
 Périphériques technologiques
IA
En tête de la liste internationale faisant autorité en matière d'analyse sémantique conversationnelle SParC et CoSQL, le nouveau modèle de pré-formation des connaissances sur les tables de dialogue à plusieurs tours, interprétation STAR
Périphériques technologiques
IA
En tête de la liste internationale faisant autorité en matière d'analyse sémantique conversationnelle SParC et CoSQL, le nouveau modèle de pré-formation des connaissances sur les tables de dialogue à plusieurs tours, interprétation STAR
En tête de la liste internationale faisant autorité en matière d'analyse sémantique conversationnelle SParC et CoSQL, le nouveau modèle de pré-formation des connaissances sur les tables de dialogue à plusieurs tours, interprétation STAR

Dans l'ère actuelle d'Internet en développement rapide, divers types de données émergent constamment. Parmi elles, les données de table sont les plus couramment utilisées. Les tables sont une sorte de données structurées générales. Nous pouvons concevoir des instructions de requête SQL en fonction de nos besoins d'obtention. tables, mais nécessite souvent des coûts de conception et d’apprentissage plus élevés. À l'heure actuelle, la tâche d'analyse Text-to-SQL est particulièrement importante, selon différents scénarios de dialogue, elle est également divisée en analyse Text-to-SQL à un seul tour et en analyse Text-to-SQL à plusieurs tours. étudie les plus difficiles et les plus proches Plusieurs séries de tâches d'analyse Text-to-SQL pour les applications du monde réel.
Récemment, l'Académie Alibaba DAMO et l'Institut de technologie avancée de Shenzhen de l'Académie chinoise des sciences ont proposé un modèle de pré-formation orienté requête SQL STAR pour plusieurs cycles d'analyse sémantique Text-to-SQL. Désormais, STAR occupe la première place sur les listes SParC et CoSQL depuis 10 mois consécutifs. Le document de recherche a été accepté par EMNLP 2022 Findings, une conférence internationale dans le domaine du traitement du langage naturel.

- Adresse de papier: https://arxiv.org/abs/2210.11888
- code Adresse: https://github.com/alibabaresearch/damo-convai/ tree/main/star
STAR est un modèle de langage de pré-formation de connaissances de table de dialogue multi-tours nouveau et efficace. Ce modèle utilise principalement deux objectifs de pré-formation pour suivre la sémantique contextuelle complexe dans les dialogues multi-tours et. Le traçage de l'état des schémas de bases de données est modélisé dans le but d'améliorer les requêtes en langage naturel et la représentation codée des schémas de bases de données dans les flux de conversation.
La recherche a été évaluée sur SParC et CoSQL, les listes faisant autorité en matière d'analyse sémantique conversationnelle. Dans le cadre d'une comparaison équitable de modèles en aval, STAR a été comparé au meilleur modèle de pré-formation à table multi-tours précédent, SCoRe, sur l'ensemble de données SParC QM/IM. s'est amélioré de 4,6 %/3,3 %, et QM/IM s'est considérablement amélioré de 7,4 %/8,5 % sur l'ensemble de données CoSQL. En particulier, CoSQL a plus de changements contextuels que l'ensemble de données SParC, ce qui vérifie l'efficacité de la tâche de pré-formation proposée dans cette étude.
Introduction au contexte
Afin de permettre aux utilisateurs d'interagir avec la base de données via un dialogue en langage naturel même s'ils ne sont pas familiers avec la syntaxe SQL, plusieurs séries de tâches d'analyse Text-to-SQL ont vu le jour. un lien entre l'utilisateur et la base de données. Un pont entre les utilisateurs, convertissant les questions en langage naturel lors des interactions en instructions de requête SQL exécutables.
Les modèles pré-entraînés ont brillé sur diverses tâches de PNL ces dernières années. Cependant, en raison des différences inhérentes entre les tables et les langages naturels, les modèles de langage pré-entraînés ordinaires (tels que BERT, RoBERTa) sont inefficaces sur cette tâche. Les performances optimales ne peuvent pas être atteintes, c'est pourquoi le modèle tabulaire pré-entraîné (TaLM) [1-5] a vu le jour. Généralement, les modèles tabulaires pré-entraînés (TaLM) doivent traiter deux problèmes principaux, notamment la manière de modéliser des dépendances complexes (références, décalages d'intention) entre les requêtes contextuelles et la manière d'utiliser efficacement les résultats SQL générés historiquement. Pour résoudre les deux problèmes fondamentaux ci-dessus, les modèles tabulaires pré-entraînés existants présentent les défauts suivants :
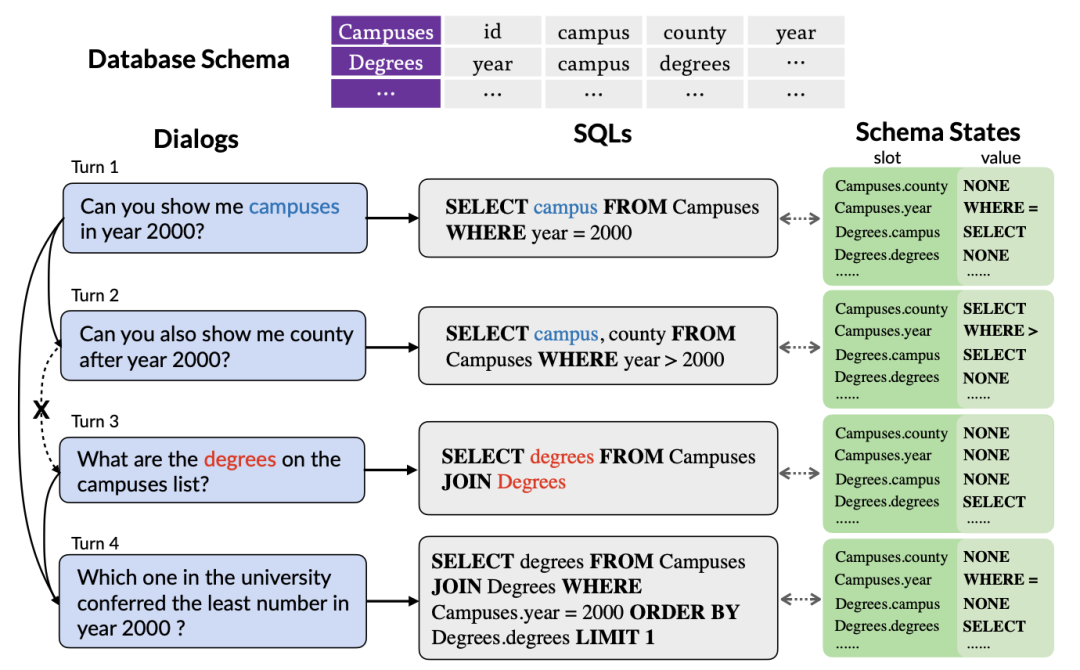
Figure 1. Un exemple d'analyse Text-to-SQL multi-tours dépendant du contexte.
