
 Périphériques technologiques
IA
Scandaleux! Dernière recherche : 61 % des articles en anglais rédigés par des Chinois seront jugés comme générés par l'IA par le détecteur ChatGPT
Périphériques technologiques
IA
Scandaleux! Dernière recherche : 61 % des articles en anglais rédigés par des Chinois seront jugés comme générés par l'IA par le détecteur ChatGPT
Scandaleux! Dernière recherche : 61 % des articles en anglais rédigés par des Chinois seront jugés comme générés par l'IA par le détecteur ChatGPT

Après que ChatGPT soit devenu populaire, il existe de nombreuses façons de l'utiliser.
Certaines personnes l'utilisent pour demander des conseils de vie, d'autres l'utilisent simplement comme moteur de recherche et certaines personnes l'utilisent pour rédiger des articles.
Thèse... ce n'est pas amusant à écrire.
Certaines universités aux États-Unis ont interdit aux étudiants d'utiliser ChatGPT pour rédiger leurs devoirs, et ont également développé un certain nombre de logiciels pour identifier et déterminer si les documents soumis par les étudiants sont générés par GPT.
Il y a un problème ici.
L'article de quelqu'un était à l'origine mal rédigé, mais l'IA qui a jugé le texte pensait qu'il avait été rédigé par un pair.
De plus, la probabilité que les articles en anglais rédigés par des Chinois soient jugés comme étant générés par l'IA atteint 61 %.

C'est... qu'est-ce que ça veut dire ? Frissons !
Les locuteurs non natifs n'en valent pas la peine ?
Actuellement, les modèles de langage génératifs se développent rapidement et ont en effet apporté de grands progrès à la communication numérique.
Mais il y a vraiment beaucoup d'abus.
Bien que les chercheurs aient proposé de nombreuses méthodes de détection pour distinguer le contenu généré par l'IA et le contenu généré par l'homme, l'équité et la stabilité de ces méthodes de détection doivent encore être améliorées.
À cette fin, les chercheurs ont évalué les performances de plusieurs détecteurs GPT largement utilisés à l'aide de travaux rédigés par des auteurs anglophones natifs et non natifs.
Les résultats de recherche montrent que ces détecteurs déterminent toujours de manière incorrecte les échantillons écrits par des locuteurs non natifs tels que générés par l'IA, alors que les échantillons écrits par des locuteurs natifs peuvent en principe être identifiés avec précision.
De plus, les chercheurs ont démontré que ce biais peut être atténué avec quelques stratégies simples et contourner efficacement les détecteurs GPT.
Qu'est-ce que cela signifie ? Cela montre que le détecteur GPT méprise les auteurs dont les compétences linguistiques ne sont pas très bonnes, ce qui est très ennuyeux.
Je ne peux m'empêcher de penser à ce jeu pour juger si l'IA est une personne réelle. Si l'adversaire est une personne réelle mais que vous devinez qu'il s'agit d'une IA, le système dira : « L'autre partie peut vous trouver offensant. ."
Pas assez complexe = génération IA ?
Les chercheurs ont obtenu 91 essais TOEFL provenant d'un forum sur l'éducation chinois et 88 essais rédigés par des élèves américains de huitième année à partir de l'ensemble de données de la Fondation Hewlett pour détecter 7 détecteurs GPT largement utilisés.
