

NetEase Cloud Music est un produit musical développé par NetEase. C'est le résultat du NetEase Hangzhou Research Institute S'appuyant sur des musiciens professionnels, des DJ, des recommandations d'amis et des fonctions sociales, c'est le principal. service de musique en ligne Playlists, réseaux sociaux, recommandations de grands noms et empreintes musicales, avec playlists, programmes DJ, réseaux sociaux et localisation géographique comme éléments centraux, axés sur la découverte et le partage. Explorez la partie playlist du site officiel de NetEase Cloud Music, obtenez des données de la playlist NetEase Cloud Music, obtenez toutes les playlists d'un certain style de chanson et obtenez le nom, l'étiquette, l'introduction, le volume de la collection, le volume de lecture et la liste des chansons de la playlist. Le nombre de chansons incluses dans le single, ainsi que le nombre de commentaires.
Prétraitez les données analysées, analysez les données prétraitées et analysez le volume de la liste de lecture, le volume de la collection de chansons et les commentaires de la liste de chansons. Le volume, l'état de la collection de chansons de la liste de lecture, les balises de la liste de lecture , les contributeurs de playlist, etc. sont analysés et visualisés pour refléter les résultats de l'analyse de manière plus intuitive.
Écouter de la musique est aujourd'hui un moyen pour de nombreux jeunes d'exprimer leurs émotions. NetEase Cloud Music est une plateforme musicale populaire. Vous pouvez analyser la playlist de NetEase Cloud Music. afin de comprendre les problèmes rencontrés par les jeunes dans la société d'aujourd'hui, ainsi que divers aspects de la pression émotionnelle ; il peut également comprendre les préférences des utilisateurs, analyser quel type de liste de chansons est la plus populaire auprès du public et peut également refléter les préférences et opinions du public sur la musique. La création du créateur joue également un rôle très important. Du point de vue des utilisateurs ordinaires, pour les créateurs de playlists, d'une part, la création de playlists facilite la classification et la gestion de leur propre collection de bibliothèques musicales, d'autre part, la production de playlists de haute qualité peut mettre en valeur leurs propres goûts musicaux. et les commentaires vous procurent un grand sentiment d'accomplissement et de satisfaction. La « liste de lecture » pour écouter de la musique est très importante pour les consommateurs et peut améliorer considérablement l'expérience d'écoute de l'utilisateur. Pour les musiciens, les animateurs de radio et autres types de créateurs de playlists, les « playlists » peuvent mieux diffuser leur musique et leurs œuvres, mais aussi mieux interagir avec leurs fans et accroître leur popularité.
Ce projet explore les données de la partie playlist chinoise du site officiel de NetEase Cloud. L'adresse d'exploration est : Chinese Playlist - Playlist - NetEase Cloud Music
Entrez chaque page, obtenez chaque liste de chansons sur la page, entrez une seule liste de chansons, le nom de la liste de chansons, le volume de la collection, le nombre de commentaires, les tags, l'introduction, le nombre total de chansons, le volume de lecture, les titres de chansons inclus et d'autres données. tous stockés dans le même div de la page Web, et chaque contenu est sélectionné via le sélecteur.
