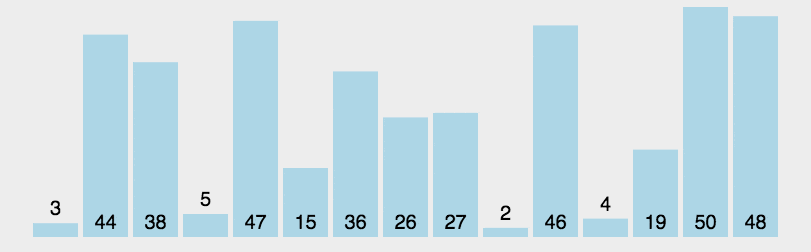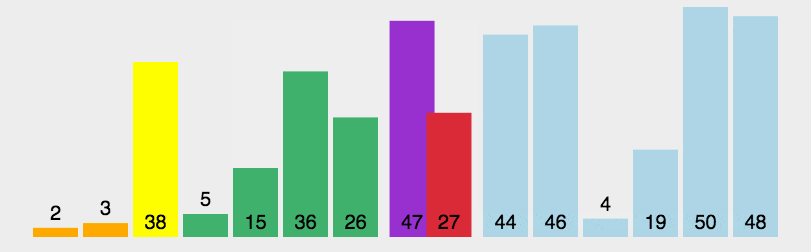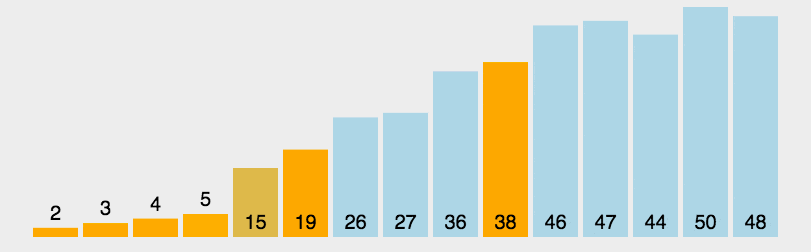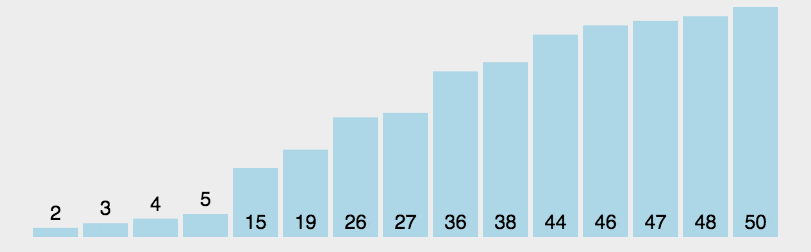
Tri rapide ;Utilisez la stratégie diviser pour régner pour diviser une séquence (liste) en deux sous-séquences, une plus petite et une plus grande, puis trier les deux sous-séquences de manière récursive.
Les étapes sont les suivantes :
Choisissez la valeur pivot : Sélectionnez un élément de la séquence, appelé "pivot" (pivot)
Split : Réorganisez la séquence pour que tout les valeurs sont inférieures à la valeur pivot. Les petits éléments sont placés devant le pivot, et tous les éléments plus grands que la valeur pivot sont placés derrière le pivot (les nombres égaux à la valeur pivot peuvent aller de chaque côté). Une fois cette division terminée, le tri de la valeur de référence est terminé ;
Trier récursivement les sous-séquences : Trier récursivement les sous-séquences d'éléments plus petites que la valeur de référence et les sous-séquences d'éléments supérieures à la valeur de référence.
La condition de jugement pour récurer vers le bas est que la taille de la séquence est zéro ou un. À ce moment, la séquence est évidemment en ordre.
