
 Périphériques technologiques
IA
PandaLM, un « grand modèle d'arbitre » open source de l'Université de Pékin, de l'Université de West Lake et d'autres : trois lignes de code pour évaluer de manière entièrement automatique le LLM, avec une précision de 94 % de ChatGPT
Périphériques technologiques
IA
PandaLM, un « grand modèle d'arbitre » open source de l'Université de Pékin, de l'Université de West Lake et d'autres : trois lignes de code pour évaluer de manière entièrement automatique le LLM, avec une précision de 94 % de ChatGPT
PandaLM, un « grand modèle d'arbitre » open source de l'Université de Pékin, de l'Université de West Lake et d'autres : trois lignes de code pour évaluer de manière entièrement automatique le LLM, avec une précision de 94 % de ChatGPT

Après la sortie de ChatGPT, l'écosystème dans le domaine du traitement du langage naturel a complètement changé De nombreux problèmes qui ne pouvaient pas être résolus auparavant peuvent l'être en utilisant ChatGPT.
Cependant, cela pose aussi un problème : les performances des grands modèles sont trop fortes, et il est difficile d'évaluer les différences de chaque modèle à l'œil nu.
Par exemple, si vous entraînez plusieurs versions du modèle avec différents modèles de base et hyperparamètres, les performances peuvent être similaires à celles des exemples et il est impossible de quantifier pleinement l'écart de performances entre les deux modèles.
Actuellement, il existe deux options principales pour évaluer les grands modèles de langage : 1 Appelez l'interface API d'OpenAI pour évaluation.
ChatGPT peut être utilisé pour évaluer la qualité de la sortie de deux modèles. Cependant, ChatGPT a été mis à niveau de manière itérative. Les réponses à la même question à des moments différents peuvent être différentes. Les résultats de l'évaluation présentent le problème de ne pas pouvoir l'être. reproduit
.2. Annotation manuelle
Si une annotation manuelle est demandée sur la plateforme de crowdsourcing, les équipes disposant de fonds insuffisants pourraient ne pas être en mesure de se le permettre, et il existe également des cas où des sociétés tierces
divulguent des données. Afin de résoudre de tels « problèmes d'évaluation de grands modèles », des chercheurs de l'Université de Pékin, de l'Université de Westlake, de l'Université d'État de Caroline du Nord, de l'Université Carnegie Mellon et de la MSRA ont collaboré pour développer un nouveau cadre d'évaluation de modèle de langage PandaLM. -des solutions d'évaluation de grands modèles préservées, fiables, reproductibles et bon marché.
 Lien du projet : https://github.com/WeOpenML/PandaLM
Lien du projet : https://github.com/WeOpenML/PandaLM
En fournissant le même contexte, PandaLM peut comparer les résultats de réponse de différents LLM et fournir des raisons spécifiques.
Pour démontrer la fiabilité et la cohérence de l'outil, les chercheurs ont créé un ensemble de données de test diversifié, étiqueté par des humains, composé d'environ 1 000 échantillons, dans lequel PandaLM-7B a atteint une précision de 94 % des Compétences d'évaluation ChatGPT .
Trois lignes de code utilisant PandaLMLorsque deux grands modèles différents produisent des réponses différentes à la même instruction et au même contexte, PandaLM vise à comparer la qualité de réponse des deux grands modèles et à afficher les résultats de la comparaison et les raisons de la comparaison. et les réponses pour référence.
Il y a trois résultats de comparaison : la réponse 1 est meilleure, la réponse 2 est meilleure, la réponse 1 et la réponse 2 ont une qualité similaire.
Lorsque vous comparez les performances de plusieurs grands modèles, il vous suffit d'utiliser PandaLM pour les comparer par paires, puis de résumer les résultats des comparaisons par paires pour classer les performances de plusieurs grands modèles ou dessiner un diagramme de relation d'ordre partiel de modèle. Analysez de manière claire et intuitive les différences de performances entre les différents modèles.
PandaLM doit seulement être "déployé localement" et "ne nécessite pas de participation humaine", de sorte que l'évaluation de PandaLM peut protéger la vie privée et est assez bon marché.
Afin d'offrir une meilleure interprétabilité, PandaLM peut également expliquer ses sélections en langage naturel et générer un ensemble supplémentaire de réponses de référence.