from bs4 import BeautifulSoup
import requests
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
for i in range(0, 1330, 35):
print(i)
time.sleep(2)
url = 'https://music.163.com/discover/playlist/?cat=华语&order=hot&limit=35&offset=' + str(i)#修改这里即可
response = requests.get(url=url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 获取包含歌单详情页网址的标签
ids = soup.select('.dec a')
# 获取包含歌单索引页信息的标签
lis = soup.select('#m-pl-container li')
print(len(lis))
for j in range(len(lis)):
# 获取歌单详情页地址
url = ids[j]['href']
# 获取歌单标题
title = ids[j]['title']
# 获取歌单播放量
play = lis[j].select('.nb')[0].get_text()
# 获取歌单贡献者名字
user = lis[j].select('p')[1].select('a')[0].get_text()
# 输出歌单索引页信息
print(url, title, play, user)
# 将信息写入CSV文件中
with open('playlist.csv', 'a+', encoding='utf-8-sig') as f:
f.write(url + ',' + title + ',' + play + ',' + user + '\n')
from bs4 import BeautifulSoup
import pandas as pd
import requests
import time
df = pd.read_csv('playlist.csv', header=None, error_bad_lines=False, names=['url', 'title', 'play', 'user'])
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
for i in df['url']:
time.sleep(2)
url = 'https://music.163.com' + i
response = requests.get(url=url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 获取歌单标题
title = soup.select('h3')[0].get_text().replace(',', ',')
# 获取标签
tags = []
tags_message = soup.select('.u-tag i')
for p in tags_message:
tags.append(p.get_text())
# 对标签进行格式化
if len(tags) > 1:
tag = '-'.join(tags)
else:
tag = tags[0]
# 获取歌单介绍
if soup.select('#album-desc-more'):
text = soup.select('#album-desc-more')[0].get_text().replace('\n', '').replace(',', ',')
else:
text = '无'
# 获取歌单收藏量
collection = soup.select('#content-operation i')[1].get_text().replace('(', '').replace(')', '')
# 歌单播放量
play = soup.select('.s-fc6')[0].get_text()
# 歌单内歌曲数
songs = soup.select('#playlist-track-count')[0].get_text()