Il existe plusieurs méthodes spécifiques de sélection de la valeur de référence. Cette méthode de sélection a un impact déterminant sur les performances temporelles du tri.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
Résultats en cours:
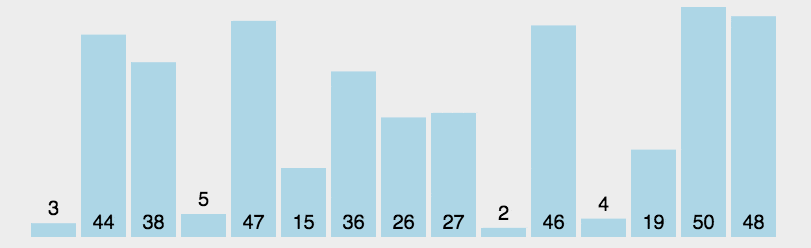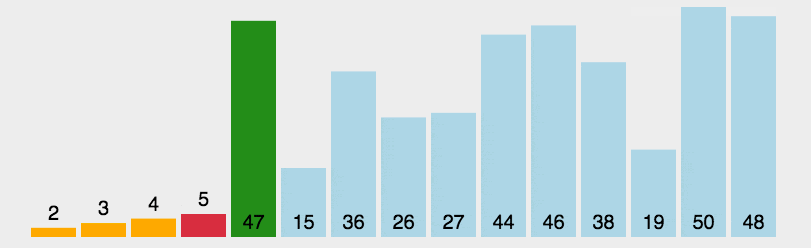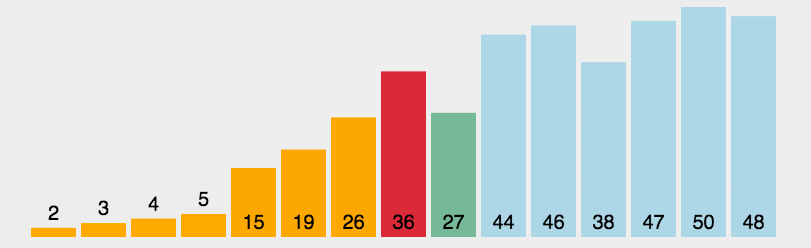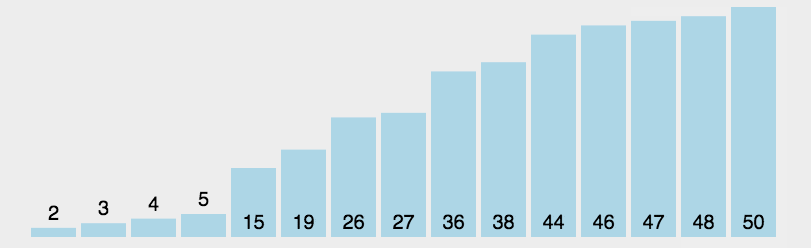
Red Sorted Tableau: [1, 5, 7, 8, 9, 10] . Voici comment cela fonctionne.
Trouvez d'abord le plus petit (grand) élément de la séquence non triée et stockez-le au début de la séquence triée. Ensuite, continuez à trouver le plus petit (grand) élément parmi les éléments non triés restants et placez-le à la fin de la séquence triée. séquence. Et ainsi de suite jusqu'à ce que tous les éléments soient triés.
1
2
3
4
5
6
7
8
9
10
11
A = [64, 25, 12, 22, 11]
fori in range(len(A)):
min_idx = i
forj in range(i+1, len(A)):
ifA[min_idx] > A[j]:
min_idx = j
A[i], A[min_idx] = A[min_idx], A[i]
("排序后的数组:")
(A)Copier après la connexion
tableau trié :
[11, 12, 22, 25, 64]
Tri à bulles :
