
 Périphériques technologiques
IA
Interface cerveau-ordinateur, ondes cérébrales et IRMf, l'IA maîtrise la lecture des pensées
Périphériques technologiques
IA
Interface cerveau-ordinateur, ondes cérébrales et IRMf, l'IA maîtrise la lecture des pensées
Interface cerveau-ordinateur, ondes cérébrales et IRMf, l'IA maîtrise la lecture des pensées

La lecture dans les pensées peut être considérée comme l'un des superpouvoirs les plus recherchés des êtres humains, et elle doit aussi être le superpouvoir que les gens veulent le moins que les autres aient. Entrez simplement le mot-clé « lire dans les pensées » dans un moteur de recherche et vous trouverez un grand nombre de livres, de vidéos et de tutoriels connexes, ce qui montre que les gens sont obsédés par cette capacité. Mais en mettant de côté ces contenus psychologiques, comportementaux ou mystiques, d’un point de vue technique, il existe des schémas dans les signaux cérébraux humains, et donc la lecture dans les pensées (analyser les schémas des signaux cérébraux) est possible.
Aujourd'hui, avec le développement de la technologie de l'IA, sa capacité à analyser des modèles est devenue de plus en plus sophistiquée et la lecture des pensées devient une réalité.
Il y a quelques jours, un article publié par l'Université du Texas à Austin dans Nature Neuroscience a suscité une discussion animée, selon laquelle il est possible de reconstruire des phrases continues sémantiquement cohérentes en lisant de manière non invasive les signaux cérébraux - sans surprise, le modèle utilise également le Modèle de langage GPT actuellement populaire. Mais laissons de côté ce dernier résultat pour l’instant et examinons d’autres résultats de recherche antérieurs sur la lecture dans les pensées de l’IA pour avoir une compréhension approximative du paysage actuel de la recherche sur ce sujet.
D'une manière générale, la lecture de pensées peut être divisée en deux catégories : la lecture de pensées directe et la lecture de pensées indirecte.
La lecture mentale indirecte fait référence à la déduction des pensées et des émotions d'une personne à travers des caractéristiques indirectes. Ces caractéristiques incluent les expressions faciales, la posture du corps, la température corporelle, la fréquence cardiaque, le rythme respiratoire, la vitesse et le ton de la parole, etc. Ces dernières années, la technologie d'apprentissage profond basée sur le Big Data a permis à l'IA d'identifier avec assez de précision les émotions à travers les expressions faciales. Par exemple, Deepface, une bibliothèque légère de logiciels de reconnaissance faciale open source, peut analyser de manière exhaustive plusieurs caractéristiques telles que l'âge, le sexe, l'émotion et l'émotion. course. Atteint une précision de l'ensemble de test de 97,53 %. Cependant, la technologie d'analyse des émotions basée sur les caractéristiques ci-dessus n'est généralement pas considérée comme une lecture dans les pensées. Après tout, les humains eux-mêmes peuvent plus ou moins deviner les émotions des autres à travers leurs expressions et d'autres caractéristiques. Par conséquent, la technologie de lecture dans les pensées s'est concentrée dans cet article. se limite à la lecture directe des pensées.

Utilisez la bibliothèque Deepfake pour obtenir les résultats de l'analyse des attributs du visage
La lecture mentale directe fait référence à la "traduction" directe des signaux cérébraux sous une forme que d'autres peuvent comprendre, comme du texte, de la voix et images. Actuellement, les chercheurs se concentrent sur trois principaux types de signaux cérébraux : les interfaces cerveau-ordinateur invasives, les ondes cérébrales et la neuroimagerie.
La lecture mentale basée sur une interface cerveau-ordinateur invasive
L'interface cerveau-ordinateur intrusive peut être considérée comme une caractéristique standard des œuvres cyberpunk. Vous pouvez la voir dans de nombreux films ou jeux tels que "Cyberpunk 2077". L'idée de base est de lire les signaux électriques transmis entre les cellules nerveuses dans ou à proximité du cerveau ou du système nerveux. Les signaux cérébraux lus de manière invasive sont généralement plus précis et moins bruyants que les méthodes non invasives.