# 歌单评论数
comments = soup.select('#cnt_comment_count')[0].get_text()
# 输出歌单详情页信息
print(title, tag, text, collection, play, songs, comments)
# 将详情页信息写入CSV文件中
with open('music_message.csv', 'a+', encoding='utf-8') as f:
# f.write(title + '/' + tag + '/' + text + '/' + collection + '/' + play + '/' + songs + '/' + comments + '\n')
f.write(title + ',' + tag + ',' + text + ',' + collection + ',' + play + ',' + songs + ',' + comments + '\n')Stockez le contenu pertinent dans le fichier .csv correspondant. Le fichier music_message.csv stocke le nom, la balise et l'introduction, le numéro de. collections, nombre d'écoutes, nombre de chansons incluses dans la playlist et nombre de commentaires. L'adresse, le titre, le volume de lecture et le nom du contributeur de la page de détails de la playlist sont tous stockés dans le fichier playlist.csv. Les résultats sont présentés dans les figures 2-1 et 2-2.
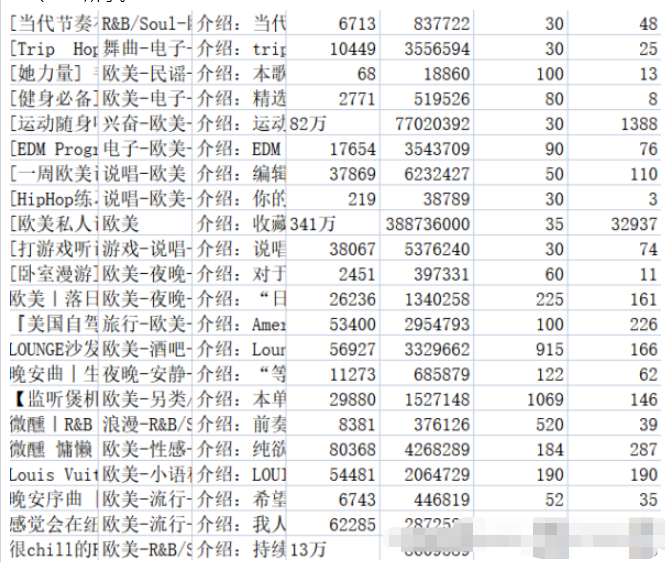
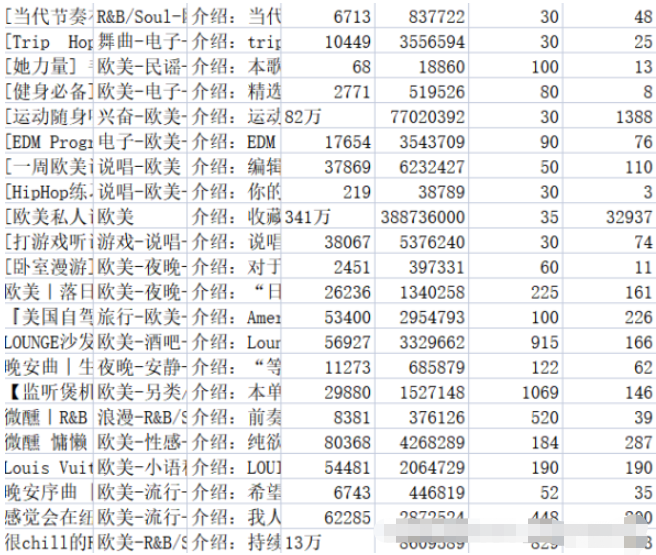
Concernant le nettoyage des données, en effet, une partie du processus de capture des données a été effectuée dans la partie précédente, notamment : les informations de liste de chansons vides renvoyées par l'arrière-plan, la déduplication des données en double, etc. . De plus, un certain nettoyage est à faire : unifier les données du volume de commentaires dans un format unifié, etc.
Ajoutez les données "10 000" aux données dans le nombre de commentaires, remplacez "10 000" par "0000" pour faciliter l'analyse ultérieure des données, remplissez les données avec des erreurs statistiques dans le nombre de commentaires par " 0", ne participez pas aux statistiques ultérieures.
df['collection'] = df['collection'].astype('string').str.strip() df['collection'] = [int(str(i).replace('万','0000')) for i in df['collection']] df['text'] = [str(i)[3:] for i in df['text']] df['comments'] = [0 if '评论' in str(i).strip() else int(i) for i in df['comments']]
