
 Périphériques technologiques
IA
La grande revue de modèles est là ! Un article vous aidera à clarifier l'histoire de l'évolution des grands modèles des géants mondiaux de l'IA
Périphériques technologiques
IA
La grande revue de modèles est là ! Un article vous aidera à clarifier l'histoire de l'évolution des grands modèles des géants mondiaux de l'IA
La grande revue de modèles est là ! Un article vous aidera à clarifier l'histoire de l'évolution des grands modèles des géants mondiaux de l'IA

Xi Xiaoyao Science and Technology Talk Original
Auteur | Xiaoxi, Python
Si vous êtes novice en matière de grands modèles, que penserez-vous lorsque vous verrez pour la première fois l'étrange combinaison de ces mots GPT, PaLm et LLaMA ? Si je vais plus loin et que je vois des mots étranges comme BERT, BART, RoBERTa et ELMo apparaître les uns après les autres, je me demande si, en tant que novice, je vais devenir fou ?
Même un vétéran qui fait partie du petit cercle de la PNL depuis longtemps, avec la vitesse de développement explosive des grands modèles, peut être confus et incapable de suivre le développement rapide de nouveaux et rapides grands modèles. . À ce stade, vous devrez peut-être demander un examen de grand modèle pour vous aider ! Cette revue à grande échelle « Exploiter la puissance des LLM en pratique : une enquête sur ChatGPT et au-delà » lancée par des chercheurs d'Amazon, de la Texas A&M University et de la Rice University nous fournit un moyen de construire un « arbre généalogique ». passé, présent et futur des grands modèles représentés par ChatGPT, et sur la base des tâches, il a construit un guide pratique très complet pour les grands modèles, nous a présenté les avantages et les inconvénients des grands modèles dans différentes tâches, et a enfin souligné l'actuel risques et défis du modèle.
Titre de l'article :
Exploiter la puissance des LLM en pratique : une enquête sur ChatGPT et au-delà
Lien de l'article : https://www.php.cn/link/f50fb34f27bd263e6be8ffcf8967ced0
Page d'accueil du projet : https:// www.php.cn/link/968b15768f3d19770471e9436d97913c
Arbre généalogique - la vie passée et présente des grands modèles
La recherche de la "source de tout mal" des grands modèles devrait probablement commencer par l'article "L'attention est tout ce dont vous avez besoin ", basé sur cet article À partir de Transformer, un modèle de traduction automatique composé de plusieurs groupes d'Encoder et de Decoder proposé par l'équipe Google Machine Translation, le développement de grands modèles a généralement suivi deux voies. L'une consiste à abandonner la partie Décodeur et utilisez uniquement l'Encoder comme modèle de pré-formation pour l'encodeur , dont le représentant le plus célèbre est la famille Bert. Ces modèles ont commencé à essayer la méthode de « pré-formation non supervisée » pour mieux utiliser les données de langage naturel à grande échelle qui sont plus faciles à obtenir que d'autres données, et la méthode « non supervisée » est le modèle de langage masqué (MLM), via Let Mask Remove. quelques mots dans la phrase et laissez le modèle apprendre la capacité d'utiliser le contexte pour prédire les mots supprimés par Mask. Lorsque Bert est sorti, il était considéré comme une bombe dans le domaine de la PNL. En même temps, SOTA était utilisé dans de nombreuses tâches courantes de traitement du langage naturel, telles que l'analyse des sentiments, la reconnaissance d'entités nommées, etc. À l'exception de Bert et ALbert proposés. par Google, des représentants exceptionnels de la famille Bert. À cela s'ajoutent ERNIE de Baidu, RoBERTa de Meta, DeBERTa de Microsoft, etc.