En 2021, dans l'article « Neuroprosthesis for Decoding Speech in a Paralyzed Person with Anarthria », des chercheurs de l'Université de Californie à San Francisco ont proposé d'utiliser l'IA pour aider les personnes ayant des troubles de la parole à communiquer. Dans cette étude, le sujet était une personne handicapée à un bras et dont la parole était inarticulée. Notamment, leurs expériences ont utilisé un implant neuronal pour acquérir le signal, qui utilisait une combinaison d’un réseau d’électrodes EEG corticales à haute densité et d’un connecteur transcutané. Cette approche intrusive conduit naturellement à une plus grande précision – atteignant une précision maximale de 98 % et un taux de décodage médian de 75 %, le modèle étant capable de décoder à des vitesses allant jusqu'à 18 mots par minute. De plus, l’application de modèles de langage améliore également grandement l’expression de sens des résultats de décodage, qui n’est plus seulement une simple accumulation de chaînes.
Après cela, l'équipe a encore amélioré son système dans l'article 2022 de Nature Neuroscience "Orthographe généralisable à l'aide d'une neuroprothèse vocale chez un individu atteint d'une paralysie sévère des membres et de la voix", intégrant le modèle de langage émergent GPT, ce qui rend les performances encore plus avancées. amélioré.
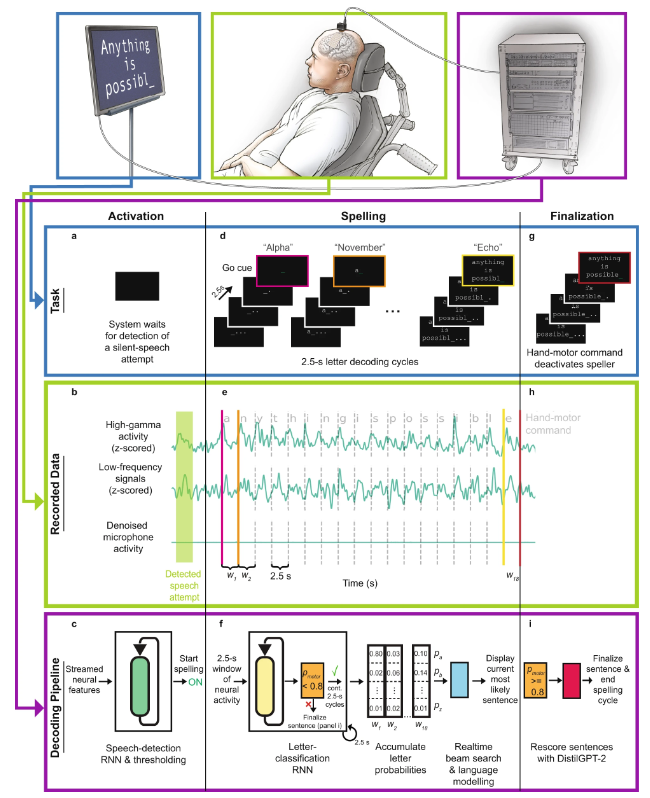
Schéma schématique du flux de travail de l'interface cerveau-ordinateur vocale directe
Plus précisément, le flux de travail est :
- a Au début de l'essai d'orthographe de phrases, les participants ont tenté de prononcer silencieusement un mot, activant ainsi l'orthographe avec conscience.
- b Les caractéristiques neuronales (activité gamma élevée et signaux basse fréquence) sont extraites en temps réel des données corticales enregistrées pendant la tâche. Les signaux du microphone indiquent l'absence de signaux vocaux pendant la tâche.
- c Modèle de détection de la parole, qui consiste en un réseau neuronal récurrent (RNN) et une opération de seuil. Sa tâche est de détecter les caractéristiques neuronales des tentatives d'expression de la parole. Une fois la tentative de parole du sujet détectée, le processus d'orthographe est lancé.
- d Dans le processus d'orthographe, les sujets épellent le message qu'ils souhaitent à travers des cycles de décodage de lettres qui se produisent toutes les 2,5 secondes. À chaque cycle, les sujets pouvaient voir un compte à rebours et la fin du compte à rebours constituait le signal de départ. Après avoir reçu le signal de départ, les sujets ont tenté de prononcer silencieusement le mot de code représentant la lettre souhaitée.
- e Pendant l'orthographe, une activité gamma élevée et des signaux basse fréquence sont calculés pour tous les canaux d'électrodes et attribués à des fenêtres temporelles sans chevauchement d'une durée de 2,5 secondes.
- f Le modèle de classification des lettres basé sur RNN traite chaque fenêtre temporelle neuronale pour prédire sa probabilité lorsqu'un participant souhaite prononcer silencieusement chacun des 26 mots de code possibles ou tente d'exécuter une commande de mouvement de la main.