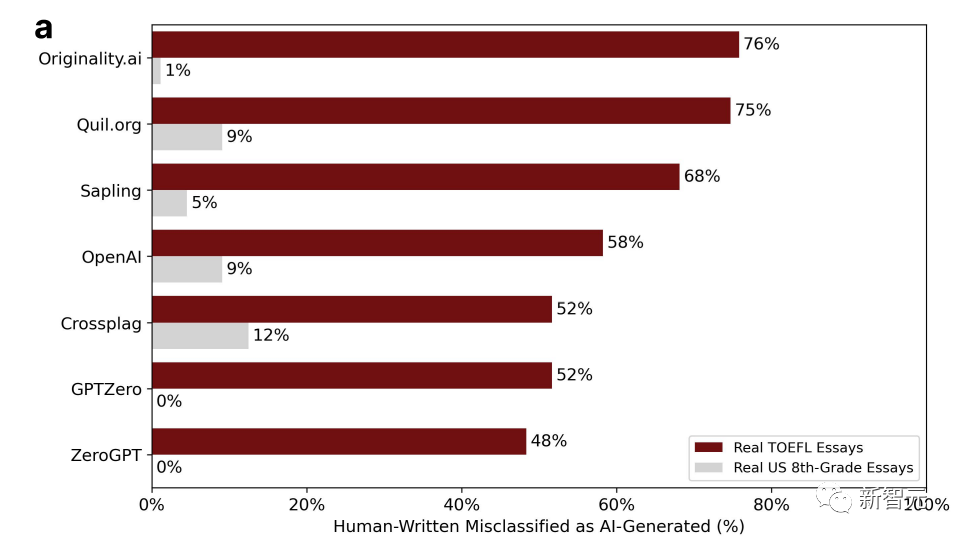
Le pourcentage dans le tableau représente la proportion d'"erreurs de jugement". Autrement dit, il a été écrit par un humain, mais le logiciel de détection pense qu'il a été généré par l'IA.
Vous pouvez constater que les données sont très disparates.
Parmi les sept détecteurs, la probabilité la plus élevée d'être mal jugé pour les essais rédigés par des élèves américains de huitième année n'est que de 12 %, et il existe deux GPT sans erreur de jugement.
Fondamentalement, plus de la moitié des essais du TOEFL sur les forums chinois sont mal jugés, et la probabilité la plus élevée d'erreur de jugement peut atteindre 76 %.
18 des 91 essais du TOEFL ont été jugés à l'unanimité comme étant générés par l'IA par les 7 détecteurs GPT, tandis que 89 des 91 essais ont été mal jugés par au moins un détecteur GPT.
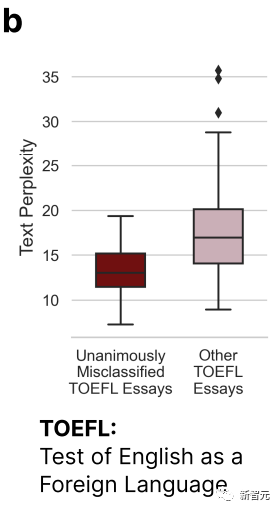
D'après l'image ci-dessus, nous pouvons voir que l'essai du TOEFL qui a été mal jugé par les 7 GPT est nettement moins complexe que les autres essais.
Cela confirme la conclusion du début : le détecteur GPT aura un certain biais contre les auteurs ayant une capacité d'expression linguistique limitée.
Par conséquent, les chercheurs pensent que le détecteur GPT devrait lire davantage d'articles écrits par des locuteurs non natifs. Ce n'est qu'avec plus d'échantillons que les biais pourront être éliminés.
Ensuite, les chercheurs ont jeté des essais TOEFL rédigés par des locuteurs non natifs dans ChatGPT pour enrichir la langue et imiter les habitudes d'utilisation des mots des locuteurs natifs.
Dans le même temps, en tant que groupe témoin, des compositions écrites par des enfants américains de huitième année ont également été lancées dans ChatGPT, et le langage a été simplifié pour imiter les caractéristiques d'écriture de locuteurs non natifs. L'image ci-dessous est le nouveau résultat du jugement après correction.
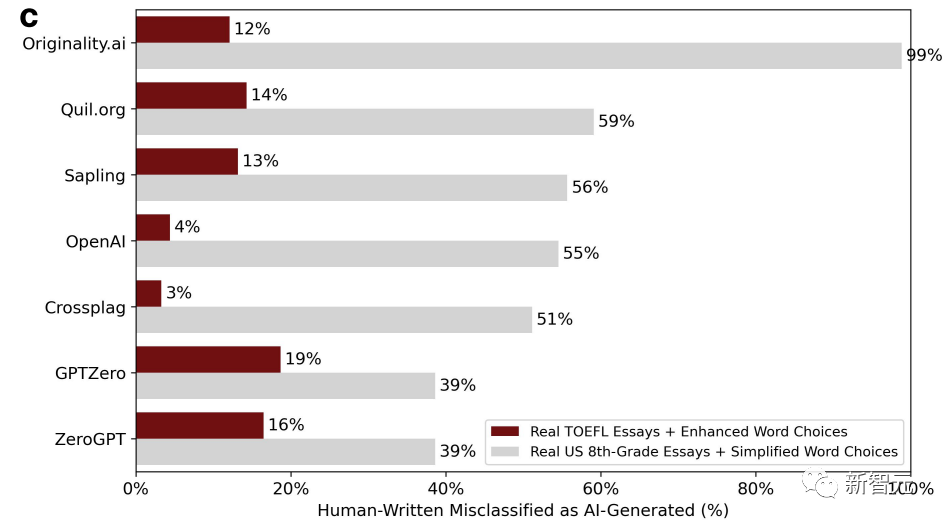
Nous pouvons constater que la situation a radicalement changé. Le taux d'erreurs d'évaluation des essais du TOEFL qui enrichissent la langue a chuté, jusqu'à 3 % et jusqu'à 19 %. Contrairement au taux de faux positifs précédent, qui était essentiellement supérieur à la moitié.
