
 Périphériques technologiques
IA
La zone de saisie 32k du GPT-4 n'est toujours pas suffisante ? Unlimiformer étend la longueur du contexte à une longueur infinie
Périphériques technologiques
IA
La zone de saisie 32k du GPT-4 n'est toujours pas suffisante ? Unlimiformer étend la longueur du contexte à une longueur infinie
La zone de saisie 32k du GPT-4 n'est toujours pas suffisante ? Unlimiformer étend la longueur du contexte à une longueur infinie

Transformer est l'architecture seq2seq la plus puissante aujourd'hui. Les transformateurs pré-entraînés ont généralement des fenêtres contextuelles de 512 (par exemple BERT) ou 1 024 (par exemple BART), ce qui est suffisamment long pour de nombreux ensembles de données de synthèse de texte actuels (XSum, CNN/DM).
Mais 16384 n'est pas une limite supérieure à la longueur du contexte nécessaire pour générer : des tâches impliquant de longs récits, comme des résumés de livres (Krys-´cinski et al., 2021) ou des questions et réponses narratives (Kociský et al. , 2018), nécessitent souvent des entrées dépassant 100 000 jetons. L'ensemble de défis généré à partir d'articles Wikipédia (Liu* et al., 2018) contient des entrées de plus de 500 000 jetons. Les tâches de domaine ouvert dans la réponse générative aux questions peuvent synthétiser des informations à partir d'entrées plus larges, telles que répondre à des questions sur les propriétés agrégées des articles de tous les auteurs vivants sur Wikipédia. La figure 1 représente la taille de plusieurs ensembles de données de synthèse et de questions-réponses populaires par rapport aux longueurs de fenêtre contextuelle courantes ; l'entrée la plus longue est plus de 34 fois plus longue que la fenêtre contextuelle de Longformer.
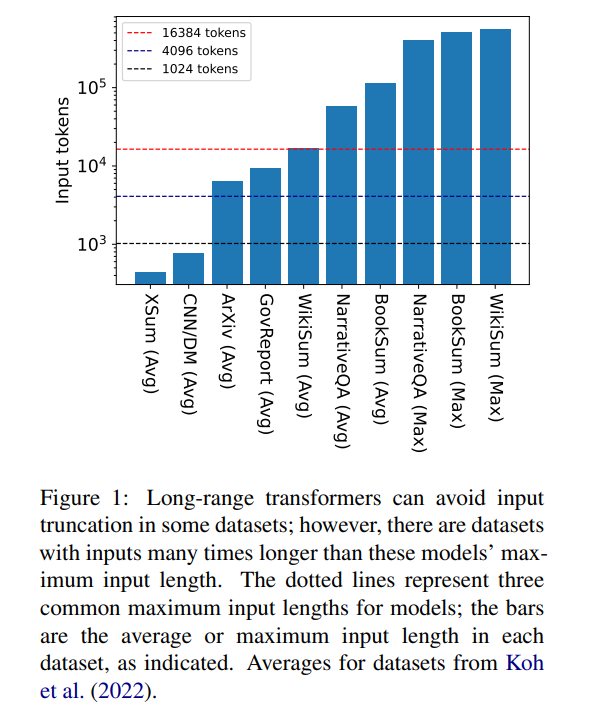
Dans le cas de ces entrées très longues, le transformateur vanille ne peut pas évoluer car le mécanisme d'attention natif a une complexité quadratique. Les transformateurs à entrée longue, bien que plus efficaces que les transformateurs standards, nécessitent néanmoins des ressources de calcul importantes qui augmentent à mesure que la taille de la fenêtre de contexte augmente. De plus, l'augmentation de la fenêtre contextuelle nécessite de recycler le modèle à partir de zéro avec la nouvelle taille de la fenêtre contextuelle, ce qui est coûteux en termes de calcul et d'environnement.
Dans l'article « Unlimiformer : transformateurs à longue portée avec entrée de longueur illimitée », des chercheurs de l'Université Carnegie Mellon ont présenté Unlimiformer. Il s'agit d'une approche basée sur la récupération qui augmente un modèle de langage pré-entraîné pour accepter des entrées de longueur infinie au moment du test. Unlimiformer peut être injecté dans n'importe quel transformateur codeur-décodeur existant, capable de gérer une entrée de longueur illimitée. . Étant donné une longue séquence d'entrée, Unlimiformer peut créer un magasin de données sur les états cachés de tous les jetons d'entrée. Le mécanisme d'attention croisée standard du décodeur est alors capable d'interroger le magasin de données et de se concentrer sur les k premiers jetons d'entrée. Le magasin de données peut être stocké dans la mémoire du GPU ou du CPU et peut être interrogé de manière sublinéaire.