Dans le projet, les chercheurs prennent non seulement en charge l'utilisation de PandaLM à l'aide de l'interface utilisateur Web pour faciliter l'analyse de cas, mais prennent également en charge trois lignes de code pour appeler PandaLM pour l'évaluation de texte généré par des modèles et des données arbitraires. 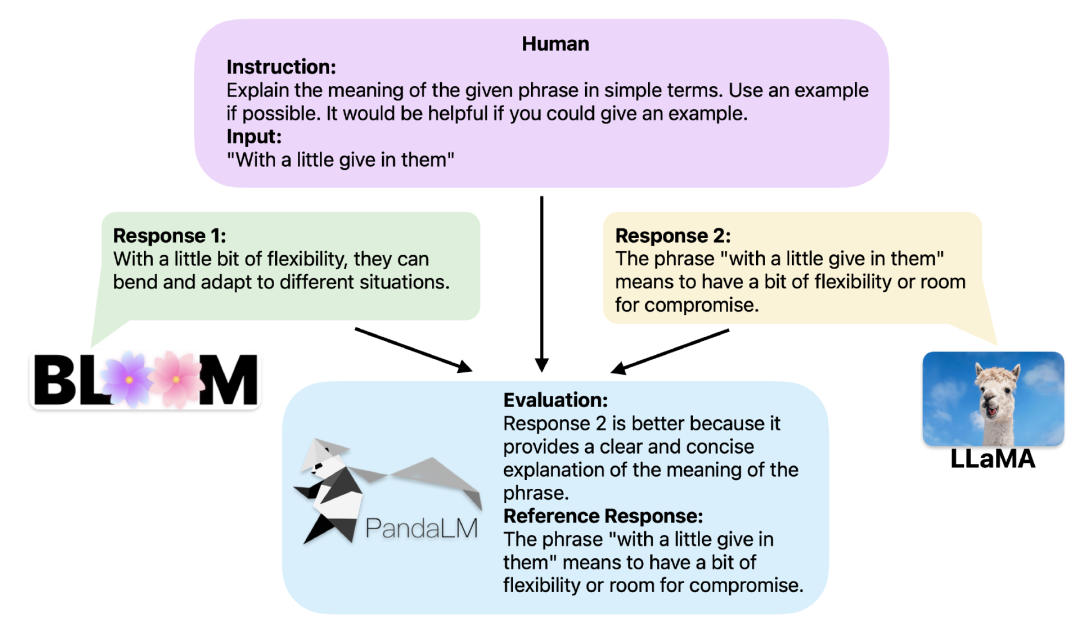
Étant donné que de nombreux modèles et frameworks existants ne sont pas open source ou sont difficiles à réaliser localement, PandaLM prend en charge l'utilisation de poids de modèle spécifiés pour générer le texte à évaluer, ou la transmission directe d'un fichier .json contenant le texte. à évaluer.
Les utilisateurs doivent uniquement transmettre une liste contenant le nom du modèle/l'ID du modèle HuggingFace ou le chemin du fichier .json, et PandaLM peut être utilisé pour réaliser des modèles définis par l'utilisateur et données d’entrée. Ce qui suit est un exemple d'utilisation minimaliste :

Afin de rendre tout le monde flexible PandaLM a été utilisé pour une évaluation gratuite. Les chercheurs ont également publié les poids du modèle PandaLM sur le site Web huggingface. Vous pouvez charger le modèle PandaLM-7B via la commande suivante :
#. 🎜 Caractéristiques de PandaLM 🎜🎜#
La mise à jour du modèle basée sur l'API en ligne n'est pas transparente, sa sortie peut être très incohérente à différents moments, et l'ancienne version du modèle n'est plus accessible, donc l'évaluation basée sur l'API en ligne n'est souvent pas reproductible. Automatisation, confidentialité et faibles frais généraux
Déployez simplement le PandaLM modélisez localement et appelez des commandes prêtes à l'emploi pour commencer à évaluer divers grands modèles. Il n'est pas nécessaire de rester en communication constante avec des experts lors de l'embauche d'experts pour l'annotation, et il n'y aura pas de problèmes de fuite de données. tous les frais d'API et la main d'œuvre. Le coût est très bon marché.
