
 Périphériques technologiques
IA
Six capteurs inertiels et un téléphone portable réalisent la capture des mouvements du corps humain, le positionnement et la reconstruction de l'environnement
Périphériques technologiques
IA
Six capteurs inertiels et un téléphone portable réalisent la capture des mouvements du corps humain, le positionnement et la reconstruction de l'environnement
Six capteurs inertiels et un téléphone portable réalisent la capture des mouvements du corps humain, le positionnement et la reconstruction de l'environnement

Cet article tente d'ouvrir les "yeux" de la capture de mouvement inertielle. En portant une caméra téléphonique supplémentaire, notre algorithme a une « vision ». Il peut détecter des informations environnementales tout en capturant les mouvements humains, obtenant ainsi un positionnement précis du corps humain. Cette recherche provient de l'équipe de Xu Feng de l'Université Tsinghua et a été acceptée par SIGGRAPH2023, la plus grande conférence internationale dans le domaine de l'infographie.

- Adresse papier : https://arxiv.org/abs/2305.01599
- Page d'accueil du projet : https://xinyu-yi.github.io/EgoLocate/
- Code source ouvert : https://github.com/Xinyu-Yi/EgoLocate
Introduction
Avec le développement de la technologie informatique, la perception du corps humain et la perception de l'environnement sont devenues deux éléments indispensables dans les applications intelligentes modernes. La technologie de détection du corps humain peut réaliser une interaction homme-machine, des soins médicaux intelligents, des jeux et d'autres applications en capturant les mouvements et les actions du corps humain. La technologie de perception de l'environnement peut réaliser des applications telles que la reconstruction tridimensionnelle, l'analyse de scènes et la navigation intelligente en reconstruisant des modèles de scène. Les deux tâches sont interdépendantes, mais la plupart des technologies existantes en Allemagne et à l’étranger les accomplissent de manière indépendante. L’équipe de recherche estime que la perception combinée du mouvement humain et de l’environnement est très importante pour les scénarios dans lesquels les humains interagissent avec l’environnement. Premièrement, la détection simultanée du corps humain et de l’environnement peut améliorer l’efficacité et la sécurité de l’interaction humaine avec l’environnement. Par exemple, dans les voitures autonomes, la détection simultanée du comportement du conducteur et de l'environnement environnant peut mieux garantir la sécurité et la douceur de la conduite. Deuxièmement, la perception simultanée du corps humain et de l'environnement peut atteindre un niveau plus élevé d'interaction homme-machine. Par exemple, dans la réalité virtuelle et la réalité augmentée, la perception simultanée des actions de l'utilisateur et de l'environnement environnant peut mieux réaliser une expérience immersive. . Par conséquent, la perception simultanée du corps humain et de l’environnement peut nous apporter une expérience d’interaction homme-machine et d’application environnementale plus efficace, plus sûre et plus intelligente. Sur cette base, L'équipe de Xu Feng de l'Université Tsinghua a proposé une technologie simultanée de capture de mouvement humain, de positionnement et de cartographie de l'environnement en temps réel en utilisant seulement 6 capteurs inertiels (IMU) et 1 caméra couleur monoculaire
(comme le montre le photo montrée en 1). La technologie de capture de mouvement inertiel (mocap) explore les informations « internes » telles que les signaux de mouvement du corps humain, tandis que la technologie de localisation et de cartographie simultanées (SLAM) s'appuie principalement sur des informations « externes », c'est-à-dire l'environnement capturé par la caméra. Le premier a une bonne stabilité, mais comme il n'y a pas de référence externe correcte, la dérive de la position globale s'accumulera lors de mouvements à long terme ; le second peut estimer la position globale dans la scène avec une grande précision, mais lorsque les informations environnementales ne sont pas fiables (comme par exemple). pas de texture ou il y a une occlusion), il est facile de perdre le suivi.Cet article combine donc efficacement ces deux technologies complémentaires (mocap et SLAM). Un positionnement humain et une reconstruction de cartes robustes et précis sont obtenus grâce à la fusion des mouvements humains antérieurs et du suivi visuel sur plusieurs algorithmes clés.
Figure 1 Cet article propose une technologie simultanée de capture de mouvement humain et de cartographie de l'environnement
Plus précisément, cette étude porte 6 IMU sur les membres humains, la tête et le dos, une caméra couleur monoculaire est fixé sur la tête et tire vers l'extérieur. Cette conception s'inspire du comportement humain réel : lorsque les humains se trouvent dans un nouvel environnement, ils observent l'environnement à travers leurs yeux et déterminent leur position, planifiant ainsi leurs mouvements au sein de la scène.
Dans notre système, la caméra monoculaire agit comme l'œil humain, fournissant des signaux visuels pour la reconstruction de la scène en temps réel et l'auto-positionnement pour cette technologie, tandis que l'IMU mesure le mouvement des membres et de la tête humains. Cette configuration est compatible avec l'équipement VR existant et peut utiliser la caméra du casque VR et une IMU supplémentaire pour effectuer une capture de mouvement stable et sans dérive du corps entier et une perception de l'environnement.Pour la première fois, l'ensemble du système réalise simultanément une capture de mouvement humain et une reconstruction de points clairsemés de l'environnement sur la base de seulement 6 IMU et 1 caméra. La vitesse de fonctionnement atteint 60 ips sur le processeur, et la précision dépasse les technologies les plus avancées dans les deux domaines. en même temps.