- g Une fois que le participant aura fini d'épeler le message qu'il souhaite exprimer, il essaiera de serrer sa main droite pour mettre fin au processus d'orthographe et terminer la phrase.
- h La fenêtre temporelle neuronale associée à la commande de mouvement de la main est transmise au modèle de classification.
- i Si le classificateur confirme que le participant a tenté d'utiliser une commande de mouvement de la main, une phrase valide est réenregistrée à l'aide d'un modèle de langage basé sur un réseau neuronal (DistilGPT-2). Après une nouvelle notation, la phrase la plus probable est utilisée comme prédiction finale.
Une autre recherche sur l'interface cerveau-ordinateur implantable prétend avoir réussi à reconnaître efficacement l'écriture manuscrite et à convertir les signaux EEG en texte. Dans l'article de Nature « Communication cerveau-texte haute performance via l'écriture manuscrite », des chercheurs de l'Université de Stanford ont réussi à permettre à des personnes paralysées souffrant de lésions de la moelle épinière de taper à une vitesse de 90 caractères par minute, et la précision en ligne d'origine a atteint 94,1 %, en utilisant La précision hors ligne du modèle de langage dépasse 99% !
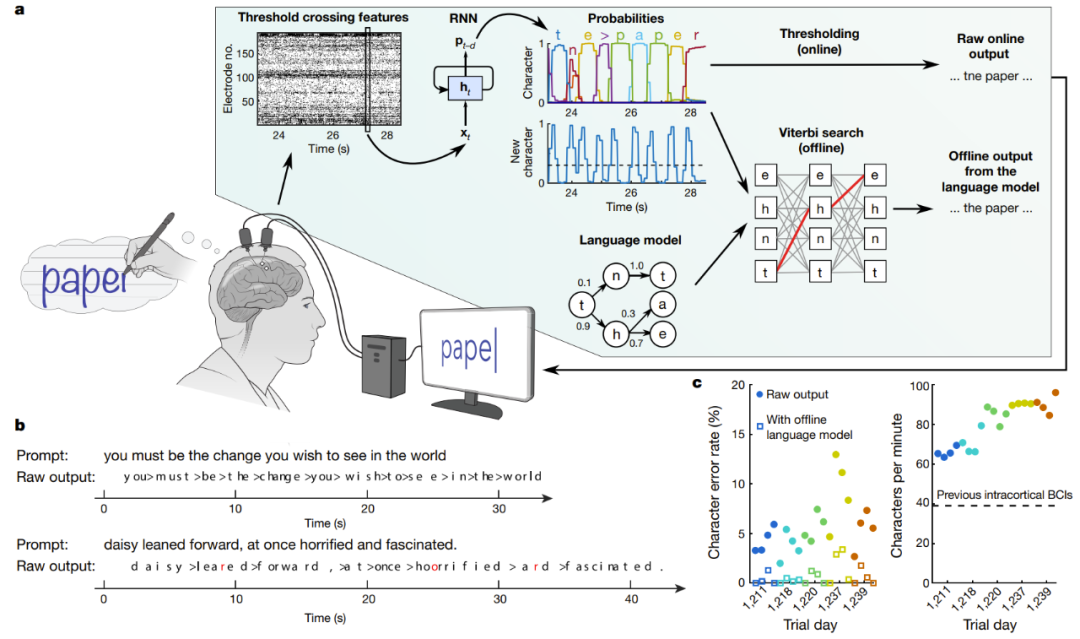
Décodage en temps réel des signaux cérébraux de sujets essayant d'écrire à la main
A sur la figure est un diagramme schématique de l'algorithme de décodage. Premièrement, l’activité neuronale de chaque électrode est combinée et lissée dans le temps. Un RNN est ensuite utilisé pour convertir la série chronologique de la population neuronale en une série chronologique probabiliste, qui décrit la probabilité de chaque caractère et la probabilité de démarrage de tout nouveau caractère. Le RNN a un délai de sortie (d) de 1 seconde, ce qui lui laisse le temps d'observer pleinement chaque caractère avant de déterminer son identité. Enfin, définissez le seuil de probabilité de caractère pour obtenir la « sortie en ligne originale » pour une utilisation en temps réel (lorsque la probabilité d'un nouveau caractère dépasse un certain seuil au temps t, le caractère le plus probable est donné au temps t+0,3 seconde et s'affiche à l'écran). Dans une analyse rétrospective hors ligne, les chercheurs ont combiné les probabilités de caractères avec un modèle de langage doté d'un large vocabulaire pour décoder le texte que les participants étaient le plus susceptibles d'écrire.
