
 Périphériques technologiques
IA
Comprendre et unifier 14 algorithmes d'attribution pour rendre les réseaux de neurones interprétables
Périphériques technologiques
IA
Comprendre et unifier 14 algorithmes d'attribution pour rendre les réseaux de neurones interprétables
Comprendre et unifier 14 algorithmes d'attribution pour rendre les réseaux de neurones interprétables

Bien que les DNN aient connu un large succès dans diverses applications pratiques, leurs processus sont souvent considérés comme des boîtes noires car il est difficile d'expliquer comment les DNN prennent des décisions. Le manque d’interprétabilité compromet la fiabilité des DNN, entravant ainsi leur application généralisée dans des tâches à enjeux élevés telles que la conduite autonome et la médecine IA. Par conséquent, les DNN explicables ont attiré une attention croissante.
En tant que perspective typique pour expliquer le DNN, la méthode d'attribution vise à calculer le score d'attribution/importance/contribution de chaque variable d'entrée à la sortie du réseau. Par exemple, étant donné un DNN pré-entraîné pour la classification d'images et une image d'entrée, le score d'attribut pour chaque variable d'entrée fait référence à l'impact numérique de chaque pixel sur le score de confiance de classification.
Bien que les chercheurs aient proposé de nombreuses méthodes d'attribution ces dernières années, la plupart d'entre elles reposent sur des heuristiques différentes. Il manque actuellement une perspective théorique unifiée pour tester l’exactitude de ces méthodes d’attribution, ou du moins pour élucider mathématiquement leurs mécanismes fondamentaux. Les chercheurs ont tenté d’unifier différentes méthodes d’attribution, mais ces études n’ont couvert que quelques méthodes.
Dans cet article, nous proposons une "explication unifiée du mécanisme intrinsèque de 14 algorithmes d'attribution d'importance des unités d'entrée".

En fait, qu'il s'agisse de « 12 algorithmes pour améliorer la résistance à la migration » ou de « 14 types d'attribution d'importance aux unités d'entrée Les « algorithmes » sont les domaines les plus touchés des algorithmes d’ingénierie. Dans ces deux domaines, la plupart des algorithmes sont empiriques. Les gens conçoivent des algorithmes d’ingénierie plausibles basés sur une expérience expérimentale ou une compréhension intuitive. La plupart des études n'ont pas fait de définitions rigoureuses ni de démonstrations théoriques de « quelle est exactement l'importance des unités d'entrée ». Quelques études ont certaines démonstrations, mais elles sont souvent très imparfaites. Bien entendu, le problème du « manque de définitions et de démonstrations rigoureuses » imprègne tout le domaine de l’intelligence artificielle, mais il est particulièrement prégnant dans ces deux directions.
Premièrement, dans un environnement où de nombreux algorithmes d'attribution empiriques inondent le domaine de l'apprentissage automatique interprétable, nous espérons prouver que « les 14 algorithmes d'attribution (Algorithmes qui expliquent l'importance des unités d'entrée des réseaux neuronaux) peut être exprimée comme une distribution de l'utilité d'interaction modélisée par les réseaux de neurones, et différents algorithmes d'attribution correspondent à différentes proportions de distribution d'utilité d'interaction. De cette façon, bien que différents algorithmes aient des objectifs de conception complètement différents (par exemple, certains algorithmes ont une fonction objectif définie et certains algorithmes sont de purs pipelines), nous avons constaté que mathématiquement, ces algorithmes peuvent être inclus dans la distribution « utilitaire d'interaction » " de logique narrative.
- Sur la base du cadre d'allocation des utilitaires d'interaction ci-dessus, nous pouvons en outre proposer trois critères d'évaluation pour l'algorithme d'attribution de l'importance des unités d'entrée du réseau neuronal afin de mesurer les prédictions de l'algorithme d'attribution. Si la valeur d’importance de l’unité d’entrée est raisonnable.