Des exemples en temps réel de ce système sont présentés dans les figures 2 et 3.
Figure 2 Dans le mouvement complexe de 70 mètres, ce système suit avec précision la position du corps humain et capture les mouvements du corps humain sans dérive de position évidente.

Figure 3 Le système est reconstruit en même temps, des exemples en temps réel de mouvements humains et de points clairsemés de scènes.
Présentation de la méthode
#🎜🎜 #
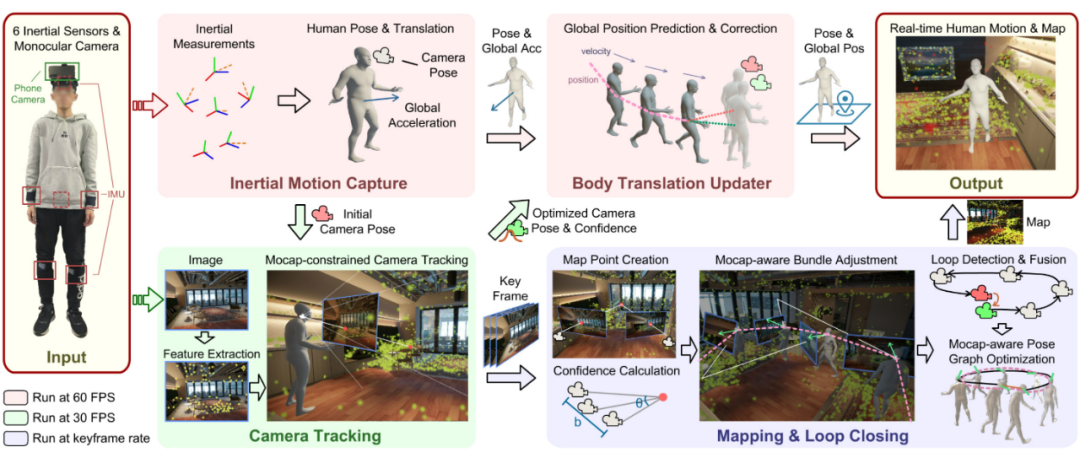 Figure 4 Processus global de la méthode
Figure 4 Processus global de la méthode
La tâche du système est d'obtenir l'orientation et l'accélération de les 6 capteurs IMU Le mouvement du corps humain et les nuages de points clairsemés de scènes tridimensionnelles sont reconstruits en temps réel à partir des valeurs mesurées et des images couleur prises par la caméra, et la position de la personne dans la scène est localisée. Nous concevons un cadre profondément couplé pour exploiter pleinement les avantages complémentaires des technologies de capture de mouvement inertielle clairsemée et de SLAM. Dans ce cadre, les priorités de mouvement humain sont combinées avec plusieurs composants clés du SLAM, et les résultats de positionnement du SLAM sont également réinjectés dans la capture du mouvement humain. Comme le montre la figure 4, selon les fonctions, nous divisons le système en quatre modules : module de capture de mouvement inertiel (Inertial Motion Capture), module de suivi de caméra (Camera Tracking
), module de détection de cartographie et de fermeture de boucle (Mapping & Loop Closing) et module de mise à jour du mouvement humain (Body Translation Updater). Chaque module est présenté ci-dessous. Capture de mouvement inertielLe module de capture de mouvement inertiel estime la posture et le mouvement humains à partir de 6 mesures IMU. La conception de ce module est basée sur nos précédents travaux PIP [1], mais dans ce travail, nous ne supposons plus que la scène est un sol plat, mais envisageons de capturer le mouvement humain libre dans un espace 3D. À cette fin, cet article apporte des modifications adaptatives à l'algorithme d'optimisation PIP.
