
 Périphériques technologiques
IA
Dernière nouvelle : OpenAI s'apprête à ouvrir un nouveau modèle en open source ! La prospérité de la communauté open source dépend-elle entièrement de la « charité » des grandes entreprises ?
Périphériques technologiques
IA
Dernière nouvelle : OpenAI s'apprête à ouvrir un nouveau modèle en open source ! La prospérité de la communauté open source dépend-elle entièrement de la « charité » des grandes entreprises ?
Dernière nouvelle : OpenAI s'apprête à ouvrir un nouveau modèle en open source ! La prospérité de la communauté open source dépend-elle entièrement de la « charité » des grandes entreprises ?

Tout à l'heure, selon les dernières nouvelles de The Information, OpenAI est sur le point de publier un nouveau grand modèle de langage open source.
Bien qu'il ne soit pas clair si OpenAI a l'intention d'utiliser le prochain modèle open source pour s'emparer de la part de marché de Vicuna ou d'autres modèles open source.
Mais il est presque certain que les capacités du nouveau modèle ne pourront probablement pas rivaliser avec GPT-4 ou même GPT-3.5.
Après tout, la valorisation de 27 milliards de dollars américains détermine également que les modèles les plus avancés d'OpenAI seront utilisés à des fins commerciales, bien que les deux premières versions de GPT soient open source.
Un porte-parole d'OpenAI n'a pas répondu à une demande de commentaire.

L'explosion open source de la famille alpaga
Il y a dix jours, un document interne de Google a fuité. Dans cet article intitulé "Nous n'avons pas de fossé, et OpenAI non plus", l'auteur déplore le coup dur que l'open source a porté à Google et à OpenAI.
En effet, ni Google ni OpenAI ne semblent sortir vainqueurs de cette course aux armements, car la communauté open source est en train de manger les « bénéfices » qui leur appartiennent.
ChatGPT a déclenché une révolution mondiale du LLM. Cependant, OpenAI n’est pas ouvert, et de nombreuses entreprises et développeurs ne peuvent que regarder et s’inquiéter.
À cette époque, Meta s'est manifesté et a publié LLaMA, apportant des avantages aux développeurs du monde entier.
À l'origine, Meta avait promis que LLaMA serait open source pour les cas d'utilisation de recherche non commerciale, mais qui aurait pensé qu'une semaine seulement après sa sortie, le poids de LLaMA a soudainement fuité sur 4chan, déclenchant des milliers de téléchargements dans un instant.

Cette "fuite épique" a directement changé le domaine LLM open source. En quelques semaines seulement, divers remplacements de ChatGPT ont explosé à une vitesse fulgurante.
Alpaca, Vicuna, Koala, ChatLLaMA, FreedomGPT, ColossalChat... On peut appeler cela une explosion de la "famille Alpaga".

En fait, bien avant Yangtuo, le modèle open source avait brisé les ambitions d’OpenAI.
À cette époque, le nouveau Dall-E 2 faisait sensation sur Internet avec son superbe effet graphique vincentien.
Cependant, alors qu'OpenAI essayait encore de vendre des API, une alternative open source est soudainement apparue : Stable Diffusion.
Avec l'essor rapide de Stable Diffusion, Dall-E 2 a été rapidement oublié par les développeurs.
Big model open source, envie de subvertir les grandes entreprises de la Silicon Valley ?
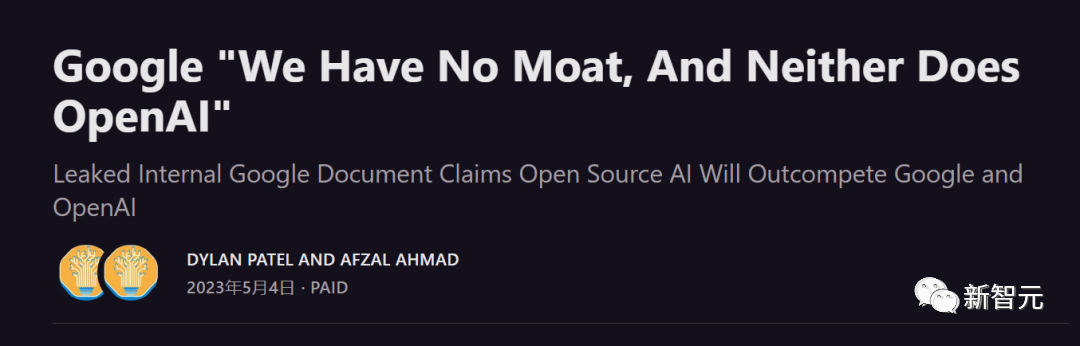
Ion Stoica, professeur d'informatique à l'UC Berkeley, est l'un des chercheurs qui ont utilisé les recherches de Meta pour développer Vicuna.
Pour améliorer les capacités de Vicuna, Stoica et ses collègues s'efforcent d'augmenter le nombre de calculs dans le modèle, ce qui facilitera les tâches impliquant l'inférence, telles que l'écriture de code.
Vicuna est développé par une équipe de Berkeley avec un budget annuel de millions de dollars, dont environ 500 000 $ proviennent de sociétés publiques dont Microsoft, Google et Amazon.

