
 Périphériques technologiques
IA
Dieu restaure les objets complexes et les détails haute fréquence, la synthèse de vue haute fidélité 4K-NeRF est là
Périphériques technologiques
IA
Dieu restaure les objets complexes et les détails haute fréquence, la synthèse de vue haute fidélité 4K-NeRF est là
Dieu restaure les objets complexes et les détails haute fréquence, la synthèse de vue haute fidélité 4K-NeRF est là

L'ultra haute résolution est saluée par de nombreux chercheurs comme une norme pour l'enregistrement et l'affichage d'images et de vidéos de haute qualité. Par rapport aux résolutions inférieures (format HD 1K), les scènes capturées à haute résolution ont généralement des détails très clairs. amplifié par de petites taches. Cependant, l’application de cette technologie au traitement d’images et à la vision par ordinateur pose encore de nombreux défis.
Dans cet article, des chercheurs d'Alibaba se concentrent sur de nouvelles tâches de synthèse de vues et proposent un cadre appelé 4K-NeRF. Sa méthode de rendu de volume basée sur NeRF peut atteindre une haute fidélité avec une composition de vues 4K ultra-haute.

Adresse papier : https://arxiv.org/abs/2212.04701
Page d'accueil du projet : https://github.com/frozoul/4K-NeRF
Sans plus loin, jetons un coup d'œil à l'effet d'abord (les vidéos suivantes ont été sous-échantillonnées, veuillez vous référer au projet original pour la vidéo 4K originale).
Méthodes
Voyons ensuite comment la recherche a été menée.
Pipeline 4K-NeRF (comme indiqué ci-dessous) : utilisez la technologie d'échantillonnage de rayons basée sur des patchs pour former conjointement VC-Encoder (View-Consistent) (basé sur DEVO) pour coder des informations géométriques tridimensionnelles dans un espace de résolution inférieure, puis grâce à un décodeur VC, un rendu haute fréquence, de qualité fine et de haute qualité et une amélioration de la cohérence de la vue sont obtenus.
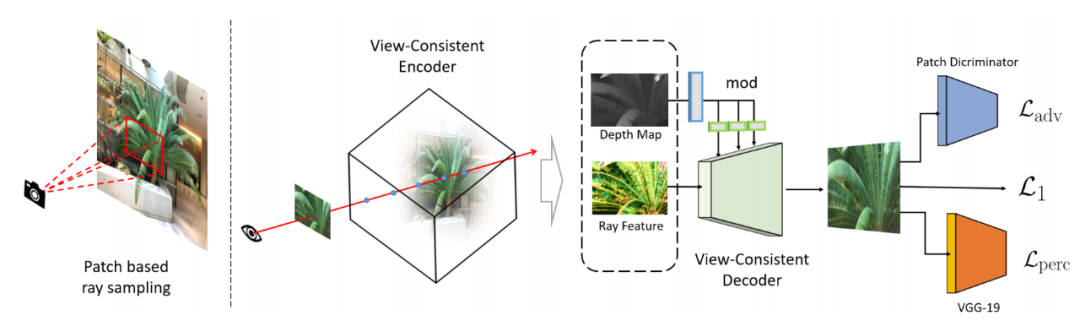
L'étude instancie l'encodeur sur la base de la formule définie dans DVGO [32] et apprend une représentation basée sur une grille de voxels pour coder explicitement la géométrie :
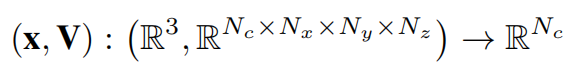
Pour chaque Pour chaque point d'échantillonnage, l'interpolation trilinéaire d'estimation de la densité est équipée d'une fonction d'activation softplus pour générer la valeur de densité volumique du point :
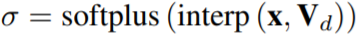
La couleur est estimée à l'aide d'un petit MLP :
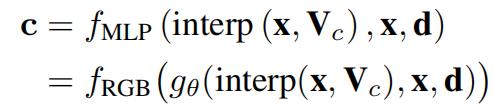
Dans ce De cette manière, la valeur caractéristique de chaque rayon (ou pixel) peut être obtenue en accumulant les caractéristiques des points d'échantillonnage le long de la ligne définie r :
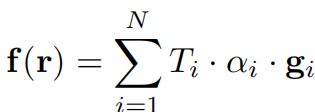
Afin de mieux utiliser la géométrie intégrée dans les propriétés du VC-Encoder, l'étude a également généré une carte de profondeur en estimant la profondeur de chaque rayon r le long de l'axe du rayon échantillonné. La carte de profondeur estimée fournit un guide solide sur la structure tridimensionnelle de la scène générée par l'encodeur ci-dessus :
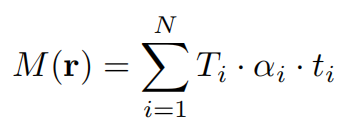
Le réseau transmis ensuite est obtenu en empilant plusieurs blocs de convolution (ni en utilisant une normalisation non paramétrique ni Créé à l'aide d'opérations de sous-échantillonnage) et d'opérations de suréchantillonnage entrelacées. En particulier, au lieu de simplement concaténer la caractéristique F et la carte de profondeur M, cette étude joint le signal de profondeur de la carte de profondeur et l'injecte dans chaque bloc via une transformation apprise pour moduler les activations de blocs.
