
 Opération et maintenance
exploitation et maintenance Linux
Quelle est la raison pour laquelle Linux utilise select ?
Opération et maintenance
exploitation et maintenance Linux
Quelle est la raison pour laquelle Linux utilise select ?
Quelle est la raison pour laquelle Linux utilise select ?

L'utilisation de la fonction select permet aux développeurs d'attendre plusieurs tampons de fichiers en même temps, réduisant ainsi le temps d'attente des IO et améliorant l'efficacité des IO du processus. La fonction select() est une fonction de multiplexage IO qui permet au programme de surveiller plusieurs descripteurs de fichiers et d'attendre qu'un ou plusieurs des descripteurs de fichiers surveillés deviennent « prêts » ; l'état dit « prêt » fait référence à : le fichier ; Le descripteur n'est plus bloqué et peut être utilisé pour certains types d'opérations d'E/S, y compris les opérations en lecture, en écriture et les exceptions.
#include
1. Introduction à la fonction select
La fonction select est une fonction de multiplexage IO. Sa fonction principale est d'attendre que l'événement dans le descripteur de fichier soit prêt. La sélection nous permet d'attendre plusieurs tampons de fichiers en même temps. Zone de temps, réduisant le temps d'attente des IO et améliorant l'efficacité des IO du processus. La fonction
select() permet au programme de surveiller plusieurs descripteurs de fichiers et d'attendre qu'un ou plusieurs des descripteurs de fichiers surveillés soient "prêts". L'état dit « prêt » signifie : le descripteur de fichier n'est plus dans un état de blocage et peut être utilisé pour certains types d'opérations d'E/S, y compris les occurrences de lecture, d'écriture et d'exception
2.
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);ndfs
La valeur maximale du descripteur de fichier en attente de +1, par exemple : si le processus de candidature veut attendre les événements des descripteurs de fichier 3, 5, 8, alors
nfds=max(3,5,8)+1;
fd_set type
readfds Les types de writefds et exceptfds sont tous fd_set, alors quel est le type fd_set ?
Le type fd_set est essentiellement un bitmap La position du bitmap représente le descripteur de fichier correspondant, et le contenu indique si le descripteur de fichier est valide, 1 représente que le descripteur de fichier à cette position est valide, et 0. représente cette position. Le descripteur de fichier n'est pas valide.
Si les descripteurs de fichiers 2 et 3 sont définis dans le bitmap, le bitmap représente 1100.
La limite supérieure de fd_set est de 1024 descripteurs de fichiers.
readfds
readfds est une collection de descripteurs de fichiers en attente d'événements de lecture Si vous ne vous souciez pas des événements de lecture (le tampon contient des données), vous pouvez transmettre la valeur NULL.
- Le processus d'application et le noyau peuvent définir readfds. Le processus d'application définit readfds pour informer le noyau d'attendre l'événement de lecture du descripteur de fichier dans readfds. Le
kernel définit readfds pour indiquer au processus d'application qui a lu. les événements prendront effet

Semblable à readfds, writefds est une collection en attente d'événements d'écriture (qu'il y ait de l'espace dans le tampon). Si vous ne vous souciez pas des événements d'écriture, vous). peut passer la valeur NULL.
sauffdsSi le
noyau attend que le descripteur de fichier correspondant reçoive une exception, alors définissez le descripteur de fichier ayant échoué dans exceptfds Si vous ne vous souciez pas des événements d'erreur, vous pouvez transmettre la valeur NULL. .
timeoutDéfinissez les blocs de sélection de temps dans le noyau. Si vous souhaitez le définir sur non bloquant, définissez-le sur NULL. Si vous souhaitez sélectionner un blocage pendant 5 secondes, vous créerez un
struct timeval time={5,0};où le type de structure de struct timeval est :
struct timeval {
long tv_sec; /* seconds */
long tv_usec; /* microseconds */
};- S'il y a il n'y a pas de description de fichier Renvoie 0 lorsque le symbole est prêt ;
- Si l'appel échoue, renvoie -1 ;
- Le flux de travail de 3.select
et le noyau doivent obtenir des informations de readfds et writefds. Parmi eux, le noyau doit savoir de readfds et writefds quels descripteurs de fichiers doivent attendre. , et le processus de candidature a besoin de savoir quels événements de descripteur de fichier sont prêts à partir de readfds et writefds.
