
hadoop namenode -format
b. Entrez i pour passer en mode édition. c. Insérez le contenu suivant dans le nœud start-yarn.sh
d. Appuyez sur la touche Echap pour quitter le mode d'édition, entrez : wq pour enregistrer et quitter. " >start-dfs.sh
b. Entrez i pour passer en mode édition. c. Insérez le contenu suivant dans le nœud start-yarn.sh
d. Appuyez sur la touche Echap pour quitter le mode d'édition, entrez : wq pour enregistrer et quitter.
 Opération et maintenance
exploitation et maintenance Linux
Comment installer Hadoop sous Linux
Opération et maintenance
exploitation et maintenance Linux
Comment installer Hadoop sous Linux
Comment installer Hadoop sous Linux

1 : Installez JDK
1. Exécutez la commande suivante pour télécharger le package d'installation de JDK1.8.
wget --no-check-certificate https://repo.huaweicloud.com/java/jdk/8u151-b12/jdk-8u151-linux-x64.tar.gz
2. Exécutez la commande suivante pour décompresser le package d'installation JDK1.8 téléchargé.
tar -zxvf jdk-8u151-linux-x64.tar.gz
3. Déplacez et renommez le package JDK.
mv jdk1.8.0_151/ /usr/java8
4. Configurez les variables d'environnement Java.
echo 'export JAVA_HOME=/usr/java8' >> /etc/profile echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile source /etc/profile
5. Vérifiez si Java est installé avec succès.
java -version
Deux : Installez Hadoop
Remarque : Pour télécharger le package d'installation Hadoop, vous pouvez choisir la source Huawei (la vitesse est moyenne, acceptable, l'accent est mis sur la version complète), la source Tsinghua (la vitesse de téléchargement de la version 3.0 .0 ou supérieur est trop lent et il existe peu de versions), source de l'Université des études étrangères de Pékin (vitesse de téléchargement rapide, mais relativement peu de versions) - Je l'ai personnellement testé
1 Exécutez la commande suivante pour télécharger le package d'installation Hadoop. .
wget --no-check-certificate https://repo.huaweicloud.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
2. Exécutez la commande suivante pour décompresser le package d'installation Hadoop dans /opt/hadoop.
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/ mv /opt/hadoop-3.1.3 /opt/hadoop
3. Exécutez la commande suivante pour configurer les variables d'environnement Hadoop.
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile source /etc/profile
4. Exécutez les commandes suivantes pour modifier les fichiers de configuration fil-env.sh et hadoop-env.sh.
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh
5. Exécutez la commande suivante pour tester si Hadoop est installé avec succès.
hadoop version
Si les informations de version sont renvoyées, cela signifie que l'installation est réussie.
Trois : Configurez Hadoop
1. Modifiez le fichier de configuration Hadoop core-site.xml.
a. Exécutez la commande suivante pour accéder à la page d'édition. a. 执行以下命令开始进入编辑页面。
vim /opt/hadoop/etc/hadoop/core-site.xml
b. 输入i进入编辑模式。c. 在<configuration></configuration>节点内插入如下内容。
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>d. 按Esc键退出编辑模式,输入:wq保存退出。
2. 修改Hadoop配置文件 hdfs-site.xml。
a. 执行以下命令开始进入编辑页面。
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
b. 输入i进入编辑模式。c. 在<configuration></configuration>节点内插入如下内容。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>d. 按Esc键退出编辑模式,输入:wq保存退出。
四:配置SSH免密登录
1. 执行以下命令,创建公钥和私钥。
ssh-keygen -t rsa
2. 执行以下命令,将公钥添加到authorized_keys文件中。
cd ~ cd .ssh cat id_rsa.pub >> authorized_keys
若报错,执行下面操作后重新执行上面两句命令;若没有报错直接进入第五步:
输入如下命令,在环境变量中添加下面的配置
vi /etc/profile
然后向里面加入如下的内容
export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
输入如下命令使改动生效
source /etc/profile
b. Entrez i pour passer en mode édition. c. Insérez le contenu suivant dans le nœud <configuration></configuration> hadoop namenode -format
Copier après la connexion
hadoop namenode -format
d. Appuyez sur la touche Echap pour quitter le mode d'édition, entrez : wq pour enregistrer et quitter. 2. Modifiez le fichier de configuration Hadoop hdfs-site.xml.
a. Exécutez la commande suivante pour commencer à accéder à la page d'édition. start-dfs.sh
Copier après la connexionb. Entrez i pour passer en mode édition. c. Insérez le contenu suivant dans le nœud <configuration></configuration> start-yarn.sh
Copier après la connexiond. Appuyez sur la touche Echap pour quitter le mode d'édition, entrez : wq pour enregistrer et quitter.
