
 développement back-end
Tutoriel Python
Comment utiliser Python pour développer un framework Web personnalisé
développement back-end
Tutoriel Python
Comment utiliser Python pour développer un framework Web personnalisé
Comment utiliser Python pour développer un framework Web personnalisé

Développez un framework Web personnalisé
Recevez des demandes de ressources dynamiques du serveur Web et fournissez au serveur Web des services pour traiter les demandes de ressources dynamiques. Déterminez en fonction du nom de suffixe du chemin de ressource demandé :
Si le nom de suffixe du chemin de ressource demandé est .html, il s'agit d'une demande de ressource dynamique et laissez le programme-cadre Web la gérer.
Sinon, il s'agit d'une demande de ressource statique, laissez le programme du serveur Web la gérer.
1. Développer le programme principal du serveur Web
1. Accepter les requêtes HTTP des clients (la couche inférieure est TCP)
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
from socket import *
import threading
# 开发自己的Web服务器主类
class MyHttpWebServer(object):
def __init__(self, port):
# 创建 HTTP服务的 TCP套接字
server_socket = socket(AF_INET, SOCK_STREAM)
# 设置端口号互用,程序退出之后不需要等待,直接释放端口
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, True)
# 绑定 ip和 port
server_socket.bind(('', port))
# listen使套接字变为了被动连接
server_socket.listen(128)
self.server_socket = server_socket
# 处理请求函数
@staticmethod # 静态方法
def handle_browser_request(new_socket):
# 接受客户端发来的数据
recv_data = new_socket.recv(4096)
# 如果没有数据,那么请求无效,关闭套接字,直接退出
if len(recv_data) == 0:
new_socket.close()
return
# 启动服务器,并接受客户端请求
def start(self):
# 循环并多线程来接收客户端请求
while True:
# accept等待客户端连接
new_socket, ip_port = self.server_socket.accept()
print("客户端ip和端口", ip_port)
# 一个客户端的请求交给一个线程来处理
sub_thread = threading.Thread(target=MyHttpWebServer.handle_browser_request, args=(new_socket, ))
# 设置当前线程为守护线程
sub_thread.setDaemon(True)
sub_thread.start() # 启动子线程
# Web 服务器程序的入口
def main():
web_server = MyHttpWebServer(8080)
web_server.start()
if __name__ == '__main__':
main()2 Déterminer si la requête est une ressource statique ou une ressource dynamique
# 对接收的字节数据进行转换为字符数据
request_data = recv_data.decode('utf-8')
print("浏览器请求的数据:", request_data)
request_array = request_data.split(' ', maxsplit=2)
# 得到请求路径
request_path = request_array[1]
print("请求的路径是:", request_path)
if request_path == "/":
# 如果请求路径为根目录,自动设置为:/index.html
request_path = "/index.html"
# 判断是否为:.html 结尾
if request_path.endswith(".html"):
"动态资源请求"
pass
else:
"静态资源请求"
pass3. Comment. gérer des ressources statiques ?
