

Analyse comparative des architectures de deep learning

Le concept d'apprentissage profond est né de la recherche de réseaux de neurones artificiels. Un perceptron multicouche contenant plusieurs couches cachées est une structure d'apprentissage profond. L'apprentissage profond combine des fonctionnalités de bas niveau pour former des représentations de haut niveau plus abstraites afin de caractériser des catégories ou des caractéristiques de données. Il est capable de découvrir des représentations de fonctionnalités distribuées de données. L'apprentissage profond est un type d'apprentissage automatique, et l'apprentissage automatique est le seul moyen d'atteindre l'intelligence artificielle.
Alors, quelles sont les différences entre les différentes architectures de systèmes de deep learning ?
1. Réseau entièrement connecté (FCN)
Un réseau entièrement connecté (FCN) se compose d'une série de couches entièrement connectées, avec chaque neurone de chaque couche connecté à chaque neurone dans une autre couche. Son principal avantage est qu'il est « indépendant de la structure », c'est-à-dire qu'aucune hypothèse particulière concernant l'entrée n'est requise. Bien que cette structure indépendante rende les réseaux entièrement connectés très largement applicables, ces réseaux ont tendance à être moins performants que les réseaux spécialisés spécifiquement adaptés à la structure de l’espace problématique.
Le schéma ci-dessous montre un réseau entièrement connecté avec plusieurs couches de profondeur :
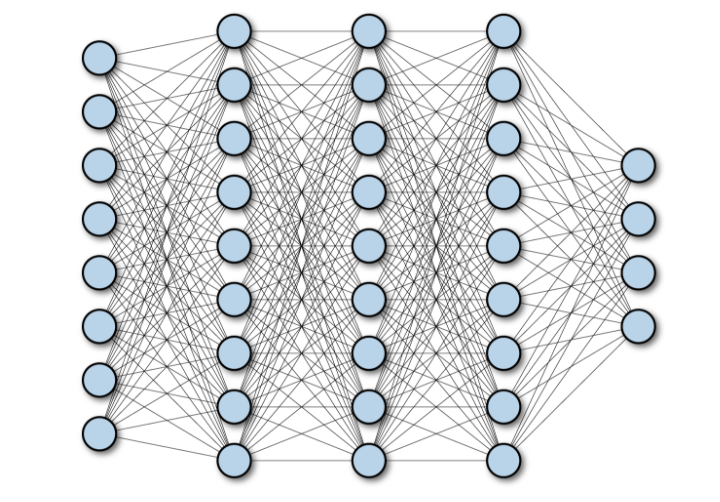
2 . Réseau de neurones convolutifs (CNN)
Le réseau de neurones convolutifs (CNN) est une architecture de réseau neuronal multicouche principalement utilisée dans les applications de traitement d'images. L'architecture CNN suppose explicitement que l'entrée a une dimension spatiale (et éventuellement une dimension de profondeur), telle qu'une image, ce qui permet d'encoder certaines propriétés dans l'architecture du modèle. Yann LeCun a créé le premier CNN, une architecture utilisée à l'origine pour reconnaître les caractères manuscrits.
2.1 Caractéristiques architecturales de CNN
Décomposons les détails techniques du modèle de vision par ordinateur à l'aide de CNN :
- Saisie du modèle : CNN L'entrée du modèle est généralement une image ou un texte. Les CNN peuvent également être utilisés sur du texte, mais ils sont généralement moins utilisés.
L'image est représentée ici comme une grille de pixels, qui est une grille d'entiers positifs, avec à chaque nombre attribué une couleur.
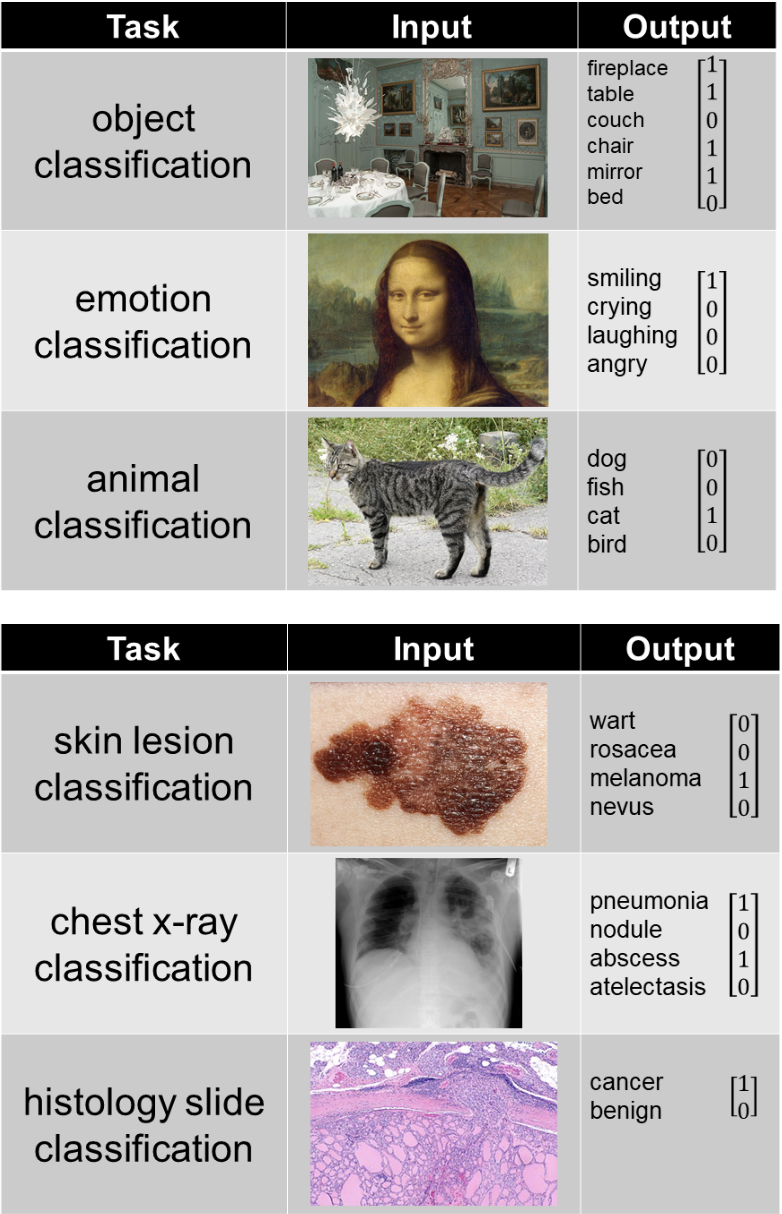
- Sortie du modèle : La sortie du modèle dépend de ce qu'il essaie de prédire, les exemples suivants représentent quelques tâches courantes :
- #🎜🎜 ##🎜🎜 #
 Un réseau neuronal convolutionnel simple se compose d'une série de couches, chaque couche divise un volume d'activation à travers un volume différentiable fonction Le bloc est converti en une autre expression. L'architecture d'un réseau neuronal convolutif utilise principalement trois types de couches : les couches convolutives, les couches de pooling et les couches entièrement connectées. La figure ci-dessous montre les différentes parties de la couche du réseau neuronal convolutif : , en utilisant des opérations d'addition et de multiplication. CNN tente d'apprendre les valeurs des filtres convolutifs pour prédire le résultat souhaité.