Quatre : Configurez la connexion SSH sans mot de passestart-dfs.sh
start-yarn.sh
1 Exécutez les commandes suivantes pour créer la clé publique et la clé privée. jps
Copier après la connexion2. Exécutez la commande suivante pour ajouter la clé publique au fichierauthorized_keys.
jps
rrreee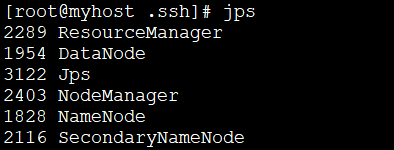 Si une erreur est signalée, effectuez les opérations suivantes puis réexécutez les deux commandes ci-dessus ; si aucune erreur n'est signalée, passez directement à la cinquième étape :
Si une erreur est signalée, effectuez les opérations suivantes puis réexécutez les deux commandes ci-dessus ; si aucune erreur n'est signalée, passez directement à la cinquième étape :
Entrez la commande suivante et ajoutez ce qui suit configuration à la variable d'environnement
rrreee
Puis ajoutez-y le contenu suivantrrreeeEntrez la commande suivante pour que les modifications prennent effetrrreeeCinq : Démarrez Hadoop
1.
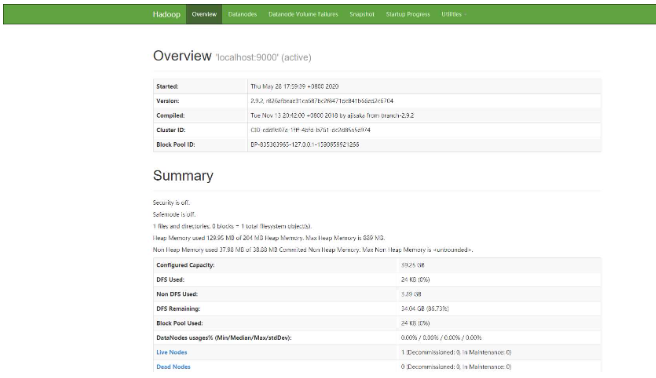 rrreee
rrreee
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Impossible de se connecter à MySQL en tant que racine
Apr 08, 2025 pm 04:54 PM
Impossible de se connecter à MySQL en tant que racine
Apr 08, 2025 pm 04:54 PM
Les principales raisons pour lesquelles vous ne pouvez pas vous connecter à MySQL en tant que racines sont des problèmes d'autorisation, des erreurs de fichier de configuration, des problèmes de mot de passe incohérents, des problèmes de fichiers de socket ou une interception de pare-feu. La solution comprend: vérifiez si le paramètre Bind-Address dans le fichier de configuration est configuré correctement. Vérifiez si les autorisations de l'utilisateur racine ont été modifiées ou supprimées et réinitialisées. Vérifiez que le mot de passe est précis, y compris les cas et les caractères spéciaux. Vérifiez les paramètres et les chemins d'autorisation du fichier de socket. Vérifiez que le pare-feu bloque les connexions au serveur MySQL.
 C compilation conditionnelle du langage: un guide détaillé pour les débutants vers des applications pratiques
Apr 04, 2025 am 10:48 AM
C compilation conditionnelle du langage: un guide détaillé pour les débutants vers des applications pratiques
Apr 04, 2025 am 10:48 AM
C La compilation conditionnelle du langage est un mécanisme pour compiler sélectivement les blocs de code en fonction des conditions de temps de compilation. Les méthodes d'introduction incluent: l'utilisation des directives #IF et #ELSE pour sélectionner des blocs de code en fonction des conditions. Les expressions conditionnelles couramment utilisées incluent STDC, _WIN32 et Linux. Cas pratique: imprimez différents messages en fonction du système d'exploitation. Utilisez différents types de données en fonction du nombre de chiffres du système. Différents fichiers d'en-tête sont pris en charge selon le compilateur. La compilation conditionnelle améliore la portabilité et la flexibilité du code, ce qui le rend adaptable aux modifications du compilateur, du système d'exploitation et de l'architecture du processeur.