Unlimiformer peut être appliqué directement à un modèle entraîné et peut améliorer les points de contrôle existants sans aucune formation supplémentaire. Les performances d'Unlimiformer seront encore améliorées après un réglage fin. Cet article démontre qu'Unlimiformer peut être appliqué à plusieurs modèles de base, tels que BART (Lewis et al., 2020a) ou PRIMERA (Xiao et al., 2022), sans ajout de poids ni recyclage. Dans divers ensembles de données seq2seq à longue portée, Unlimiformer est non seulement plus puissant que les transformateurs à longue portée tels que Longformer (Beltagy et al., 2020b), SLED (Ivgi et al., 2022) et les transformateurs mémorisants (Wu et al., 2021). ) sur ces ensembles de données, les performances sont meilleures et cet article a également révélé qu'Unlimiform peut être appliqué au-dessus du modèle d'encodeur Longformer pour apporter d'autres améliorations. 
La taille de la fenêtre contextuelle de l'encodeur étant fixe, la longueur maximale d'entrée du Transformer est limitée. Cependant, lors du décodage, différentes informations peuvent être pertinentes et différentes têtes d'attention peuvent se concentrer sur différents types d'informations (Clark et al., 2019). Par conséquent, une fenêtre de contexte fixe peut gaspiller des efforts sur des jetons sur lesquels l’attention est moins concentrée.
À chaque étape de décodage, chaque tête d'attention dans Unlimiformer sélectionne une fenêtre contextuelle distincte parmi toutes les entrées. Ceci est réalisé en injectant la recherche Unlimiformer dans le décodeur : avant d'entrer dans le module d'attention croisée, le modèle effectue une recherche du k-voisin le plus proche (kNN) dans le magasin de données externe, en sélectionnant un ensemble de chaque tête d'attention dans chaque couche de décodeur. jeton pour participer.
Encodage
Afin d'encoder la séquence d'entrée plus longue que la longueur de la fenêtre contextuelle du modèle, cet article encode les blocs d'entrée qui se chevauchent selon la méthode d'Ivgi et al (2022) (Ivgi et al., 2022), en ne conservant que chacun. fragmentez la moitié centrale de la sortie pour garantir un contexte suffisant avant et après le processus d'encodage. Enfin, cet article utilise des bibliothèques telles que Faiss (Johnson et al., 2019) pour indexer les entrées codées dans les magasins de données (Johnson et al., 2019).
Récupérer un mécanisme d'attention croisée amélioré
Dans le mécanisme d'attention croisée standard, le décodeur du transformateur se concentre sur l'état caché final de l'encodeur, et l'encodeur tronque généralement l'entrée et seulement le premier k jetons sont codés.
Cet article ne se concentre pas uniquement sur les k premiers jetons de l'entrée. Pour chaque tête d'attention croisée, il récupère les k premiers états cachés de la série d'entrée la plus longue et se concentre uniquement sur les k premiers. Cela permet au mot-clé d'être récupéré à partir de l'intégralité de la séquence d'entrée plutôt que de tronquer le mot-clé. Notre approche est également moins coûteuse en termes de calcul et de mémoire GPU que le traitement de tous les jetons d'entrée, tout en conservant généralement plus de 99 % des performances d'attention.
La figure 2 montre les modifications apportées par cet article à l'architecture du transformateur seq2seq. L'entrée complète est codée par bloc à l'aide du codeur et stockée dans une mémoire de données ; la mémoire de données d'état latent codée est ensuite interrogée lors du décodage. La recherche kNN est non paramétrique et peut être injectée dans n'importe quel transformateur seq2seq pré-entraîné, comme détaillé ci-dessous.