Plus précisément, ce module prédit d'abord la rotation des articulations humaines, la vitesse, la probabilité de contact avec le pied et le sol à partir des mesures de l'IMU via un réseau neuronal récurrent à plusieurs étages. Le double contrôleur PD proposé par PIP est utilisé pour résoudre le contrôle optimal de l'accélération angulaire
et de l'accélération linéaire des articulations du corps humain. Par la suite, ce module optimise l'accélération de la posture du corps humain 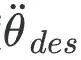 pour réaliser un contrôle de la DP tout en satisfaisant les contraintes de contact
pour réaliser un contrôle de la DP tout en satisfaisant les contraintes de contact 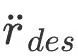 C Accélération donnée par l'appareil :
C Accélération donnée par l'appareil : 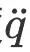
Parmi eux, 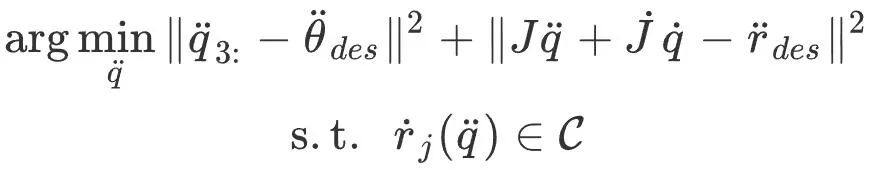 J
J
est la vitesse linéaire du pied en contact avec le sol, et la contrainte #🎜 🎜#C La vitesse du pied touchant le sol doit être faible (aucun glissement ne se produit). Pour résoudre ce problème de programmation quadratique, veuillez vous référer à PIP[1]. Après avoir obtenu la posture et le mouvement du corps humain grâce à l'intégration de l'accélération de la posture, la posture de la caméra liée au corps humain peut être obtenue pour les modules suivants. Le module de suivi de la caméra prend la pose initiale de la caméra donnée par le module de capture de mouvement inertiel et l'image couleur capturée par la caméra en entrée, et utilise les informations de l'image pour optimiser la pose de la caméra. Plus précisément, ce module est conçu sur la base d'ORB-SLAM3 [2]. Il extrait d'abord les points caractéristiques ORB de l'image et effectue la correspondance des caractéristiques avec les points de la carte clairsemée reconstruite (décrits ci-dessous) en utilisant la similarité des caractéristiques pour obtenir un point 2D-3D correspondant. paires , puis optimisez la pose de la caméra en optimisant l’erreur de reprojection. Il convient de noter que l’optimisation uniquement de l’erreur de reprojection peut être affectée par de fausses correspondances, conduisant à de mauvais résultats d’optimisation de la pose de la caméra. Par conséquent, Cet article intègre les informations préalables sur le mouvement humain dans l'optimisation du suivi de la caméra, utilise les résultats de la capture de mouvement inertiel comme contraintes, limite le processus d'optimisation des erreurs de reprojection et découvre et élimine en temps opportun les points caractéristiques erronés - Carte Cliquez pour correspond . Mémorisez les coordonnées mondiales du point de la carte comme pour représenter la pose initiale de la caméra avant l'optimisation, puis ce module optimise la pose de la caméra R " #Parmi eux, 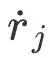
Suivi de la caméra
 , et les pixels de l'image 2D correspondante points caractéristiques Les coordonnées sont
, et les pixels de l'image 2D correspondante points caractéristiques Les coordonnées sont 
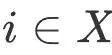 indiquant toutes les relations correspondantes. Utilisez
indiquant toutes les relations correspondantes. Utilisez 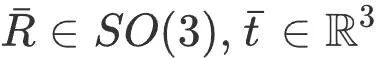
mappe la rotation tridimensionnelle à l'espace vectoriel tridimensionnel, #🎜 🎜##🎜🎜 #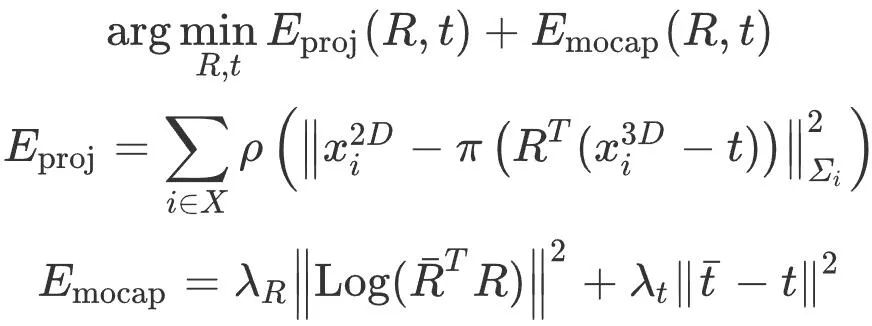 est l'opération de projection en perspective,
est l'opération de projection en perspective,
est le coefficient de contrôle des éléments de rotation et de translation de capture de mouvement. Cette optimisation est effectuée trois fois, en classant à chaque fois les correspondances 2D-3D comme correctes ou incorrectes en fonction de l'erreur de reprojection. Lors de l'optimisation suivante, seules les correspondances correctes sont utilisées et les correspondances incorrectes sont supprimées. Grâce à de solides connaissances préalables fournies par les contraintes de capture de mouvement, cet algorithme peut mieux distinguer les correspondances correctes et incorrectes, améliorant ainsi la précision du suivi de la caméra. Après avoir résolu la pose de la caméra, ce module extrait le nombre de paires de points de carte correctement appariées et l'utilise comme crédibilité de la pose de la caméra.