Un réseau neuronal convolutionnel simple se compose d'une série de couches, chaque couche divise un volume d'activation à travers un volume différentiable fonction Le bloc est converti en une autre expression. L'architecture d'un réseau neuronal convolutif utilise principalement trois types de couches : les couches convolutives, les couches de pooling et les couches entièrement connectées. La figure ci-dessous montre les différentes parties de la couche du réseau neuronal convolutif : , en utilisant des opérations d'addition et de multiplication. CNN tente d'apprendre les valeurs des filtres convolutifs pour prédire le résultat souhaité.
Non-linéarité : C'est l'équation appliquée au filtre convolutif, qui permet au CNN d'apprendre la relation complexe entre les images d'entrée et de sortie.
Pooling : Également connu sous le nom de "max pooling", il sélectionne uniquement le plus grand nombre dans une série de nombres. Cela permet de réduire la taille de l’expression et la quantité de calculs que CNN doit effectuer, améliorant ainsi l’efficacité.
La combinaison de ces trois opérations forme un réseau entièrement convolutif.- 2.2 Cas d'utilisation de CNN
- CNN (Convolutional Neural Network) est un type de réseau de neurones couramment utilisé pour résoudre des problèmes liés aux données spatiales, généralement pour les images (CNN 2D) et audio (1D CNN) et autres domaines. Le large éventail d’applications de CNN inclut la reconnaissance faciale, l’analyse et la classification médicales, etc. Grâce à CNN, des caractéristiques plus détaillées peuvent être capturées dans des données image ou audio, permettant ainsi une reconnaissance et une analyse plus précises. En outre, CNN peut également être appliqué à d’autres domaines, tels que le traitement du langage naturel et les données de séries chronologiques. Bref, CNN peut nous aider à mieux comprendre et analyser différents types de données.
- 2.3 Avantages de CNN par rapport à FCN
Dans la couche convolutive, l'entrée est une image de forme (Hin, Win, Cin) et les poids considèrent que la taille du voisinage du pixel donné est K×K. Le résultat est la somme pondérée d’un pixel donné et de ses voisins. Il existe un noyau distinct pour chaque paire (Cin, Cout) de canaux d'entrée et de sortie, mais les poids du noyau sont des tenseurs de forme indépendants de la position (K, K, Cin, Cout). En fait, cette couche peut accepter des images de n’importe quelle résolution, tandis que les couches entièrement connectées ne peuvent utiliser que des résolutions fixes. Enfin, les paramètres de couche sont (K, K, Cin, Cout). Pour le cas où la taille du noyau K est bien inférieure à la résolution d'entrée, le nombre de variables sera considérablement réduit.
Depuis qu'AlexNet a remporté le concours ImageNet, le fait que chaque réseau neuronal gagnant ait utilisé un composant CNN prouve que CNN est plus efficace pour les données d'image. Il est très probable que vous ne trouverez aucune comparaison significative car il n'est pas possible d'utiliser uniquement les couches FC pour traiter les données d'image, alors que CNN peut gérer ces données. Pourquoi?
Le nombre de poids avec 1000 neurones dans la couche FC est d'environ 150 millions pour une image. Il s'agit simplement du nombre de poids pour une couche. Les architectures CNN modernes comportent 50 à 100 couches avec un total de centaines de milliers de paramètres (par exemple, ResNet50 a 23 millions de paramètres, Inception V3 a 21 millions de paramètres).
D'un point de vue mathématique, en comparant le nombre de poids entre CNN et FCN (avec 100 unités cachées), si l'image d'entrée est de 500×500×3 :
- Wx de la couche FC = 100×(500×500 × 3)=100×750000=75M
- Couche CNN =
<code>((shape of width of the filter * shape of height of the filter * number of filters in the previous layer+1)*number of filters)( +1 是为了偏置) = (Fw×Fh×D+1)×F=(5×5×3+1)∗2=152</code>
Invariance de traduction
L'invariance signifie qu'un objet peut toujours être correctement reconnu même si sa position change. Il s’agit généralement d’une caractéristique positive car elle préserve l’identité (ou la catégorie) de l’objet. La « traduction » a ici une signification spécifique en géométrie. L'image ci-dessous montre le même objet à différents endroits et, grâce à l'invariance de traduction, CNN est capable d'identifier correctement qu'il s'agit de deux chats.
3. Réseau neuronal récurrent (RNN)
RNN est l'une des architectures de réseau de base sur lesquelles sont construites d'autres architectures d'apprentissage en profondeur. Une différence clé est que contrairement aux réseaux à réaction normale, les RNN peuvent avoir des connexions qui renvoient vers leur couche précédente ou vers la même couche. Dans un sens, RNN possède une « mémoire » des calculs précédents et utilise ces informations pour le traitement en cours.
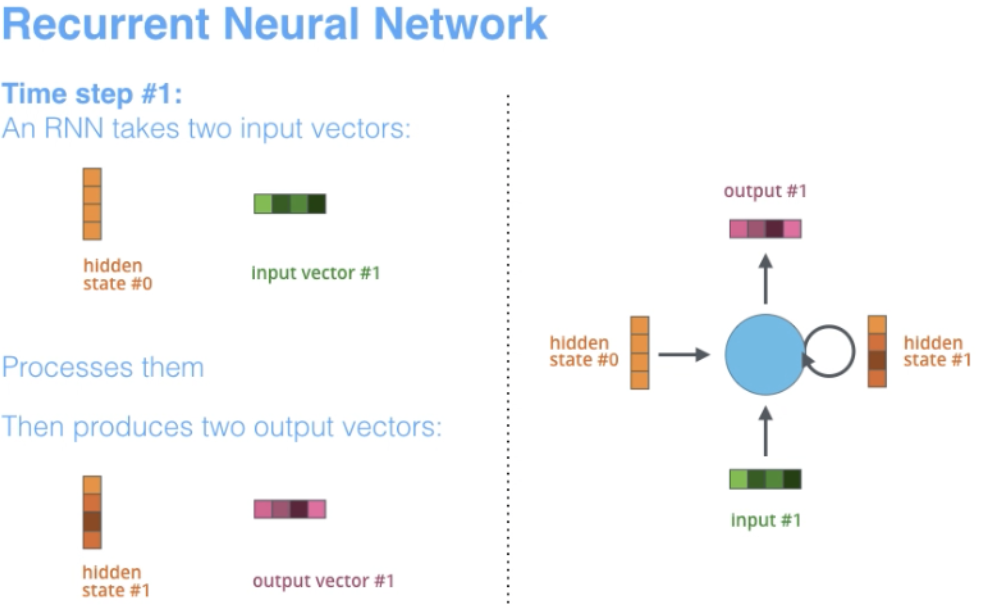
3.1 Caractéristiques architecturales de RNN
Le terme « récurrent » s'applique lorsque le réseau effectue la même tâche sur chaque instance de séquence, de sorte que la sortie dépend des calculs et des résultats précédents.
RNN convient naturellement à de nombreuses tâches de PNL, telles que la modélisation du langage. Ils sont capables de capturer la différence de signification entre "dog" et "hot dog", les RNN sont donc conçus sur mesure pour modéliser ce type de dépendance contextuelle dans les langages et les tâches de modélisation de séquences similaires, ce qui rend l'utilisation des RNN dans ces domaines plutôt que la principale raison de CNN. Un autre avantage de RNN est que la taille du modèle n'augmente pas avec la taille de l'entrée, il est donc possible de gérer des entrées de longueur arbitraire.
De plus, contrairement à CNN, RNN a des étapes de calcul flexibles, offre de meilleures capacités de modélisation et crée la possibilité de capturer un contexte illimité car il prend en compte les informations historiques et ses poids sont partagés au fil du temps. Cependant, les réseaux de neurones récurrents souffrent du problème du gradient de disparition. Le gradient devient très petit, ce qui rend les poids de mise à jour de la rétropropagation très petits. En raison du traitement séquentiel requis pour chaque étiquette et de la présence de gradients qui disparaissent/explosent, la formation RNN est lente et parfois difficile à converger.