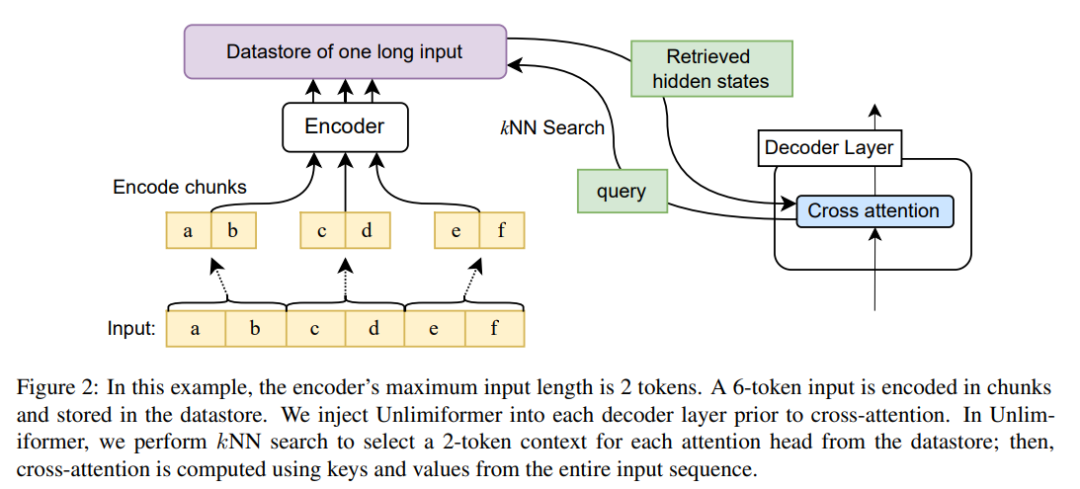
Résultats expérimentaux
Résumé du document long
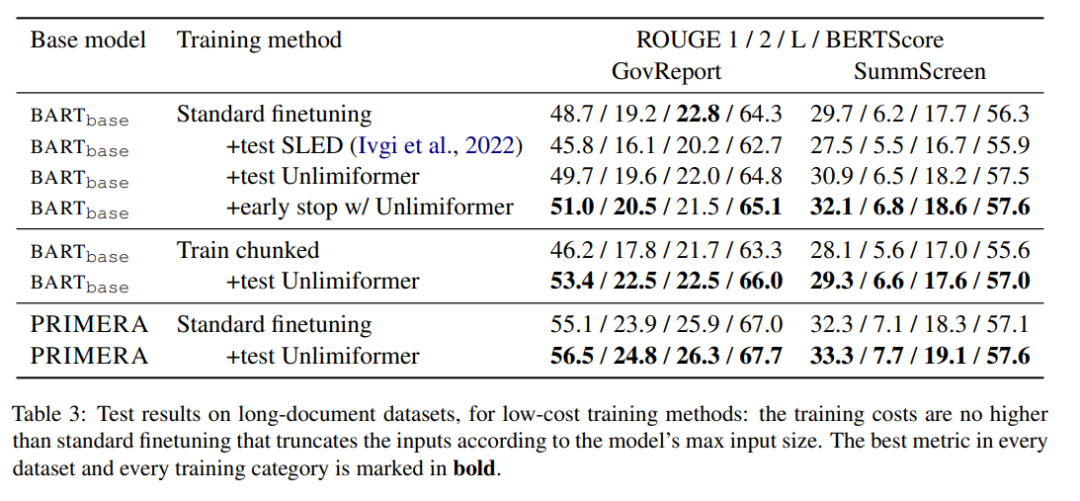
Le tableau 3 montre les résultats dans l'ensemble de données récapitulatives en texte long (entrée de jeton 4k et 16k).
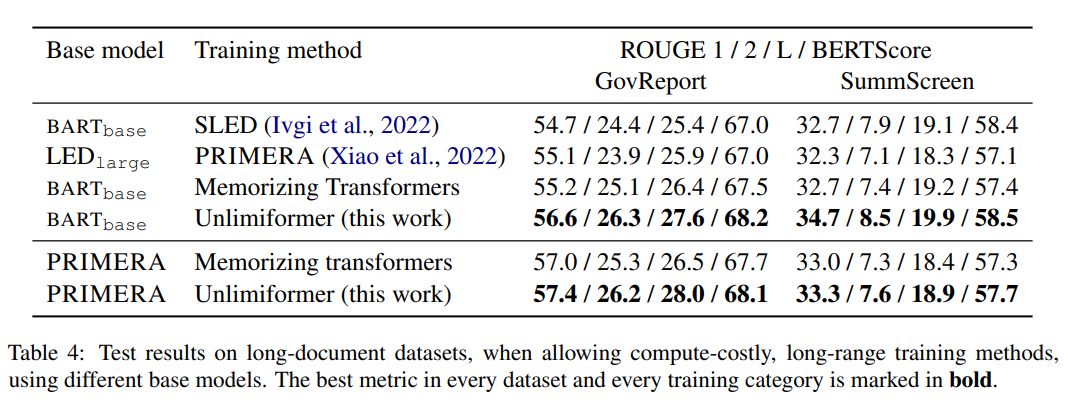
Parmi les méthodes d'entraînement du tableau 4, Unlimiformer peut obtenir le meilleur dans divers indicateurs.