- Bien sûr, notre analyse théorique n'est pas seulement applicable à 14 algorithmes d'attribution, et peut théoriquement unifier davantage de recherches similaires. En raison d’une main-d’œuvre limitée, nous ne discutons que de 14 algorithmes dans cet article.
La vraie difficulté de la recherche est que différents algorithmes d'attribution empiriques sont souvent construits sur des intuitions différentes, et chaque article s'efforce uniquement d'apprendre de ses propres perspectives "se justifier", et les algorithmes d’attribution sont conçus sur la base de différentes intuitions ou perspectives, mais il manque un langage mathématique standardisé pour décrire uniformément l’essence des différents algorithmes.
Révision de l'algorithme
Avant de parler de mathématiques, cet article passera brièvement en revue l'algorithme précédent d'un niveau intuitif.1. Algorithme d'attribution basé sur le dégradé. Ce type d'algorithme estime généralement que le gradient de la sortie du réseau neuronal vers chaque unité d'entrée peut refléter l'importance de l'unité d'entrée. Par exemple, l'algorithme Gradient*Input modélise l'importance d'une unité d'entrée en tant que produit élément par élément du gradient et de la valeur de l'unité d'entrée. Considérant que le gradient ne peut refléter que l'importance locale de l'unité d'entrée, les algorithmes Smooth Gradients et Integrated Gradients modélisent l'importance comme le produit élément par élément du gradient moyen et de la valeur de l'unité d'entrée, où le gradient moyen dans ces deux méthodes fait référence. au voisin de l'échantillon d'entrée respectivement. La valeur moyenne du gradient dans le domaine ou le gradient moyen du point d'interpolation linéaire entre l'échantillon d'entrée et le point de référence. De même, l'algorithme Grad-CAM prend la moyenne de la sortie du réseau sur tous les gradients de caractéristiques de chaque canal pour calculer le score d'importance. De plus, l'algorithme des gradients attendus estime que la sélection d'un seul point de référence conduira souvent à des résultats d'attribution biaisés, proposant ainsi de modéliser l'importance comme l'attente des résultats d'attribution des gradients intégrés sous différents points de référence.
2. Algorithme d'attribution basé sur la rétropropagation couche par couche. Les réseaux de neurones profonds sont souvent extrêmement complexes et la structure de chaque couche de réseau neuronal est relativement simple (par exemple, les caractéristiques profondes sont généralement la somme linéaire de caractéristiques superficielles + une fonction d'activation non linéaire), ce qui facilite l'analyse de l'importance de des traits peu profonds aux traits profonds. Par conséquent, ce type d'algorithme obtient l'importance de l'unité d'entrée en estimant l'importance des caractéristiques de niveau intermédiaire et en propageant cette importance couche par couche jusqu'à la couche d'entrée. Les algorithmes de cette catégorie incluent LRP-epsilon, LRP-alphabeta, Deep Taylor, DeepLIFT Rescale, DeepLIFT RevealCancel, DeepShap, etc. La différence fondamentale entre les différents algorithmes de rétropropagation est qu'ils utilisent des règles de propagation d'importance différente couche par couche.
3. Algorithme d'attribution basé sur l'occlusion. Ce type d'algorithme déduit l'importance d'une unité d'entrée en fonction de l'impact de l'occlusion d'une unité d'entrée sur la sortie du modèle. Par exemple, l'algorithme Occlusion-1 (Occlusion-patch) modélise l'importance du i-ème pixel (bloc de pixels) en tant que changement de sortie lorsque le pixel i n'est pas masqué et masqué lorsque les autres pixels ne sont pas masqués. L'algorithme de valeur de Shapley considère de manière exhaustive toutes les situations d'occlusion possibles d'autres pixels et modélise l'importance en tant que moyenne des changements de sortie correspondant au pixel i dans différentes situations d'occlusion. La recherche a prouvé que la valeur de Shapley est le seul algorithme d'attribution qui satisfait aux axiomes de linéarité, de factice, de symétrie et d'efficacité.