L'image ci-dessous de l'Université de Stanford est un exemple d'architecture RNN.
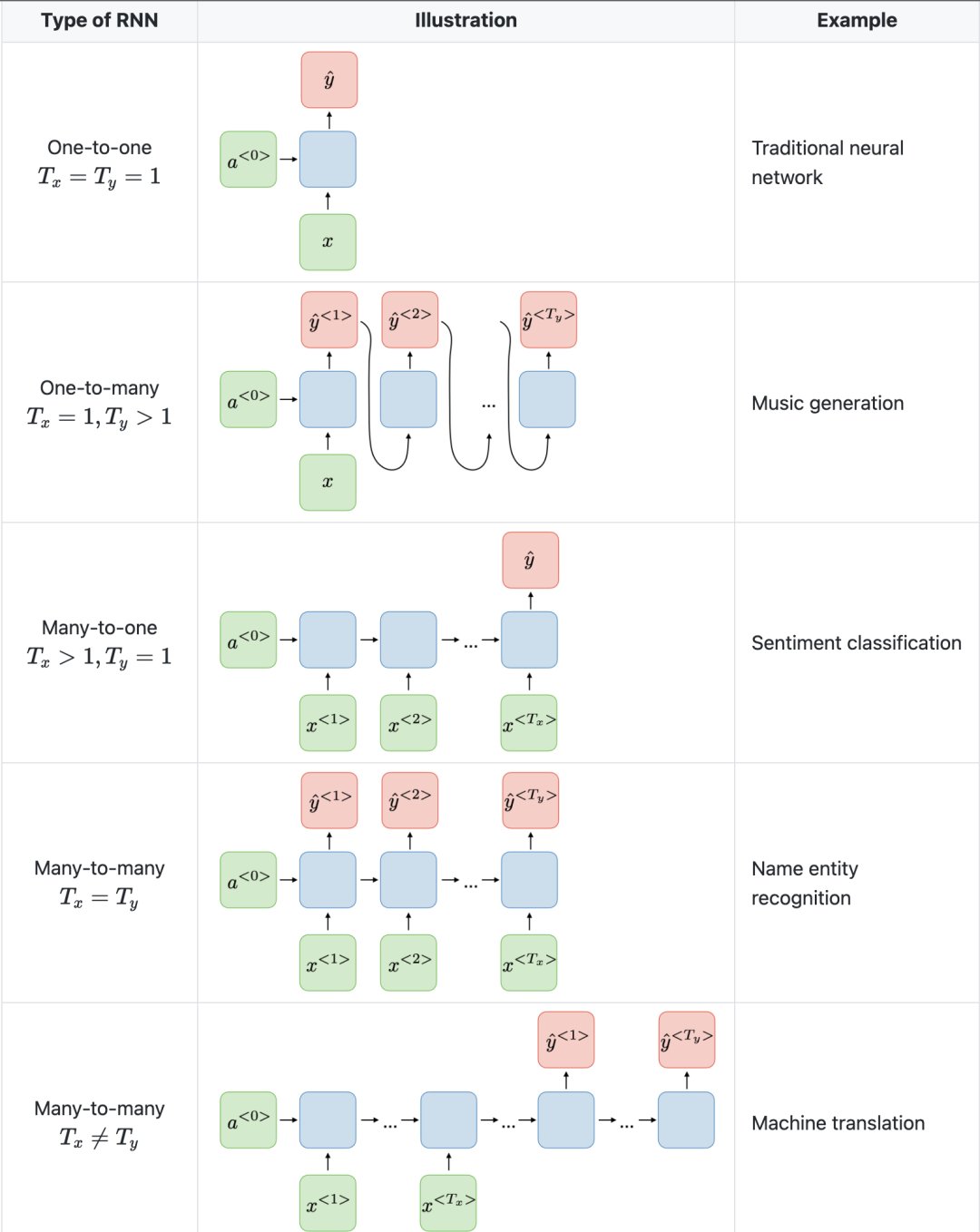
Une autre chose à noter est que CNN et RNN ont des architectures différentes. CNN est un réseau neuronal à rétroaction qui utilise des filtres et des couches de regroupement, tandis que RNN renvoie les résultats dans le réseau par autorégression.
3.2 Cas d'utilisation typiques de RNN
RNN est un réseau de neurones spécialement conçu pour analyser les données de séries chronologiques. Parmi elles, les données de séries chronologiques font référence à des données classées par ordre chronologique, telles que du texte ou des vidéos. RNN a de nombreuses applications dans la traduction de texte, le traitement du langage naturel, l'analyse des sentiments et l'analyse de la parole. Par exemple, il peut être utilisé pour analyser des enregistrements audio afin d'identifier le discours de l'orateur et de le convertir en texte. De plus, les RNN peuvent également être utilisés pour la génération de texte, par exemple pour créer du texte pour des e-mails ou des publications sur les réseaux sociaux.
3.3 Avantages comparatifs de RNN et CNN
Dans CNN, les tailles d'entrée et de sortie sont fixes. Cela signifie que CNN prend une image de taille fixe et la diffuse au niveau approprié, avec la confiance de sa prédiction. Cependant, dans RNN, les tailles d'entrée et de sortie peuvent varier. Cette fonctionnalité est utile pour les applications qui nécessitent des entrées et des sorties de taille variable, telles que la génération de texte.
Les unités récurrentes fermées (GRU) et les unités de mémoire à long terme (LSTM) fournissent des solutions au problème de gradient de disparition rencontré par les réseaux neuronaux récurrents (RNN).
4. Réseau neuronal à mémoire longue et courte (LSTM)
Le réseau neuronal à mémoire longue et courte (LSTM) est un type spécial de RNN. Cela permet aux RNN de conserver plus facilement les informations sur de nombreux horodatages en apprenant les dépendances à long terme. La figure ci-dessous est une représentation visuelle de l'architecture LSTM.