"静态资源请求"
# 根据请求路径读取/static 目录中的文件数据,相应给客户端
response_body = None # 响应主体
response_header = None # 响应头的第一行
response_first_line = None # 响应头内容
response_type = 'test/html' # 默认响应类型
try:
# 读取 static目录中相对应的文件数据,rb模式是一种兼容模式,可以打开图片,也可以打开js
with open('static'+request_path, 'rb') as f:
response_body = f.read()
if request_path.endswith('.jpg'):
response_type = 'image/webp'
response_first_line = 'HTTP/1.1 200 OK'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: ' + response_type + '; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 浏览器读取的文件可能不存在
except Exception as e:
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容
# 响应头
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Content-Length:'+str(len(response_body))+'\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 最后都会执行的代码
finally:
# 组成响应数据发送给(客户端)浏览器
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
new_socket.send(response)
# 关闭套接字
new_socket.close()
Vérification de la demande de ressources statiques :
4. Que faire si les ressources dynamiques
if request_path.endswith(".html"):
"动态资源请求"
# 动态资源的处理交给Web框架来处理,需要把请求参数交给Web框架,可能会有多个参数,采用字典结构
params = {
'request_path': request_path
}
# Web框架处理动态资源请求后,返回一个响应
response = MyFramework.handle_request(params)
new_socket.send(response)
new_socket.close()5. Fermez le serveur Web
new_socket.close()
Affichage du code total du cadre principal du serveur Web :
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
import sys
import time
from socket import *
import threading
import MyFramework
# 开发自己的Web服务器主类
class MyHttpWebServer(object):
def __init__(self, port):
# 创建 HTTP服务的 TCP套接字
server_socket = socket(AF_INET, SOCK_STREAM)
# 设置端口号互用,程序退出之后不需要等待,直接释放端口
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, True)
# 绑定 ip和 port
server_socket.bind(('', port))
# listen使套接字变为了被动连接
server_socket.listen(128)
self.server_socket = server_socket
# 处理请求函数
@staticmethod # 静态方法
def handle_browser_request(new_socket):
# 接受客户端发来的数据
recv_data = new_socket.recv(4096)
# 如果没有数据,那么请求无效,关闭套接字,直接退出
if len(recv_data) == 0:
new_socket.close()
return
# 对接收的字节数据进行转换为字符数据
request_data = recv_data.decode('utf-8')
print("浏览器请求的数据:", request_data)
request_array = request_data.split(' ', maxsplit=2)
# 得到请求路径
request_path = request_array[1]
print("请求的路径是:", request_path)
if request_path == "/":
# 如果请求路径为根目录,自动设置为:/index.html
request_path = "/index.html"
# 判断是否为:.html 结尾
if request_path.endswith(".html"):
"动态资源请求"
# 动态资源的处理交给Web框架来处理,需要把请求参数交给Web框架,可能会有多个参数,采用字典结构
params = {
'request_path': request_path
}
# Web框架处理动态资源请求后,返回一个响应
response = MyFramework.handle_request(params)
new_socket.send(response)
new_socket.close()
else:
"静态资源请求"
# 根据请求路径读取/static 目录中的文件数据,相应给客户端
response_body = None # 响应主体
response_header = None # 响应头的第一行
response_first_line = None # 响应头内容
response_type = 'test/html' # 默认响应类型
try:
# 读取 static目录中相对应的文件数据,rb模式是一种兼容模式,可以打开图片,也可以打开js
with open('static'+request_path, 'rb') as f:
response_body = f.read()
if request_path.endswith('.jpg'):
response_type = 'image/webp'
response_first_line = 'HTTP/1.1 200 OK'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: ' + response_type + '; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 浏览器读取的文件可能不存在
except Exception as e:
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容
# 响应头
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Content-Length:'+str(len(response_body))+'\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 最后都会执行的代码
finally:
# 组成响应数据发送给(客户端)浏览器
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
new_socket.send(response)
# 关闭套接字
new_socket.close()
# 启动服务器,并接受客户端请求
def start(self):
# 循环并多线程来接收客户端请求
while True:
# accept等待客户端连接
new_socket, ip_port = self.server_socket.accept()
print("客户端ip和端口", ip_port)
# 一个客户端的请求交给一个线程来处理
sub_thread = threading.Thread(target=MyHttpWebServer.handle_browser_request, args=(new_socket, ))
# 设置当前线程为守护线程
sub_thread.setDaemon(True)
sub_thread.start() # 启动子线程
# Web 服务器程序的入口
def main():
web_server = MyHttpWebServer(8080)
web_server.start()
if __name__ == '__main__':
main()2 .Développez le programme principal du framework Web
1. Répondez dynamiquement aux données correspondantes en fonction du chemin de la requête
# -*- coding: utf-8 -*-
# @File : MyFramework.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/25 14:05
import time
# 自定义Web框架
# 处理动态资源请求的函数
def handle_request(parm):
request_path = parm['request_path']
if request_path == '/index.html': # 当前请求路径有与之对应的动态响应,当前框架只开发了 index.html的功能
response = index()
return response
else:
# 没有动态资源的数据,返回404页面
return page_not_found()
# 当前 index函数,专门处理index.html的请求
def index():
# 需求,在页面中动态显示当前系统时间
data = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
response_body = data
response_first_line = 'HTTP/1.1 200 OK\r\n'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
response = (response_first_line + response_header + '\r\n' + response_body).encode('utf-8')
return response
def page_not_found():
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容
# 响应头
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
return response2 Si le chemin de la requête n'a pas de données de réponse correspondantes, une page 404 doit être renvoyée
. 