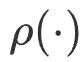 Cartographie et détection en boucle fermée
Cartographie et détection en boucle fermée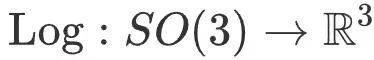 Le module de cartographie et de détection en boucle fermée utilise des images clés pour reconstruire des points de carte clairsemés et détecter si un corps humain est présent. Atteindre un emplacement précédemment visité pour corriger l'erreur accumulée. Pendant le processus de cartographie, nous utilisons ajustement de l'ensemble contraint de capture de mouvement (Ajustement de l'ensemble, BA) pour optimiser simultanément les positions des points de carte clairsemés et les poses de caméra par images clés, et introduire la confiance des points de carte pour équilibrer dynamiquement la force relative de le terme de contrainte de capture de mouvement et le terme d'erreur de reprojection
Le module de cartographie et de détection en boucle fermée utilise des images clés pour reconstruire des points de carte clairsemés et détecter si un corps humain est présent. Atteindre un emplacement précédemment visité pour corriger l'erreur accumulée. Pendant le processus de cartographie, nous utilisons ajustement de l'ensemble contraint de capture de mouvement (Ajustement de l'ensemble, BA) pour optimiser simultanément les positions des points de carte clairsemés et les poses de caméra par images clés, et introduire la confiance des points de carte pour équilibrer dynamiquement la force relative de le terme de contrainte de capture de mouvement et le terme d'erreur de reprojection 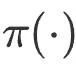 , améliorant ainsi la précision des résultats. Lorsqu'une boucle fermée se produit dans le mouvement humain, une optimisation du graphique de pose assistée par capture de mouvement
, améliorant ainsi la précision des résultats. Lorsqu'une boucle fermée se produit dans le mouvement humain, une optimisation du graphique de pose assistée par capture de mouvement  est effectuée pour corriger l'erreur de boucle fermée . Enfin, les positions optimisées des points de carte clairsemées et les poses d'images clés sont obtenues, qui sont utilisées pour exécuter l'algorithme dans l'image suivante.
est effectuée pour corriger l'erreur de boucle fermée . Enfin, les positions optimisées des points de carte clairsemées et les poses d'images clés sont obtenues, qui sont utilisées pour exécuter l'algorithme dans l'image suivante.