Au contraire, le taux d'erreur des essais rédigés par des enfants de huitième année est monté en flèche. Il existe même un détecteur GPT avec un taux d'erreur pouvant atteindre 99 %, ce qui correspond essentiellement à toutes les erreurs.
Parce que la variable de complexité des articles a changé.
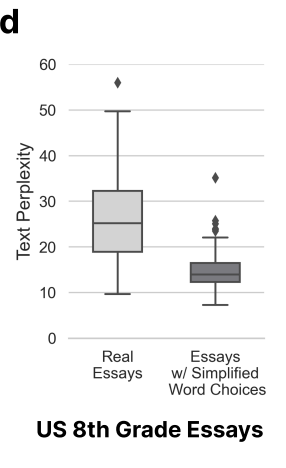
Ici, les chercheurs sont arrivés à la conclusion que les choses écrites par des locuteurs non natifs ne sont pas authentiques, sont peu complexes et sont facilement mal jugées.
Cela entraîne également un problème technique, mais aussi un problème de valeur. Utiliser la complexité pour déterminer si l’IA ou les humains en sont les auteurs est raisonnable, complet et rigoureux.
Le résultat ne l'est évidemment pas.
À en juger par la complexité, les locuteurs non natifs subissent une grande perte car ce sont des locuteurs non natifs (absurdité).
AI polonais = écrit par des humains ? ?
Les chercheurs pensent que l'amélioration de la diversité linguistique peut non seulement atténuer les préjugés à l'égard des locuteurs non natifs, mais également permettre au contenu généré par GPT de contourner les détecteurs GPT.
Pour prouver ce point, les chercheurs ont sélectionné des sujets de dissertation d'admission pour les candidatures universitaires américaines de 2022 à 2023, les ont saisis dans ChatGPT-3.5 et ont généré un total de 31 faux essais.
Le détecteur GPT était assez efficace au début, mais pas au second tour. En effet, lors du deuxième tour, les chercheurs ont jeté ces articles dans ChatGPT et les ont peaufinés, en utilisant un langage littéraire pour améliorer la qualité du texte.
De cette façon, la précision du détecteur GPT est passée de 100 % à 0 %. Comme indiqué ci-dessous :
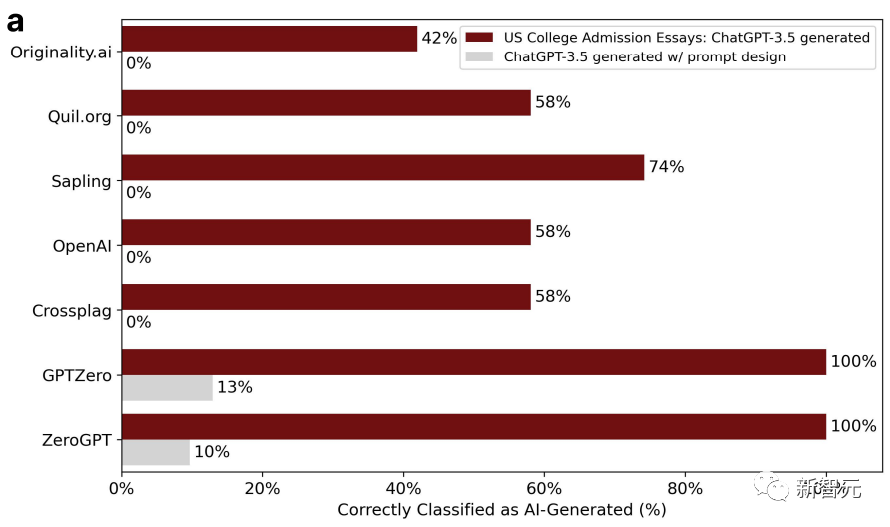
La complexité de l'article poli a également augmenté en conséquence.