3. Utilisez des modèles pour afficher le contenu de la réponse
1. Concevez vous-même un modèle index.html et utilisez des données dynamiques pour le remplacer à certains endroits
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>首页 - 电影列表</title>
<link href="/css/bootstrap.min.css" rel="stylesheet">
<script src="/js/jquery-1.12.4.min.js"></script>
<script src="/js/bootstrap.min.js"></script>
</head>
<body>
<div class="navbar navbar-inverse navbar-static-top ">
<div class="container">
<div class="navbar-header">
<button class="navbar-toggle" data-toggle="collapse" data-target="#mymenu">
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a href="#" class="navbar-brand">电影列表</a>
</div>
<div class="collapse navbar-collapse" id="mymenu">
<ul class="nav navbar-nav">
<li class="active"><a href="">电影信息</a></li>
<li><a href="">个人中心</a></li>
</ul>
</div>
</div>
</div>
<div class="container">
<div class="container-fluid">
<table class="table table-hover">
<tr>
<th>序号</th>
<th>名称</th>
<th>导演</th>
<th>上映时间</th>
<th>票房</th>
<th>电影时长</th>
<th>类型</th>
<th>备注</th>
<th>删除电影</th>
</tr>
{%datas%}
</table>
</div>
</div>
</body>
</html>2 Comment le remplacer, quelles données remplacer
response_body = response_body.replace('{%datas%}', data)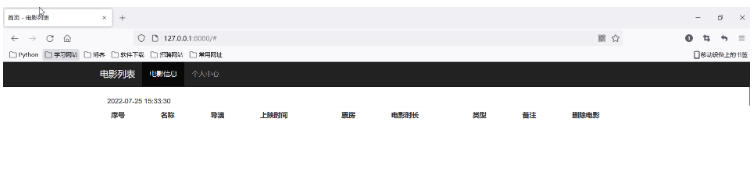
4. Développer la fonction de liste de routage du framework
1. Pour développer de nouvelles fonctions de ressources d'action à l'avenir, il vous suffit de :
a Ajouter une branche de jugement conditionnel
b. function
2. Routage : le chemin de l'URL demandé et la fonction de traitement sont directement mappés.
3. Table de routage
| Chemin de requête | Fonction de traitement |
|---|---|
| /index.html | fonction d'index |
| /user_info.html | fonction user_info |
# 定义路由表
route_list = {
('/index.html', index),
('/user_info.html', user_info)
}
for path, func in route_list:
if request_path == path:
return func()
else:
# 没有动态资源的数据,返回404页面
return page_not_found()Attention : Utilisateur La demande de ressource dynamique est complétée en parcourant la table de routage pour trouver la fonction de traitement correspondante.