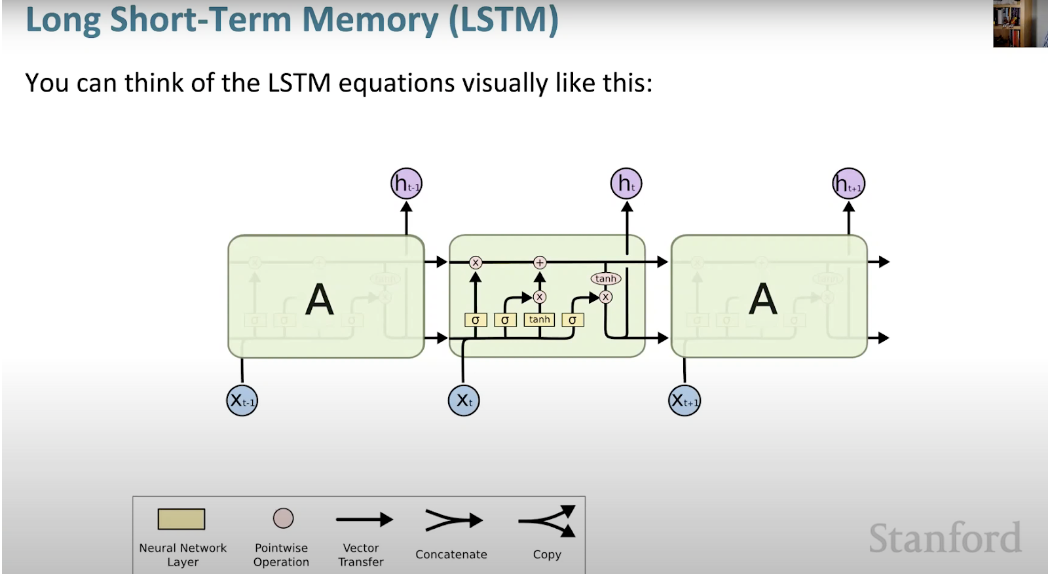
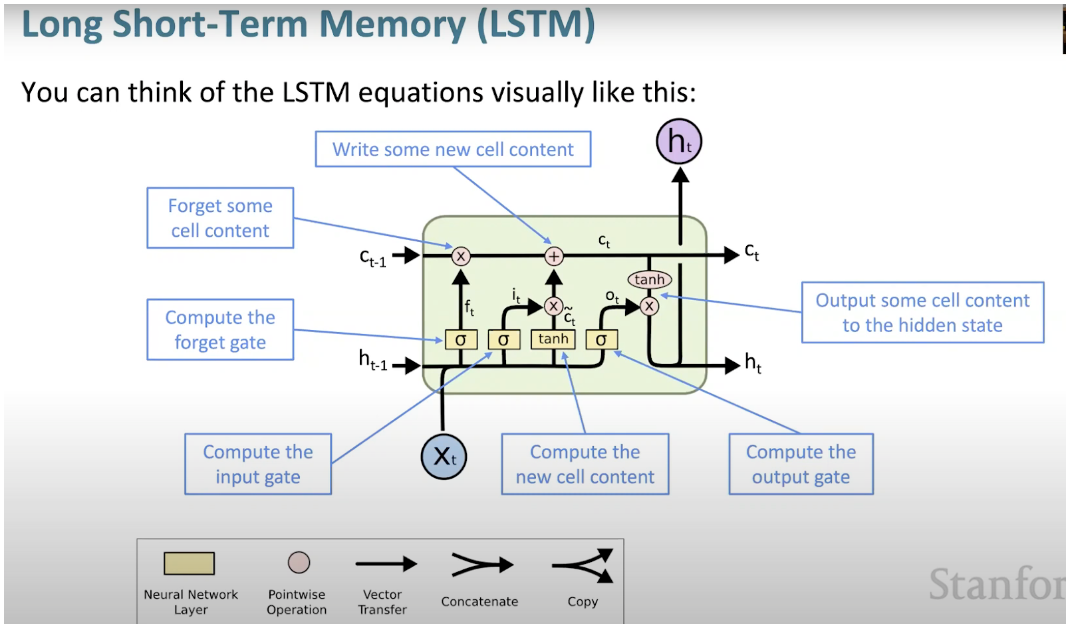
LSTM est partout et se retrouve dans de nombreuses applications ou produits, comme les smartphones. Sa puissance réside dans le fait qu’elle s’éloigne de l’architecture typique basée sur les neurones et adopte à la place le concept d’unités de mémoire. Cette unité mémoire conserve sa valeur selon la fonction de son entrée, et peut conserver sa valeur pendant une durée courte ou longue. Cela permet à l'unité de mémoriser des éléments importants, pas seulement la dernière valeur calculée.
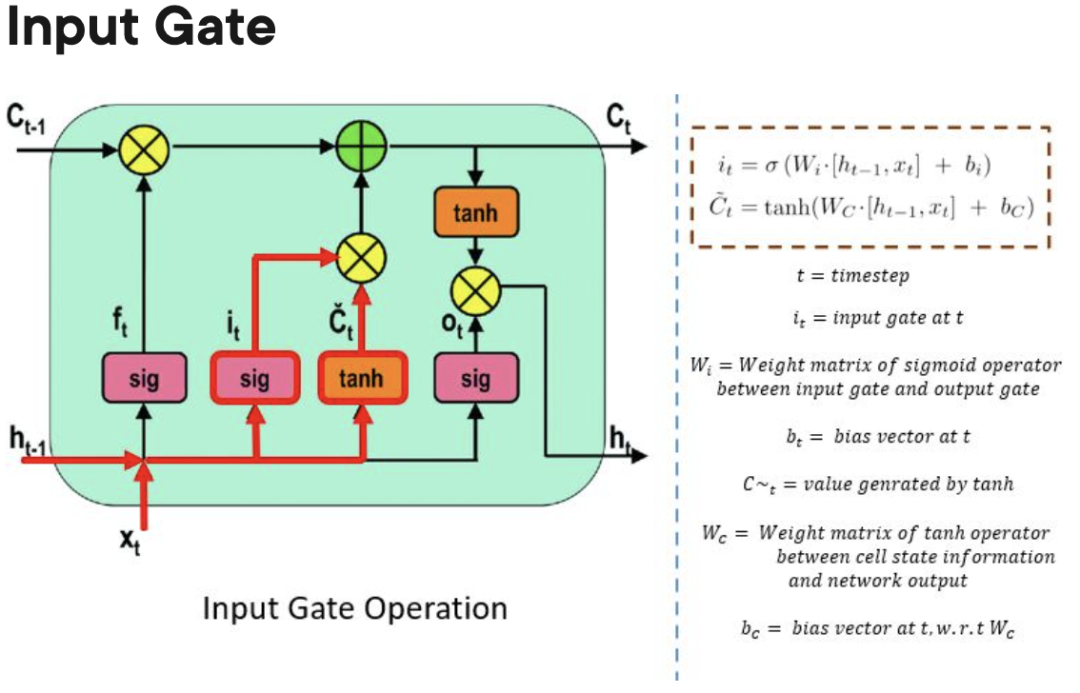
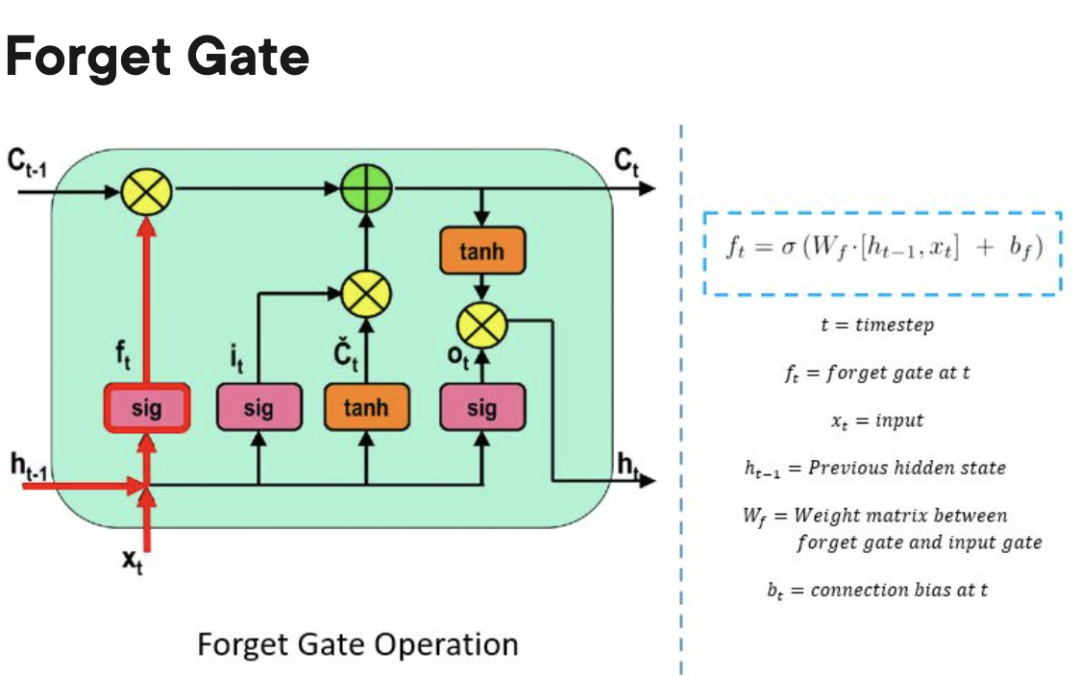
La cellule mémoire LSTM contient trois portes qui contrôlent l'entrée ou la sortie d'informations au sein de sa cellule.