Lecture mentale basée sur les ondes cérébrales
Sur la base des résultats de recherche en science du cerveau au cours des dernières décennies, nous savons qu'il existe de minuscules courants dans le processus de transmission des signaux par les cellules nerveuses dans le cerveau, qui produiront de subtiles fluctuations électromagnétiques. Lorsqu’un grand nombre de cellules nerveuses travaillent simultanément, ces fluctuations électromagnétiques peuvent être captées à l’aide d’instruments de précision non invasifs. En 1875, les scientifiques ont observé pour la première fois chez les animaux un phénomène de champ électrique circulant appelé ondes cérébrales. En 1925, Hans Berger invente l'électroencéphalogramme (EEG) et enregistre pour la première fois l'activité électrique du cerveau humain. Au cours des presque cent ans qui ont suivi, la technologie EEG n'a cessé de s'améliorer, et sa précision et ses performances en temps réel ont atteint un niveau très élevé et ont été appliquées commercialement. Vous pouvez désormais même acheter des équipements portables de détection et d'analyse des ondes cérébrales.
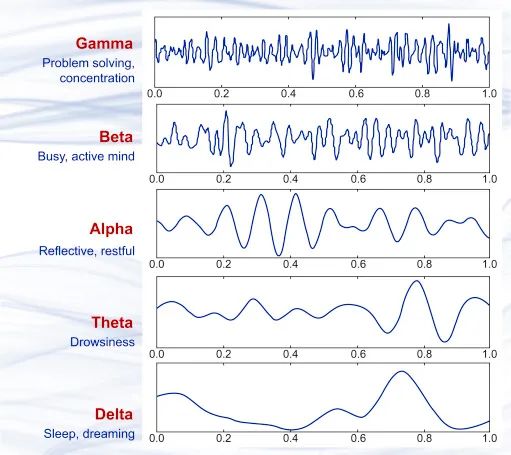
Plusieurs échantillons de forme d'onde d'onde cérébrale différents, de haut en bas sont l'onde γ (au-dessus de 35 Hz), l'onde β (12-35 Hz), l'onde α (8-12 Hz), les ondes thêta ( 4-8 Hz) et les ondes delta (0,5-4 Hz) sont à peu près équivalentes à différents états cérébraux.
En termes d'analyse des émotions et des pensées des gens à travers les ondes cérébrales, la méthode la plus courante consiste à analyser les ondes P300, qui sont les ondes cérébrales générées par le cerveau du sujet environ 300 millisecondes après avoir vu un stimulus. La recherche sur l'analyse des ondes cérébrales s'est poursuivie sans interruption depuis la découverte des ondes cérébrales. Par exemple, en 2001, Lawrence Farwell, un chercheur controversé dans le domaine, a proposé un algorithme capable de détecter si un sujet a vécu quelque chose en évaluant les réponses des ondes cérébrales. , et même si le sujet essayait de le cacher, ce serait en vain. En d’autres termes, il s’agit d’un détecteur de mensonge basé sur les ondes cérébrales.
Étant donné que les ondes cérébrales elles-mêmes sont des signaux avec des motifs, il est naturel d'utiliser des réseaux neuronaux pour analyser les ondes cérébrales. Ci-dessous, nous présenterons quelques méthodes utilisées par les scientifiques pour traduire les signaux des ondes cérébrales en parole, texte et images grâce à certaines recherches menées ces dernières années.
En 2019, une équipe de recherche russe a proposé un système d'interface visuelle cerveau-ordinateur (BCI) capable de reconstruire des images basées sur les ondes cérébrales. L'idée de recherche est très simple : extraire des caractéristiques des signaux des ondes cérébrales, puis extraire des vecteurs de caractéristiques, puis les cartographier pour trouver l'emplacement des caractéristiques dans l'espace caché, et enfin décoder et reconstruire l'image. Parmi eux, le décodeur d'image fait partie d'un modèle d'auto-encodeur convolutif image à image, comprenant 1 couche d'entrée entièrement connectée, suivie de 5 modules de déconvolution, chaque module se compose de 1 couche de déconvolution et il se compose d'activations ReLU, tandis que l'activation de le dernier module est la couche d'activation de la tangente hyperbolique.