5. Utilisez des décorateurs pour ajouter des routes
1. Utilisez des décorateurs avec des paramètres
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
# 定义路由表
route_list = []
# route_list = {
# ('/index.html', index),
# ('/user_info.html', user_info)
# }
# 定义一个带参数的装饰器
def route(request_path): # 参数就是URL请求
def add_route(func):
# 添加路由表
route_list.append((request_path, func))
@wraps(func)
def invoke(*args, **kwargs):
# 调用指定的处理函数,并返回结果
return func()
return invoke
return add_route
# 处理动态资源请求的函数
def handle_request(parm):
request_path = parm['request_path']
# if request_path == '/index.html': # 当前请求路径有与之对应的动态响应,当前框架只开发了 index.html的功能
# response = index()
# return response
# elif request_path == '/user_info.html': # 个人中心的功能
# return user_info()
# else:
# # 没有动态资源的数据,返回404页面
# return page_not_found()
for path, func in route_list:
if request_path == path:
return func()
else:
# 没有动态资源的数据,返回404页面
return page_not_found()2 Ajoutez une fonction pour ajouter des routes en fonction de n'importe quelle fonction de traitement
@route('/user_info.html')
Résumé : Utiliser la décoration avec des paramètres Le routeur peut automatiquement ajouter nos routes à. la table de routage.
6. Cas de développement de la page de liste de films
1. Requête de données
my_web.py
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
import socket
import sys
import threading
import time
import MyFramework
# 开发自己的Web服务器主类
class MyHttpWebServer(object):
def __init__(self, port):
# 创建HTTP服务器的套接字
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置端口号复用,程序退出之后不需要等待几分钟,直接释放端口
server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
server_socket.bind(('', port))
server_socket.listen(128)
self.server_socket = server_socket
# 处理浏览器请求的函数
@staticmethod
def handle_browser_request(new_socket):
# 接受客户端发送过来的数据
recv_data = new_socket.recv(4096)
# 如果没有收到数据,那么请求无效,关闭套接字,直接退出
if len(recv_data) == 0:
new_socket.close()
return
# 对接受的字节数据,转换成字符
request_data = recv_data.decode('utf-8')
print("浏览器请求的数据:", request_data)
request_array = request_data.split(' ', maxsplit=2)
# 得到请求路径
request_path = request_array[1]
print('请求路径是:', request_path)
if request_path == '/': # 如果请求路径为跟目录,自动设置为/index.html
request_path = '/index.html'
# 根据请求路径来判断是否是动态资源还是静态资源
if request_path.endswith('.html'):
'''动态资源的请求'''
# 动态资源的处理交给Web框架来处理,需要把请求参数传给Web框架,可能会有多个参数,所有采用字典机构
params = {
'request_path': request_path,
}
# Web框架处理动态资源请求之后,返回一个响应
response = MyFramework.handle_request(params)
new_socket.send(response)
new_socket.close()
else:
'''静态资源的请求'''
response_body = None # 响应主体
response_header = None # 响应头
response_first_line = None # 响应头的第一行
# 其实就是:根据请求路径读取/static目录中静态的文件数据,响应给客户端
try:
# 读取static目录中对应的文件数据,rb模式:是一种兼容模式,可以打开图片,也可以打开js
with open('static' + request_path, 'rb') as f:
response_body = f.read()
if request_path.endswith('.jpg'):
response_type = 'image/webp'
response_first_line = 'HTTP/1.1 200 OK'
response_header = 'Server: Laoxiao_Server\r\n'
except Exception as e: # 浏览器想读取的文件可能不存在
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容(字节)
# 响应头 (字符数据)
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Server: Laoxiao_Server\r\n'
finally:
# 组成响应数据,发送给客户端(浏览器)
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
new_socket.send(response)
new_socket.close() # 关闭套接字
# 启动服务器,并且接受客户端的请求
def start(self):
# 循环并且多线程来接受客户端的请求
while True:
new_socket, ip_port = self.server_socket.accept()
print("客户端的ip和端口", ip_port)
# 一个客户端请求交给一个线程来处理
sub_thread = threading.Thread(target=MyHttpWebServer.handle_browser_request, args=(new_socket,))
sub_thread.setDaemon(True) # 设置当前线程为守护线程
sub_thread.start() # 子线程要启动
# web服务器程序的入口
def main():
web_server = MyHttpWebServer(8080)
web_server.start()
if __name__ == '__main__':
main()MyFramework.py
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
import time