- Input Gate : contrôle le moment où les informations peuvent circuler dans la mémoire.
Forgetting Gate : Responsable du suivi des informations qui peuvent être "oubliées" pour permettre à l'unité de traitement de mémoriser de nouvelles données.
Output Gate : Détermine quand les informations stockées dans l'unité de traitement peuvent être utilisées comme sortie de la cellule.
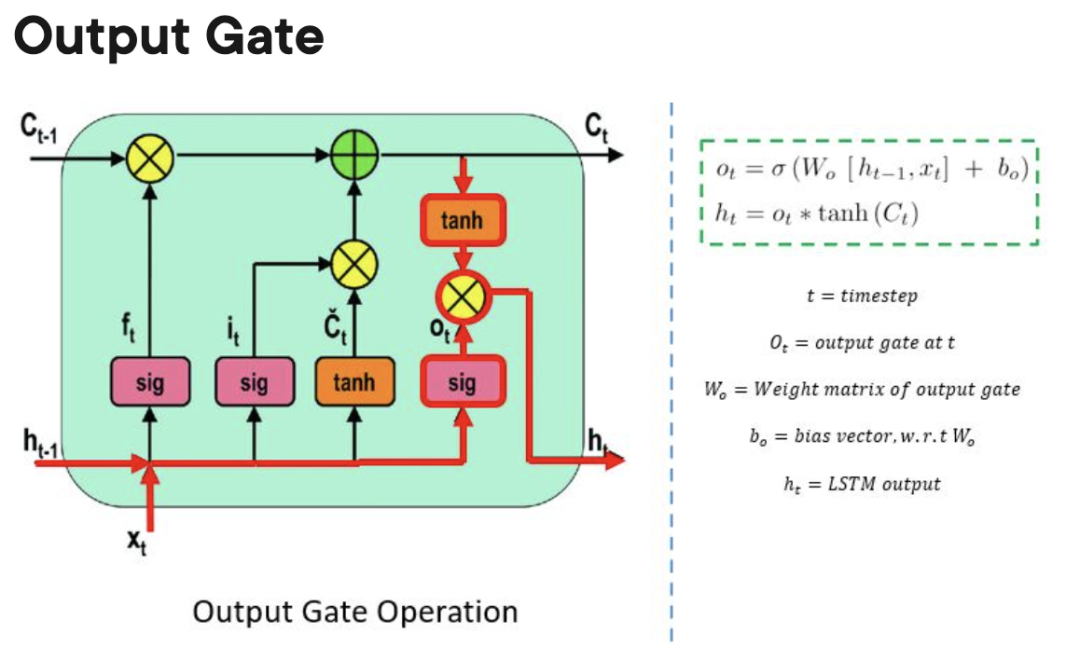
Avantages et inconvénients de LSTM par rapport à GRU et RNN
Par rapport à GRU et surtout RNN, LSTM peut apprendre des dépendances à plus long terme. Puisqu'il y a trois portes (deux dans GRU et zéro dans RNN), LSTM a plus de paramètres que RNN et GRU. Ces paramètres supplémentaires permettent au modèle LSTM de mieux gérer les données de séquence complexes, telles que les données en langage naturel ou les séries chronologiques. De plus, les LSTM peuvent également gérer des séquences d'entrée de longueur variable car leur structure de porte leur permet d'ignorer les entrées inutiles. En conséquence, LSTM fonctionne bien dans de nombreuses applications, notamment la reconnaissance vocale, la traduction automatique et les prévisions boursières.
5. Gated Recurrent Unit (GRU)
GRU a deux portes : la porte de mise à jour et la porte de réinitialisation (essentiellement deux vecteurs) pour décider quelles informations doivent être transmises à la sortie.
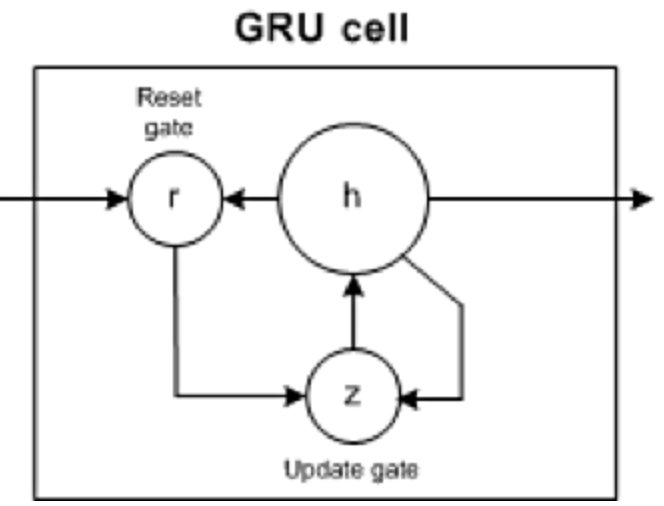
- Réinitialiser la porte : aide le modèle à décider de la quantité d'informations passées qu'il peut oublier.
- Porte de mise à jour : aide le modèle à déterminer la quantité d'informations passées (pas de temps précédents) qui doivent être transmises au futur.
GRU compare les avantages et les inconvénients de LSTM et RNN
Semblable à RNN, GRU est également un réseau neuronal récurrent qui peut efficacement conserver les informations pendant une longue période et capturer des dépendances plus longues que RNN. Cependant, GRU est plus simple et plus rapide à former que LSTM.
Bien que GRU soit plus complexe à mettre en œuvre que RNN, car il ne contient que deux mécanismes de déclenchement, il a un plus petit nombre de paramètres et ne peut généralement pas capturer des dépendances à plus longue portée comme LSTM. Par conséquent, GRU peut nécessiter davantage de données de formation dans certains cas pour atteindre le même niveau de performances que LSTM.
De plus, étant donné que GRU est relativement simple et que son coût de calcul est faible, il peut être plus approprié d'utiliser GRU dans des environnements aux ressources limitées, tels que les appareils mobiles ou les systèmes embarqués. D'un autre côté, si la précision du modèle est essentielle pour l'application, LSTM peut être un meilleur choix.
6.Transformer
L'article sur les Transformers "L'attention est tout ce dont vous avez besoin" est presque l'article numéro un jamais publié sur Arxiv. Transformer est un grand modèle d'encodeur-décodeur capable de traiter des séquences entières à l'aide de mécanismes d'attention complexes.