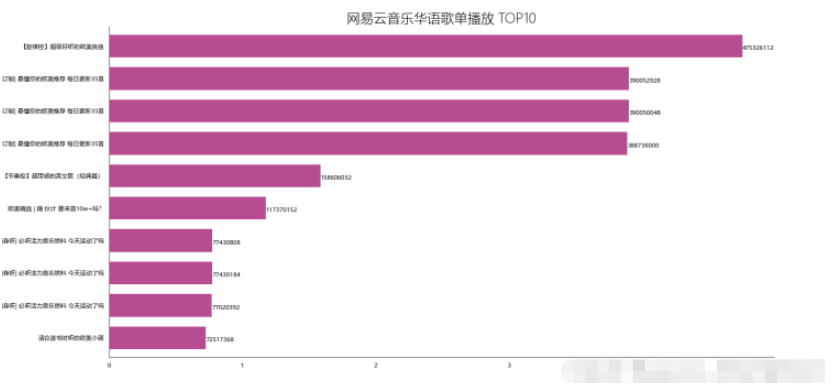
df_play = df[['title','play']].sort_values('play',ascending=False) df_play[:10] df_play = df_play[:10] _x = df_play['title'].tolist() _y = df_play['play'].tolist() df_play = get_matplot(x=_x,y=_y,chart='barh',title='网易云音乐华语歌单播放 TOP10',ha='left',size=8,color=color[0]) df_play

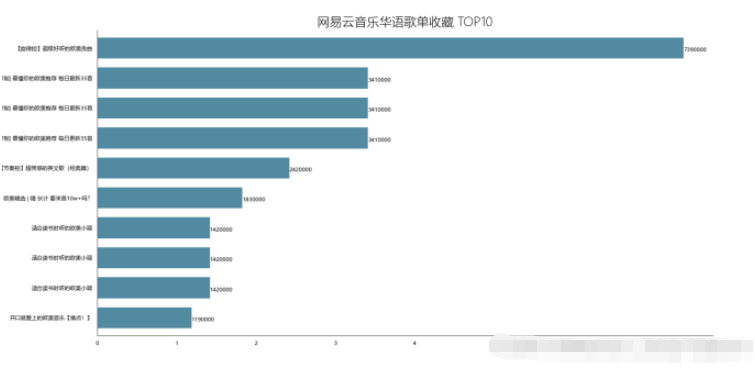
df_col = df[['title','collection']].sort_values('collection',ascending=False) df_col[:10] df_col = df_col[:10] _x = df_col['title'].tolist() _y = df_col['collection'].tolist() df_col = get_matplot(x=_x,y=_y,chart='barh',title='网易云音乐华语歌单收藏 TOP10',ha='left',size=8,color=color[1]) df_col
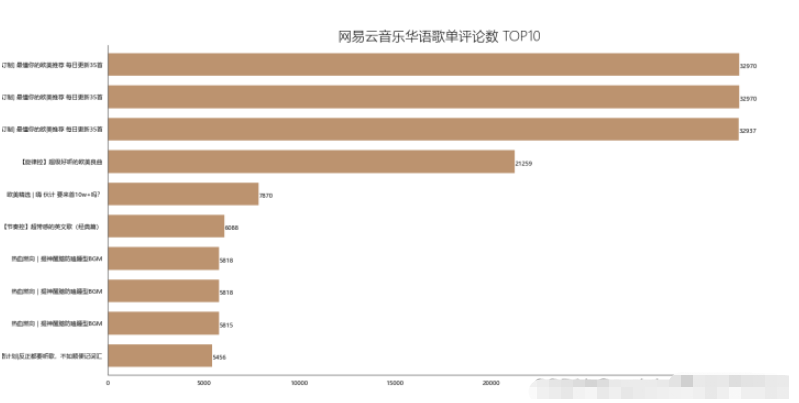
df_com = df[['title','comments']].sort_values('comments',ascending=False) df_com[:10] df_com = df_com[:10] _x = df_com['title'].tolist() _y = df_com['comments'].tolist() df_com = get_matplot(x=_x,y=_y,chart='barh',title='网易云音乐华语歌单评论数 TOP10',ha='left',size=8,color=color[2]) df_com

df_songs = np.log(df['songs']) df_songs df_songs = get_matplot(x=0,y=df_songs,chart='hist',title='华语歌单歌曲收录分布情况',ha='left',size=10,color=color[3]) df_songs
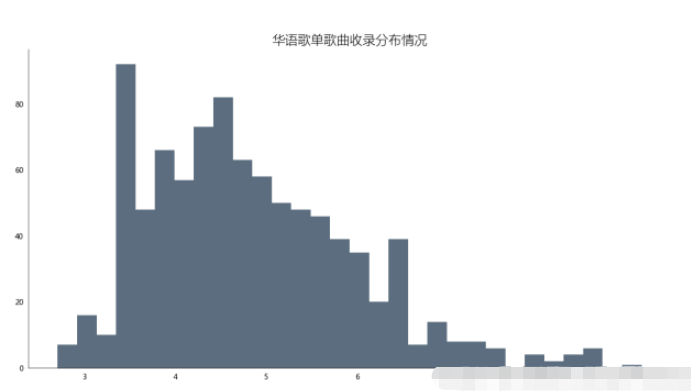
通过对柱形图分析发现,歌单对歌曲的收录情况多数集中在20-60首歌曲,至多超过80首,也存在空歌单现象,但绝大多数歌单收录歌曲均超过10首左右。这次可视化分析将有助于后续创作者更好地收录歌曲到自己的创作歌单中。也能够更受大众欢迎。
def get_tag(df):
df = df['tag'].str.split('-')
datalist = list(set(x for data in df for x in data))
return datalist
df_tag = get_tag(df)
# df_tag
def get_lx(x,i):
if i in str(x):
return 1
else:
return 0
for i in list(df_tag):#这里的df['all_category'].unique()也可以自己用列表构建,我这里是利用了前面获得的
df[i] = df['tag'].apply(get_lx,i=f'{i}')
# df.head()
Series = df.iloc[:,7:].sum().sort_values(0,ascending=False)
df_tag = [tag for tag in zip(Series.index.tolist(),Series.values.tolist())]
df_tag[:10]