Également un outil simple et intuitif algorithme de tri. Il parcourt à plusieurs reprises la séquence à trier, en comparant deux éléments à la fois et en les échangeant s'ils sont dans le mauvais ordre. Le travail de visite du tableau est répété jusqu'à ce qu'aucun échange ne soit plus nécessaire, ce qui signifie que le tableau a été trié. Le nom de cet algorithme vient du fait que les éléments plus petits « flotteront » lentement vers le haut du tableau grâce à l’échange.
🎜🎜Résultat de l'exécution : 🎜 🎜🎜🎜tableau trié :🎜[11, 12, 22, 25, 34, 64, 90]🎜
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def bubbleSort(arr):
n = len(arr)
# 遍历所有数组元素
fori in range(n):
# Last i elements are already in place
forj in range(0, n-i-1):
ifarr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
returnarr
arr = [64, 34, 25, 12, 22, 11, 90]
("排序后的数组:")
(bubbleSort(arr))Copier après la connexion
归并排序(Merge sort,或mergesort):,是创建在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
分治法:
分割:递归地把当前序列平均分割成两半。
集成:在保持元素顺序的同时将上一步得到的子序列集成到一起(归并)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
|
运行结果:
给定的数组
[12, 11, 13, 5, 6, 7, 13]
排序后的数组