Unifier le mécanisme interne de 14 algorithmes d'attribution empiriques
Après une étude approfondie de plusieurs algorithmes d'attribution empiriques, nous ne pouvons nous empêcher de réfléchir à une question : au niveau mathématique, quel est le problème de l'attribution des réseaux de neurones résoudre ? Existe-t-il une modélisation mathématique et un paradigme unifiés derrière de nombreux algorithmes d'attribution empiriques ? À cette fin, nous essayons d’examiner les questions ci-dessus en partant de la définition de l’attribution. L'attribution fait référence au score d'importance/contribution de chaque unité d'entrée à la sortie du réseau neuronal. Ensuite, la clé pour résoudre le problème ci-dessus est de (1) modéliser le « mécanisme d'influence de l'unité d'entrée sur la sortie du réseau » au niveau mathématique, et (2) d'expliquer combien d'algorithmes d'attribution empiriques utilisent ce mécanisme d'influence pour concevoir l'importance Formule d'attribution.
Concernant le premier point clé, nos recherches ont révélé que chaque unité d'entrée affecte souvent la sortie du réseau neuronal de deux manières. D'une part, une certaine unité d'entrée n'a pas besoin de s'appuyer sur d'autres unités d'entrée et peut agir indépendamment et affecter la sortie du réseau. Ce type d'influence est appelé « effet indépendant ». D'un autre côté, une unité d'entrée doit coopérer avec d'autres unités d'entrée pour former un certain modèle, affectant ainsi la sortie du réseau. Ce type d'influence est appelé « effet d'interaction ». Notre théorie prouve que la sortie du réseau neuronal peut être rigoureusement déconstruite en effets indépendants de différentes variables d'entrée, ainsi qu'en effets interactifs entre les variables d'entrée dans différents ensembles.
Parmi eux,  représente l'effet indépendant de la i-ème unité d'entrée, #🎜🎜 ##🎜 🎜#
représente l'effet indépendant de la i-ème unité d'entrée, #🎜🎜 ##🎜 🎜# représente l'effet d'interaction entre plusieurs unités d'entrée dans l'ensemble S. Concernant le deuxième point clé, nous avons exploré et constaté que les mécanismes internes des 14 algorithmes d'attribution empiriques existants peuvent représenter une allocation de l'utilité indépendante et de l'utilité interactive ci-dessus, mais que différents algorithmes d'attribution allouent des utilités indépendantes et interactives. utilité aux unités d'entrée du réseau neuronal dans différentes proportions. Plus précisément, laissez
représente l'effet d'interaction entre plusieurs unités d'entrée dans l'ensemble S. Concernant le deuxième point clé, nous avons exploré et constaté que les mécanismes internes des 14 algorithmes d'attribution empiriques existants peuvent représenter une allocation de l'utilité indépendante et de l'utilité interactive ci-dessus, mais que différents algorithmes d'attribution allouent des utilités indépendantes et interactives. utilité aux unités d'entrée du réseau neuronal dans différentes proportions. Plus précisément, laissez  # 🎜 🎜# représente le score d'attribution de la i-ème unité d'entrée. Nous prouvons rigoureusement que le obtenu par les 14 algorithmes d'attribution empiriques peut être uniformément exprimé comme le paradigme mathématique suivant (c'est-à-dire la somme pondérée de l'utilité indépendante et de l'utilité interactive) : #🎜 🎜 ## 🎜🎜 # # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜 🎜 🎜 #
# 🎜 🎜# représente le score d'attribution de la i-ème unité d'entrée. Nous prouvons rigoureusement que le obtenu par les 14 algorithmes d'attribution empiriques peut être uniformément exprimé comme le paradigme mathématique suivant (c'est-à-dire la somme pondérée de l'utilité indépendante et de l'utilité interactive) : #🎜 🎜 ## 🎜🎜 # # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜 🎜 🎜 #  Parmi eux, reflète proportion de l'effet indépendant de la j-ème unité d'entrée allouée à la i-ème unité d'entrée,
Parmi eux, reflète proportion de l'effet indépendant de la j-ème unité d'entrée allouée à la i-ème unité d'entrée,  représente l'allocation des effets interactifs entre plusieurs unités d'entrée dans l'ensemble S à la i-ème proportions de l'unité d'entrée. La « différence fondamentale » entre de nombreux algorithmes d'attribution est que différents algorithmes d'attribution correspondent à différents ratios d'attribution .