df_iex = [index for index in Series.index.tolist()][:20]
df_tag = [tag for tag in Series.values.tolist()][:20]
df_tagiex = get_matplot(x=df_iex,y=df_tag,chart='plot',title='网易云音乐华语歌单标签图',size=10,ha='center',color=color[3])
df_tagiex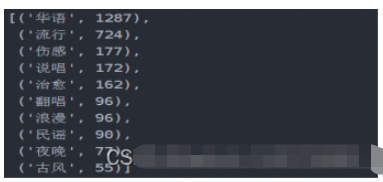
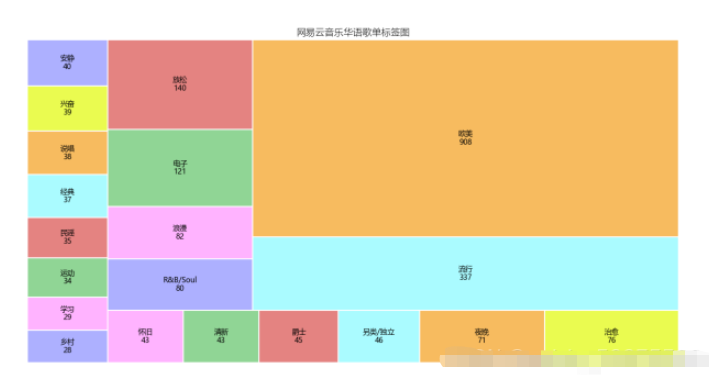
可以通过此标签图看出歌单的风格,可以分析出目前的主流歌曲的情感,以及大众的需求,也网易云音乐用户的音乐偏好,据此可以看出,网易云音乐用户,在音乐偏好上比较多元化:国内流行、欧美流行、电子、 等各种风格均有涉及。
df_user = pd.read_csv('playlist.csv',encoding="unicode_escape",header=0,names=['url','title','play','user'],sep=',') df_user.shape df_user = df_user.iloc[:,1:] df_user['count'] = 0 df_user = df_user.groupby('user',as_index=False)['count'].count() df_user = df_user.sort_values('count',ascending=False)[:10] df_user df_user = df_user[:10] names = df_user['user'].tolist() nums = df_user['count'].tolist() df_u = get_matplot(x=names,y=nums,chart='barh',title='歌单贡献UP主 TOP10',ha='left',size=10,color=color[4]) df_u
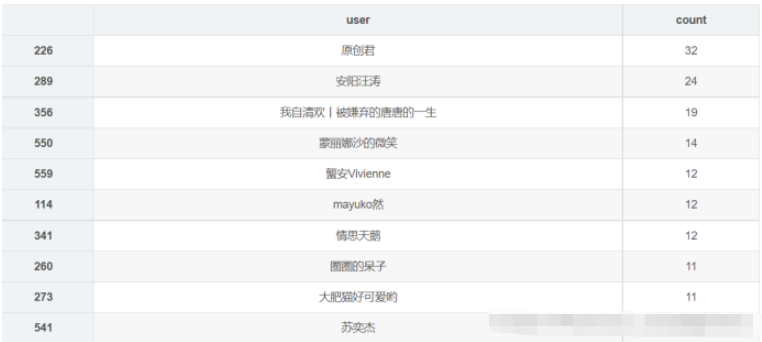
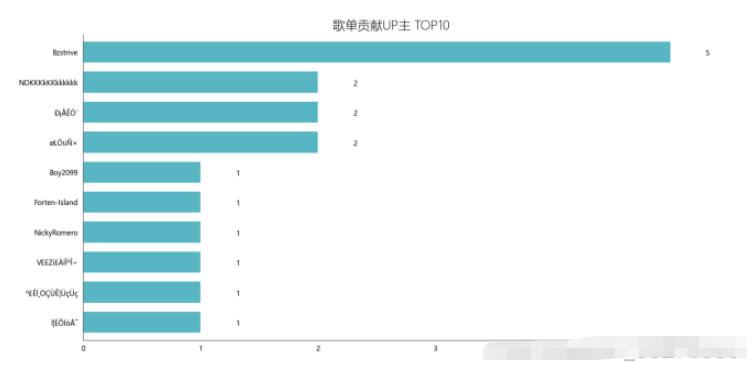
import wordcloud
import pandas as pd
import numpy as np
from PIL import Image
data = pd.read_excel('music_message.xlsx')
#根据播放量排序,只取前五十个
data = data.sort_values('play',ascending=False).head(50)
#font_path指明用什么样的字体风格,这里用的是电脑上都有的微软雅黑
w1 = wordcloud.WordCloud(width=1000,height=700,
background_color='black',
font_path='msyh.ttc')
txt = "\n".join(i for i in data['title'])
w1.generate(txt)
w1.to_file('F:\\词云.png')
为了简化代码,构建了通用函数
get_matplot(x,y,chart,title,ha,size,color)
x表示充当x轴数据;
y表示充当y轴数据;
chart表示图标类型,这里分为三种barh、hist、squarify.plot;
ha表示文本相对朝向;
size表示字体大小;
color表示图表颜色;
def get_matplot(x,y,chart,title,ha,size,color):
# 设置图片显示属性,字体及大小
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['font.size'] = size
plt.rcParams['axes.unicode_minus'] = False
# 设置图片显示属性
fig = plt.figure(figsize=(16, 8), dpi=80)
ax = plt.subplot(1, 1, 1)