Un autre composant important de ce modèle est le mappeur de caractéristiques EEG, dont la fonction est de traduire les données du domaine de caractéristiques EEG vers le domaine d'espace caché du décodeur d'image. L’équipe a utilisé le LSTM comme unité récurrente dans le modèle et a utilisé un mécanisme d’attention pour un raffinement ultérieur. Sa fonction de perte est de minimiser l'erreur quadratique moyenne entre la représentation des caractéristiques de l'EEG et l'image. Pour plus de détails, consultez leur article « Reconstruction d'images naturelles à partir d'ondes cérébrales : un nouveau système visuel BCI avec retour natif ».
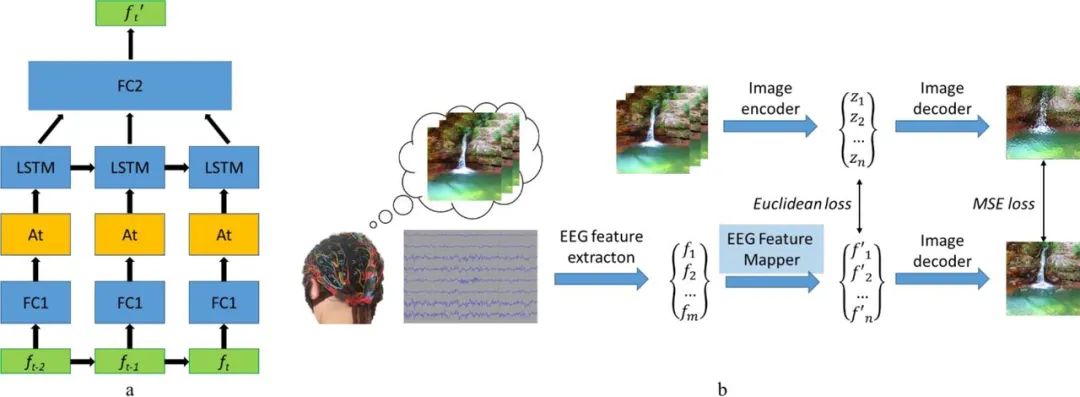
Structure du modèle (a) et routine d'entraînement (b) du mappeur de caractéristiques EEG
Vous trouverez ci-dessous quelques exemples de résultats, on peut voir qu'il existe une différence significative entre l'image reconstruite et l'association d'images originale.

L'image originale vue par le sujet (à gauche de chaque paire d'images) et l'image reconstruite à partir des ondes cérébrales du sujet (à droite de chaque paire d'images)
2022, Meta IA Dans l'article « Décodage de la parole à partir d'enregistrements cérébraux non invasifs », l'équipe a proposé une architecture de réseau neuronal capable de décoder les signaux vocaux provenant des signaux d'électroencéphalographie (EEG) ou de magnétoencéphalographie (MEG).
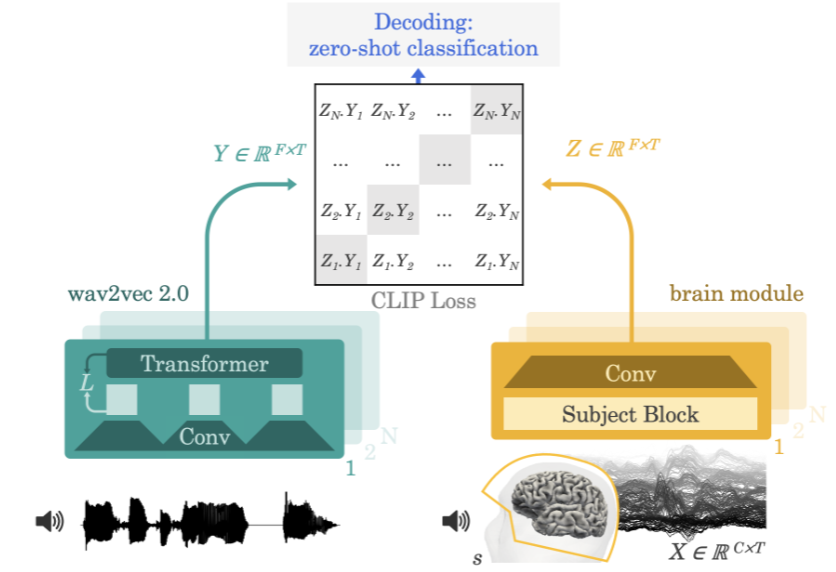
Méthode de l'équipe Meta AI
La méthode utilisée par l'équipe consiste à faire écouter aux participants expérimentaux des histoires ou des phrases tout en enregistrant une électroencéphalographie ou une magnétoencéphalographie de leur activité cérébrale. Pour ce faire, le modèle extrait d'abord une représentation contextuelle profonde du signal vocal de 3 secondes (Y) via un modèle auto-supervisé pré-entraîné (wav2vec 2.0), et apprend également une représentation de l'activité cérébrale dans le 3 aligné correspondant. -deuxième fenêtre (X) (Z). La représentation Z est donnée par un réseau convolutif profond. Au cours de l'évaluation, les chercheurs ont alimenté le modèle avec les phrases restantes et ont calculé chaque segment de langage de 3 secondes en fonction de chaque représentation cérébrale. En conséquence, ce processus de décodage peut être nul, permettant au modèle de prédire les clips audio qui ne sont pas inclus dans l'ensemble d'apprentissage.