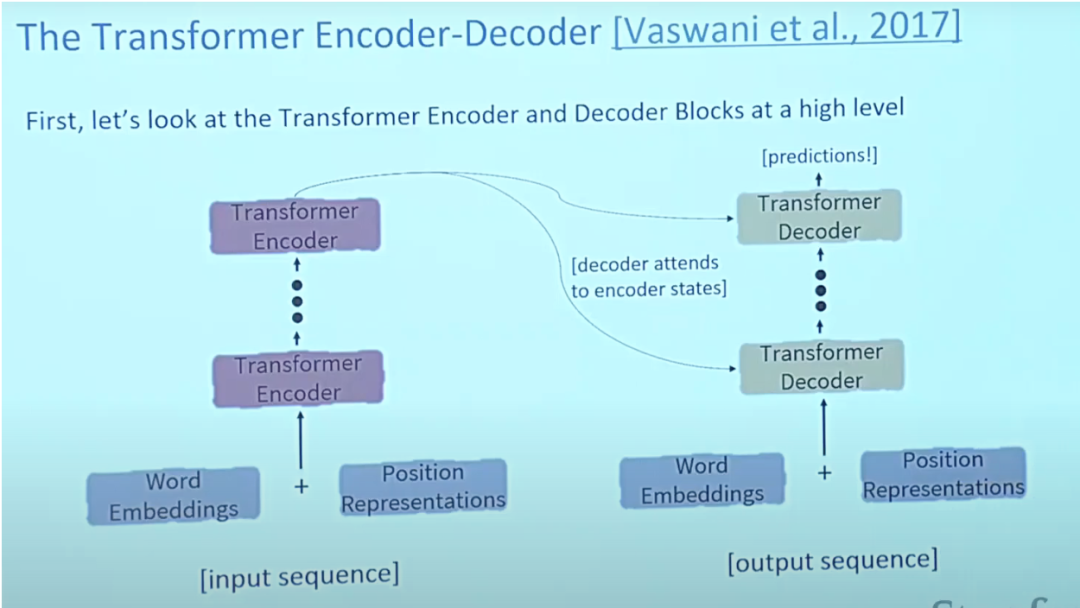
Généralement, dans les applications de traitement du langage naturel, chaque mot saisi est d'abord converti en vecteur à l'aide d'un algorithme d'intégration. L'intégration ne se produit que dans l'encodeur de niveau le plus bas. L'abstraction partagée par tous les encodeurs est qu'ils reçoivent une liste de vecteurs de taille 512, qui sera le mot incorporations, mais dans d'autres encodeurs, elle sera directement en dessous de la sortie de l'encodeur.
Attention apporte une solution au problème du goulot d'étranglement. Pour ces types de modèles, les vecteurs de contexte deviennent un goulot d'étranglement, ce qui rend difficile pour le modèle de gérer des phrases longues. L'attention permet au modèle de se concentrer sur les parties pertinentes de la séquence d'entrée selon les besoins et de traiter la représentation de chaque mot comme une requête pour accéder et combiner les informations d'un ensemble de valeurs.
6.1 Caractéristiques architecturales du Transformer
Généralement, dans l'architecture du Transformer, l'encodeur est capable de transmettre tous les états cachés au décodeur. Cependant, le décodeur utilise son attention pour effectuer une étape supplémentaire avant de générer la sortie. Le décodeur multiplie chaque état caché par son score softmax, amplifiant ainsi les états cachés ayant un score plus élevé et inondant les autres états cachés. Cela permet au modèle de se concentrer sur les parties de l’entrée qui sont pertinentes pour la sortie.
L'auto-attention est située dans l'encodeur. La première étape consiste à créer 3 vecteurs à partir de chaque vecteur d'entrée de l'encodeur (intégration de chaque mot) : les vecteurs Clé, Requête et Valeur. Ces vecteurs sont transmis aux intégrations. sont créés en multipliant les 3 matrices entraînées lors de la formation. Les dimensions K, V, Q sont de 64, tandis que les vecteurs d'entrée/sortie d'intégration et d'encodeur ont une dimension de 512. L'image ci-dessous est tirée d'Illustrated Transformer de Jay Alammar, qui est probablement la meilleure interprétation visuelle sur Internet.
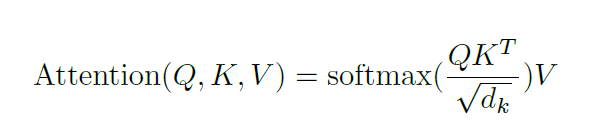
La taille de cette liste est un hyperparamètre qui peut être défini et sera essentiellement la phrase la plus longue de la formation longueur de l’ensemble de données.
- Attention :
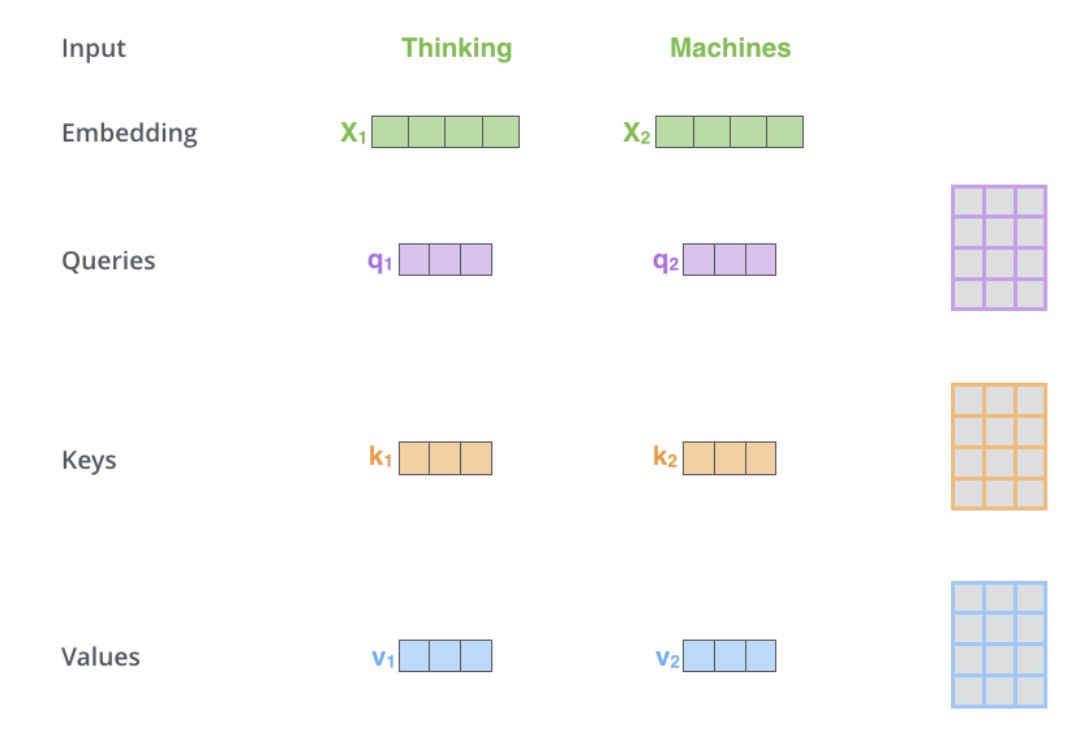
Qu'est-ce que la requête, vecteurs clés et valeurs ? Ce sont des concepts abstraits utiles pour calculer et réfléchir à l’attention. Le calcul de l’attention croisée dans le décodeur est le même que celui de l’auto-attention à l’exception de l’entrée. L’attention croisée combine asymétriquement deux séquences d’intégration indépendantes de la même dimension, tandis que l’entrée d’auto-attention est une seule séquence d’intégration.
Afin d'évoquer Transformer, il faut également évoquer deux modèles pré-entraînés, à savoir BERT et GPT, car ils ont conduit au succès de Transformer.
Le décodeur pré-entraîné de GPT comporte 12 couches, dont 768 états cachés dimensionnels, des couches cachées à feed-forward de 3072 dimensions, et est codé avec 40 000 paires d'octets fusionnés. Il est principalement utilisé dans le raisonnement en langage naturel pour marquer des paires de phrases comme implication, contradiction ou neutre.