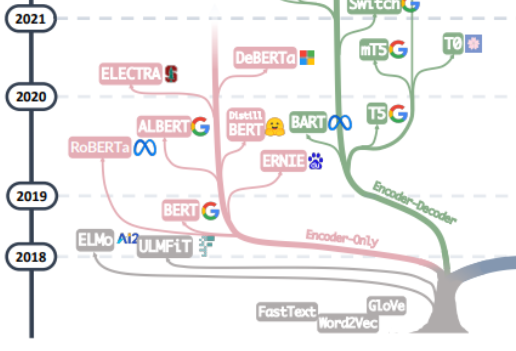
Malheureusement, l'approche de Bert n'a pas réussi à briser la loi d'échelle, et ce point est fait par la force principale des grands modèles actuels, c'est-à-dire une autre façon de développer de grands modèles, en abandonnant la partie Encodeur et en se basant sur le Décodeur. fait partie de GPT La famille l'a vraiment fait. Le succès de la famille GPT vient de la découverte surprenante d'un chercheur : "L'augmentation de la taille du modèle de langage peut améliorer considérablement la capacité d'apprentissage par tir zéro (zero-shot) et par petits coups (quelques coups)." avec la famille Bert basée sur un réglage fin, il y a une grande différence, et c'est aussi la source du pouvoir magique des modèles linguistiques à grande échelle d'aujourd'hui. La famille GPT est formée sur la base de la prédiction du mot suivant à partir de la séquence de mots précédente. Par conséquent, GPT n'est initialement apparu que comme un modèle de génération de texte, et l'émergence de GPT-3 a été un tournant dans le destin de la famille GPT. 3 a été le premier. Il montre aux gens les capacités magiques apportées par les grands modèles au-delà de la génération de texte elle-même, et montre la supériorité de ces modèles de langage autorégressifs. À partir de GPT-3, les actuels ChatGPT, GPT-4, Bard, PaLM et LLaMA ont prospéré, ouvrant la voie à l'ère actuelle des grands modèles.

De la fusion des deux branches de cet arbre généalogique, nous pouvons voir les débuts de Word2Vec et FastText, jusqu'aux débuts de l'exploration d'ELMo et d'ULFMiT dans les modèles de pré-formation, jusqu'à l'émergence de Bert, qui est devenu un succès hit, et à la culture silencieuse de la famille GPT. Jusqu'aux débuts époustouflants de GPT-3, ChatGPT s'est envolé dans le ciel. En plus de l'itération de la technologie, nous pouvons également voir qu'OpenAI a adhéré silencieusement à son propre chemin technique et a finalement suivi. est devenu le leader incontesté des LLM. Nous avons vu que Google a fait de gros efforts dans l'ensemble de l'architecture du modèle Encoder-Decoder. Nous avons vu les contributions théoriques significatives apportées par Meta, la participation généreuse et continue de Meta à de grands projets open source de modèles, et bien sûr nous. Nous avons également vu la tendance des LLM à devenir progressivement des sources « fermées » depuis GPT-3. Il est très probable que la plupart des recherches devront évoluer vers des recherches basées sur les API.

Les données - la source du pouvoir des grands modèles
En dernière analyse, le pouvoir magique des grands modèles vient-il du GPT ? Je pense que la réponse est non. Presque chaque avancée en matière de capacités de la famille GPT a apporté des améliorations importantes en termes de quantité, de qualité et de diversité des données de pré-entraînement. Les données d'entraînement du grand modèle comprennent des livres, des articles, des informations sur des sites Web, des informations de code, etc. Le but de la saisie de ces données dans le grand modèle est de refléter pleinement et précisément « l'être humain » en indiquant au grand modèle les mots, la grammaire, la syntaxe et les informations sémantiques permettent au modèle d'acquérir la capacité de reconnaître le contexte et de générer des réponses cohérentes pour capturer les aspects de la connaissance humaine, de la langue, de la culture, etc.
D'une manière générale, face à de nombreuses tâches PNL, nous pouvons les classer en échantillons zéro, quelques échantillons et échantillons multiples du point de vue des informations d'annotation des données. Sans aucun doute, les LLM sont la méthode la plus appropriée pour les tâches sans tir. Sans aucune exception, les grands modèles sont loin devant les autres modèles pour les tâches sans tir. Dans le même temps, les tâches à quelques échantillons sont également très adaptées à l'application de grands modèles. En affichant des paires « question-réponse » pour les grands modèles, les performances des grands modèles peuvent être améliorées. Cette approche est également généralement appelée en contexte. Apprentissage. Bien que les grands modèles puissent également couvrir des tâches multi-échantillons, un réglage fin peut rester la meilleure méthode. Bien entendu, sous certaines contraintes telles que la confidentialité et l'informatique, les grands modèles peuvent toujours être utiles.