Lecture mentale basée sur la neuroimagerie
Les scientifiques peuvent également utiliser une technologie appelée imagerie par résonance magnétique fonctionnelle (IRMf) pour comprendre l'activité cérébrale. La technologie, développée au début des années 1990, fonctionne en examinant le flux sanguin dans le cerveau grâce à l'imagerie par résonance magnétique pour détecter l'activité cérébrale. La technologie peut révéler si des zones fonctionnelles spécifiques du cerveau sont actives.
Quand on dit qu'une certaine zone du cerveau est « plus active », qu'entend-on par là ? Comment l’IRMf détecte-t-elle cette activité ?
Lorsque les neurones d'une zone cérébrale commencent à envoyer plus de signaux électriques qu'avant, on dit que cette zone cérébrale est plus active. Par exemple, si une zone spécifique du cerveau devient plus active lorsque vous soulevez votre jambe, alors cette zone du cerveau peut être considérée comme responsable du contrôle du levage de la jambe.
fMRI détecte cette activité électrique en mesurant les niveaux d'oxygène dans le sang. C’est ce qu’on appelle la réponse dépendante du niveau d’oxygène dans le sang (BOLD). La façon dont cela fonctionne est que lorsque les neurones sont plus actifs, ils ont besoin de plus d’oxygène provenant des globules rouges. Pour ce faire, les vaisseaux sanguins environnants s’élargissent pour permettre à davantage de sang de circuler. Ainsi, lorsque les neurones sont plus actifs, les niveaux d’oxygène augmentent. Le sang oxygéné crée moins d'interférences de champ que le sang désoxygéné, permettant au signal du neurone (qui est essentiellement de l'hydrogène dans l'eau) de durer plus longtemps. Ainsi, lorsque le signal persiste plus longtemps, l’IRMf sait que la zone contient plus d’oxygène, ce qui signifie qu’elle est plus active. Après avoir codé en couleur cette activité, des images IRMf sont obtenues.
Ensuite, nous examinerons la recherche mentionnée précédemment sur l'utilisation de GPT pour reconstruire des phrases continues sémantiquement cohérentes "Reconstruction sémantique du langage continu à partir d'enregistrements cérébraux non invasifs" . Ils proposent un décodeur non invasif capable de reconstruire un langage naturel continu basé sur des représentations corticales de la signification sémantique dans les enregistrements IRMf. Lorsqu'on lui a présenté de nouveaux enregistrements cérébraux, le décodeur a pu générer des séquences de mots intelligibles qui reproduisaient le sens de la parole entendue par les sujets, de la parole imaginée et même des vidéos silencieuses, ce qui suggère qu'un seul décodeur de langue pourrait être utilisé. Une gamme de tâches sémantiques différentes . Le flux de travail du décodeur de langue est le suivant :
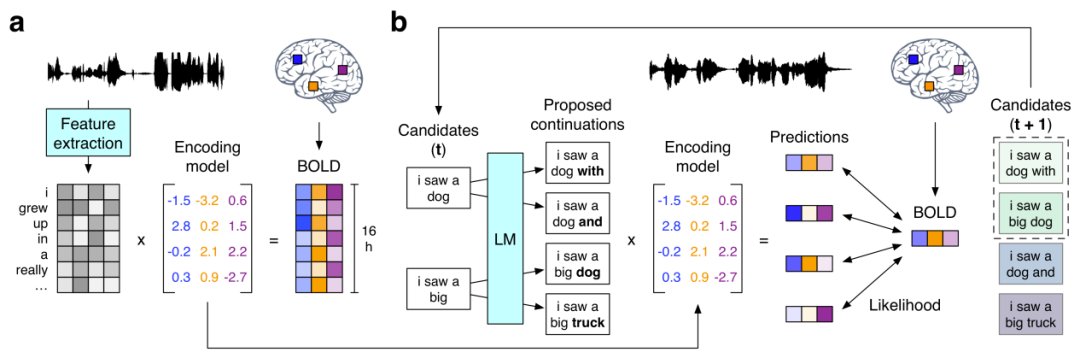
(a) Quand trois réponses BOLD IRMf enregistrées pendant que les sujets écoutaient des histoires narratives pendant 16 heures. Le système estime pour chaque sujet un modèle de codage qui prédit les réponses cérébrales suscitées par les caractéristiques sémantiques des mots utilisés comme stimuli. (b) Pour reconstruire le langage sur la base de nouveaux enregistrements cérébraux, le décodeur conserve un ensemble de séquences de mots candidats. Lorsqu'un nouveau mot est détecté, un modèle de langage propose une continuité pour chaque séquence, et le modèle de codage est ensuite utilisé pour évaluer la probabilité de la réponse cérébrale enregistrée pour chaque condition de continuité. La séquence contiguë la plus probable est retenue en dernier.