représente l'allocation des effets interactifs entre plusieurs unités d'entrée dans l'ensemble S à la i-ème proportions de l'unité d'entrée. La « différence fondamentale » entre de nombreux algorithmes d'attribution est que différents algorithmes d'attribution correspondent à différents ratios d'attribution .
Le tableau 1 montre comment quatorze algorithmes d'attribution différents attribuent respectivement des effets indépendants et des effets interactifs.


 Graphique 1. Quatorze types Attribution les algorithmes peuvent être écrits comme un paradigme mathématique de la somme pondérée des effets indépendants et des effets interactifs. Parmi eux,
Graphique 1. Quatorze types Attribution les algorithmes peuvent être écrits comme un paradigme mathématique de la somme pondérée des effets indépendants et des effets interactifs. Parmi eux,
représente respectivement l'effet indépendant de Taylor et l'effet d'interaction de Taylor, satisfaisant
 est un raffinement de l'effet indépendant
est un raffinement de l'effet indépendant 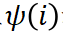 et de l'effet interactif
et de l'effet interactif  .
.










 min Trois principes majeurs
min Trois principes majeurs
Dans la recherche sur les explications d'attribution, en raison de Il n'y a aucun moyen d'obtenir/étiqueter la vraie valeur de l'explication d'attribution du réseau neuronal, et les gens ne peuvent pas évaluer la fiabilité d'un certain algorithme d'explication d'attribution d'un point de vue empirique. Le défaut fondamental du « manque de critères objectifs d’évaluation de la fiabilité des algorithmes d’explication d’attribution » a suscité de nombreuses critiques et remises en question dans le domaine universitaire de la recherche sur l’explication d’attribution.

(1)Critère 1 : Couvrir tous les effets indépendants et effets interactifs dans le processus d'attribution. Après avoir déconstruit la sortie du réseau neuronal en effets indépendants et effets interactifs, un algorithme d'attribution fiable devrait couvrir autant que possible tous les effets indépendants et effets interactifs dans le processus d'allocation. Par exemple, l'attribution à la phrase Je ne suis pas heureux devrait couvrir tous les effets indépendants des trois mots Je ne suis pas heureux, ainsi que J (Je ne suis pas heureux), J (Je suis heureux). ), J (pas, heureux), J (je ne suis pas heureux), etc. tous les effets d'interaction possibles.
(2)Ligne directrice 2 : Évitez d'attribuer des effets et des interactions indépendants à des unités d'entrée non pertinentes. L’effet indépendant de la ième unité d’entrée ne doit être attribué qu’à la ième unité d’entrée et non à d’autres unités d’entrée. De même, l’effet d’interaction entre les unités d’entrée au sein de l’ensemble S ne doit être attribué qu’aux unités d’entrée au sein de l’ensemble S et non aux unités d’entrée en dehors de l’ensemble S (ne participant pas à l’interaction). Par exemple, l’effet d’interaction entre pas et heureux ne doit pas être attribué au mot je suis.