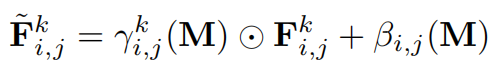
Différent du mécanisme au niveau des pixels des méthodes NeRF traditionnelles, la méthode étudiée dans cette étude vise à capturer les informations spatiales entre les rayons (pixels). Par conséquent, la stratégie d’échantillonnage aléatoire des rayons dans NeRF ne convient pas ici. Par conséquent, cette étude propose une stratégie de formation à l’échantillonnage de rayons basée sur des patchs pour faciliter la capture de la dépendance spatiale entre les caractéristiques des rayons. Lors de l'entraînement, l'image de la vue d'entraînement est d'abord divisée en patchs p de taille N_p×N_p pour garantir que la probabilité d'échantillonnage sur les pixels est uniforme. Lorsque la dimension de l'espace image ne peut pas être divisée avec précision par la taille du patch, le patch doit être tronqué jusqu'au bord pour obtenir un ensemble de patchs d'entraînement. Ensuite, un (ou plusieurs) patchs sont sélectionnés au hasard dans l'ensemble, et les rayons des pixels du patch forment un mini-lot pour chaque itération.
Pour résoudre le problème du flou ou du lissage excessif des effets visuels sur les détails fins, cette recherche ajoute la perte contradictoire et la perte de perception pour régulariser la synthèse des détails fins. La perte de perception 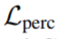 estime la similarité entre le patch prédit
estime la similarité entre le patch prédit 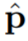 et la vérité terrain p dans l'espace des fonctionnalités via un réseau VGG à 19 couches pré-entraîné :
et la vérité terrain p dans l'espace des fonctionnalités via un réseau VGG à 19 couches pré-entraîné :
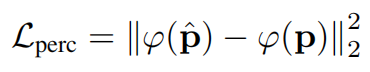
L'étude utilise 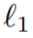 perte Au lieu de MSE pour superviser la reconstruction des détails à haute fréquence
perte Au lieu de MSE pour superviser la reconstruction des détails à haute fréquence
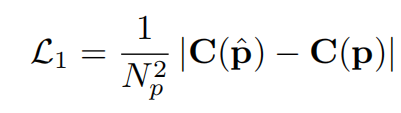
De plus, l'étude a également ajouté une perte MSE auxiliaire, et la fonction de perte totale finale a la forme suivante :
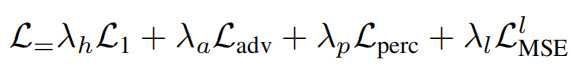
Effet expérimental
Analyse qualitative
L'expérience a comparé le 4K-NeRF avec d'autres modèles. On peut voir que les méthodes basées sur le NeRF ordinaire présentent différents degrés de perte de détails et de flou. En revanche, le 4K-NeRF offre un rendu photoréaliste de haute qualité de ces détails complexes et haute fréquence, même sur des scènes avec un champ de vision d'entraînement limité.