Premièrement, le modèle de pré-entraînement de table existant explore uniquement les informations contextuelles des requêtes en langage naturel, sans prendre en compte les informations d'état interactives contenues dans les instructions de requête SQL historiques. Ces informations peuvent souvent être utilisées de manière plus précise. Résumez l’intention de l’utilisateur sous une forme précise et compacte. Par conséquent, la modélisation et le suivi des informations SQL historiques peuvent mieux capturer l'intention de la série de requêtes en cours, générant ainsi avec plus de précision les instructions de requête SQL correspondantes. Comme le montre la figure 1, puisque le nom de la table « Compuses » est mentionné lors du premier cycle de requête SQL, la table est susceptible d'être à nouveau sélectionnée lors du deuxième cycle de requête SQL. Il est donc particulièrement important de suivre l'état du nom de la table "Compuses" important.
Deuxièmement, étant donné que l'utilisateur peut ignorer les entités mentionnées dans l'historique de la conversation ou introduire certaines références, ce qui entraîne un manque d'informations de dialogue dans le cycle actuel, les tâches d'analyse Text-to-SQL à plusieurs tours doivent modéliser efficacement les informations contextuelles pour mieux analyser le cycle actuel de dialogue en langage naturel. Comme le montre la figure 1, le deuxième cycle de dialogue a omis les « campus en 2000 » mentionnés dans le premier cycle de dialogue. Cependant, la plupart des modèles de tables pré-entraînés existants ne prennent pas en compte les informations contextuelles, mais modélisent séparément chaque cycle de dialogue en langage naturel. Bien que SCoRe [1] modélise les informations de changement de contexte en prédisant les étiquettes de changement de contexte entre deux cycles de dialogue adjacents, il ignore les informations de contexte plus complexes et ne peut pas suivre les informations de dépendance entre les dialogues longue distance. Par exemple, dans la figure 1, en raison du changement de contexte entre les deuxième et troisième tours de dialogue, SCoRe ne peut pas capturer les informations de dépendance longue distance entre les premier et quatrième tours de dialogue.
Inspirée de la tâche de suivi de l'état de conversation dans les dialogues multi-tours, cette recherche propose un objectif de pré-entraînement basé sur le suivi de l'état des modèles pour suivre l'état des modèles du SQL contextuel visant le problème des dépendances sémantiques complexes entre les questions ; dialogues multi-tours, cette recherche propose une méthode de suivi des dépendances du dialogue pour capturer les dépendances sémantiques complexes entre plusieurs tours de dialogue, et propose une méthode d'apprentissage contrastif basée sur le poids pour mieux modéliser la relation positive et négative entre les dialogues.
Définition du problème
Cette étude donne d'abord les notations et les définitions de problèmes impliquées dans plusieurs séries de tâches d'analyse Text-to-SQL. 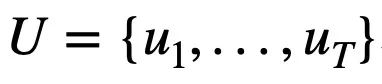 représente T séries de requêtes en langage naturel, plusieurs séries d'interactions de dialogue texte vers SQL de la requête, où
représente T séries de requêtes en langage naturel, plusieurs séries d'interactions de dialogue texte vers SQL de la requête, où 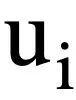 représente la ième série de questions en langage naturel et chaque série de dialogue en langage naturel
représente la ième série de questions en langage naturel et chaque série de dialogue en langage naturel 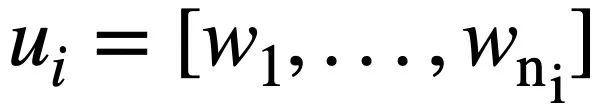 contient
contient 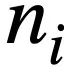 jetons. De plus, il existe une base de données interactive s, qui contient N tables
jetons. De plus, il existe une base de données interactive s, qui contient N tables 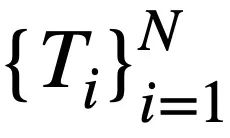 , et toutes les tables contiennent m noms de tables et noms de colonnes,
, et toutes les tables contiennent m noms de tables et noms de colonnes, 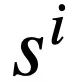 représente le i-ième nom de table ou nom de colonne dans le schéma de base de données s. En supposant que le cycle actuel est le ième tour, le but de la tâche d'analyse Text-to-SQL est de se baser sur le cycle actuel de requêtes en langage naturel
représente le i-ième nom de table ou nom de colonne dans le schéma de base de données s. En supposant que le cycle actuel est le ième tour, le but de la tâche d'analyse Text-to-SQL est de se baser sur le cycle actuel de requêtes en langage naturel 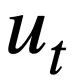 , de requêtes historiques
, de requêtes historiques  , de schémas de base de données et de la requête SQL prédite. instruction du tour précédent
, de schémas de base de données et de la requête SQL prédite. instruction du tour précédent 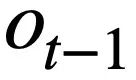 , Générez l'instruction de requête SQL
, Générez l'instruction de requête SQL 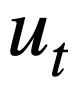 correspondant au cycle en cours de requête en langage naturel
correspondant au cycle en cours de requête en langage naturel 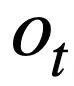 .
.
Description de la méthode
Comme le montre la figure 2, cette étude propose un cadre de pré-formation à plusieurs tables rondes basé sur des conseils SQL, utilisant pleinement les informations structurées des données historiques. SQL pour enrichir les représentations conversationnelles afin de modéliser plus efficacement des informations contextuelles complexes. Figure 2. Cadre modèle de STAR.