(3)Troisième principe : allocation complète. Chaque effet indépendant (effet d'interaction) doit être entièrement attribué à l'unité d'entrée correspondante. En d'autres termes, les valeurs d'attribution attribuées à toutes les unités d'entrée correspondantes par un certain effet indépendant (effet d'interaction) doivent correspondre exactement à la valeur de l'effet indépendant (effet d'interaction). Par exemple, l'effet d'interaction J (pas, heureux) attribuerait une partie de l'effet  (pas, heureux) au mot pas et une partie de l'effet
(pas, heureux) au mot pas et une partie de l'effet  (pas, heureux) au mot heureux. Ensuite, le ratio de répartition devrait satisfaire
(pas, heureux) au mot heureux. Ensuite, le ratio de répartition devrait satisfaire 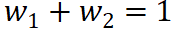 .
.
Ensuite, nous avons utilisé ces trois critères d'évaluation pour évaluer les 14 algorithmes d'attribution différents ci-dessus (comme indiqué dans le tableau 2). Nous avons constaté que les algorithmes Integrated Gradients, Expected Gradients, Shapley value, Deep Shap, DeepLIFT Rescale et DeepLIFT RevealCancel satisfont à tous les critères de fiabilité.

Tableau 2. Résumé indiquant si 14 algorithmes d'attribution différents satisfont aux trois critères d'évaluation de la fiabilité.
Présentation de l'auteur
L'auteur de cet article, Deng Huiqi, est titulaire d'un doctorat en mathématiques appliquées de l'Université Sun Yat-sen. Au cours de son doctorat, il a visité l'Université baptiste de Hong Kong et. du Département d'informatique de la Texas A&M University, et mène actuellement des recherches postdoctorales au sein de l'équipe du professeur Zhang Quanshi. L'orientation de la recherche est principalement l'apprentissage automatique fiable/interprétable, notamment en expliquant l'importance de l'attribution des réseaux de neurones profonds, en expliquant la capacité d'expression des réseaux de neurones, etc.
Deng Huiqi a fait beaucoup de travail au début. Le professeur Zhang l'a simplement aidée à réorganiser la théorie une fois le travail initial terminé pour rendre la méthode et le système de preuve plus fluides. Deng Huiqi n'a pas rédigé beaucoup d'articles avant d'obtenir son diplôme. Après avoir rejoint le professeur Zhang fin 2021, il a effectué trois tâches en plus d'un an dans le cadre du système d'interaction de jeu, notamment (1) découvrir et expliquer théoriquement le goulot d'étranglement de la représentation commune des neurones. Les réseaux, c'est-à-dire que les réseaux de neurones se sont révélés encore moins aptes à modéliser des représentations interactives de complexité modérée. Ce travail a eu la chance d'être sélectionné comme article oral de l'ICLR 2022 et sa note de révision s'est classée parmi les cinq premières (score 8 8 8 10). (2) La théorie prouve la tendance à la représentation conceptuelle des réseaux bayésiens et fournit une nouvelle perspective pour expliquer les performances de classification, la capacité de généralisation et la robustesse contradictoire des réseaux bayésiens. (3) Explique théoriquement la capacité du réseau neuronal à apprendre des concepts interactifs de complexité différente au cours du processus de formation.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
La couche inférieure de la fonction de tri C++ utilise le tri par fusion, sa complexité est O(nlogn) et propose différents choix d'algorithmes de tri, notamment le tri rapide, le tri par tas et le tri stable.
 L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
La convergence de l’intelligence artificielle (IA) et des forces de l’ordre ouvre de nouvelles possibilités en matière de prévention et de détection de la criminalité. Les capacités prédictives de l’intelligence artificielle sont largement utilisées dans des systèmes tels que CrimeGPT (Crime Prediction Technology) pour prédire les activités criminelles. Cet article explore le potentiel de l’intelligence artificielle dans la prédiction de la criminalité, ses applications actuelles, les défis auxquels elle est confrontée et les éventuelles implications éthiques de cette technologie. Intelligence artificielle et prédiction de la criminalité : les bases CrimeGPT utilise des algorithmes d'apprentissage automatique pour analyser de grands ensembles de données, identifiant des modèles qui peuvent prédire où et quand les crimes sont susceptibles de se produire. Ces ensembles de données comprennent des statistiques historiques sur la criminalité, des informations démographiques, des indicateurs économiques, des tendances météorologiques, etc. En identifiant les tendances qui pourraient échapper aux analystes humains, l'intelligence artificielle peut donner du pouvoir aux forces de l'ordre.