Dans le même temps, le modèle affiné est susceptible d'être confronté au problème des changements dans la distribution des données d'entraînement et des données de test. De manière significative, le modèle affiné fonctionne généralement très mal sur les données OOD. En conséquence, les LLM fonctionnent bien mieux car ils n'ont pas de processus d'ajustement explicite. L'apprentissage par renforcement ChatGPT typique basé sur la rétroaction humaine (RLHF) fonctionne bien dans la plupart des tâches de classification et de traduction hors distribution. Il fonctionne également bien sur DDXPlus, un. ensemble de données de diagnostic médical conçu pour l'évaluation OOD.
Guide pratique - Débuter avec les grands modèles axés sur les tâches
Souvent, l'affirmation « Les grands modèles sont bons ! » est suivie de la question « Comment utiliser les grands modèles et quand les utiliser face à un problème spécifique ? tâche , faut-il choisir le réglage fin, ou commencer par le grand modèle sans réfléchir ? Cet article résume un « flux de décision » pratique pour nous aider à déterminer s'il convient d'utiliser un grand modèle basé sur une série de questions telles que « s'il est nécessaire d'imiter les humains », « si des capacités de raisonnement sont requises », « s'il est multi -tâches".
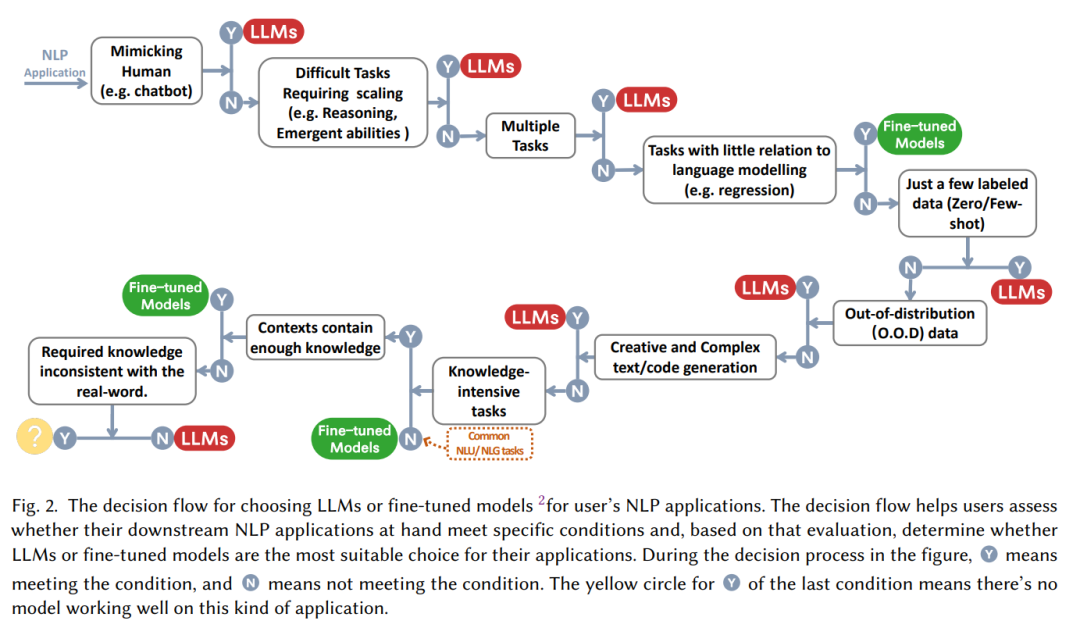
Du point de vue de la classification des tâches PNL :
Compréhension traditionnelle du langage naturel
Il existe actuellement de nombreuses tâches PNL avec une grande quantité de données annotées riches, et le modèle de réglage fin peut encore contrôler fermement l'avantage, dans dans la plupart des cas, les LLM de l'ensemble de données sont inférieurs aux modèles affinés, en particulier :
- Classification de texte : dans la classification de texte, les LLM sont généralement inférieurs aux modèles affinés
- Analyse des sentiments : sur les tâches IMDB et SST, les performances ; Les grands modèles et les modèles affinés sont similaires. Dans des tâches telles que la surveillance de la toxicité, presque tous les grands modèles sont pires que les modèles affinés.