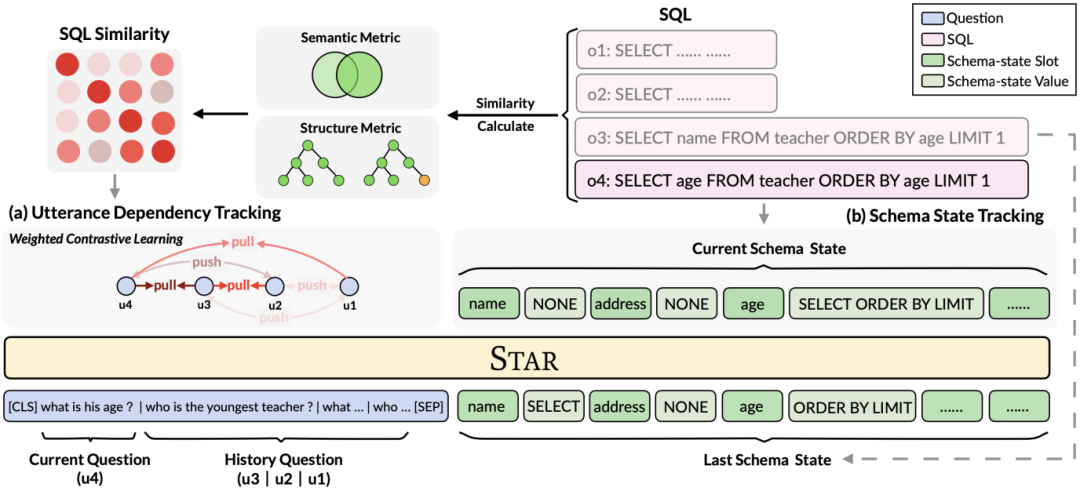
Plus précisément, cette étude propose des objectifs de pré-entraînement basés sur le suivi de l'état du modèle et le suivi des dépendances du dialogue, respectivement, pour plusieurs tours. l'intention des requêtes SQL et des questions en langage naturel dans les interactions. (1) Dans une situation de dialogue multi-tours, la requête SQL du dialogue en cours dépend des informations SQL contextuelles. Par conséquent, inspirée de la tâche de suivi de l'état de conversation dans les dialogues multi-tours, cette recherche propose un Schema State Tracking (Schema State). Tracking, l'objectif de pré-formation des tables de SST) suit l'état du schéma des instructions de requête SQL contextuelles (ou des demandes des utilisateurs) de manière auto-supervisée. (2) Pour le problème des dépendances sémantiques complexes entre les questions en langage naturel dans les dialogues à plusieurs tours, un objectif de pré-formation sur table basé sur le suivi de la dépendance de l'énoncé (UDT) est proposé, et une méthode d'apprentissage contrastif basée sur le poids est utilisée pour mieux apprendre. Représentation des fonctionnalités pour les requêtes en langage naturel. Ce qui suit décrit en détail les deux objectifs de pré-entraînement du tableau. Tableau d'objectif de pré-entraînement basé sur le suivi de l'état du modèle
Cette recherche propose un objectif de pré-formation sur les tables basé sur le suivi de l'état du schéma, qui suit l'état du schéma (ou la demande de l'utilisateur) des instructions de requête SQL contextuelles (ou des demandes de l'utilisateur) de manière auto-supervisée, dans le but de prédire la valeur de l'emplacement de schéma. Plus précisément, l'étude suit l'état d'interaction d'une session Text-to-SQL sous la forme d'un état de schéma, où l'emplacement est le schéma de la base de données (c'est-à-dire les noms de colonnes de toutes les tables) et la valeur de l'emplacement correspondant est le mot-clé SQL. En prenant la requête SQL de la figure 3 comme exemple, la valeur de l'emplacement de mode "[car_data]" est le mot-clé SQL "[SELECT]". Premièrement, l'étude convertit l'instruction de requête SQL 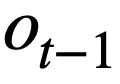 prédite au tour t - 1 sous la forme d'un ensemble d'états de modèle. Étant donné que les emplacements d'état du schéma sont les noms de colonnes de toutes les tables de la base de données, les valeurs qui n'apparaissent pas dans l'état du schéma correspondant à l'instruction de requête SQL
prédite au tour t - 1 sous la forme d'un ensemble d'états de modèle. Étant donné que les emplacements d'état du schéma sont les noms de colonnes de toutes les tables de la base de données, les valeurs qui n'apparaissent pas dans l'état du schéma correspondant à l'instruction de requête SQL 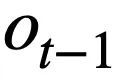 sont définies sur [NONE]. Comme le montre la figure 3, cette étude utilise m états de mode
sont définies sur [NONE]. Comme le montre la figure 3, cette étude utilise m états de mode 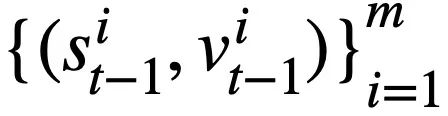 pour représenter l'instruction de requête SQL
pour représenter l'instruction de requête SQL 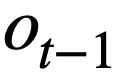 , où
, où 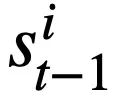 représente l'emplacement du i-ème état de mode et
représente l'emplacement du i-ème état de mode et 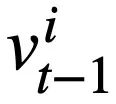 représente la valeur du mode. État. Pour le tour t, l'objectif du suivi de l'état du modèle est de prédire l'état du modèle
représente la valeur du mode. État. Pour le tour t, l'objectif du suivi de l'état du modèle est de prédire l'état du modèle 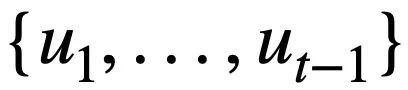 du tour t étant donné toutes les questions historiques en langage naturel
du tour t étant donné toutes les questions historiques en langage naturel 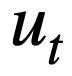 , la question actuelle
, la question actuelle 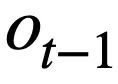 et la série précédente d'instructions de requête SQL
et la série précédente d'instructions de requête SQL 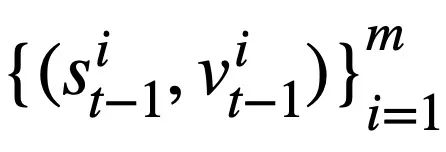 Le valeur
Le valeur 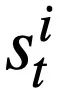 de chaque emplacement d'état de mode
de chaque emplacement d'état de mode 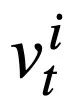 de l'instruction de requête SQL t-round. C'est-à-dire qu'au tour t, l'entrée
de l'instruction de requête SQL t-round. C'est-à-dire qu'au tour t, l'entrée 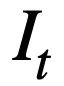 à la cible de pré-entraînement de suivi de l'état du modèle est :
à la cible de pré-entraînement de suivi de l'état du modèle est :
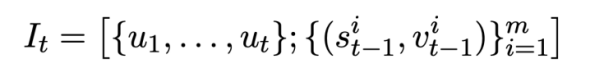
Étant donné que chaque état de modèle 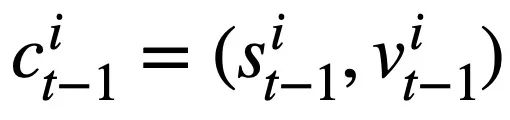 contient plusieurs mots, une couche d'attention est appliquée pour obtenir la représentation de
contient plusieurs mots, une couche d'attention est appliquée pour obtenir la représentation de 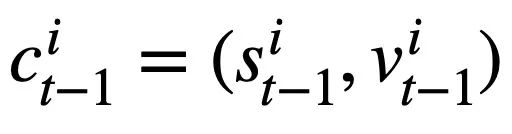 . Plus précisément, étant donné la représentation contextualisée de sortie