Plus précisément, ce module calcule d'abord la confiance du point de la carte en fonction de la situation d'observation, qui est utilisée pour l'optimisation BA ultérieure. Comme le montre la figure 5 ci-dessous, en fonction de l'emplacement de l'image clé du point de carte observé, ce module calcule la longueur de base de l'image clé bi et l'angle d'observation θi pour déterminer la confiance 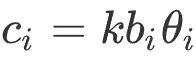 du point de carte i, où k est le coefficient de contrôle.
du point de carte i, où k est le coefficient de contrôle.
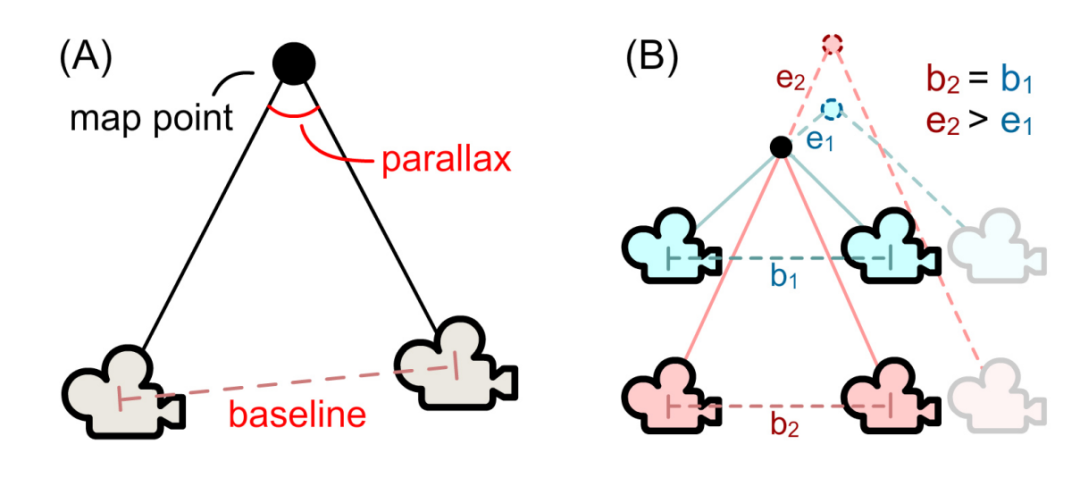
Figure 5 (a) Calcul de la confiance des points de la carte. (b) Avec la même longueur de base b1 = b2, un angle d'observation plus grand (bleu) peut mieux résister à la perturbation de la pose de la caméra, ce qui entraîne des erreurs de position des points sur la carte plus petites (e1
Ensuite, optimisez simultanément les poses de caméra des 20 dernières images clés et leurs points de carte observés. Les autres poses d'images clés qui voient ces points de la carte sont corrigées lors de l'optimisation. Désignons l'ensemble de toutes les images clés optimisables par K0, l'ensemble de toutes les images clés fixes par Kf et l'ensemble des points cartographiques mesurés par l'image clé j par Xj. note
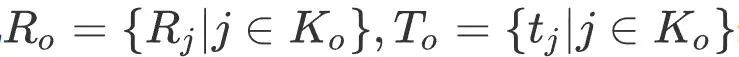
représente l'orientation de l'image clé et la position tridimensionnelle qui doivent être optimisées, et
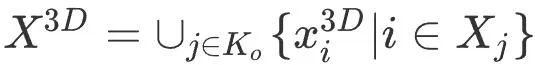
représente l'emplacement du point sur la carte. Ensuite, l'optimisation de l'ajustement du faisceau de la contrainte de capture de mouvement est définie comme :
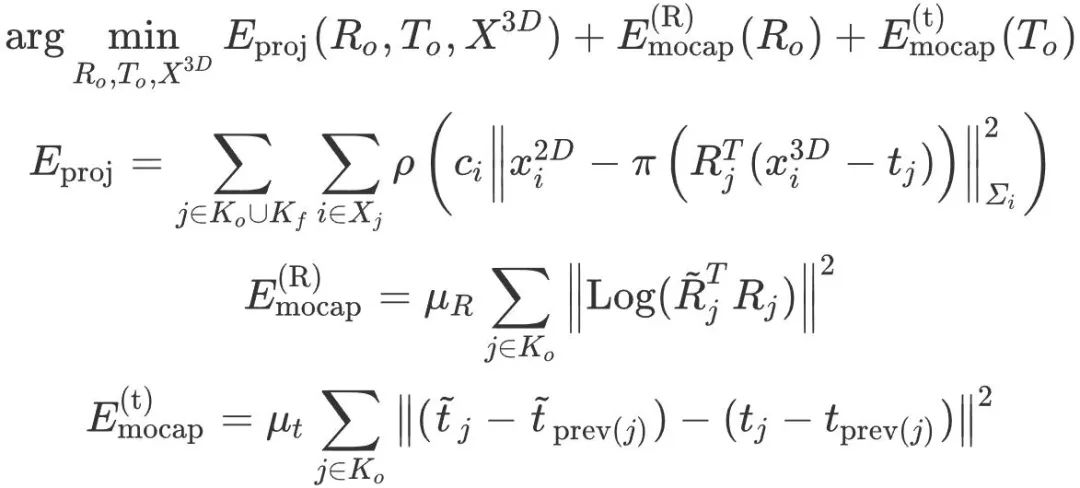
où,
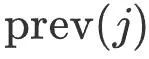
représente l'image clé précédente de l'image clé j,
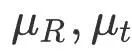
est le coefficient de la contrainte de capture de mouvement. Cette optimisation nécessite que l'erreur de reprojection des points de la carte soit faible et que la rotation et la position relative de chaque image clé soient proches des résultats de la capture de mouvement. La confiance des points de la carte ci détermine dynamiquement les contraintes de capture de mouvement et le point de la carte. reprojection La relation de poids relatif entre les éléments : Pour les zones qui n'ont pas été entièrement reconstruites, le système est plus susceptible de croire aux résultats de la capture de mouvement, à l'inverse, si une zone est observée à plusieurs reprises, le système est plus susceptible de croire ; en suivi visuel. La représentation optimisée du graphique factoriel est présentée dans la figure 6 ci-dessous.
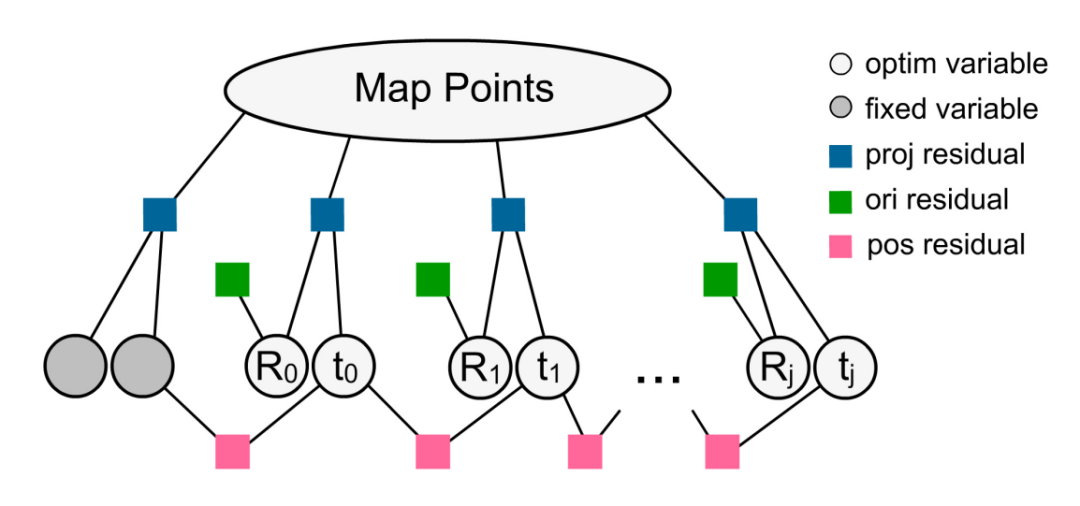
Figure 6 Représentation graphique du facteur d'optimisation de la méthode d'ajustement du faisceau pour les contraintes de capture de mouvement.