Parmi eux, le modèle de langage utilise le modèle GPT qui est actuellement au cœur de la recherche en IA. Les chercheurs ont affiné le GPT qu'ils ont utilisé sur un vaste corpus de plus de 200 millions de mots de commentaires Reddit et 240 histoires autobiographiques de The Moth Radio Hour et Modern Love. Le modèle a été formé pendant 50 époques avec une longueur de contexte maximale de 100. Quelques résultats expérimentaux sont présentés ci-dessous : Article CVPR 2023 « Voir au-delà du cerveau : modèle de diffusion conditionnelle avec modélisation masquée clairsemée pour le décodage de la vision ». Des chercheurs de l'Université nationale de Singapour, de l'Université chinoise de Hong Kong et de l'Université de Stanford affirment que le modèle MinD-Vis qu'ils ont proposé a réussi à décoder pour la première fois les signaux d'activité cérébrale basés sur l'IRMf en images, et que les images reconstruites sont non seulement riche en détails, mais contient également des caractéristiques sémantiques et d'image précises (texture, forme, etc.).
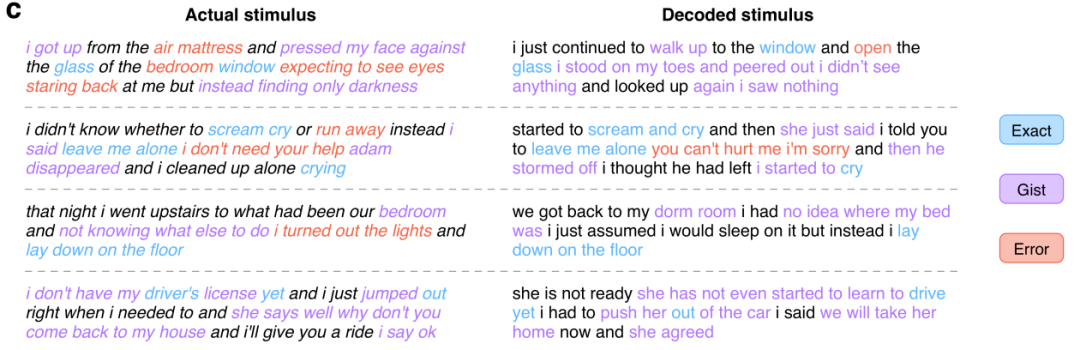
Schéma de workflow MinD-Vis
# 🎜🎜#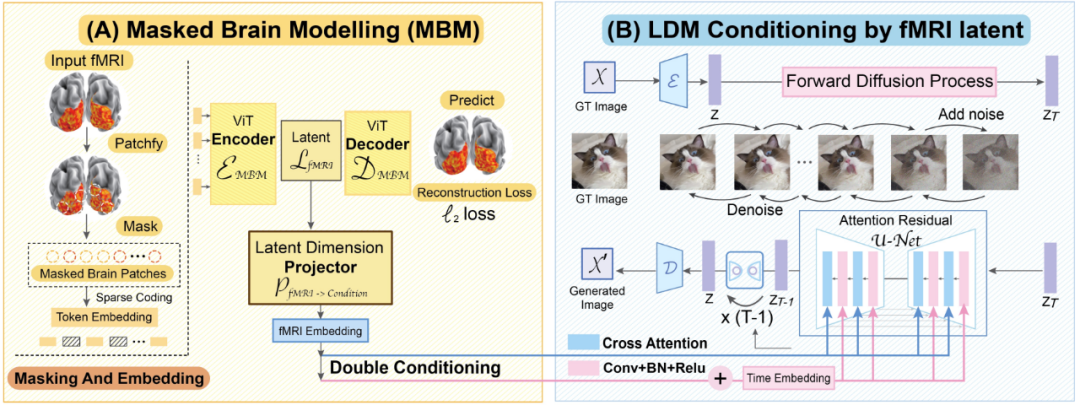 Jetons un coup d'œil aux deux étapes de travail de MinD-Vis. Comme le montre la figure, à l'étape A, le pré-entraînement est effectué sur IRMf à l'aide de SC-MBM (Sparse Coding Masked Brain Modeling). Masquez ensuite de manière aléatoire les IRMf et symbolisez-les en grandes intégrations. Les chercheurs ont formé un auto-encodeur pour récupérer les correctifs masqués. À l'étape B, il est intégré au modèle de diffusion latente (LDM) via un double conditionnement. Un algorithme de projection de dimension latente a été utilisé pour projeter l'espace latent IRMf vers l'espace conditionnel LDM via deux chemins. L'une des solutions consiste à connecter directement les têtes d'attention croisée dans LDM. Une autre voie consiste à ajouter des implications IRMf à l’intégration temporelle.
Jetons un coup d'œil aux deux étapes de travail de MinD-Vis. Comme le montre la figure, à l'étape A, le pré-entraînement est effectué sur IRMf à l'aide de SC-MBM (Sparse Coding Masked Brain Modeling). Masquez ensuite de manière aléatoire les IRMf et symbolisez-les en grandes intégrations. Les chercheurs ont formé un auto-encodeur pour récupérer les correctifs masqués. À l'étape B, il est intégré au modèle de diffusion latente (LDM) via un double conditionnement. Un algorithme de projection de dimension latente a été utilisé pour projeter l'espace latent IRMf vers l'espace conditionnel LDM via deux chemins. L'une des solutions consiste à connecter directement les têtes d'attention croisée dans LDM. Une autre voie consiste à ajouter des implications IRMf à l’intégration temporelle.