. Plus précisément, étant donné la représentation contextualisée de sortie  ( l est l'indice de départ de
( l est l'indice de départ de 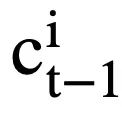 ). Pour chaque état de mode
). Pour chaque état de mode 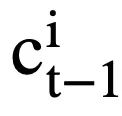 , la représentation consciente de l'attention
, la représentation consciente de l'attention 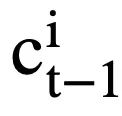 de l'état de mode
de l'état de mode 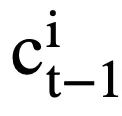 peut être calculée comme suit :
peut être calculée comme suit :
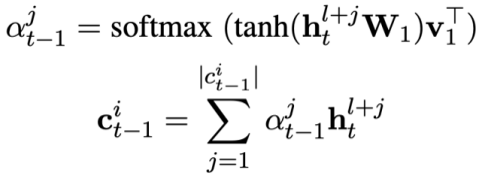
, puis prédire l'état de mode du problème actuel :
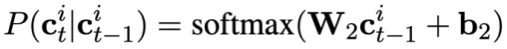
Enfin, la fonction de perte pré-entraînement pour le suivi de l'état du mode peut être définie comme :
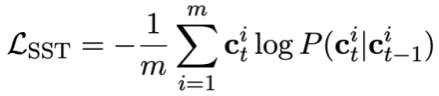
Objectif de pré-entraînement basé sur le suivi de la dépendance au dialogue
Cette étude propose un pré-entraînement objectif de suivi des dépendances d'énoncé, une méthode d'apprentissage contrastif basée sur le poids est utilisée pour capturer les dépendances sémantiques complexes entre les questions en langage naturel dans chaque énoncé Text-to-SQL. Un défi clé dans l’apprentissage contrastif basé sur le poids est de savoir comment construire des exemples d’étiquettes positives et négatives appropriées de manière auto-supervisée. Intuitivement, des paires d’exemples négatifs peuvent être construites en sélectionnant des questions en langage naturel provenant de différentes conversations. Cependant, construire des paires de questions positives n'est pas trivial car les questions actuelles peuvent ne pas être liées aux questions historiques pour lesquelles le changement de sujet s'est produit, comme les deuxième et troisième énoncés présentés dans la figure 1 . Par conséquent, cette étude traite les questions en langage naturel dans la même conversation comme des paires d’exemples positifs et leur attribue différents scores de similarité. SQL est une indication d'énoncé utilisateur hautement structurée. Par conséquent, en mesurant la similarité entre le SQL actuel et le SQL historique, nous pouvons obtenir des pseudo-étiquettes sémantiquement dépendantes des questions en langage naturel pour obtenir des scores de similarité pour différentes constructions d'instructions, guidant ainsi la construction du contexte. Cette étude propose une méthode pour mesurer la similarité SQL d'un point de vue à la fois sémantique et structurel. Comme le montre la figure 3 :

Figure 3. Deux méthodes de calcul de la similarité des instructions SQL.
Calcul de similarité SQL basé sur la sémantique Cette étude calcule la similarité entre deux instructions de requête SQL État du modèle la similarité est utilisée pour mesurer la similarité sémantique entre eux. Plus précisément, comme le montre la figure 3, cette méthode obtiendra le statut de mode  #🎜 des deux instructions de requête SQL
#🎜 des deux instructions de requête SQL 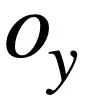 et
et 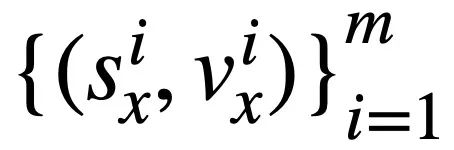 respectivement. 🎜# et
respectivement. 🎜# et 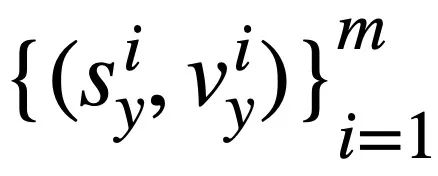 . Ensuite, l'étude adopte la similarité Jaccard pour calculer la similarité sémantique entre eux où
. Ensuite, l'étude adopte la similarité Jaccard pour calculer la similarité sémantique entre eux où  signifie
signifie
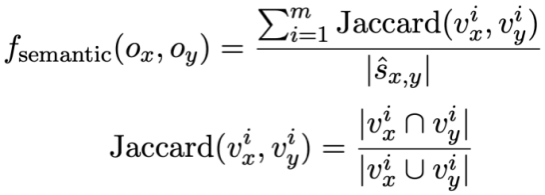 et # 🎜🎜#
et # 🎜🎜#
correspondent à l'état du mode Le nombre d'états de motif distincts dont la valeur n'est pas [NONE]. 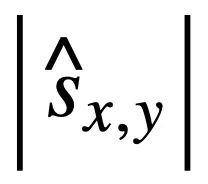
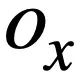
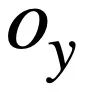 Calcul de similarité SQL basé sur la structure#🎜🎜 #
Calcul de similarité SQL basé sur la structure#🎜🎜 #
# 🎜🎜 #, comme le montre la figure 3. Deux arbres SQL étant donné la requête SQL et 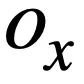 #🎜 🎜# et
#🎜 🎜# et 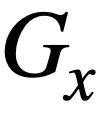 , cette étude utilise l'algorithme de Weisfeiler-Lehman pour calculer le score de similarité structurelle
, cette étude utilise l'algorithme de Weisfeiler-Lehman pour calculer le score de similarité structurelle 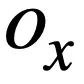 , la formule est la suivante : # 🎜 🎜#
, la formule est la suivante : # 🎜 🎜#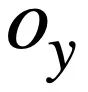
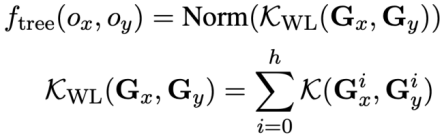
En résumé, cette étude définit deux instructions de requête SQL 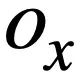 et Le score de similarité de
et Le score de similarité de 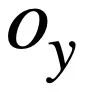 est la suivante :
est la suivante :
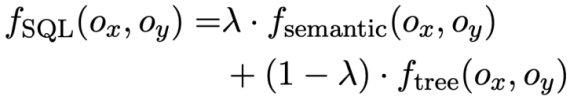