- Raisonnement en langage naturel : sur RTE et SNLI, les modèles affinés sont meilleurs que les LLM ; et dans CB et autres données, les LLM sont similaires aux modèles affinés ;
- Q&A : sur SQuADv2, QuAC et de nombreux autres ensembles de données, les modèles affinés ont de meilleures performances, tandis que sur CoQA, les LLM fonctionnent de la même manière que les modèles affinés ;
- Récupération d'informations : les LLM n'ont pas été largement utilisés dans le domaine de la récupération d'informations, les caractéristiques des tâches de récupération d'informations font qu'il n'existe pas de moyen naturel de modéliser les tâches de récupération d'informations pour les grands modèles
- Reconnaissance d'entités nommées : dans la reconnaissance d'entités nommées, les grands modèles sont encore nettement inférieurs aux modèles affinés, et les performances des modèles affinés sur CoNLL03 sont presque aussi grandes que deux fois la taille du modèle, mais la reconnaissance d'entités nommées, en tant que tâche intermédiaire classique de la PNL, est susceptible d'être remplacé par des grands modèles.
En bref, pour la plupart des tâches traditionnelles de compréhension du langage naturel, les modèles affinés fonctionnent mieux. Bien entendu, le potentiel des LLM est limité par le projet Prompt qui pourrait ne pas être entièrement publié (en fait, le modèle de réglage fin n'a pas atteint la limite supérieure, dans certains domaines de niche, comme le texte divers). Classification, NLI contradictoire et autres tâches, les LLM ont des capacités plus fortes. La capacité de généralisation conduit donc à de meilleures performances, mais pour l'instant, pour des données étiquetées de manière mature, le réglage fin du modèle peut encore être la solution optimale pour les tâches traditionnelles.
Génération du langage naturel
Par rapport à la compréhension du langage naturel, la génération du langage naturel peut être le théâtre de grands modèles. L'objectif principal de la génération de langage naturel est de créer des séquences cohérentes, fluides et significatives. Elle peut généralement être divisée en deux catégories : l'une est constituée de tâches représentées par la traduction automatique et le résumé d'informations de paragraphe, et l'autre est l'écriture naturelle plus ouverte. comme rédiger des e-mails, rédiger des actualités, créer des histoires, etc. Plus précisément :
- Résumé textuel : Pour le résumé textuel, si des indicateurs d'évaluation automatique traditionnels tels que ROUGE sont utilisés, les LLM ne présentent pas d'avantages évidents, mais si des résultats d'évaluation manuelle sont introduits, les performances des LLM seront considérablement améliorées. -modèles optimisés. Cela montre en fait que les indicateurs d'évaluation automatique actuels ne reflètent parfois pas pleinement et précisément l'effet de la génération de texte.
- Traduction automatique : pour une tâche telle que la traduction automatique avec un logiciel commercial mature, les performances des LLM sont généralement légèrement inférieures à celles des logiciels commerciaux ; outils de traduction, mais dans la traduction de certaines langues impopulaires, les LLM donnent parfois de meilleurs résultats. Par exemple, dans la tâche de traduction du roumain vers l'anglais, les LLM ont vaincu le SOTA du modèle affiné dans le cas de zéro échantillon et de peu d'échantillons ;
- Génération de formule ouverte : en termes de génération ouverte, l'affichage est ce pour quoi les grands modèles sont les meilleurs. Les articles d'actualité générés par les LLM sont presque impossibles à distinguer des vraies nouvelles écrites par les humains et ont étonnamment bien fonctionné dans des domaines tels que la génération de code et les erreurs de code. correction.
