

Les modèles de classification peuvent être divisés en deux catégories : les modèles génératifs et les modèles discriminatifs. Cet article explique les différences entre ces deux types de modèles et discute des avantages et des inconvénients de chaque approche.
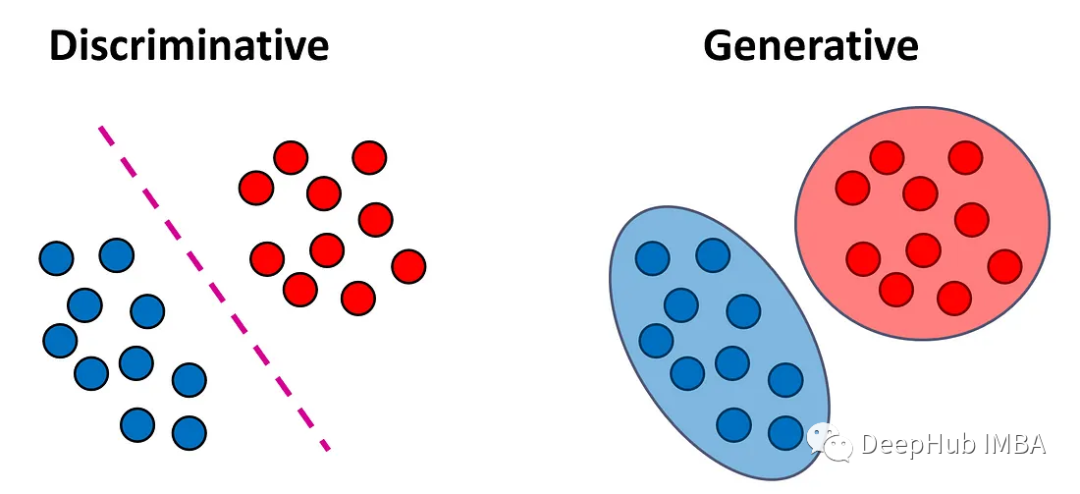
Le modèle discriminatif est un modèle qui peut apprendre la relation entre les données d'entrée et les étiquettes de sortie. Il prédit. étiquettes de sortie en apprenant les caractéristiques des données d’entrée. Dans un problème de classification, notre objectif est d'attribuer à chaque vecteur d'entrée x une étiquette y. Les modèles discriminants tentent d'apprendre directement une fonction f(x) qui mappe les vecteurs d'entrée aux étiquettes. Ces modèles peuvent être divisés en deux sous-types :
Les classificateurs tentent de trouver f(x) sans utiliser de distribution de probabilité. Ces classificateurs génèrent directement une étiquette pour chaque échantillon sans fournir d'estimation de probabilité de la classe. Ces classificateurs sont souvent appelés classificateurs déterministes ou classificateurs sans distribution. Des exemples de tels classificateurs incluent les k voisins les plus proches, les arbres de décision et SVM.
Le classificateur apprend d'abord les probabilités de classe postérieures P(y = k|x) à partir des données d'entraînement, et attribue un nouvel échantillon x à l'une des classes en fonction de ces probabilités (généralement celle avec le classe de probabilité a posteriori la plus élevée).
Ces classificateurs sont souvent appelés classificateurs probabilistes. Des exemples de tels classificateurs incluent la régression logistique et les réseaux de neurones utilisant des fonctions sigmoïdes ou softmax dans la couche de sortie.
Toutes choses étant égales par ailleurs, j'utilise généralement un classificateur probabiliste au lieu d'un classificateur déterministe car ce classificateur fournit des informations supplémentaires sur la confiance dans l'attribution d'un échantillon à une classe spécifique.