Ion Stoica, professeur d'informatique à l'UC Berkeley, a déclaré que les performances des modèles d'IA gratuits actuels sont "assez proches" des modèles propriétaires de Google et d'OpenAI. Il ne fait aucun doute que la plupart des développeurs finiront par choisir les modèles gratuits.
D'une part, les modèles open source permettent aux développeurs d'utiliser leurs propres données pour résoudre des problèmes spécifiques.
D'un autre côté, le coût de formation d'un modèle comme Vicuna peut même être aussi bas que quelques centaines de dollars, et il n'est pas nécessaire de payer des frais d'utilisation coûteux aux grands fabricants.
https://www.php.cn/link/4d8bd3f7351f4fee76ba17594f070ddd
Modèle exclusif pour vente occasion Le business plan d'un fabricant puissant.
La qualité de Vicuna et l'explosion cambrienne de l'IA open source ont conduit l'ingénieur de Google, Luke Sernau, à avertir ses collègues que Google se concentre trop sur les logiciels propriétaires dans ses efforts pour rattraper OpenAI.
Si les alternatives gratuites et de haute qualité ne comportent aucune restriction d'utilisation, qui paiera pour utiliser les produits Google soumis à des restrictions ? L'IA open source nous dépasse, et Google devrait établir son leadership dans la communauté open source et abandonner un certain contrôle sur nos modèles.
Ce mémo a rapidement trouvé un écho dans l'ensemble de l'industrie - même si Sernau a peut-être surestimé les capacités de l'IA open source et sous-estimé ses coûts et ses risques, la plupart des praticiens conviennent que Meta en bénéficiera très probablement.
Par exemple, Meta utilise des modèles d'IA en interne pour la recommandation de contenu et le positionnement des annonces. Lorsque les développeurs améliorent les modèles de Meta, Meta peut intégrer ces améliorations dans sa propre IA interne.
Le PDG de Meta, Xiao Zha, planifie cela depuis longtemps.
En avril, lors d'une conférence téléphonique avec des analystes, il a déclaré ceci à propos de la stratégie de l'entreprise :
Si l'industrie peut standardiser les outils de base que nous utilisons, alors nous pouvons le faire. C'est encore mieux d'en bénéficier les améliorations des autres.
Google n'adopte pas une approche totalement propriétaire des logiciels d'IA.
En 2020, Google a publié T5, un modèle de langage open source qui permet aux développeurs de créer des logiciels capables d'effectuer des tâches de traduction et de résumé. Par la suite, Google a publié un Flan-T5 plus avancé.
Cependant, selon Stoica et d'autres praticiens, le logiciel publié par Meta peut apporter des améliorations significatives sur la base du modèle de Google, ce qui augmente considérablement la possibilité pour les développeurs de choisir le modèle Meta.
Cependant, Stoica a déclaré que Google a encore deux avantages dans les logiciels open source.
1. Si Google profite de ses données utilisateurs qui ne sont pas ouvertes sur le monde extérieur, le modèle peut être plus performant dans certains domaines professionnels (comme la recommandation de contenu).
Cependant, un porte-parole de Google a déclaré que l'entreprise n'avait pas entraîné son modèle de base sur les données utilisateur existantes.
2. L’expertise de la société de recherche dans la gestion d’infrastructures informatiques à grande échelle lui permet d’exécuter des modèles à moindre coût, y compris pour les clients cloud.
Dans le même temps, OpenAI a déjà pris les devants dans la collecte de données sur la façon dont des millions de personnes interagissent avec ChatGPT, ce qui aidera encore OpenAI à améliorer les logiciels d'IA, sans parler de son accord de coopération avec Microsoft.
La prospérité de l'open source est-elle une « charité » des grands constructeurs ?
Cependant, cette prospérité basée sur l'open source est instable.
La plupart des open source actuels reposent encore sur des modèles géants publiés par de grandes entreprises disposant de fonds solides. Si OpenAI et Meta décident de mettre fin à leurs activités, la communauté open source florissante pourrait devenir déprimée.