Lorsque la boucle fermée de la trajectoire est détectée, le système effectue une optimisation en boucle fermée. Basé sur ORB-SLAM3 [2], l’ensemble des sommets du graphe de pose est F et l’ensemble des arêtes est C. Ensuite, l'optimisation du graphe de pose des contraintes de capture de mouvement est définie comme :
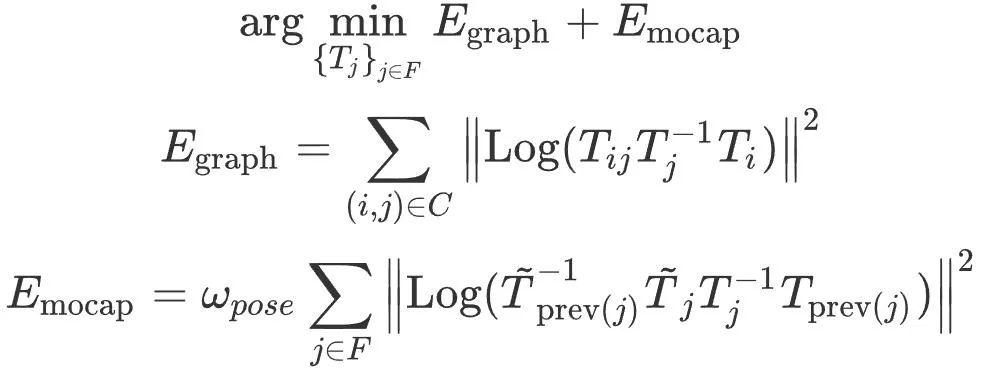
Parmi eux, 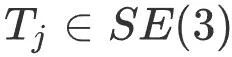 est la pose de l'image clé j,
est la pose de l'image clé j, 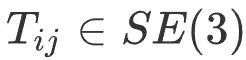 est la pose map Optimiser la pose relative entre les images clés i et j avant,
est la pose map Optimiser la pose relative entre les images clés i et j avant, 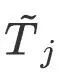 est la valeur initiale de la pose de la caméra obtenue par capture de mouvement,
est la valeur initiale de la pose de la caméra obtenue par capture de mouvement, 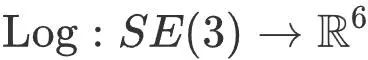 will La pose est mappée sur un espace vectoriel à six dimensions, et
will La pose est mappée sur un espace vectoriel à six dimensions, et 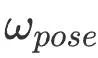 est le coefficient relatif de la contrainte de capture de mouvement. Cette optimisation est guidée par la capture de mouvement préalable et disperse l'erreur en boucle fermée sur chaque image clé.
est le coefficient relatif de la contrainte de capture de mouvement. Cette optimisation est guidée par la capture de mouvement préalable et disperse l'erreur en boucle fermée sur chaque image clé.
Mise à jour des mouvements humains
Le module de mise à jour des mouvements humains est optimisé grâce au suivi de la caméra module Pose de la caméra et crédibilité, mise à jour de la position globale du corps humain donnée par le module de capture de mouvement. Ce module est implémenté à l'aide de l'algorithme de prédiction-correction du filtre de Kalman. Parmi eux, le module de capture de mouvement fournit une variation constante de l'accélération du mouvement du corps humain, qui peut être utilisée pour prédire la position globale du corps humain (distribution préalable), tandis que le module de suivi de la caméra fournit des observations et une confiance en la position de la caméra, qui est utilisée pour corriger la position globale du corps humain (distribution postérieure). Parmi eux, la matrice de covariance de l'observation de la position de la caméra 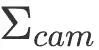 est calculée approximativement par le nombre de points de carte correspondants comme la matrice diagonale suivante :
est calculée approximativement par le nombre de points de carte correspondants comme la matrice diagonale suivante :
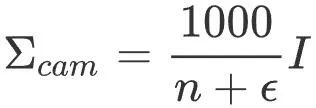
ExperimentComparison Mocap Cette méthode résout principalement la position globale en capture de mouvement inertiel clairsemé (Mocap) Pour résoudre le problème de la dérive, l'indicateur de test principal est sélectionné comme erreur de position globale du corps humain. La comparaison des résultats des tests quantitatifs des méthodes SOTA mocap TransPose[3], TIP[4] et PIP[1] sur les deux ensembles de données publiques de TotalCapture et HPS est présentée dans le tableau 1 ci-dessous. est représenté sur les figures 7 et 8 ci-dessous. On peut voir que la méthode décrite dans cet article dépasse largement la méthode de capture de mouvement inertielle précédente en termes de précision de positionnement global (amélioration de 41 % et 38 % de TotalCapture et HPS respectivement), et la trajectoire présente la plus grande similitude avec la valeur réelle.
Cette méthode résout principalement la position globale en capture de mouvement inertiel clairsemé (Mocap) Pour résoudre le problème de la dérive, l'indicateur de test principal est sélectionné comme erreur de position globale du corps humain. La comparaison des résultats des tests quantitatifs des méthodes SOTA mocap TransPose[3], TIP[4] et PIP[1] sur les deux ensembles de données publiques de TotalCapture et HPS est présentée dans le tableau 1 ci-dessous. est représenté sur les figures 7 et 8 ci-dessous. On peut voir que la méthode décrite dans cet article dépasse largement la méthode de capture de mouvement inertielle précédente en termes de précision de positionnement global (amélioration de 41 % et 38 % de TotalCapture et HPS respectivement), et la trajectoire présente la plus grande similitude avec la valeur réelle.