Les modèles discriminants généraux incluent :
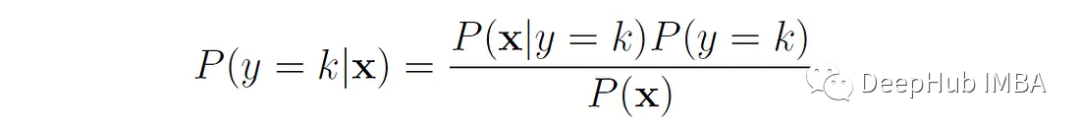
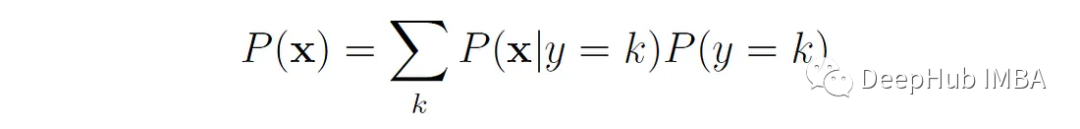
La complexité de la formation est élevée car le modèle génératif nécessite une grande quantité de ressources de calcul et de stockage pour établir une répartition conjointe entre les données d'entrée et les données de sortie. L'hypothèse de distribution des données est relativement forte, car le modèle génératif doit établir une distribution conjointe entre les données d'entrée et les données de sortie, et doit assumer et modéliser la distribution des données. Par conséquent, pour une distribution de données complexe, le modèle génératif est utilisé. convient aux petites échelles. Ne s'applique pas aux ressources informatiques.
Les modèles génératifs peuvent gérer des données multimodales car les modèles génératifs peuvent établir des distributions conjointes multivariées entre les données d'entrée et les données de sortie, étant ainsi capables de gérer des données multimodales.
Modèle discriminant :
Il est difficile, sur le plan informatique, pour un modèle génératif d'apprendre la distribution d'entrée P(x|y) sans faire certaines hypothèses sur les données. Par exemple, si x est constitué de m caractéristiques binaires, afin de prédire P. (x |y), nous devons estimer 2 ᵐ paramètres à partir des données de chaque classe (ces paramètres représentent la probabilité conditionnelle de chacune des 2 ᵐ combinaisons de m caractéristiques). Des modèles tels que Naïve Bayes supposent une indépendance conditionnelle des fonctionnalités pour réduire le nombre de paramètres à apprendre, de sorte que la complexité de la formation est faible. Mais de telles hypothèses aboutissent souvent à des modèles génératifs moins performants que des modèles discriminants.
Il offre de bonnes performances pour la distribution de données complexes et les données de grande dimension, car le modèle discriminant peut modéliser de manière flexible la relation de mappage entre les données d'entrée et les données de sortie.
Le modèle discriminant est sensible aux données bruyantes et aux données manquantes, car le modèle considère uniquement la relation de mappage entre les données d'entrée et les données de sortie, et n'utilise pas les informations contenues dans les données d'entrée pour remplir les valeurs manquantes et supprimer le bruit.
Les modèles génératifs et les modèles discriminants sont tous deux des types de modèles importants dans l'apprentissage automatique. Ils ont chacun leurs propres avantages et scénarios applicables. Dans les applications pratiques, il est nécessaire de sélectionner un modèle approprié en fonction des besoins de tâches spécifiques et de combiner des modèles hybrides et d'autres moyens techniques pour améliorer les performances et l'effet du modèle.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Pourquoi mon téléphone n'est-il pas éteint mais lorsque quelqu'un m'appelle, il me demande de l'éteindre ?
Pourquoi mon téléphone n'est-il pas éteint mais lorsque quelqu'un m'appelle, il me demande de l'éteindre ?
 Comment configurer l'hibernation dans le système Win7
Comment configurer l'hibernation dans le système Win7
 Que signifie Jingdong plus ?
Que signifie Jingdong plus ?
 La différence entre le rembourrage cellulaire et l'espacement cellulaire
La différence entre le rembourrage cellulaire et l'espacement cellulaire
 Méthode chinoise de saisie sublime
Méthode chinoise de saisie sublime
 Comment résoudre les caractères tronqués en PHP
Comment résoudre les caractères tronqués en PHP
 Quelle devise est l'USDT ?
Quelle devise est l'USDT ?
 serveur RTMP
serveur RTMP
 Qu'est-ce que la monnaie numérique
Qu'est-ce que la monnaie numérique








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