Par exemple, de nombreuses alternatives open source sont désormais construites sur la base du LLaMA de Meta.
Alors que d'autres modèles utilisent un vaste ensemble de données publiques appelé Pile, compilé par l'organisation open source à but non lucratif EleutherAI.
EleutherAI existe parce que l'ouverture d'OpenAI signifie qu'un groupe de développeurs peut effectuer de l'ingénierie inverse sur la façon dont GPT-3 est créé, puis créer ses propres modèles pendant son temps libre.
Mais tout peut changer.
OpenAI n'est plus ouvert, et Meta envisage également de restreindre l'open source pour empêcher les startups d'utiliser du code open source pour faire de mauvaises choses.
Joelle Pineau, directrice exécutive de Meta AI, a déclaré qu'ouvrir le code aux étrangers est la bonne chose à faire maintenant, mais il n'est pas sûr que Meta adoptera la même stratégie dans les cinq prochaines années.
Si cette tendance à la fermeture se poursuit, non seulement la communauté open source sera abandonnée, mais la prochaine génération d'avancées en IA reviendra également entre les mains des laboratoires d'IA les plus grands et les moins chers.
De toute évidence, l’avenir de la façon dont les grands modèles d’IA sont fabriqués et utilisés est à la croisée des chemins.
Si OpenAI avait été avare, il n'y aurait pas d'événement open source aujourd'hui
D'autres se demandent également si cette compétition open source gratuite apporte de plus grandes récompenses ou de plus grands risques.
Au même moment où Meta AI publiait LLaMA, Hugging Face a lancé un mécanisme de contrôle de porte. Avant de télécharger des modèles sur la plateforme, les utilisateurs doivent demander l'accès et obtenir l'approbation. Ceci afin de restreindre les personnes ayant des raisons légitimes.

"Je ne suis pas un évangéliste de l'open source", a déclaré Margaret Mitchell, scientifique en chef de l'éthique chez Hugging Face. "Je peux voir l'intérêt de ne pas être open source."
L'un des inconvénients de l'utilisation généralisée des grands modèles est qu'elle peut conduire à la prolifération de produits pornographiques IA.
Mitchell a déjà travaillé chez Google et a fondé l'équipe d'éthique de l'IA. Elle est très consciente des risques d'abus de mannequin. Par conséquent, elle privilégie la publication de modèles Meta AI de manière contrôlée.
Dans le même temps, OpenAI ferme également le robinet. Lorsque GPT-4 a été publié, il n'a pas annoncé de détails tels que l'architecture (y compris la taille du modèle), le matériel, les calculs de formation, la construction des ensembles de données, les méthodes de formation, etc. La raison était « compte tenu du paysage concurrentiel et de l'impact sur la sécurité des grandes entreprises ». -des modèles à l'échelle comme GPT-4." .
Cette limitation reflète le changement de mentalité d’OpenAI. Le co-fondateur et scientifique en chef Ilya Sutskever a déclaré que l’ouverture passée d’OpenAI était une erreur.
Sandhini Agarwal, chercheuse en politiques chez OpenAI, a déclaré : « Avant, si quelque chose était open source, peut-être qu'un petit groupe de bricoleurs s'en soucierait. Mais maintenant, l'environnement tout entier a changé. L'open source peut vraiment accélérer le développement et conduire à compétition."
Il y a trois ans, si OpenAI avait adhéré aux mêmes principes lors de l'annonce des détails de GPT-3, il n'y aurait pas eu l'émergence d'EleutherAI, et il n'y aurait pas eu d'innovation open source vigoureuse.
Aujourd'hui, EleutherAI joue un rôle central dans l'écosystème open source. Pile est utilisé pour former plusieurs projets open source, y compris StableLM de Stability AI.

Mais avec le verrouillage des GPT-4, 5 et 6, la communauté open source pourrait une fois de plus être laissée pour compte par quelques grandes entreprises.
Ils resteront coincés dans le modèle de la génération précédente, et s'ils veulent progresser, ils ne pourront le faire qu'à huis clos.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravelelognent Model Retrieval: Faconttement l'obtention de données de base de données Eloquentorm fournit un moyen concis et facile à comprendre pour faire fonctionner la base de données. Cet article présentera en détail diverses techniques de recherche de modèles éloquentes pour vous aider à obtenir efficacement les données de la base de données. 1. Obtenez tous les enregistrements. Utilisez la méthode All () pour obtenir tous les enregistrements dans la table de base de données: usApp \ Modèles \ Post; $ poters = post :: all (); Cela rendra une collection. Vous pouvez accéder aux données à l'aide de Foreach Loop ou d'autres méthodes de collecte: ForEach ($ PostsAs $ POST) {echo $ post->