Tableau 1 et capture de mouvement inertiel Comparaison quantitative des erreurs de position globale des travaux (unité : mètres). L'ensemble de données TotalCapture est classé par actions et l'ensemble de données HPS est classé par scènes. Pour notre travail, nous testons 9 fois et rapportons la médiane et l'écart type.

Figure 7 Comparaison qualitative de l'erreur de position globale avec le travail de capture de mouvement inertiel. La vraie valeur est affichée en vert et les résultats de prédiction des différentes méthodes sont affichés en bleu. La trajectoire du mouvement et la position actuelle du corps humain (points orange) sont indiquées dans le coin de chaque image.
Figure 8 Comparaison qualitative de l'erreur de position globale avec un travail de capture de mouvement inertiel (vidéo). La vraie valeur est affichée en vert, la méthode décrite dans cet article est en blanc et les méthodes des travaux précédents utilisent d'autres couleurs différentes (voir légende).
Comparaison avec SLAM
Cet article compare les versions monoculaire et monoculaire inertielle du travail SOTA SLAM ORB-SLAM3 [2] du point de vue de la précision du positionnement et de la précision de la reconstruction de la carte. Les résultats de comparaison quantitative de la précision du positionnement sont présentés dans le tableau 2. Les résultats de comparaison quantitative de la précision de la reconstruction de la carte sont présentés dans le tableau 3 et les résultats de comparaison qualitative sont présentés dans la figure 9. On peut constater que par rapport au SLAM, la méthode décrite dans cet article améliore considérablement la robustesse du système, la précision du positionnement et la précision de la reconstruction de la carte.
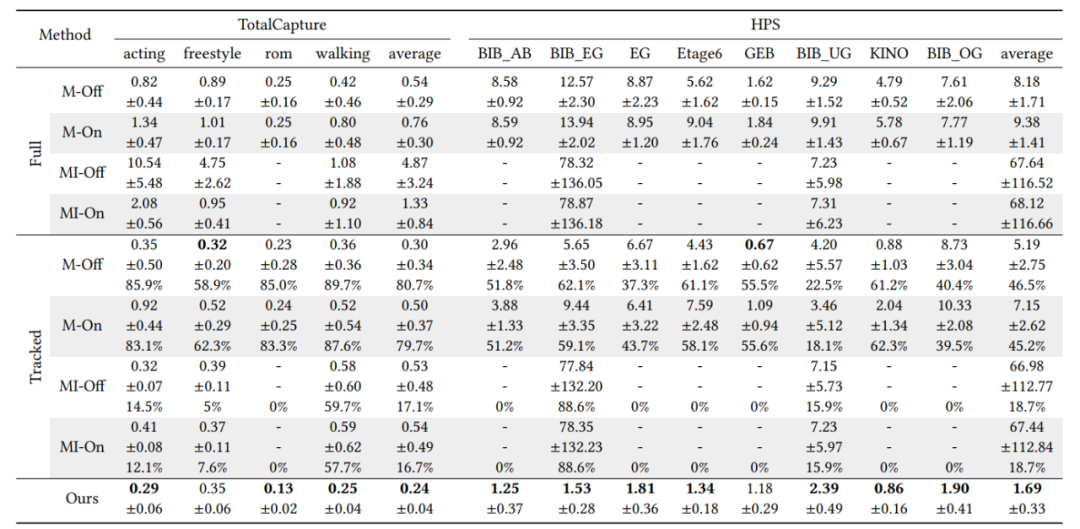
Tableau 2 Comparaison quantitative des erreurs de positionnement avec le travail SLAM (unité d'erreur : mètres). M/MI représente respectivement la version inertielle monoculaire/monoculaire d'ORB-SLAM3, et On/Off représente les résultats en temps réel et hors ligne de SLAM. Étant donné que SLAM perd souvent le suivi, nous rapportons respectivement l'erreur de positionnement moyenne sur la séquence complète (Full) et les images suivies avec succès (Tracked) pour SLAM ; Chaque méthode a été testée 9 fois et la médiane et l'écart type ont été rapportés. Pour les erreurs sur les images suivies avec succès, nous rapportons en outre le pourcentage de réussite. Si une méthode échoue plusieurs fois, nous la marquons comme ayant échoué (indiqué par "-").

Tableau 3 Comparaison quantitative des erreurs de reconstruction de carte avec le travail SLAM (unité d'erreur : mètre). M/MI représentent respectivement la version inertielle monoculaire/monoculaire d'ORB-SLAM3. Pour trois scènes différentes (bureau, extérieur, usine), nous testons l'erreur moyenne de tous les points de la carte 3D reconstruits à partir de la géométrie de la surface de la scène. Chaque méthode a été testée 9 fois et la médiane et l'écart type ont été rapportés. Si une méthode échoue plusieurs fois, nous la marquons comme ayant échoué (indiqué par "-").

Figure 9 Comparaison qualitative des erreurs de reconstruction de carte avec le travail SLAM. Nous montrons des points de scène reconstruits par différentes méthodes, la couleur indiquant l'erreur pour chaque point.