from functools import wraps
import pymysql
# 定义路由表
route_list = []
# route_list = {
# # ('/index.html',index),
# # ('/userinfo.html',user_info)
# }
# 定义一个带参数装饰器
def route(request_path): # 参数就是URL请求
def add_route(func):
# 添加路由到路由表
route_list.append((request_path, func))
@wraps(func)
def invoke(*arg, **kwargs):
# 调用我们指定的处理函数,并且返回结果
return func()
return invoke
return add_route
# 处理动态资源请求的函数
def handle_request(params):
request_path = params['request_path']
for path, func in route_list:
if request_path == path:
return func()
else:
# 没有动态资源的数据,返回404页面
return page_not_found()
# if request_path =='/index.html': # 当前的请求路径有与之对应的动态响应,当前框架,我只开发了index.html的功能
# response = index()
# return response
#
# elif request_path =='/userinfo.html': # 个人中心的功能,user_info.html
# return user_info()
# else:
# # 没有动态资源的数据,返回404页面
# return page_not_found()
# 当前user_info函数,专门处理userinfo.html的动态请求
@route('/userinfo.html')
def user_info():
# 需求:在页面中动态显示当前系统时间
date = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
# response_body =data
with open('template/user_info.html', 'r', encoding='utf-8') as f:
response_body = f.read()
response_body = response_body.replace('{%datas%}', date)
response_first_line = 'HTTP/1.1 200 OK\r\n'
response_header = 'Server: Laoxiao_Server\r\n'
response = (response_first_line + response_header + '\r\n' + response_body).encode('utf-8')
return response
# 当前index函数,专门处理index.html的请求
@route('/index.html')
def index():
# 需求:从数据库中取得所有的电影数据,并且动态展示
# date = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
# response_body =data
# 1、从MySQL中查询数据
conn = pymysql.connect(host='localhost', port=3306, user='root', password='******', database='test', charset='utf8')
cursor = conn.cursor()
cursor.execute('select * from t_movies')
result = cursor.fetchall()
# print(result)
datas = ""
for row in result:
datas += '''<tr>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s 亿人民币</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td> <input type='button' value='删除'/> </td>
</tr>
''' % row
print(datas)
# 把查询的数据,转换成动态内容
with open('template/index.html', 'r', encoding='utf-8') as f:
response_body = f.read()
response_body = response_body.replace('{%datas%}', datas)
response_first_line = 'HTTP/1.1 200 OK\r\n'
response_header = 'Server: Laoxiao_Server\r\n'
response = (response_first_line + response_header + '\r\n' + response_body).encode('utf-8')
return response
# 处理没有找到对应的动态资源
def page_not_found():
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容(字节)
# 响应头 (字符数据)
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Server: Laoxiao_Server\r\n'
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
return response2.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Cet article expliquera comment améliorer les performances du site Web en analysant les journaux Apache dans le système Debian. 1. Bases de l'analyse du journal APACH LOG enregistre les informations détaillées de toutes les demandes HTTP, y compris l'adresse IP, l'horodatage, l'URL de la demande, la méthode HTTP et le code de réponse. Dans Debian Systems, ces journaux sont généralement situés dans les répertoires /var/log/apache2/access.log et /var/log/apache2/error.log. Comprendre la structure du journal est la première étape d'une analyse efficace. 2.
 Python: jeux, GUIS, et plus
Apr 13, 2025 am 12:14 AM
Python: jeux, GUIS, et plus
Apr 13, 2025 am 12:14 AM
Python excelle dans les jeux et le développement de l'interface graphique. 1) Le développement de jeux utilise Pygame, fournissant des fonctions de dessin, audio et d'autres fonctions, qui conviennent à la création de jeux 2D. 2) Le développement de l'interface graphique peut choisir Tkinter ou Pyqt. Tkinter est simple et facile à utiliser, PYQT a des fonctions riches et convient au développement professionnel.