Niveau d'évaluation
Afin de prouver la fiabilité de PandaLM , l'étude Nous avons embauché trois experts pour effectuer des annotations répétées indépendantes et créé un ensemble de tests annoté manuellement.L'ensemble de tests contient 50 scénarios différents, et chaque scénario contient plusieurs tâches. Cet ensemble de tests est diversifié, fiable et cohérent avec les préférences humaines en matière de texte. Chaque échantillon de l'ensemble de tests se compose d'une instruction et d'un contexte, ainsi que de deux réponses générées par différents grands modèles, et la qualité des deux réponses est comparée par des humains.
Filtrez les échantillons présentant de grandes différences entre les annotateurs pour garantir que l'IAA (Inter Annotator Agreement) de chaque annotateur sur l'ensemble de test final est proche de 0,85. Il convient de noter que l'ensemble de formation de PandaLM ne chevauche pas l'ensemble de test annoté manuellement créé.
Ces échantillons filtrés nécessitent des connaissances supplémentaires ou des informations difficiles à obtenir. aider au jugement, il est donc difficile pour les humains de les étiqueter avec précision.
L'ensemble de tests filtré contient 1 000 échantillons, tandis que l'ensemble de tests non filtré d'origine contient 2 500 échantillons. La distribution de l'ensemble de test est {0:105, 1:422, 2:472}, où 0 indique que les deux réponses sont de qualité similaire, 1 indique que la réponse 1 est meilleure et 2 indique que la réponse 2 est meilleure. En prenant l'ensemble de tests humains comme référence, la comparaison des performances de PandaLM et de gpt-3.5-turbo est la suivante : 🎜# peut être vu, PandaLM-7B a atteint le niveau de gpt-3.5-turbo en termes de précision de 94%, et en termes de précision, de rappel et de score F1, PandaLM-7B est presque le même que gpt-3.5 -turbo.
Par conséquent, par rapport au gpt-3.5-turbo, on peut considérer que PandaLM-7B dispose déjà de capacités considérables d'évaluation de grands modèles.
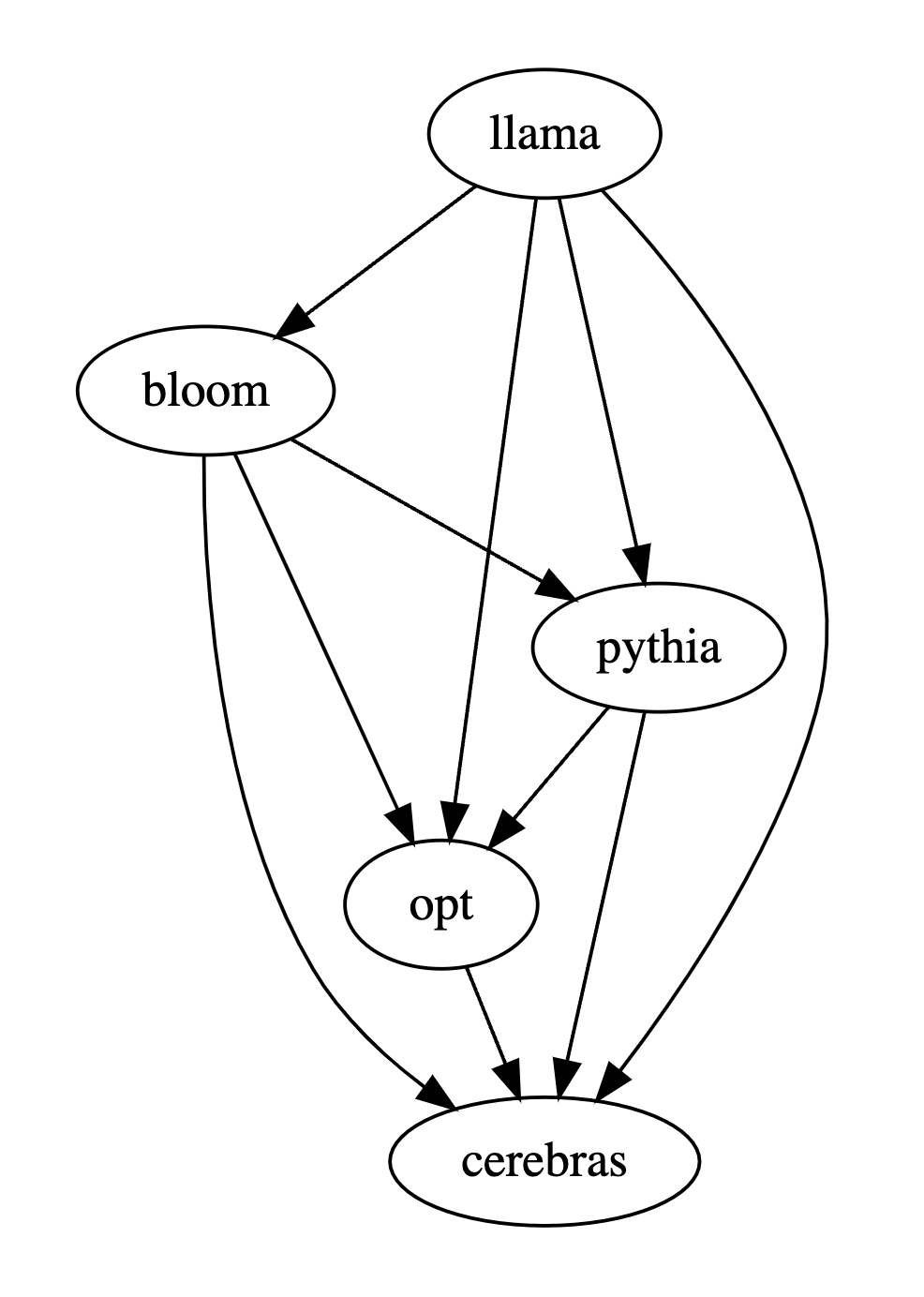
En plus de l'exactitude, de la précision, du rappel et du score F1 sur l'ensemble de test, il fournit également des résultats de comparaison entre 5 grands modèles open source de taille similaire.