De plus, ce système améliore considérablement la robustesse contre la perte de suivi visuel en introduisant le mouvement humain au préalable. Lorsque les caractéristiques visuelles sont médiocres, ce système peut utiliser les mouvements humains pour continuer le suivi sans perdre le suivi ni réinitialiser ou créer de nouvelles cartes comme les autres systèmes SLAM. Comme le montre la figure 10 ci-dessous.

Figure 10 Comparaison de la robustesse de l'occlusion avec le travail SLAM. La référence de trajectoire de vérité terrain est affichée dans le coin supérieur droit. En raison du caractère aléatoire de l'initialisation SLAM, le système de coordonnées global et l'horodatage ne sont pas complètement alignés.
Pour plus de résultats expérimentaux, veuillez vous référer au texte original de l'article, à la page d'accueil du projet et à la vidéo de l'article.
Résumé
Cet article propose le premier travail combinant mocap inertiel et SLAM pour réaliser simultanément la capture, le positionnement et la cartographie du mouvement humain en temps réel. Le système est suffisamment léger pour ne nécessiter qu'un ensemble restreint de capteurs portés par le corps humain, notamment 6 unités de mesure inertielle et une caméra de téléphone portable. Pour le suivi en ligne, mocap et SLAM sont fusionnés via des techniques d'optimisation contrainte et de filtrage de Kalman pour obtenir un positionnement humain plus précis. Pour l'optimisation back-end, les erreurs de positionnement et de cartographie sont encore réduites en intégrant le mouvement humain au préalable dans l'optimisation de l'ajustement du faisceau et l'optimisation en boucle fermée dans SLAM.
Cette recherche vise à intégrer la perception du corps humain à la perception de l'environnement. Bien que ce travail se concentre principalement sur les aspects de localisation, nous pensons qu’il constitue un premier pas vers une capture conjointe du mouvement et une perception et une reconstruction fine de l’environnement.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Sony confirme la possibilité d'utiliser des GPU spéciaux sur PS5 Pro pour développer une IA avec AMD
Apr 13, 2025 pm 11:45 PM
Sony confirme la possibilité d'utiliser des GPU spéciaux sur PS5 Pro pour développer une IA avec AMD
Apr 13, 2025 pm 11:45 PM
Mark Cerny, architecte en chef de SonyInterActiveTeretment (SIE, Sony Interactive Entertainment), a publié plus de détails matériels de l'hôte de nouvelle génération PlayStation5Pro (PS5PRO), y compris un GPU AMDRDNA2.x architecture amélioré sur les performances, et un programme d'apprentissage de l'intelligence machine / artificielle "AmethylSt" avec AMD. L'amélioration des performances de PS5PRO est toujours sur trois piliers, y compris un GPU plus puissant, un traçage avancé des rayons et une fonction de super-résolution PSSR alimentée par AI. GPU adopte une architecture AMDRDNA2 personnalisée, que Sony a nommé RDNA2.x, et il a une architecture RDNA3.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Le réglage des performances de Zookeeper sur CentOS peut commencer à partir de plusieurs aspects, notamment la configuration du matériel, l'optimisation du système d'exploitation, le réglage des paramètres de configuration, la surveillance et la maintenance, etc. Assez de mémoire: allouez suffisamment de ressources de mémoire à Zookeeper pour éviter la lecture et l'écriture de disques fréquents. CPU multi-core: utilisez un processeur multi-core pour vous assurer que Zookeeper peut le traiter en parallèle.
 Méthode de configuration de Debian Mail Server Virtual Host
Apr 13, 2025 am 11:36 AM
Méthode de configuration de Debian Mail Server Virtual Host
Apr 13, 2025 am 11:36 AM
La configuration d'un hôte virtuel pour les serveurs de messagerie sur un système Debian implique généralement l'installation et la configuration des logiciels de serveur de messagerie (tels que PostFix, EXIM, etc.) plutôt que Apache HttpServer, car Apache est principalement utilisé pour les fonctions de serveur Web. Voici les étapes de base pour configurer un hôte virtuel de serveur de messagerie: installer Postfix Mail Server Update System Pack
 Enfin changé! La fonction de recherche Microsoft Windows inaugurera une nouvelle mise à jour
Apr 13, 2025 pm 11:42 PM
Enfin changé! La fonction de recherche Microsoft Windows inaugurera une nouvelle mise à jour
Apr 13, 2025 pm 11:42 PM
Les améliorations de Microsoft aux fonctions de recherche Windows ont été testées sur certains canaux d'initiés Windows dans l'UE. Auparavant, la fonction de recherche Windows intégrée a été critiquée par les utilisateurs et avait une mauvaise expérience. Cette mise à jour divise la fonction de recherche en deux parties: recherche locale et recherche Web basée sur Bing pour améliorer l'expérience utilisateur. La nouvelle version de l'interface de recherche effectue la recherche de fichiers locale par défaut. Si vous devez rechercher en ligne, vous devez cliquer sur l'onglet "Microsoft Bingwebsearch" pour changer. Après le changement, la barre de recherche affichera "Microsoft BingWebsearch:", où les utilisateurs peuvent entrer des mots clés. Ce mouvement évite efficacement le mélange des résultats de recherche locaux avec les résultats de recherche Bing