BERT est un encodeur pré-entraîné qui utilise une modélisation de langage masqué pour remplacer une partie des mots dans l'entrée par des jetons spéciaux [MASK], puis tente de prédire ces mots. Par conséquent, la perte doit uniquement être calculée sur les mots masqués prédits. Les deux tailles de modèle BERT ont un grand nombre de couches d'encodeurs (appelées blocs Transformer dans le document) - 12 dans la version de base et 24 dans la version Large. Ceux-ci ont également des réseaux de rétroaction plus grands (768 et 1024 unités cachées respectivement) et plus que la configuration par défaut dans l'implémentation de référence de Transformer dans l'article initial (6 couches d'encodeur, 512 unités cachées et 8 têtes d'attention) de têtes d'attention (12 et 16 respectivement). ). Les modèles BERT sont faciles à affiner et peuvent généralement être réalisés sur un seul GPU. BERT peut être utilisé pour la traduction en PNL, en particulier pour la traduction dans des langues à faibles ressources.
Un inconvénient en termes de performances des Transformers est que leur temps de calcul en auto-attention est quadratique, tandis que les RNN ne croissent que linéairement.
6.2 Cas d'utilisation de Transformer
6.2.1 Domaine linguistique
Dans les modèles de langage traditionnels, les mots adjacents seront d'abord regroupés, tandis que le Transformer peut traiter en parallèle afin que chaque élément des données d'entrée puisse être connecté ou concentré sur tous les autres éléments. C’est ce qu’on appelle « l’attention personnelle ». Cela signifie que le Transformer peut voir le contenu de l'ensemble des données dès qu'il commence l'entraînement.
Avant l'émergence de Transformer, la progression des tâches de langage d'IA était dans une large mesure en retard par rapport au développement d'autres domaines. En fait, dans la révolution de l’apprentissage profond des dix dernières années, le traitement du langage naturel est arrivé tardivement et la PNL était dans une certaine mesure à la traîne par rapport à la vision par ordinateur. Cependant, avec l'émergence de Transformers, le domaine de la PNL a reçu un énorme essor et une série de modèles ont été lancés qui obtiennent de bons résultats dans diverses tâches de PNL.
Par exemple, pour comprendre la différence entre les modèles de langage traditionnels (basés sur des architectures récursives telles que RNN, LSTM ou GRU) et Transformers, on peut donner un exemple : « La chouette a repéré un écureuil et a essayé de l'attraper avec ses serres. mais n'a eu que le bout de sa queue. » La structure de la deuxième phrase prête à confusion : que signifie ce « ça » ? Les modèles de langage traditionnels qui se concentrent uniquement sur les mots entourant « cela » auraient des difficultés, mais un transformateur qui relie chaque mot à tous les autres mots peut dire qu'un hibou a attrapé un écureuil et que l'écureuil a perdu une partie de sa queue.
6.2.2 Champ de vision
À CNN, nous partons du local et obtenons progressivement la perspective globale. CNN reconnaît les images pixel par pixel en créant des caractéristiques du local au global pour identifier des caractéristiques telles que des coins ou des lignes. Cependant, dans le transformateur, grâce à l’auto-attention, des connexions entre des emplacements d’images distants sont établies même au premier niveau de traitement de l’information (tout comme le langage). Si l'approche CNN revient à mettre à l'échelle à partir d'un seul pixel, le transformateur mettra progressivement au point l'ensemble de l'image floue.

CNN génère des représentations de caractéristiques locales en appliquant à plusieurs reprises des filtres sur les correctifs locaux des données d'entrée, augmentant progressivement leur champ de vision réceptif et créant une représentation globale des caractéristiques. C’est grâce à la convolution que l’application Photos peut distinguer les poires des nuages. Avant l’architecture du transformateur, CNN était considéré comme indispensable pour les tâches de vision.
L'architecture du modèle Vision Transformer est presque identique au premier transformateur proposé en 2017, avec seulement quelques changements mineurs qui lui permettent d'analyser des images plutôt que des mots. Étant donné que le langage a tendance à être discret, l'image d'entrée doit être discrétisée pour permettre au transformateur de traiter l'entrée visuelle. Imiter exactement l’approche linguistique et effectuer une auto-attention sur chaque pixel deviendrait d’un coût prohibitif en temps de calcul. Par conséquent, ViT divise les images plus grandes en cellules carrées ou en patchs (similaires aux jetons en PNL). La taille est arbitraire car le jeton peut être plus grand ou plus petit en fonction de la résolution de l'image originale (la valeur par défaut est 16x16 pixels). Mais en traitant les pixels en groupes et en appliquant une attention personnelle à chaque pixel, ViT peut traiter rapidement d'énormes ensembles de données d'entraînement et produire des classifications de plus en plus précises.
6.2.3 Tâches multimodales
Par rapport à Transformer, d'autres architectures d'apprentissage en profondeur ne connaissent qu'une seule compétence, tandis que l'apprentissage multimodal nécessite des modalités de traitement avec différents modes dans une architecture fluide avec un biais d'induction relationnel élevé considérable peut atteindre le niveau de l'intelligence humaine. En d’autres termes, il était nécessaire de disposer d’une architecture polyvalente unique capable de faire la transition de manière transparente entre des sens tels que la lecture/le visionnage, la parole et l’écoute.
Pour les tâches multimodales, plusieurs types de données doivent être traitées simultanément, telles que des images originales, des vidéos et des langues, et Transformer offre le potentiel d'une architecture générale.
En raison de l'approche discrète adoptée dans les architectures antérieures, où chaque type de données avait son propre modèle spécifique, c'était une tâche difficile à accomplir. Cependant, les Transformers offrent un moyen simple de combiner plusieurs sources d’entrée. Par exemple, les réseaux multimodaux pourraient alimenter des systèmes capables de lire les mouvements des lèvres des gens et d'écouter leur voix en utilisant simultanément de riches représentations de langage et d'informations d'image. Grâce à une attention croisée, Transformer est capable de dériver des vecteurs de requêtes, de clés et de valeurs à partir de différentes sources, ce qui en fait un outil puissant pour l'apprentissage multimodal.
Par conséquent, Transformer est un grand pas vers la « fusion » des architectures de réseaux neuronaux, qui peut aider à réaliser un traitement universel de données modales multiples.
6.3 Avantages et inconvénients de Transformer par rapport à RNN/GRU/LSTM
Par rapport à RNN/GRU/LSTM, Transformer peut apprendre des dépendances plus longues que RNN et ses variantes (telles que GRU et LSTM).
Cependant, le plus grand avantage vient de la façon dont le Transformer se prête à la parallélisation. Contrairement à un RNN qui traite un mot à chaque pas de temps, une propriété clé du Transformer est que le mot à chaque position traverse l'encodeur via son propre chemin. Dans la couche d'auto-attention, il existe des dépendances entre ces chemins car la couche d'auto-attention calcule l'importance des autres mots dans chaque séquence d'entrée par rapport à ce mot. Cependant, une fois la sortie d'auto-attention générée, la couche feedforward n'a pas ces dépendances, de sorte que les chemins individuels peuvent s'exécuter en parallèle lorsqu'ils traversent la couche feedforward. Il s'agit d'une fonctionnalité particulièrement utile dans le cas de l'encodeur Transformer, qui traite chaque mot d'entrée en parallèle avec d'autres mots après une couche d'auto-attention. Cependant, cette fonctionnalité n’est pas très importante pour le décodeur, puisqu’il ne génère qu’un seul mot à la fois et n’utilise pas de chemins de mots parallèles.