[5, 6, 7, 11, 12, 13, 13]
堆排序(Heapsort):是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序可以说是一种利用堆的概念来排序的选择排序。

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
运行结果:
排序后的数组
[5, 6, 7, 12, 11, 13, 13, 18]
计数排序:的核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
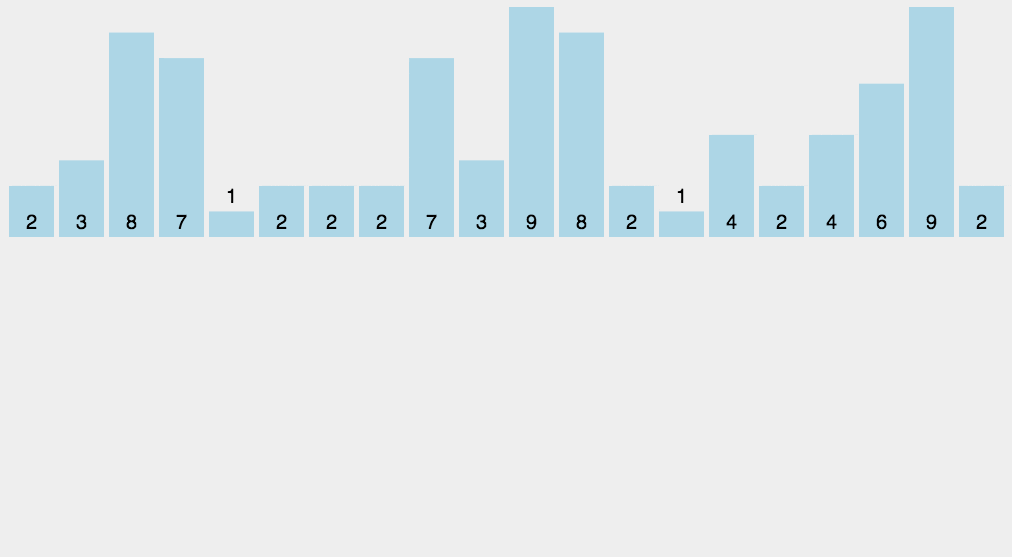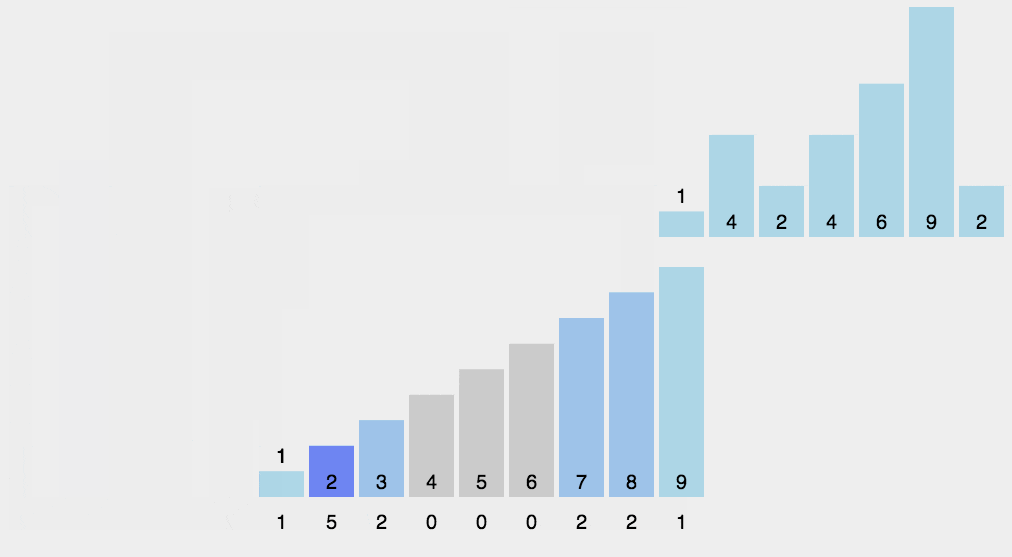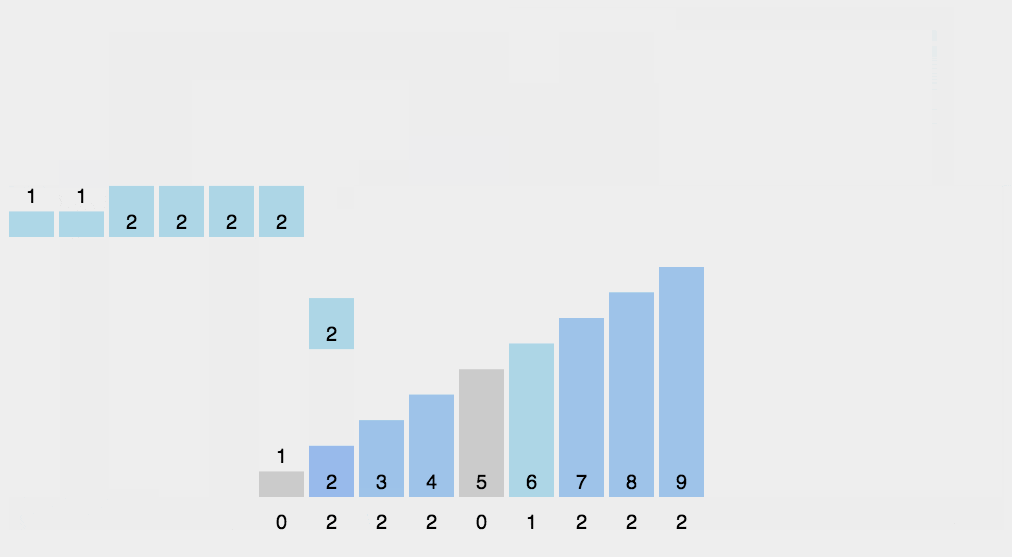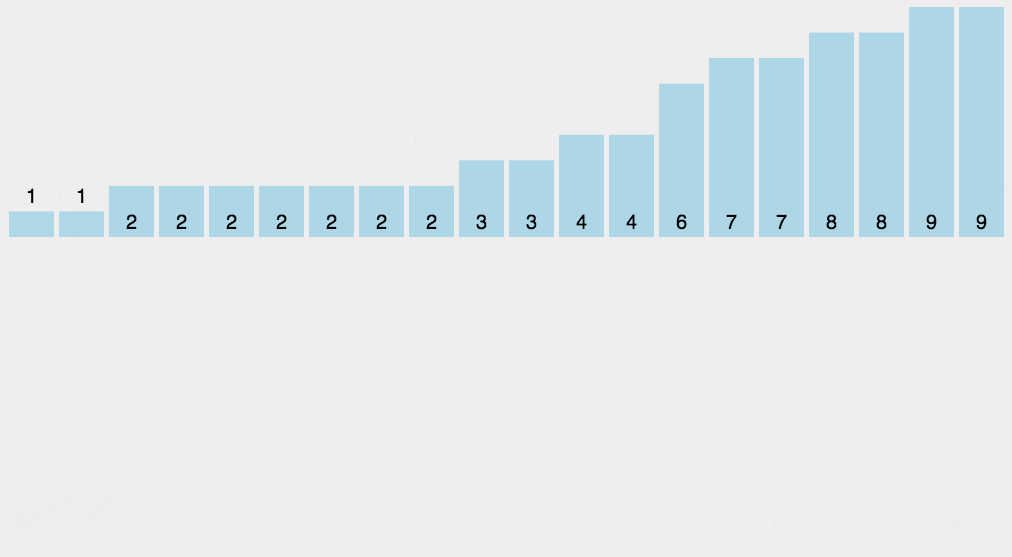
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
运行结果:
字符数组排序 ccdemnooorwwww
希尔排序:也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
运行结果:
排序前:
[12, 34, 54, 2, 3, 2, 5]
排序后:
[2, 2, 3, 5, 12, 34, 54]
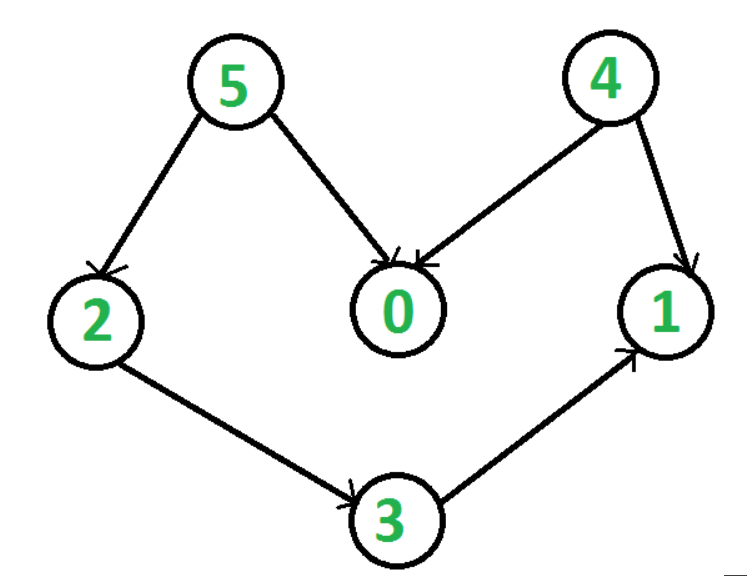
对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边(u,v)∈E(G),则u在线性序列中出现在v之前。通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称拓扑序列。拓扑排序是一种将集合上的偏序转换为全序的操作。
在图论中,由一个有向无环图的顶点组成的序列,当且仅当满足下列条件时,称为该图的一个拓扑排序(英语:Topological sorting):
每个顶点出现且只出现一次;若A在序列中排在B的前面,则在图中不存在从B到A的路径。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
|
运行结果:
拓扑排序结果:
[5, 4, 2, 3, 1, 0]
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