Poids -perte contrastive basée sur Après avoir obtenu la similarité SQL, cette étude utilise l'apprentissage contrastif pondéré pour rapprocher les représentations de questions en langage naturel sémantiquement similaires dans la conversation, et la sémantique Refoulement de représentation pour des problèmes de langage naturel différents. Plus précisément, l'étude utilise d'abord un mécanisme d'attention pour apprendre la représentation d'entrée 🎜#Ensuite, l'étude minimise la fonction de perte contrastive pondérée pour optimiser le réseau global : Enfin, afin d'apprendre les requêtes en langage naturel et la représentation de schéma de base de données basée En fonction du contexte, cette étude adopte également un objectif de pré-formation basé sur la modélisation sémantique des masques, et la fonction de perte est exprimée comme suit. Sur la base des trois objectifs d'entraînement ci-dessus, cette étude définit une fonction de perte articulaire basée sur l'homoscédasticité : 🎜🎜#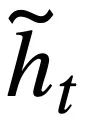 est un paramètre pouvant être entraîné.
est un paramètre pouvant être entraîné.
Effet expérimental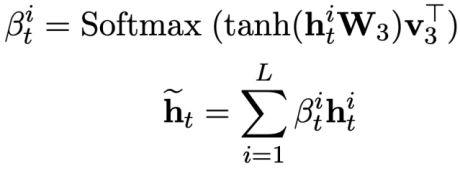
Dataset
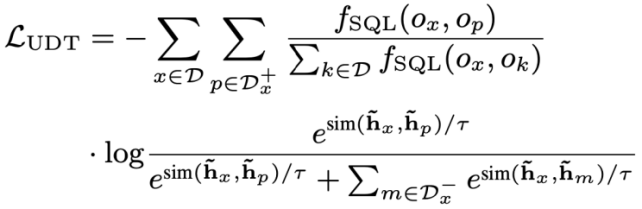 #🎜 🎜 # Cette étude a vérifié l'efficacité du modèle STAR sur deux ensembles de données d'analyse sémantique conversationnelle faisant autorité, SParC et CoSQL. Parmi eux, SParC est un ensemble de données d'analyse Text-to-SQL multi-domaines, contenant environ 4 300 interactions multi-tours et plus de 12 000 paires question-instruction de requête SQL en langage naturel. CoSQL est un texte conversationnel inter-domaines ; Ensemble de données d'analyse to-SQL. Ensemble de données d'analyse to-SQL, contenant environ 3 000 interactions conversationnelles et plus de 10 000 paires d'instructions de requête SQL en langage naturel. Comparé à SParC, le contexte de conversation de CoSQL est sémantiquement plus pertinent et la syntaxe des instructions de requête SQL est plus complexe.
#🎜 🎜 # Cette étude a vérifié l'efficacité du modèle STAR sur deux ensembles de données d'analyse sémantique conversationnelle faisant autorité, SParC et CoSQL. Parmi eux, SParC est un ensemble de données d'analyse Text-to-SQL multi-domaines, contenant environ 4 300 interactions multi-tours et plus de 12 000 paires question-instruction de requête SQL en langage naturel. CoSQL est un texte conversationnel inter-domaines ; Ensemble de données d'analyse to-SQL. Ensemble de données d'analyse to-SQL, contenant environ 3 000 interactions conversationnelles et plus de 10 000 paires d'instructions de requête SQL en langage naturel. Comparé à SParC, le contexte de conversation de CoSQL est sémantiquement plus pertinent et la syntaxe des instructions de requête SQL est plus complexe.
Benchmark Model En termes de modèle de base, l'étude a comparé les méthodes suivantes : (1) GAZP [6], qui synthétise le dialogue en langage naturel en combinant un modèle d'analyse sémantique avant et un modèle de génération de dialogue arrière - Entraînement des données de paires d'instructions de requête SQL et sélectionne enfin les données avec une cohérence de cycle pour s'adapter au modèle d'analyse sémantique directe. (2) EditSQL [7] prend en compte les informations de l'historique des interactions et améliore la qualité de génération SQL du cycle de dialogue en cours en prédisant les instructions de requête SQL au moment précédant l'édition. (3) IGSQL [8] propose un modèle de codage de graphe interactif de schéma de base de données, qui utilise les informations historiques du schéma de base de données pour capturer les informations historiques d'entrée en langage naturel, et introduit un mécanisme de déclenchement dans l'étape de décodage. (4) IST-SQL [9], inspiré de la tâche de suivi de l'état de conversation, définit deux états interactifs, l'état du schéma et l'état SQL, et met à jour l'état en fonction de la dernière instruction de requête SQL prédite à chaque tour. (5) R2SQL [10] propose un cadre de graphe dynamique pour modéliser les interactions complexes entre les dialogues et les schémas de base de données dans les flux de dialogue, et enrichit la représentation contextuelle des dialogues et des schémas de base de données grâce à un mécanisme de dégradation dynamique de la mémoire. (6) PICARD [11] propose une analyse sémantique incrémentale pour contraindre le modèle de décodage autorégressif du modèle de langage. À chaque étape de décodage, il recherche des séquences de sortie légales en limitant l'acceptabilité des résultats de décodage. (7) DELTA [12], utilise d'abord un modèle de réécriture de dialogue pour résoudre le problème d'intégrité du contexte de dialogue, puis introduit le dialogue complet dans un modèle d'analyse sémantique Text-to-SQL à un tour pour obtenir l'instruction de requête SQL finale. (8) HIE-SQL [13], d'un point de vue multimodal, traite le langage naturel et SQL comme deux modalités, explore les informations de dépendance de contexte entre toutes les conversations historiques et l'instruction de requête SQL prédite par la phrase précédente, et propose une approche bimodale pré- modèle formé et conçu un graphe de liens modaux entre les conversations et les instructions de requête SQL.