ax.patch.set_color('white')
# 设置坐标轴属性
lines = plt.gca()
# 设置显示数据
if x ==0:
pass
else:
x.reverse()
y.reverse()
data = pd.Series(y, index=x)
# 设置坐标轴颜色
lines.spines['right'].set_color('none')
lines.spines['top'].set_color('none')
lines.spines['left'].set_color((64/255, 64/255, 64/255))
lines.spines['bottom'].set_color((64/255, 64/255, 64/255))
# 设置坐标轴刻度
lines.xaxis.set_ticks_position('none')
lines.yaxis.set_ticks_position('none')
if chart == 'barh':
# 绘制柱状图,设置柱状图颜色
data.plot.barh(ax=ax, width=0.7, alpha=0.7, color=color)
# 添加标题,设置字体大小
ax.set_title(f'{title}', fontsize=18, fontweight='light')
# 添加歌曲出现次数文本
for x, y in enumerate(data.values):
plt.text(y+0.3, x-0.12, '%s' % y, ha=f'{ha}')
elif chart == 'hist':
# 绘制直方图,设置柱状图颜色
ax.hist(y, bins=30, alpha=0.7, color=(21/255, 47/255, 71/255))
# 添加标题,设置字体大小
ax.set_title(f'{title}', fontsize=18, fontweight='light')
elif chart == 'plot':
colors = ['#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50',
'#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50',
'#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50',
'#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50',
'#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50',
'#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50',
'#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff']
plot = squarify.plot(sizes=y, label=x, color=colors, alpha=1, value=y, edgecolor='white', linewidth=1.5)
# 设置标签大小为1
plt.rc('font', size=6)
# 设置标题大小
plot.set_title(f'{title}', fontsize=13, fontweight='light')
# 除坐标轴
plt.axis('off')
# 除上边框和右边框刻度
plt.tick_params(top=False, right=False)
# 显示图片
plt.show()
#构建color序列
color = [(153/255, 0/255, 102/255),(8/255, 88/255, 121/255),(160/255, 102/255, 50/255),(136/255, 43/255, 48/255),(16/255, 152/255, 168/255),(153/255, 0/255, 102/255)]Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