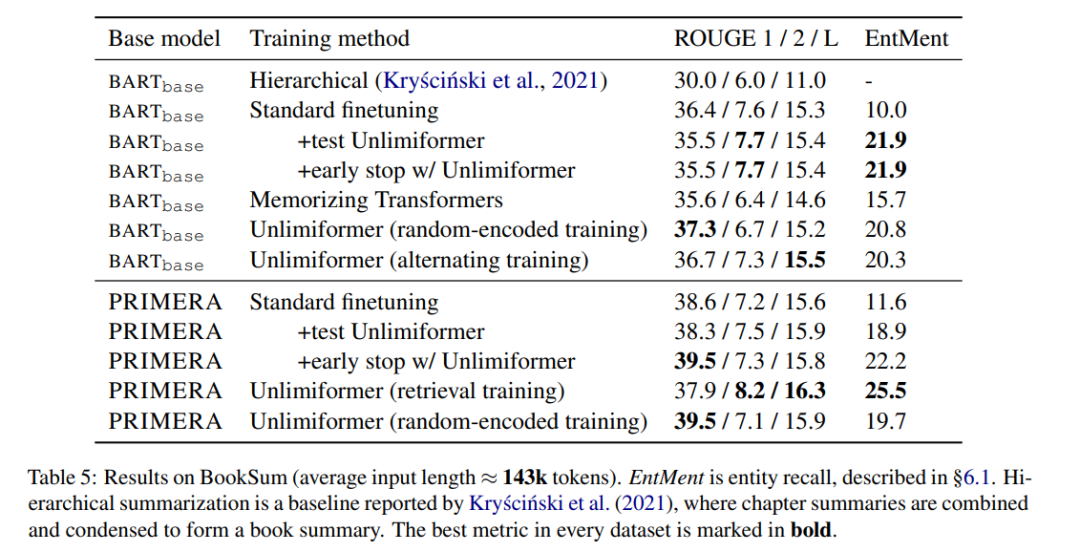
Résumé du livre
Le tableau 5 montre les résultats sur le résumé du livre. On peut voir que sur la base de BARTbase et PRIMERA, l'application d'Unlimiformer peut obtenir certains résultats d'amélioration.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ajouter une nouvelle colonne dans SQL
Apr 09, 2025 pm 02:09 PM
Comment ajouter une nouvelle colonne dans SQL
Apr 09, 2025 pm 02:09 PM
Ajoutez de nouvelles colonnes à une table existante dans SQL en utilisant l'instruction ALTER TABLE. Les étapes spécifiques comprennent: la détermination des informations du nom de la table et de la colonne, rédaction des instructions de la table ALTER et exécution des instructions. Par exemple, ajoutez une colonne de messagerie à la table des clients (VARCHAR (50)): Alter Table Clients Ajouter un e-mail VARCHAR (50);
 Quelle est la syntaxe pour ajouter des colonnes dans SQL
Apr 09, 2025 pm 02:51 PM
Quelle est la syntaxe pour ajouter des colonnes dans SQL
Apr 09, 2025 pm 02:51 PM
La syntaxe pour ajouter des colonnes dans SQL est alter table table_name Ajouter Column_name data_type [pas null] [default default_value]; Lorsque Table_Name est le nom de la table, Column_name est le nouveau nom de colonne, DATA_TYPE est le type de données, et non Null Spécifie si les valeurs NULL sont autorisées, et default default_value spécifie la valeur par défaut.