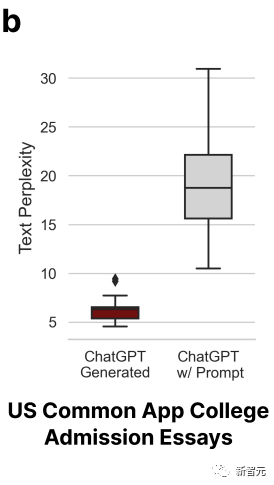
Dans le même temps, les chercheurs ont utilisé 145 sujets de rapports de projet finaux de l'Université de Stanford pour permettre à ChatGPT de générer des résumés.
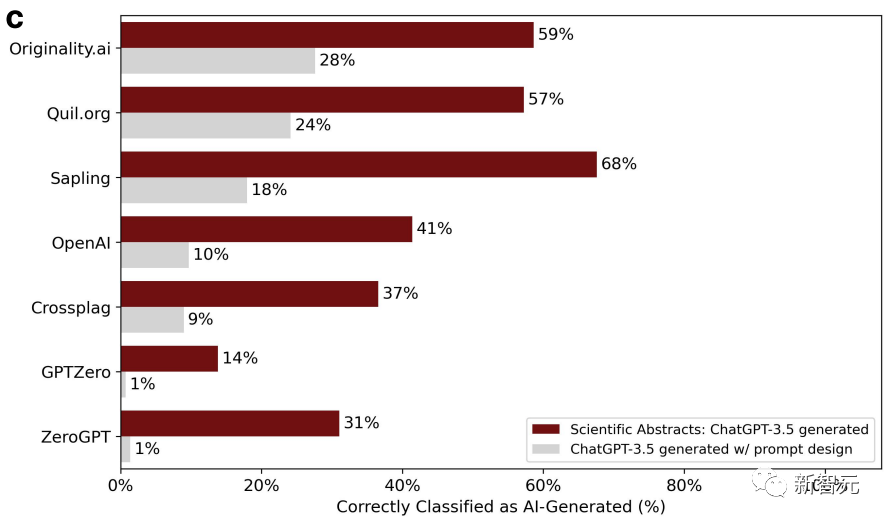
Résumé Après le polissage, la précision du jugement du détecteur continue de décliner.
Les chercheurs ont une fois de plus conclu que les articles raffinés sont facilement mal jugés et sont générés par l'IA. Deux tours valent mieux qu'un.
Détecteur GPT ? Encore un manque de pratique
En bref, dans l'ensemble, les différents détecteurs GPT semblent toujours incapables de saisir la différence la plus essentielle entre la génération d'IA et l'écriture humaine.
L'écriture populaire est également divisée en trois, six ou neuf niveaux. Il est déraisonnable de juger uniquement par la complexité.
Mis à part les facteurs de biais, la technologie elle-même doit également être améliorée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Vue et Element-UI Cascade déroulante Boîte en V Mode en V
Apr 07, 2025 pm 08:06 PM
Vue et Element-UI Cascade déroulante Boîte en V Mode en V
Apr 07, 2025 pm 08:06 PM
Vue et Element-UI Boîtes déroulantes en cascade Points de fosse de liaison V-model: V-model lie un tableau représentant les valeurs sélectionnées à chaque niveau de la boîte de sélection en cascade, pas une chaîne; La valeur initiale de SelectOptions doit être un tableau vide, non nul ou non défini; Le chargement dynamique des données nécessite l'utilisation de compétences de programmation asynchrones pour gérer les mises à jour des données en asynchrone; Pour les énormes ensembles de données, les techniques d'optimisation des performances telles que le défilement virtuel et le chargement paresseux doivent être prises en compte.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