Si nous voulons interroger et attendre en permanence les descripteurs de fichiers, le processus de candidature doit constamment réinitialiser readfds et writefds, car à chaque fois, sélectionnez. est appelé, le noyau modifiera readfds et writefds, nous devons donc définir un tableau dans l'
application pour enregistrer les descripteurs de fichiers que le programme doit attendre 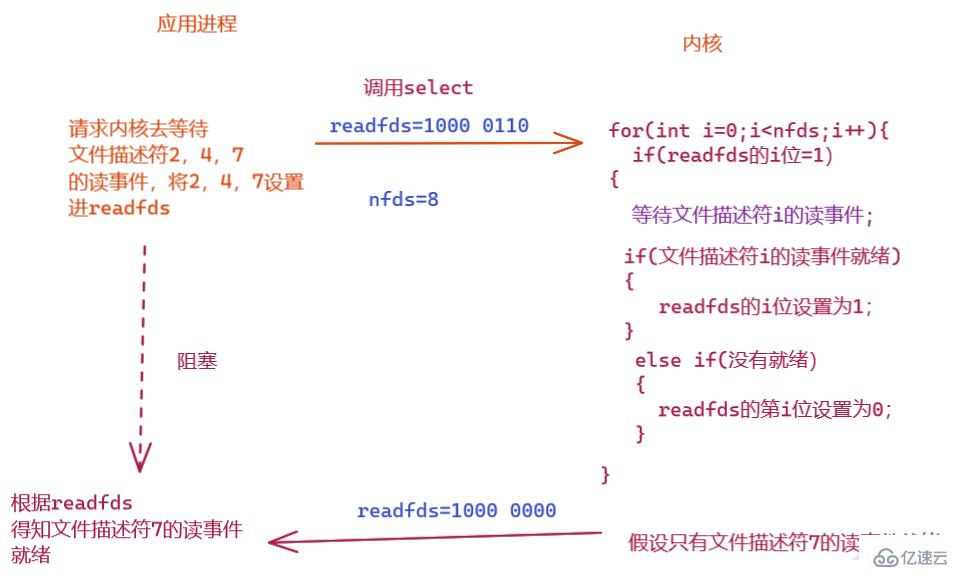 Assurez-vous que lorsque select est appelé, les valeurs dans. readfds et writefds seront les suivants :
Assurez-vous que lorsque select est appelé, les valeurs dans. readfds et writefds seront les suivants :
4.Select服务器
如果是一个select服务器进程,则服务器进程会不断的接收有新链接,每个链接对应一个文件描述符,如果想要我们的服务器能够同时等待多个链接的数据的到来,我们监听套接字listen_sock读取新链接的时候,我们需要将新链接的文件描述符保存到read_arrys数组中,下次轮询检测的就会将新链接的文件描述符设置进readfds中,如果有链接关闭,则将相对应的文件描述符从read_arrys数组中拿走。
一张图看懂select服务器:
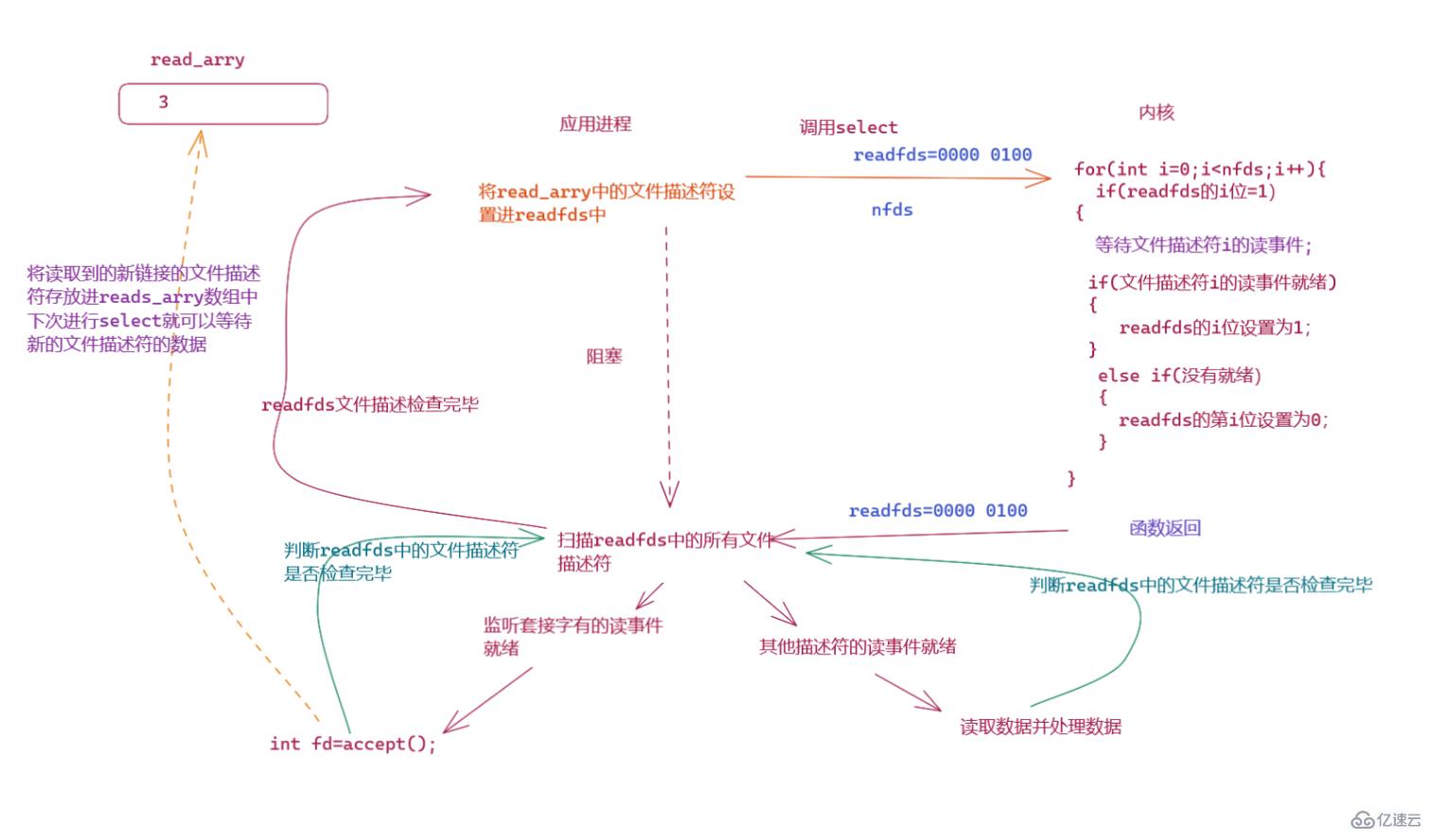
简易版的select服务器:
server.hpp文件:
#pragma once
#include<iostream>
#include<sys/socket.h>
#include<sys/types.h>
#include<netinet/in.h>
#include<string.h>
using std::cout;
using std::endl;
#define BACKLOG 5
namespace sjp{
class server{
public:
static int Socket(){
int sock=socket(AF_INET,SOCK_STREAM,0);
if(sock>0)
return sock;
if(sock<0)
exit(-1);
W> }
static bool Bind(int sockfd,short int port){
struct sockaddr_in lock;
memset(&lock,'\0',sizeof(lock));
lock.sin_family=AF_INET;
lock.sin_port=htons(port);
lock.sin_addr.s_addr=INADDR_ANY;
if(bind(sockfd,(struct sockaddr*)&lock,(socklen_t)sizeof(lock))<0){
exit(-2);
}
return true;
}
static bool Listen(int sockfd){
if(listen(sockfd,BACKLOG)<0){
exit(-3);
}
return true;
}
};
}select_server.hpp文件