Résultats expérimentaux globaux Comme le montre la figure 4, il ressort des résultats expérimentaux que le modèle STAR fonctionne bien mieux que les autres méthodes comparatives sur les deux ensembles de données SParC et CoSQL. En termes de comparaison des modèles de pré-formation, le modèle STAR dépasse de loin les autres modèles de pré-formation (tels que BERT, RoBERTa, GRAPPA, SCoRe). Sur l'ensemble de données de développement CoSQL, par rapport au modèle SCoRE, le score QM a augmenté de 7,4. % et le score IM a augmenté de 7,5 %. En termes de comparaison de modèles Text-to-SQL en aval, le modèle LGESQL utilisant STAR comme base du modèle pré-entraîné est bien meilleur que les méthodes en aval qui utilisent d'autres modèles de langage pré-entraînés comme base, par exemple, l'actuel. Le modèle LGESQL le plus performant utilise GRAPPA comme modèle de base.
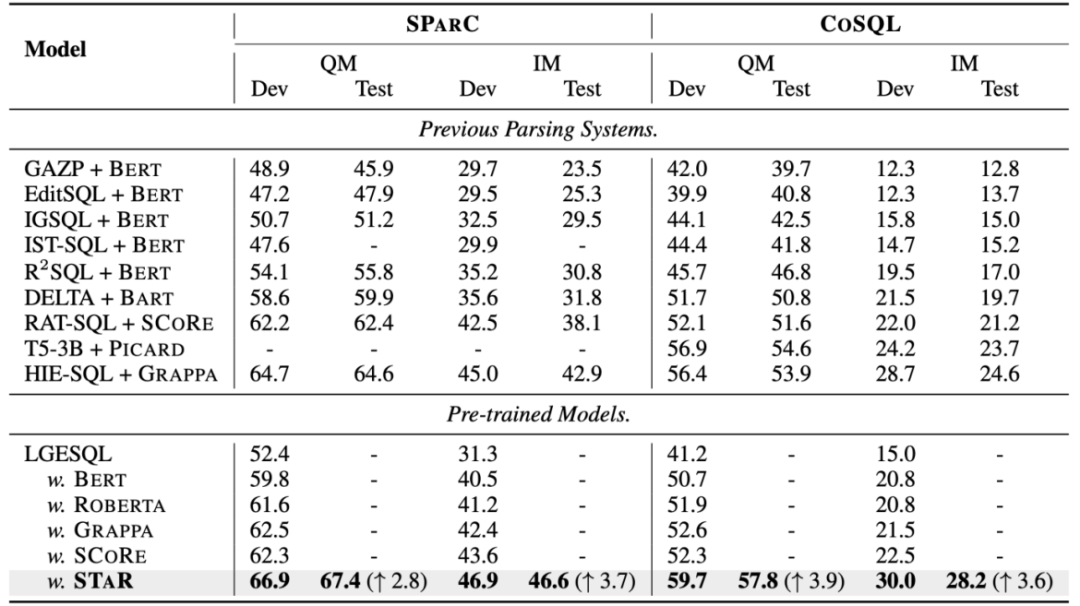
Figure 4. Résultats expérimentaux sur les ensembles de données SParC et CoSQL
Résultats de l'expérience d'ablation Cet article complète également l'expérience d'ablation complète pour illustrer le modèle STAR .l'efficacité de chaque module. Les résultats de l'expérience d'ablation sont présentés dans la figure 5. Lorsque les cibles de pré-entraînement SST ou UDT sont supprimées, l'effet diminue considérablement. Cependant, les résultats expérimentaux combinant toutes les cibles de pré-entraînement ont obtenu les meilleurs résultats sur tous les ensembles de données. , ce qui illustre cette validité SST et UDT. En outre, cette étude a mené d'autres expériences sur deux méthodes de calcul de similarité SQL dans UDT. Comme le montre la figure 6, les deux méthodes de calcul de similarité SQL peuvent améliorer l'effet du modèle STAR, et l'effet combiné est le meilleur.
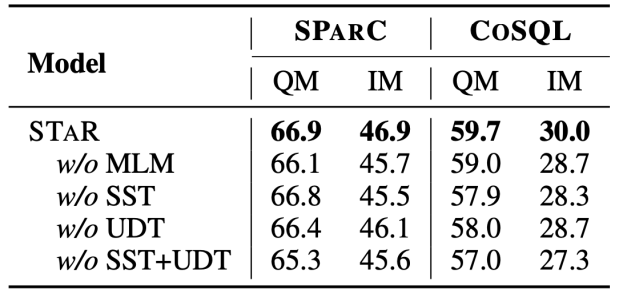
Figure 5. Résultats expérimentaux d'ablation pour les cibles de pré-entraînement.
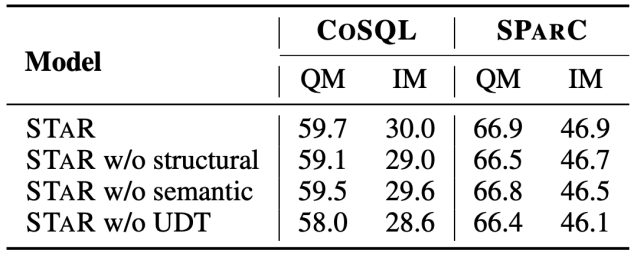
Figure 6. Résultats expérimentaux d'ablation pour la méthode de calcul de similarité SQL.