Tout d'abord, nous avons utilisé les mêmes données d'entraînement pour affiner les cinq modèles, puis nous avons utilisé des humains, gpt-3.5-turbo et PandaLM pour comparer les cinq modèles respectivement.
Le premier tuple (72, 28, 11) dans la première rangée du tableau ci-dessous indique qu'il y a 72 réponses LLaMA-7B qui sont meilleures que Bloom-7B, et 28 réponses LLaMA-7B sont meilleures que Bloom- 7B La différence, les deux modèles ont 11 qualités de réponse similaires.
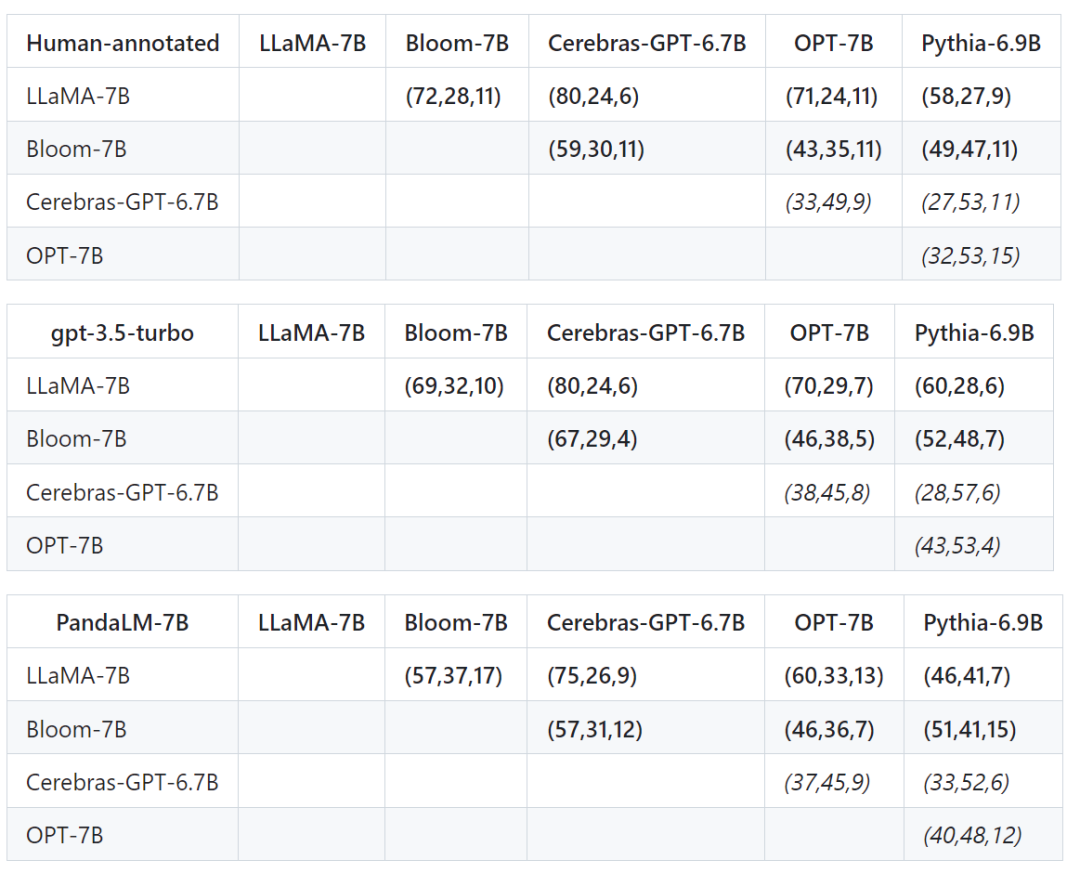
Donc, dans cet exemple, les humains pensent que LLaMA-7B est meilleur que Bloom-7B. Les résultats des trois tableaux suivants montrent que les humains, gpt-3.5-turbo et PandaLM-7B ont des jugements tout à fait cohérents sur la relation entre les avantages et les inconvénients de chaque modèle.
Résumé
PandaLM fournit une troisième solution pour évaluer les grands modèles en plus de l'évaluation humaine et de l'évaluation de l'API OpenAI. PandaLM a non seulement un niveau d'évaluation élevé, mais les résultats de l'évaluation sont également reproductibles et l'évaluation. Le processus est automatisé, préserve la confidentialité et réduit les frais généraux.
À l'avenir, PandaLM promouvra la recherche sur les grands modèles dans le monde universitaire et industriel, permettant ainsi à davantage de personnes de bénéficier du développement de grands modèles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Recommandé : Excellent projet de détection et de reconnaissance des visages open source JS
Apr 03, 2024 am 11:55 AM
Recommandé : Excellent projet de détection et de reconnaissance des visages open source JS
Apr 03, 2024 am 11:55 AM
La technologie de détection et de reconnaissance des visages est déjà une technologie relativement mature et largement utilisée. Actuellement, le langage d'application Internet le plus utilisé est JS. La mise en œuvre de la détection et de la reconnaissance faciale sur le front-end Web présente des avantages et des inconvénients par rapport à la reconnaissance faciale back-end. Les avantages incluent la