#pragma once
#include<vector>
#include"server.hpp"
#include<unistd.h>
#include<time.h>
namespace Select{
class select_server{
private:
int listen_sock;//监听套接字
int port;
public:
select_server(int _port):port(_port){}
//初始化select_server服务器
void InitServer(){
listen_sock=sjp::server::Socket();
sjp::server::Bind(listen_sock,port);
sjp::server::Listen(listen_sock);
}
void Run(){
std::vector<int> readfds_arry(1024,-1);//readfds_arry保存读事件的文件描述符
readfds_arry[0]=listen_sock;//将监听套接字保存进readfds_arry数组中
fd_set readfds;
while(1){
FD_ZERO(&readfds);
int nfds=0;
//将read_arry数组中的文件描述符设置进程readfds_arry位图中
for(int i=0;i<1024;i++)
{
if(readfds_arry[i]!=-1){
FD_SET(readfds_arry[i],&readfds);
if(nfds<readfds_arry[i]){
nfds=readfds_arry[i];
}
}
}
//调用select对readfds中的文件描述符进行等待数据
switch(select(nfds+1,&readfds,NULL,NULL,NULL)){
case 0:
//没有一个文件描述符的读事件就绪
cout<<"select timeout"<<endl;
break;
case -1:
//select失败
cout<<"select error"<<endl;
default:
{
//有读事件发生
Soluation(readfds_arry,readfds);
break;
}
}
}
}
void Soluation(std::vector<int>& readfds_arry,fd_set readfds){
W> for(int i=0;i<readfds_arry.size();i++){
if(FD_ISSET(readfds_arry[i],&readfds))
{
if(readfds_arry[i]==listen_sock){
//有新链接到来
struct sockaddr peer;
socklen_t len;
int newfd=accept(listen_sock,&peer,&len);
cout<<newfd<<endl;
//将新链接设置进readfds_arry数组中
AddfdsArry(readfds_arry,newfd);
}
else{
//其他事件就绪
char str[1024];
int sz=recv(readfds_arry[i],&str,sizeof(str),MSG_DONTWAIT);
switch(sz){
case -1:
//读取失败
cout<<readfds_arry[i]<<": recv error"<<endl;
break;
case 0:
//对端关闭
readfds_arry[i]=-1;
cout<<"peer close"<<endl;
break;
default:
str[sz]='\0';
cout<<str<<endl;
break;
}
}
}
}
}