À en juger par les résultats expérimentaux donnés dans l'article, la capacité de lecture dans les pensées de ce modèle est en effet très bonne :

L'image de gauche est l'image originale vue par le sujet, la case rouge marque les résultats de reconstruction de MinD-Vis et les trois colonnes suivantes sont les résultats d'autres méthodes.
Conclusion
Avec l'augmentation de la quantité de données et l'amélioration des algorithmes, l'intelligence artificielle comprend de plus en plus profondément notre monde, et en tant que partie de ce monde, nous, les humains, sommes naturellement les objets de compréhension - en à la découverte des êtres humains Les modèles d'activité cérébrale, les machines acquièrent la capacité de comprendre ce que pensent les humains de bas en haut. Peut-être qu’un jour dans le futur, l’IA pourra devenir un véritable maître de la lecture des pensées, et pourrait même avoir la capacité de capturer les rêves humains avec une haute fidélité !
Ce qui précède présente simplement quelques résultats de recherche récents sur l'IA en lecture directe des pensées. En fait, certaines entreprises ont commencé à travailler sur la commercialisation de technologies connexes, telles que les interfaces cerveau-ordinateur représentées par Neuralink et Blackrock Neurotech. des sociétés de neurotechnologie, dont les futurs produits potentiels auront des applications passionnantes, comme aider les personnes atteintes de handicaps inexprimables à se reconnecter au monde et contrôler à distance les machines qui fonctionnent dans des zones dangereuses telles que les profondeurs marines et l'espace. Dans le même temps, le développement de ces technologies a également donné à de nombreuses personnes l’espoir de déchiffrer le mystère de la conscience humaine.
Bien sûr, ce type de technologie a également amené de nombreuses personnes à s'inquiéter en matière de confidentialité, de sécurité et d'éthique. Après tout, nous avons vu ce type de technologie être utilisé à des fins malveillantes dans de nombreux films ou romans. De nos jours, le développement ultérieur de ces technologies est inévitable. Par conséquent, comment garantir que ces technologies sont compatibles avec les intérêts humains est devenu une question importante qui nécessite une réflexion et un débat de la part de toutes les personnes et décideurs politiques concernés.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