 【Rust AutoDud】 Introduction
Apr 04, 2025 am 08:03 AM
【Rust AutoDud】 Introduction
Apr 04, 2025 am 08:03 AM
1.0.1 Préface Ce projet (y compris le code et les commentaires) a été enregistré pendant ma rouille autodidacte. Il peut y avoir des déclarations inexactes ou peu claires, veuillez vous excuser. Si vous en profitez, c'est encore mieux. 1.0.2 Pourquoi Rustrust est-il fiable et efficace? La rouille peut remplacer C et C, par des performances similaires mais une sécurité plus élevée, et ne nécessite pas de recompilation fréquente pour vérifier les erreurs comme C et C. Les principaux avantages incluent: la sécurité de la mémoire (empêcher les pointeurs nuls de déréférences, les pointeurs pendants et la contention des données). Filetage (assurez-vous que le code multithread est sûr avant l'exécution). Évitez le comportement non défini (par exemple, le tableau hors limites, les variables non initialisées ou l'accès à la mémoire libérée). Rust offre des fonctionnalités de langue moderne telles que les génériques
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Quels sont les 5 composants de base de Linux?
Apr 06, 2025 am 12:05 AM
Quels sont les 5 composants de base de Linux?
Apr 06, 2025 am 12:05 AM
Les cinq composants de base de Linux sont: 1. Le noyau, gérant les ressources matérielles; 2. La bibliothèque système, fournissant des fonctions et des services; 3. Shell, l'interface pour les utilisateurs pour interagir avec le système; 4. Le système de fichiers, stockant et organisant des données; 5. Applications, en utilisant des ressources système pour implémenter les fonctions.
 MySQL peut-il fonctionner sur Android
Apr 08, 2025 pm 05:03 PM
MySQL peut-il fonctionner sur Android
Apr 08, 2025 pm 05:03 PM
MySQL ne peut pas fonctionner directement sur Android, mais il peut être implémenté indirectement en utilisant les méthodes suivantes: à l'aide de la base de données légère SQLite, qui est construite sur le système Android, ne nécessite pas de serveur distinct et a une petite utilisation des ressources, qui est très adaptée aux applications de périphériques mobiles. Connectez-vous à distance au serveur MySQL et connectez-vous à la base de données MySQL sur le serveur distant via le réseau pour la lecture et l'écriture de données, mais il existe des inconvénients tels que des dépendances de réseau solides, des problèmes de sécurité et des coûts de serveur.
 Où se trouve la bibliothèque de fonctions de langue C? Comment ajouter la bibliothèque de fonctions de langue C?
Apr 03, 2025 pm 11:39 PM
Où se trouve la bibliothèque de fonctions de langue C? Comment ajouter la bibliothèque de fonctions de langue C?
Apr 03, 2025 pm 11:39 PM
La bibliothèque de fonctions de langue C est une boîte à outils contenant diverses fonctions, qui sont organisées dans différents fichiers de bibliothèque. L'ajout d'une bibliothèque nécessite de la spécifier via les options de ligne de commande du compilateur, par exemple, le compilateur GCC utilise l'option -L suivie de l'abréviation du nom de la bibliothèque. Si le fichier de bibliothèque n'est pas sous le chemin de recherche par défaut, vous devez utiliser l'option -L pour spécifier le chemin du fichier de bibliothèque. La bibliothèque peut être divisée en bibliothèques statiques et bibliothèques dynamiques. Les bibliothèques statiques sont directement liées au programme au moment de la compilation, tandis que les bibliothèques dynamiques sont chargées à l'exécution.
 Solutions aux erreurs rapportées par MySQL sur une version système spécifique
Apr 08, 2025 am 11:54 AM
Solutions aux erreurs rapportées par MySQL sur une version système spécifique
Apr 08, 2025 am 11:54 AM
La solution à l'erreur d'installation de MySQL est: 1. Vérifiez soigneusement l'environnement système pour vous assurer que les exigences de la bibliothèque de dépendance MySQL sont satisfaites. Différents systèmes d'exploitation et exigences de version sont différents; 2. Lisez soigneusement le message d'erreur et prenez des mesures correspondantes en fonction des invites (telles que les fichiers de bibliothèque manquants ou les autorisations insuffisantes), telles que l'installation de dépendances ou l'utilisation de commandes sudo; 3. Si nécessaire, essayez d'installer le code source et vérifiez soigneusement le journal de compilation, mais cela nécessite une certaine quantité de connaissances et d'expérience Linux. La clé pour finalement résoudre le problème est de vérifier soigneusement l'environnement du système et les informations d'erreur et de se référer aux documents officiels.