Effets du modèle d'échantillons de différentes difficultés Comme le montre la figure 7, à partir des résultats expérimentaux d'échantillons de différentes difficultés sur les deux ensembles de données SParC et CoSQL, on peut voir que l'effet de prédiction du modèle STAR sur des échantillons de diverses difficultés Les difficultés sont bien meilleures que les autres comparaisons. La méthode est efficace même dans les échantillons extra-durs les plus difficiles.
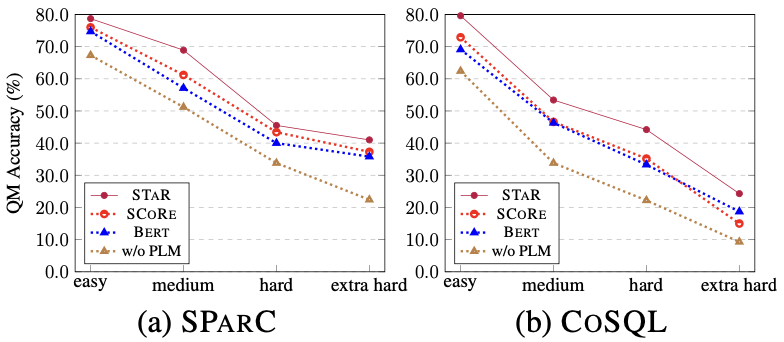
Figure 7. Résultats expérimentaux d'échantillons de difficulté différente sur des ensembles de données SParC et CoSQL.
Effets du modèle de différentes séries d'échantillons Comme le montre la figure 8, à partir des résultats expérimentaux de différentes séries d'échantillons sur les deux ensembles de données de SParC et CoSQL, on peut voir que comme la conversation tourne Avec l'augmentation du temps, l'indice QM du modèle de base diminue fortement, tandis que le modèle STAR peut montrer des performances plus stables même aux troisième et quatrième tours. Cela montre que le modèle STAR peut mieux suivre et explorer les états d'interaction dans l'historique de la conversation pour aider le modèle à mieux analyser la conversation en cours.
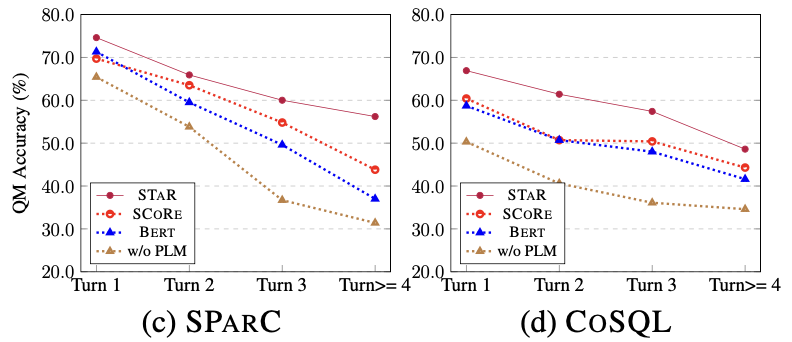
Figure 8. Résultats expérimentaux de différentes séries d'échantillons sur des ensembles de données SParC et CoSQL.
Analyse de cas Afin d'évaluer l'effet réel du modèle STAR, cette étude a sélectionné deux échantillons de l'ensemble de validation CoSQL et a comparé les requêtes SQL générées par le modèle SCoRe et le modèle STAR. dans la déclaration de la figure 9. À partir du premier exemple, nous pouvons voir que le modèle STAR peut bien utiliser les informations sur l'état du schéma du SQL historique (par exemple, [car_names.Model]), générant ainsi correctement l'instruction de requête SQL pour le troisième tour de dialogue, tandis que le SCoRe Le modèle ne peut pas suivre les informations sur l'état de ce mode. Dans le deuxième exemple, le modèle STAR suit efficacement les dépendances conversationnelles à long terme entre le premier et le quatrième cycle d'énoncés, et en suivant et en référençant « le nombre de » messages dans le deuxième cycle de conversations, dans le quatrième. Le mot-clé SQL [ SELECT COUNT (*)] est correctement généré dans l'instruction de requête SQL ronde. Cependant, le modèle SCoRe ne peut pas suivre cette dépendance à long terme et est perturbé par la troisième série d'énoncés pour générer des instructions de requête SQL incorrectes.
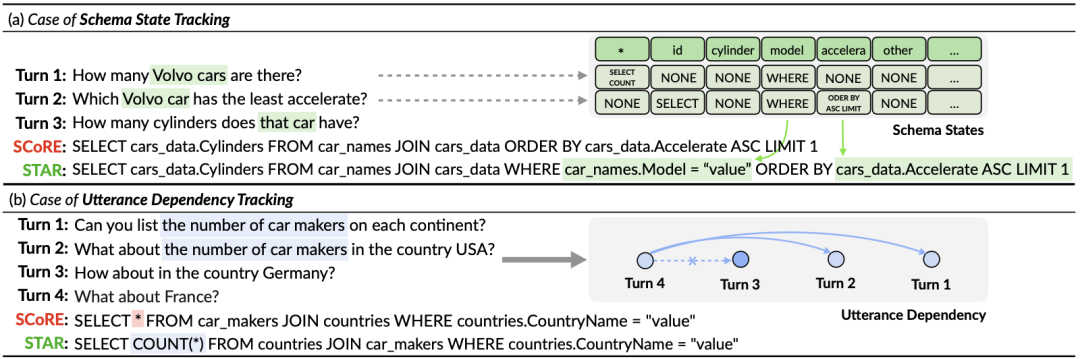
Figure 9. Exemple d'analyse.