Le temps d'exécution de l'architecture Transformer évolue quadratiquement avec la longueur de la séquence d'entrée, ce qui signifie que le traitement peut être lent lors du traitement de documents ou de caractères longs en entrée. En d'autres termes, lors de la formation de l'auto-attention, toutes les paires d'interactions doivent être calculées, ce qui signifie que le calcul croît quadratiquement avec la longueur de la séquence, c'est-à-dire O(T^2 d), où T est la longueur de la séquence et D est la dimension. Par exemple, correspondant à une phrase simple d=1000, T≤30⇒T^2≤900⇒T^2d≈900K. Et pour les nerfs circulants, sa croissance n’est que linéaire.
Ne serait-il pas bien si le Transformer n'avait pas besoin de calculer les interactions par paires entre chaque paire de mots de la phrase ? Certaines études montrent que des niveaux de performance assez élevés peuvent être atteints sans calculer les interactions entre toutes les paires de mots (par exemple en rapprochant l'attention par paire).
Par rapport à CNN, Transformer a des exigences extrêmement élevées en matière de données. Les CNN sont toujours efficaces en matière d'échantillons, ce qui en fait un excellent choix pour les tâches nécessitant peu de ressources. Cela est particulièrement vrai pour les tâches de génération d'images/vidéo, qui, même pour les architectures CNN, nécessitent de grandes quantités de données (impliquant ainsi les exigences extrêmement élevées en matière de données de l'architecture Transformer). Par exemple, l'architecture CLIP récemment proposée par Radford et al. est formée en utilisant ResNets basés sur CNN comme épine dorsale visuelle (au lieu de l'architecture Transformer de type ViT). Alors que les Transformers offrent des gains de précision une fois que leurs exigences en matière de données sont satisfaites, les CNN offrent un moyen de fournir de bonnes performances de précision dans les tâches où la quantité de données disponibles n'est pas inhabituellement élevée. Les deux architectures ont donc leur utilité.
Parce que le temps d'exécution de l'architecture Transformer a une relation quadratique avec la longueur de la séquence d'entrée. Autrement dit, l'attention informatique sur toutes les paires de mots nécessite que le nombre d'arêtes du graphique augmente quadratiquement avec le nombre de nœuds, c'est-à-dire que dans une phrase de n mots, le transformateur doit calculer n ^ 2 paires de mots. Cela signifie que le nombre de paramètres est énorme (c'est-à-dire que l'utilisation de la mémoire est élevée), ce qui entraîne une grande complexité de calcul. Des exigences informatiques élevées ont un impact négatif sur la puissance et la durée de vie de la batterie, en particulier pour les appareils mobiles. Dans l'ensemble, afin de fournir de meilleures performances (telles que la précision), Transformer nécessite une puissance de calcul plus élevée, plus de données, plus de puissance/durée de vie de la batterie et d'empreinte mémoire.
7. Biais d'inférence
Chaque algorithme d'apprentissage automatique utilisé dans la pratique, des voisins les plus proches à l'augmentation de gradient, a son propre biais inductif quant aux catégories les plus faciles à apprendre. Presque tous les algorithmes d’apprentissage ont tendance à apprendre que les éléments similaires (« proches » les uns des autres dans certains espaces de fonctionnalités) sont plus susceptibles d’appartenir à la même classe. Les modèles linéaires, tels que la régression logistique, supposent également que les catégories peuvent être séparées par des limites linéaires, ce qui constitue un biais « dur » car le modèle ne peut rien apprendre d'autre. Même pour la régression régularisée, qui est presque toujours le type utilisé dans l'apprentissage automatique, il existe un biais en faveur des limites d'apprentissage impliquant un petit nombre de fonctionnalités, avec de faibles poids de fonctionnalités. Il s'agit d'un biais « doux » car le modèle peut apprendre implique de nombreuses classes. limites avec des caractéristiques de poids élevé, mais cela est plus difficile/nécessite plus de données.
Même les modèles d'apprentissage profond ont des biais d'inférence. Par exemple, le réseau neuronal LSTM est très efficace pour les tâches de traitement du langage naturel car il préfère conserver les informations contextuelles sur de longues séquences.

Comprendre la connaissance du domaine et la difficulté des problèmes peut nous aider à choisir des applications d'algorithmes appropriées. Par exemple, le problème de l’extraction des termes pertinents des dossiers cliniques pour déterminer si un patient a reçu un diagnostic de cancer. Dans ce cas, la régression logistique fonctionne bien car il existe de nombreux termes informatifs indépendants. Pour d’autres problèmes, tels que l’extraction des résultats d’un test génétique à partir d’un rapport PDF complexe, l’utilisation de LSTM permet de mieux gérer le contexte à long terme de chaque mot, ce qui entraîne de meilleures performances. Une fois qu'un algorithme de base a été choisi, comprendre ses biais peut également nous aider à réaliser l'ingénierie des fonctionnalités, le processus de sélection des informations à alimenter dans un algorithme d'apprentissage.
Chaque structure de modèle possède un biais d'inférence inhérent qui aide à comprendre les modèles dans les données, permettant ainsi l'apprentissage. Par exemple, CNN présente le partage de paramètres spatiaux et l'invariance de traduction/spatiale, tandis que RNN présente le partage de paramètres temporels.
8. Résumé
L'ancien codeur a essayé de comparer et d'analyser Transformer, CNN, RNN/GRU/LSTM dans une architecture d'apprentissage en profondeur, et a compris que Transformer peut apprendre des dépendances plus longues, mais nécessite des exigences de données et une puissance de calcul plus élevées. adapté aux tâches multimodales et peut basculer de manière transparente entre des sens tels que lire/regarder, parler et écouter ; chaque structure de modèle possède un biais d'inférence inhérent pour aider à comprendre les modèles dans les données, permettant ainsi l'apprentissage ;
【Référence】
- CNN vs réseau entièrement connecté pour la reconnaissance d'images ?, https://stats.stackexchange.com/questions/341863/cnn-vs-fully-connected-network-for-image-recognition
- https ://web.stanford.edu/class/archive/cs/cs224n/cs224n.1184/lectures/lecture12.pdf
- Introduction aux unités LSTM dans RNN, https://www.pluralsight.com/guides/introduction- to -lstm-units-in-rnn
- Apprentissage de modèles visuels transférables à partir de la supervision du langage naturel, https://arxiv.org/abs/2103.00020
- Linformer : auto-attention avec complexité linéaire, https://arxiv.org/ abs /2006.04768
- Repenser l'attention avec les artistes interprètes ou exécutants, https://arxiv.org/abs/2009.14794
- Big Bird : Transformers for Longer Sequences, https://arxiv.org/abs/2007.14062
- Synthesizer : Repenser l'attention personnelle dans Modèles de transformateurs, https://arxiv.org/abs/2005.00743
- Les transformateurs de vision ressemblent-ils à des réseaux de neurones convolutifs ?, https://arxiv.org/abs/2108.08810
- Illustrated Transformer, https://jalammar.github . io/transformateur-illustré/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Cette semaine, FigureAI, une entreprise de robotique investie par OpenAI, Microsoft, Bezos et Nvidia, a annoncé avoir reçu près de 700 millions de dollars de financement et prévoit de développer un robot humanoïde capable de marcher de manière autonome au cours de la prochaine année. Et l’Optimus Prime de Tesla a reçu à plusieurs reprises de bonnes nouvelles. Personne ne doute que cette année sera celle de l’explosion des robots humanoïdes. SanctuaryAI, une entreprise canadienne de robotique, a récemment lancé un nouveau robot humanoïde, Phoenix. Les responsables affirment qu’il peut accomplir de nombreuses tâches de manière autonome, à la même vitesse que les humains. Pheonix, le premier robot au monde capable d'accomplir des tâches de manière autonome à la vitesse d'un humain, peut saisir, déplacer et placer avec élégance chaque objet sur ses côtés gauche et droit. Il peut identifier des objets de manière autonome
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