 PHP et Python: comparaison de deux langages de programmation populaires
Apr 14, 2025 am 12:13 AM
PHP et Python: comparaison de deux langages de programmation populaires
Apr 14, 2025 am 12:13 AM
PHP et Python ont chacun leurs propres avantages et choisissent en fonction des exigences du projet. 1.Php convient au développement Web, en particulier pour le développement rapide et la maintenance des sites Web. 2. Python convient à la science des données, à l'apprentissage automatique et à l'intelligence artificielle, avec syntaxe concise et adaptée aux débutants.
 Le rôle de Debian Sniffer dans la détection des attaques DDOS
Apr 12, 2025 pm 10:42 PM
Le rôle de Debian Sniffer dans la détection des attaques DDOS
Apr 12, 2025 pm 10:42 PM
Cet article traite de la méthode de détection d'attaque DDOS. Bien qu'aucun cas d'application directe de "Debiansniffer" n'ait été trouvé, les méthodes suivantes ne peuvent être utilisées pour la détection des attaques DDOS: technologie de détection d'attaque DDOS efficace: détection basée sur l'analyse du trafic: identification des attaques DDOS en surveillant des modèles anormaux de trafic réseau, tels que la croissance soudaine du trafic, une surtension dans des connexions sur des ports spécifiques, etc. Par exemple, les scripts Python combinés avec les bibliothèques Pyshark et Colorama peuvent surveiller le trafic réseau en temps réel et émettre des alertes. Détection basée sur l'analyse statistique: en analysant les caractéristiques statistiques du trafic réseau, telles que les données
 Certificat NGINX SSL Mise à jour du tutoriel Debian
Apr 13, 2025 am 07:21 AM
Certificat NGINX SSL Mise à jour du tutoriel Debian
Apr 13, 2025 am 07:21 AM
Cet article vous guidera sur la façon de mettre à jour votre certificat NGINXSSL sur votre système Debian. Étape 1: Installez d'abord CERTBOT, assurez-vous que votre système a des packages CERTBOT et Python3-CERTBOT-NGINX installés. Si ce n'est pas installé, veuillez exécuter la commande suivante: Sudoapt-getUpDaSuDoapt-GetInstallCertBotpyThon3-Certerbot-Nginx Étape 2: Obtenez et configurez le certificat Utilisez la commande Certbot pour obtenir le certificat LETSCRYPT et configure
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Python et temps: tirer le meilleur parti de votre temps d'étude
Apr 14, 2025 am 12:02 AM
Python et temps: tirer le meilleur parti de votre temps d'étude
Apr 14, 2025 am 12:02 AM
Pour maximiser l'efficacité de l'apprentissage de Python dans un temps limité, vous pouvez utiliser les modules DateTime, Time et Schedule de Python. 1. Le module DateTime est utilisé pour enregistrer et planifier le temps d'apprentissage. 2. Le module de temps aide à définir l'étude et le temps de repos. 3. Le module de planification organise automatiquement des tâches d'apprentissage hebdomadaires.
 Comment configurer le serveur HTTPS dans Debian OpenSSL
Apr 13, 2025 am 11:03 AM
Comment configurer le serveur HTTPS dans Debian OpenSSL
Apr 13, 2025 am 11:03 AM
La configuration d'un serveur HTTPS sur un système Debian implique plusieurs étapes, notamment l'installation du logiciel nécessaire, la génération d'un certificat SSL et la configuration d'un serveur Web (tel qu'Apache ou Nginx) pour utiliser un certificat SSL. Voici un guide de base, en supposant que vous utilisez un serveur Apacheweb. 1. Installez d'abord le logiciel nécessaire, assurez-vous que votre système est à jour et installez Apache et OpenSSL: SudoaptupDaSuDoaptupgradeSudoaptinsta