Analyse quantitative
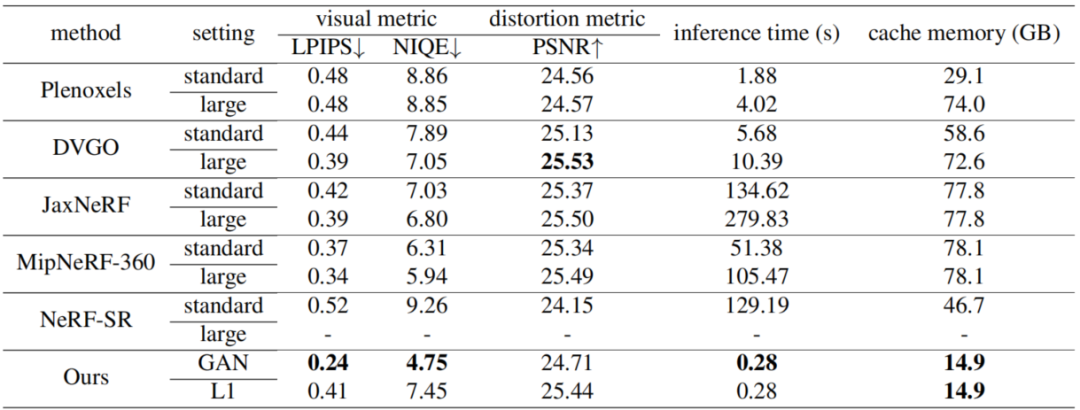
Cette étude a été comparée à plusieurs méthodes actuelles sur la base de données 4k, notamment Plenoxels, DVGO, JaxNeRF, MipNeRF-360 et NeRF-SR. L'expérience utilise non seulement les indicateurs d'évaluation de la récupération d'image à titre de comparaison, mais fournit également un temps d'inférence et une mémoire cache pour une référence d'évaluation complète. Les résultats sont les suivants :
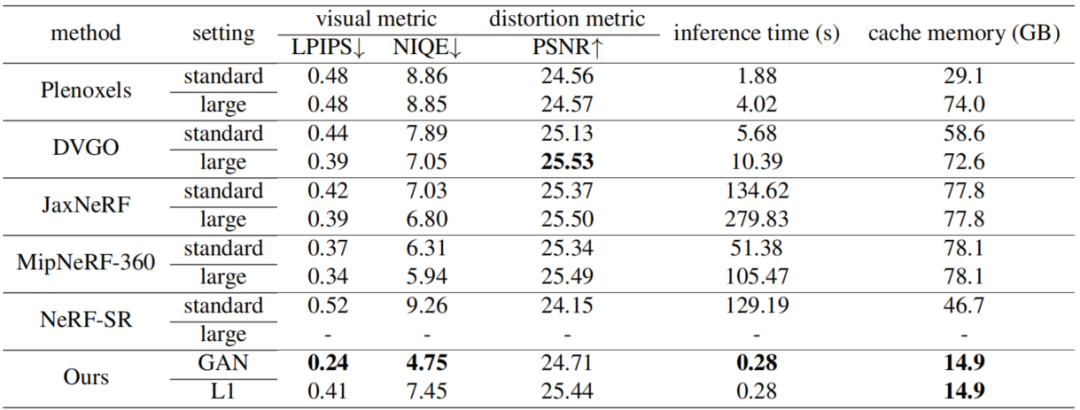
Bien que les résultats ne soient pas très différents des résultats de certaines méthodes dans certains indicateurs, grâce à leur méthode basée sur les voxels, ils ont atteint des performances étonnantes en termes d'efficacité de raisonnement et de coût de mémoire. , permettant de restituer une image 4K en 300 ms.
Résumé et perspectives futures
Cette étude explore les capacités de NeRF en matière de modélisation des détails fins, proposant un nouveau cadre pour améliorer son expressivité dans la récupération de détails fins cohérents avec la vue dans des scènes à des résolutions extrêmement élevées. En outre, cette recherche introduit également une paire de modules codeurs-décodeurs qui maintiennent la cohérence géométrique, modélisent efficacement les propriétés géométriques dans les espaces inférieurs et utilisent des corrélations locales entre les fonctionnalités sensibles à la géométrie pour obtenir des vues dans un espace à grande échelle. Le cadre de formation à l'échantillonnage basé sur l'échantillonnage permet également à la méthode d'intégrer la supervision à partir d'une régularisation orientée perceptron. Cette recherche espère intégrer les effets du cadre dans la modélisation de scènes dynamiques, ainsi que dans les tâches de rendu neuronal comme orientations futures.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravelelognent Model Retrieval: Faconttement l'obtention de données de base de données Eloquentorm fournit un moyen concis et facile à comprendre pour faire fonctionner la base de données. Cet article présentera en détail diverses techniques de recherche de modèles éloquentes pour vous aider à obtenir efficacement les données de la base de données. 1. Obtenez tous les enregistrements. Utilisez la méthode All () pour obtenir tous les enregistrements dans la table de base de données: usApp \ Modèles \ Post; $ poters = post :: all (); Cela rendra une collection. Vous pouvez accéder aux données à l'aide de Foreach Loop ou d'autres méthodes de collecte: ForEach ($ PostsAs $ POST) {echo $ post->