Tâches à forte intensité de connaissances
Les tâches à forte intensité de connaissances font généralement référence à des tâches qui reposent fortement sur des connaissances de base, une expertise spécifique à un domaine ou des connaissances générales du monde. Les tâches à forte intensité de connaissances sont différentes de la simple reconnaissance de formes et de l'analyse syntaxique et nécessitent une analyse approfondie. compréhension de notre réalité. Le monde a du « bon sens » et peut l'utiliser correctement, en particulier :
- Réponse aux questions à livre fermé : Dans la tâche de réponse aux questions à livre fermé, le modèle doit répondre à des questions factuelles sans intervention extérieure. informations, dans de nombreux ensembles de données, les LLM tels que NaturalQuestions, WebQuestions et TriviaQA affichent tous de meilleures performances, en particulier dans TriviaQA, les LLM à échantillon nul affichent de meilleures performances en matière de genre que les modèles affinés
- Compréhension du langage multitâche à grande échelle : grande ; -scale Multi-tâche Language Understanding (MMLU) contient 57 questions à choix multiples sur différents sujets et nécessite également que le modèle ait des connaissances générales. La plus impressionnante dans cette tâche est GPT-4, qui a obtenu un score de 86,5 en % de taux correct MMLU. .
Il convient de noter que dans les tâches à forte intensité de connaissances, les grands modèles ne sont pas toujours efficaces. Parfois, les grands modèles peuvent être inutiles ou même erronés pour les connaissances du monde réel. De telles connaissances « incohérentes » rendent parfois les grands modèles inutiles. pire que les suppositions aléatoires. Par exemple, la tâche Redéfinir les mathématiques nécessite que le modèle choisisse entre le sens original et le sens redéfini. Cela nécessite la capacité d'être exactement à l'opposé des connaissances apprises par les modèles de langage à grande échelle. Par conséquent, les performances des LLM sont encore pires que celles des modèles de langage à grande échelle. aléatoire.
Tâches d'inférence
L'évolutivité des LLM peut considérablement améliorer la capacité des modèles de langage pré-entraînés. Lorsque la taille du modèle augmente de façon exponentielle, certaines capacités de raisonnement clés seront progressivement activées avec l'expansion des paramètres, le raisonnement arithmétique des LLM. la raison avec le bon sens est extrêmement puissante, visible à l'œil nu. Dans ce type de tâches :
- Raisonnement arithmétique : il n'est pas exagéré de dire que les capacités de jugement arithmétique et de raisonnement de GPT-4 dépassent celles de n'importe quel modèle précédent dans GSM8k. SVAMP et les grands modèles sur AQuA ont des capacités révolutionnaires. Il convient de souligner que grâce à la méthode d'invite de chaîne de pensée (CoT), la puissance de calcul des LLM peut être considérablement améliorée.
- Raisonnement de bon sens : le raisonnement de bon sens nécessite de grands modèles ; mémoriser des informations factuelles et effectuer Pour le raisonnement en plusieurs étapes, les LLM maintiennent leur supériorité sur les modèles affinés dans la plupart des ensembles de données, en particulier dans ARC-C (questions difficiles aux examens scientifiques de la 3e à la 9e année), où les performances du GPT-4 sont proches à 100% (96,3%) .
En plus du raisonnement, à mesure que la taille du modèle augmente, certaines capacités émergentes apparaîtront également dans le modèle, telles que les opérations de coïncidence, la dérivation logique, la compréhension de concepts, etc. Cependant, il existe également un phénomène intéressant appelé « phénomène en forme de U », qui fait référence au phénomène selon lequel, à mesure que l'échelle des LLM augmente, les performances du modèle augmentent d'abord, puis commencent à décliner. Le représentant typique est le problème de la redéfinition des mathématiques. Ces phénomènes nécessitent des recherches plus approfondies et plus détaillées sur les principes des grands modèles.