void AddfdsArry(std::vector<int>& fds_arry,int fd){
W> for(int i=0;i<fds_arry.size();i++){
if(fds_arry[i]==-1){
fds_arry[i]=fd;
break;
}
}
}
};
}select_server.cc文件
#include"select_server.hpp"
int main(int argv,char* argc[]){
if(argv!=2){
cout<<"./selectserver port"<<endl;
exit(-4);
}
int port=atoi(argc[1]);//端口号
Select::select_server* sl=new Select::select_server(port);
sl->InitServer();
sl->Run();
}测试:


5.Select的缺陷
由于fd_set的上限是1024,所以select能等待的读事件的文件描述符和写事件的文件描述是有上限的,如果作为一个大型服务器,能够同时链接的客户端是远远不够的。
每次应用进程调用一次select之前,都需要重新设定writefds和readfds,如果进行轮询调用select,这对影响cpu效率。
内核每一次等待文件描述符 都会重新扫描所有readfds或者writefds中的所有文件描述符,如果有较多的文件描述符,则会影响效率。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment démarrer Apache
Apr 13, 2025 pm 01:06 PM
Comment démarrer Apache
Apr 13, 2025 pm 01:06 PM
Les étapes pour démarrer Apache sont les suivantes: Installez Apache (Commande: Sudo apt-get install Apache2 ou téléchargez-le à partir du site officiel) Start Apache (Linux: Sudo SystemCTL Démarrer Apache2; Windows: Cliquez avec le bouton droit sur le service "APACHE2.4" et SELECT ") Vérifiez si elle a été lancée (Linux: SUDO SYSTEMCTL STATURE APACHE2; (Facultatif, Linux: Sudo SystemCTL
 Que faire si le port Apache80 est occupé
Apr 13, 2025 pm 01:24 PM
Que faire si le port Apache80 est occupé
Apr 13, 2025 pm 01:24 PM
Lorsque le port Apache 80 est occupé, la solution est la suivante: découvrez le processus qui occupe le port et fermez-le. Vérifiez les paramètres du pare-feu pour vous assurer qu'Apache n'est pas bloqué. Si la méthode ci-dessus ne fonctionne pas, veuillez reconfigurer Apache pour utiliser un port différent. Redémarrez le service Apache.