Communauté open source du modèle ModelScope
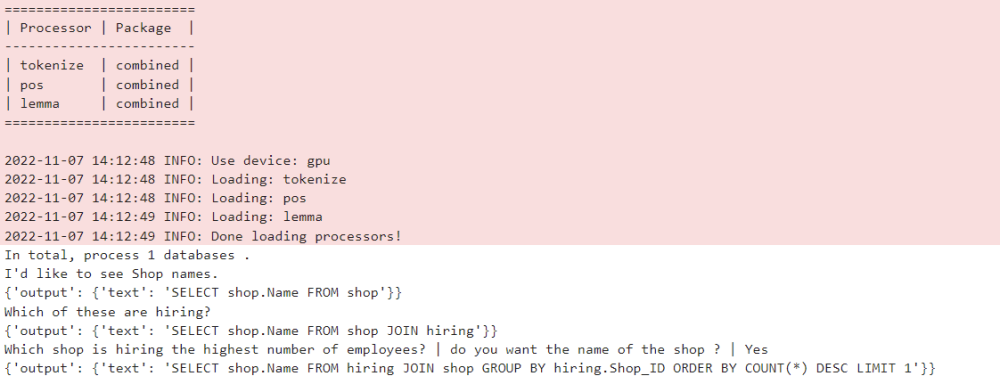
Le modèle formé sur l'ensemble de données CoSQL dans cet article a été intégré à la communauté open source du modèle ModelScope. Les lecteurs peuvent sélectionner directement l'environnement GPU V100 dans le bloc-notes et utiliser le modèle de démonstration pour plusieurs séries de tâches d'analyse sémantique Text-to-SQL via un simple pipeline.
Résumé
Dans cet article, l'équipe de recherche a proposé un modèle de pré-formation des connaissances multi-tables rondes nouveau et efficace (modèle STAR). Pour les tâches d'analyse sémantique Text-to-SQL à plusieurs tours, le modèle STAR propose des objectifs de pré-formation de table basés sur le suivi de l'état du schéma et le suivi des dépendances de dialogue, qui suivent respectivement l'intention des instructions de requête SQL et des questions en langage naturel dans les interactions à plusieurs tours. . Le modèle STAR a obtenu de très bons résultats dans deux listes d'analyse sémantique multi-tours faisant autorité, occupant la première place de la liste pendant 10 mois consécutifs.
Enfin, les étudiants intéressés par le groupe SIAT-NLP des Instituts de technologie avancée de Shenzhen, Académie chinoise des sciences sont invités à postuler pour des postes postdoctoraux/master/stage. Veuillez envoyer votre CV à min.yang. @siat.ac.cn.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 J'ai essayé le codage d'ambiance avec Cursor Ai et c'est incroyable!
Mar 20, 2025 pm 03:34 PM
J'ai essayé le codage d'ambiance avec Cursor Ai et c'est incroyable!
Mar 20, 2025 pm 03:34 PM
Le codage des ambiances est de remodeler le monde du développement de logiciels en nous permettant de créer des applications en utilisant le langage naturel au lieu de lignes de code sans fin. Inspirée par des visionnaires comme Andrej Karpathy, cette approche innovante permet de dev
 Top 5 Genai Lunets de février 2025: GPT-4.5, Grok-3 et plus!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Lunets de février 2025: GPT-4.5, Grok-3 et plus!
Mar 22, 2025 am 10:58 AM
Février 2025 a été un autre mois qui change la donne pour une IA générative, nous apportant certaines des mises à niveau des modèles les plus attendues et de nouvelles fonctionnalités révolutionnaires. De Xai's Grok 3 et Anthropic's Claude 3.7 Sonnet, à Openai's G
 Comment utiliser YOLO V12 pour la détection d'objets?
Mar 22, 2025 am 11:07 AM
Comment utiliser YOLO V12 pour la détection d'objets?
Mar 22, 2025 am 11:07 AM
Yolo (vous ne regardez qu'une seule fois) a été un cadre de détection d'objets en temps réel de premier plan, chaque itération améliorant les versions précédentes. La dernière version Yolo V12 introduit des progrès qui améliorent considérablement la précision
 Chatgpt 4 o est-il disponible?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 o est-il disponible?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 est actuellement disponible et largement utilisé, démontrant des améliorations significatives dans la compréhension du contexte et la génération de réponses cohérentes par rapport à ses prédécesseurs comme Chatgpt 3.5. Les développements futurs peuvent inclure un interg plus personnalisé
 Google & # 039; s Gencast: Prévision météorologique avec Mini démo Gencast
Mar 16, 2025 pm 01:46 PM
Google & # 039; s Gencast: Prévision météorologique avec Mini démo Gencast
Mar 16, 2025 pm 01:46 PM
Gencast de Google Deepmind: une IA révolutionnaire pour les prévisions météorologiques Les prévisions météorologiques ont subi une transformation spectaculaire, passant des observations rudimentaires aux prédictions sophistiquées alimentées par l'IA. Gencast de Google Deepmind, un terreau
 Meilleurs générateurs d'art AI (gratuit & amp; payé) pour des projets créatifs
Apr 02, 2025 pm 06:10 PM
Meilleurs générateurs d'art AI (gratuit & amp; payé) pour des projets créatifs
Apr 02, 2025 pm 06:10 PM
L'article passe en revue les meilleurs générateurs d'art AI, discutant de leurs fonctionnalités, de leur aptitude aux projets créatifs et de la valeur. Il met en évidence MidJourney comme la meilleure valeur pour les professionnels et recommande Dall-E 2 pour un art personnalisable de haute qualité.
 Quelle IA est la meilleure que Chatgpt?
Mar 18, 2025 pm 06:05 PM
Quelle IA est la meilleure que Chatgpt?
Mar 18, 2025 pm 06:05 PM
L'article traite des modèles d'IA dépassant Chatgpt, comme Lamda, Llama et Grok, mettant en évidence leurs avantages en matière de précision, de compréhension et d'impact de l'industrie. (159 caractères)
 O1 vs GPT-4O: le nouveau modèle Openai est-il meilleur que GPT-4O?
Mar 16, 2025 am 11:47 AM
O1 vs GPT-4O: le nouveau modèle Openai est-il meilleur que GPT-4O?
Mar 16, 2025 am 11:47 AM
O1'S O1: Une vague de cadeaux de 12 jours commence par leur modèle le plus puissant à ce jour L'arrivée de décembre apporte un ralentissement mondial, les flocons de neige dans certaines parties du monde, mais Openai ne fait que commencer. Sam Altman et son équipe lancent un cadeau de don de 12 jours