Résumé - Défis et avenir des grands modèles
Les grands modèles feront inévitablement partie de notre travail et de notre vie pendant longtemps dans le futur, et pour un si "grand gars" très interactif avec nos vies, en plus de la performance , efficacité et coût En plus d'autres problèmes, le problème de sécurité des modèles de langage à grande échelle est presque la priorité absolue parmi tous les défis auxquels sont confrontés les grands modèles. L'hallucination des machines est un problème majeur pour les grands modèles qui n'a actuellement aucune excellente solution. la sortie des grands modèles présente des écarts ou des hallucinations néfastes qui peuvent avoir de graves conséquences pour l'utilisateur. Dans le même temps, à mesure que la « crédibilité » des LLM augmente, les utilisateurs peuvent devenir trop dépendants des LLM et croire qu'ils peuvent fournir des informations précises. Cette tendance prévisible augmente les risques de sécurité des grands modèles.
En plus des informations trompeuses, en raison de la haute qualité et du faible coût du texte généré par les LLM, les LLM peuvent être exploités comme outils d'attaques telles que la haine, la discrimination, la violence et la désinformation. Les LLM peuvent également être attaqués pour fournir des informations illégales. à des attaquants malveillants. Vol d'informations ou de confidentialité Selon des rapports, des employés de Samsung ont accidentellement divulgué des données top secrètes telles que les attributs du code source du dernier programme et des enregistrements de réunions internes liés au matériel alors qu'ils utilisaient ChatGPT pour gérer leur travail.
De plus, la clé pour savoir si les grands modèles peuvent être appliqués à des domaines sensibles, tels que les soins de santé, la finance, le droit, etc., réside dans la « crédibilité » des grands modèles à l'heure actuelle, à échantillon nul. les modèles ne sont pas fiables. L’adhésivité a tendance à diminuer. Dans le même temps, il a été démontré que les LLM sont socialement biaisés ou discriminatoires, de nombreuses études observant des différences de performance significatives entre les catégories démographiques telles que l'accent, la religion, le sexe et la race. Cela peut entraîner des problèmes « d’équité » pour les grands modèles.
Enfin, si l'on s'éloigne des enjeux sociaux pour faire une synthèse, on peut également se pencher sur l'avenir de la recherche sur les grands modèles. Les principaux défis auxquels sont actuellement confrontés les grands modèles peuvent être classés comme suit :
- Vérification pratique : Évaluation actuelle. Les ensembles de données pour les grands modèles sont souvent des ensembles de données académiques qui ressemblent davantage à des « jouets », mais ces ensembles de données académiques ne peuvent pas refléter pleinement les divers problèmes et défis du monde réel. Il existe donc un besoin urgent de données réelles. des ensembles pour évaluer le modèle sur des problèmes divers et complexes du monde réel afin de garantir que les modèles peuvent faire face aux défis du monde réel ;
- Alignement du modèle : la puissance des grands modèles soulève également un autre problème. Le modèle doit être aligné sur les choix de valeurs humaines pour garantir. que le modèle se comporte comme prévu et ne « renforce » pas les résultats indésirables. En tant que système complexe avancé, si cette question éthique n'est pas traitée sérieusement, elle pourrait provoquer un désastre pour l'humanité.
- Risques pour la sécurité : la recherche sur les grands modèles doit davantage insister ; des problèmes de sécurité et éliminer les risques pour la sécurité. Des recherches spécifiques sont nécessaires pour garantir que la recherche et le développement des grands modèles nécessitent davantage de travail sur l'interprétabilité, la supervision et la gestion des modèles. Les problèmes de sécurité devraient être une partie importante du développement des modèles, plutôt qu'une décoration superflue ; Avenir du modèle : les performances du modèle sont toujours va-t-elle augmenter à mesure que la taille du modèle augmente ? , on estime qu'OpenAI a du mal à répondre à cette question. Notre compréhension des phénomènes magiques des grands modèles est encore très limitée et les connaissances sur les principes des grands modèles sont encore très précieuses.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