 Tableau Clear SQL: Conseils d'optimisation des performances
Apr 09, 2025 pm 02:54 PM
Tableau Clear SQL: Conseils d'optimisation des performances
Apr 09, 2025 pm 02:54 PM
Conseils pour améliorer les performances de compensation de la table SQL: utilisez une table tronquée au lieu de supprimer, libre d'espace et réinitialiser la colonne d'identité. Désactivez les contraintes de clés étrangères pour éviter la suppression en cascade. Utilisez les opérations d'encapsulation des transactions pour assurer la cohérence des données. Supprimer les mégadonnées et limiter le nombre de lignes via Limit. Reconstruisez l'indice après la compensation pour améliorer l'efficacité de la requête.
 Comment définir des valeurs par défaut lors de l'ajout de colonnes dans SQL
Apr 09, 2025 pm 02:45 PM
Comment définir des valeurs par défaut lors de l'ajout de colonnes dans SQL
Apr 09, 2025 pm 02:45 PM
Définissez la valeur par défaut des colonnes nouvellement ajoutées, utilisez l'instruction ALTER TABLE: Spécifiez des colonnes Ajouter et définissez la valeur par défaut: alter table table_name Ajouter Column_name data_type default_value; Utilisez la clause CONSTRAINT pour spécifier la valeur par défaut: ALTER TABLE TABLE_NAME ADD COLUMN COLUMN_NAME DATA_TYPE CONSTRAINT DEFAULT_CONSTRAINT DEFAULT_VALUE;
 Utilisez la déclaration de suppression pour effacer les tables SQL
Apr 09, 2025 pm 03:00 PM
Utilisez la déclaration de suppression pour effacer les tables SQL
Apr 09, 2025 pm 03:00 PM
Oui, l'instruction Delete peut être utilisée pour effacer une table SQL, les étapes sont les suivantes: Utilisez l'instruction Delete: Delete de Table_Name; Remplacez Table_Name par le nom de la table à effacer.
 Comment gérer la fragmentation de la mémoire redis?
Apr 10, 2025 pm 02:24 PM
Comment gérer la fragmentation de la mémoire redis?
Apr 10, 2025 pm 02:24 PM
La fragmentation de la mémoire redis fait référence à l'existence de petites zones libres dans la mémoire allouée qui ne peut pas être réaffectée. Les stratégies d'adaptation comprennent: Redémarrer Redis: effacer complètement la mémoire, mais le service d'interruption. Optimiser les structures de données: utilisez une structure plus adaptée à Redis pour réduire le nombre d'allocations et de versions de mémoire. Ajustez les paramètres de configuration: utilisez la stratégie pour éliminer les paires de valeurs clés les moins récemment utilisées. Utilisez le mécanisme de persistance: sauvegardez régulièrement les données et redémarrez Redis pour nettoyer les fragments. Surveillez l'utilisation de la mémoire: découvrez les problèmes en temps opportun et prenez des mesures.
 phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
Pour créer un tableau de données à l'aide de PhpMyAdmin, les étapes suivantes sont essentielles: connectez-vous à la base de données et cliquez sur le nouvel onglet. Nommez le tableau et sélectionnez le moteur de stockage (InnODB recommandé). Ajouter les détails de la colonne en cliquant sur le bouton Ajouter une colonne, y compris le nom de la colonne, le type de données, s'il faut autoriser les valeurs nuls et d'autres propriétés. Sélectionnez une ou plusieurs colonnes comme clés principales. Cliquez sur le bouton Enregistrer pour créer des tables et des colonnes.
 Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
La création d'une base de données Oracle n'est pas facile, vous devez comprendre le mécanisme sous-jacent. 1. Vous devez comprendre les concepts de la base de données et des SGBD Oracle; 2. Master les concepts de base tels que SID, CDB (base de données de conteneurs), PDB (base de données enfichable); 3. Utilisez SQL * Plus pour créer CDB, puis créer PDB, vous devez spécifier des paramètres tels que la taille, le nombre de fichiers de données et les chemins; 4. Les applications avancées doivent ajuster le jeu de caractères, la mémoire et d'autres paramètres et effectuer un réglage des performances; 5. Faites attention à l'espace disque, aux autorisations et aux paramètres des paramètres, et surveillez et optimisez en continu les performances de la base de données. Ce n'est qu'en le maîtrisant habilement une pratique continue que vous pouvez vraiment comprendre la création et la gestion des bases de données Oracle.