réduction de l'interaction réseau et de la reconnaissance en temps réel, ce qui réduit considérablement le temps d'attente des utilisateurs et améliore l'expérience utilisateur. Les inconvénients sont les suivants : il est limité par la taille du modèle et la précision est également limitée ; Comment utiliser js pour implémenter la détection de visage sur le web ? Afin de mettre en œuvre la reconnaissance faciale sur le Web, vous devez être familier avec les langages et technologies de programmation associés, tels que JavaScript, HTML, CSS, WebRTC, etc. Dans le même temps, vous devez également maîtriser les technologies pertinentes de vision par ordinateur et d’intelligence artificielle. Il convient de noter qu'en raison de la conception du côté Web
 Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA
Apr 02, 2024 am 11:31 AM
Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA
Apr 02, 2024 am 11:31 AM
Nouveau SOTA pour des capacités de compréhension de documents multimodaux ! L'équipe Alibaba mPLUG a publié le dernier travail open source mPLUG-DocOwl1.5, qui propose une série de solutions pour relever les quatre défis majeurs que sont la reconnaissance de texte d'image haute résolution, la compréhension générale de la structure des documents, le suivi des instructions et l'introduction de connaissances externes. Sans plus tarder, examinons d’abord les effets. Reconnaissance et conversion en un clic de graphiques aux structures complexes au format Markdown : Des graphiques de différents styles sont disponibles : Une reconnaissance et un positionnement de texte plus détaillés peuvent également être facilement traités : Des explications détaillées sur la compréhension du document peuvent également être données : Vous savez, « Compréhension du document " est actuellement un scénario important pour la mise en œuvre de grands modèles linguistiques. Il existe de nombreux produits sur le marché pour aider à la lecture de documents. Certains d'entre eux utilisent principalement des systèmes OCR pour la reconnaissance de texte et coopèrent avec LLM pour le traitement de texte.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