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
 Pratique et réflexion sur la plateforme multimodale de grands modèles Jiuzhang Yunji DataCanvas
Oct 20, 2023 am 08:45 AM
Pratique et réflexion sur la plateforme multimodale de grands modèles Jiuzhang Yunji DataCanvas
Oct 20, 2023 am 08:45 AM
1. Le développement historique des grands modèles multimodaux. La photo ci-dessus est le premier atelier sur l'intelligence artificielle organisé au Dartmouth College aux États-Unis en 1956. Cette conférence est également considérée comme le coup d'envoi du développement de l'intelligence artificielle. pionniers de la logique symbolique (à l'exception du neurobiologiste Peter Milner au milieu du premier rang). Cependant, cette théorie de la logique symbolique n’a pas pu être réalisée avant longtemps et a même marqué le début du premier hiver de l’IA dans les années 1980 et 1990. Il a fallu attendre la récente mise en œuvre de grands modèles de langage pour découvrir que les réseaux de neurones portent réellement cette pensée logique. Les travaux du neurobiologiste Peter Milner ont inspiré le développement ultérieur des réseaux de neurones artificiels, et c'est pour cette raison qu'il a été invité à y participer. dans ce projet.
 Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
1. Contexte de la construction de la plateforme 58 Portraits Tout d'abord, je voudrais partager avec vous le contexte de la construction de la plateforme 58 Portraits. 1. La pensée traditionnelle de la plate-forme de profilage traditionnelle ne suffit plus. La création d'une plate-forme de profilage des utilisateurs s'appuie sur des capacités de modélisation d'entrepôt de données pour intégrer les données de plusieurs secteurs d'activité afin de créer des portraits d'utilisateurs précis. Elle nécessite également l'exploration de données pour comprendre le comportement et les intérêts des utilisateurs. et besoins, et fournir des capacités côté algorithmes ; enfin, il doit également disposer de capacités de plate-forme de données pour stocker, interroger et partager efficacement les données de profil utilisateur et fournir des services de profil. La principale différence entre une plate-forme de profilage d'entreprise auto-construite et une plate-forme de profilage de middle-office est que la plate-forme de profilage auto-construite dessert un seul secteur d'activité et peut être personnalisée à la demande. La plate-forme de mid-office dessert plusieurs secteurs d'activité et est complexe ; modélisation et offre des fonctionnalités plus générales. 2.58 Portraits d'utilisateurs de l'arrière-plan de la construction du portrait sur la plate-forme médiane 58
 Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !
Mar 14, 2024 pm 11:50 PM
Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !
Mar 14, 2024 pm 11:50 PM
Écrit ci-dessus & La compréhension personnelle de l'auteur est que dans le système de conduite autonome, la tâche de perception est un élément crucial de l'ensemble du système de conduite autonome. L'objectif principal de la tâche de perception est de permettre aux véhicules autonomes de comprendre et de percevoir les éléments environnementaux environnants, tels que les véhicules circulant sur la route, les piétons au bord de la route, les obstacles rencontrés lors de la conduite, les panneaux de signalisation sur la route, etc., aidant ainsi en aval modules Prendre des décisions et des actions correctes et raisonnables. Un véhicule doté de capacités de conduite autonome est généralement équipé de différents types de capteurs de collecte d'informations, tels que des capteurs de caméra à vision panoramique, des capteurs lidar, des capteurs radar à ondes millimétriques, etc., pour garantir que le véhicule autonome peut percevoir et comprendre avec précision l'environnement environnant. éléments , permettant aux véhicules autonomes de prendre les bonnes décisions pendant la conduite autonome. Tête