 Comment surveiller les performances de Nginx SSL sur Debian
Apr 12, 2025 pm 10:18 PM
Comment surveiller les performances de Nginx SSL sur Debian
Apr 12, 2025 pm 10:18 PM
Cet article décrit comment surveiller efficacement les performances SSL des serveurs Nginx sur les systèmes Debian. Nous utiliserons NginxExporter pour exporter des données d'état NGINX à Prometheus, puis l'afficher visuellement via Grafana. Étape 1: Configuration de Nginx Tout d'abord, nous devons activer le module Stub_Status dans le fichier de configuration NGINX pour obtenir les informations d'état de Nginx. Ajoutez l'extrait suivant dans votre fichier de configuration Nginx (généralement situé dans /etc/nginx/nginx.conf ou son fichier incluant): emplacement / nginx_status {Stub_status
 Comment configurer un bac de recyclage dans le système Debian
Apr 12, 2025 pm 10:51 PM
Comment configurer un bac de recyclage dans le système Debian
Apr 12, 2025 pm 10:51 PM
Cet article présente deux méthodes de configuration d'un bac de recyclage dans un système Debian: une interface graphique et une ligne de commande. Méthode 1: Utilisez l'interface graphique Nautilus pour ouvrir le gestionnaire de fichiers: Recherchez et démarrez le gestionnaire de fichiers Nautilus (généralement appelé "fichier") dans le menu de bureau ou d'application. Trouvez le bac de recyclage: recherchez le dossier de bac de recyclage dans la barre de navigation gauche. S'il n'est pas trouvé, essayez de cliquer sur "Autre emplacement" ou "ordinateur" pour rechercher. Configurer les propriétés du bac de recyclage: cliquez avec le bouton droit sur "Recycler le bac" et sélectionnez "Propriétés". Dans la fenêtre Propriétés, vous pouvez ajuster les paramètres suivants: Taille maximale: Limitez l'espace disque disponible dans le bac de recyclage. Temps de rétention: définissez la préservation avant que le fichier ne soit automatiquement supprimé dans le bac de recyclage
 Comment redémarrer le serveur Apache
Apr 13, 2025 pm 01:12 PM
Comment redémarrer le serveur Apache
Apr 13, 2025 pm 01:12 PM
Pour redémarrer le serveur Apache, suivez ces étapes: Linux / MacOS: Exécutez Sudo SystemCTL Restart Apache2. Windows: Exécutez net stop apache2.4 puis net start apache2.4. Exécuter netstat -a | Findstr 80 pour vérifier l'état du serveur.
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 L'importance de Debian Sniffer dans la surveillance du réseau
Apr 12, 2025 pm 11:03 PM
L'importance de Debian Sniffer dans la surveillance du réseau
Apr 12, 2025 pm 11:03 PM
Bien que les résultats de la recherche ne mentionnent pas directement "Debiansniffer" et son application spécifique dans la surveillance du réseau, nous pouvons en déduire que "Sniffer" se réfère à un outil d'analyse de capture de paquets de réseau, et son application dans le système Debian n'est pas essentiellement différente des autres distributions Linux. La surveillance du réseau est cruciale pour maintenir la stabilité du réseau et l'optimisation des performances, et les outils d'analyse de capture de paquets jouent un rôle clé. Ce qui suit explique le rôle important des outils de surveillance du réseau (tels que Sniffer Running dans Debian Systems): La valeur des outils de surveillance du réseau: Faute-défaut Emplacement: surveillance en temps réel des métriques du réseau, telles que l'utilisation de la bande passante, la latence, le taux de perte de paquets, etc.
 Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Ce guide vous guidera pour apprendre à utiliser Syslog dans Debian Systems. Syslog est un service clé dans les systèmes Linux pour les messages du système de journalisation et du journal d'application. Il aide les administrateurs à surveiller et à analyser l'activité du système pour identifier et résoudre rapidement les problèmes. 1. Connaissance de base de Syslog Les fonctions principales de Syslog comprennent: la collecte et la gestion des messages journaux de manière centralisée; Prise en charge de plusieurs formats de sortie de journal et des emplacements cibles (tels que les fichiers ou les réseaux); Fournir des fonctions de visualisation et de filtrage des journaux en temps réel. 2. Installer et configurer syslog (en utilisant RSYSLOG) Le système Debian utilise RSYSLOG par défaut. Vous pouvez l'installer avec la commande suivante: SudoaptupDatesud
