

Comment créer et appeler des fonctions en Python

Créer une fonction
Une fonction est créée à l'aide de l'instruction def. La syntaxe est la suivante : def 语句创建,语法如下:
def 函数名(参数列表): # 具体情况具体对待,参数可有可无
"""函数说明文档字符串"""
函数封装的代码
……标题行由 def 关键字,函数的名字,以及参数的集合(如果有的话)组成
def 子句的剩余部分包括了一个虽然可选但是强烈推荐的文档字串,和必需的函数体
函数名称 的命名应该 符合 标识符的命名规则
可以由 字母、下划线 和 数字 组成
不能以数字开头
不能与关键字重名
def washing_machine(): # 洗衣机可以帮我们完成
print("打水")
print("洗衣服")
print("甩干")调用函数
使用一对圆括号 () 调用函数,如果没有圆括号,只是对函数的引用
任何输入的参数都必须放置在括号中
图例:

案例:加洗衣粉
def washing_machine(): # 洗衣机可以帮我们完成
print("打水")
print("加洗衣粉!!!")
print("洗衣服")
print("甩干")
# 早上洗衣服
washing_machine()
# 中午洗衣服
washing_machine()
# 晚上洗衣服
washing_machine()
总结
定义好函数之后,只表示这个函数封装了一段代码而已
如果不主动调用函数,函数是不会主动执行的
思考
能否将 函数调用 放在 函数定义 的上方?
不能!
因为在 使用函数名 调用函数之前,必须要保证
Python已经知道函数的存在否则控制台会提示
NameError: name 'menu' is not defined(名称错误:menu 这个名字没有被定义)
函数的参数
形参和实参
形参:定义 函数时,小括号中的参数,是用来接收参数用的,在函数内部 作为变量使用
实参:调用 函数时,小括号中的参数,是用来把数据传递到 函数内部 用的
问题
当我们想洗其他的东西,要手动改方法内部的代码:
def washing_machine(): # 洗衣机可以帮我们完成
print("打水")
print("加洗衣粉!!!")
print("洗床单") # 洗被套
print("甩干")在函数内部有一定的变化的值:
def washing_machine(): # 洗衣机可以帮我们完成
print("打水")
print("加洗衣粉!!!")
print("洗衣服")
print("甩干")
washing_machine()
def washing_machine(): # 洗衣机可以帮我们完成
print("打水")
print("加洗衣粉!!!")
print("洗床单")
print("甩干")
washing_machine()
......思考一下存在什么问题
函数只能处理固定的数据
如何解决?
如果能够把需要处理的数据,在调用函数时,传递到函数内部就好了!
传递参数
在函数名的后面的小括号内部填写 参数
多个参数之间使用
,分隔调用函数时,实参的个数需要与形参个数一致,实参将依次传递给形参
def washing_machine(something): # 洗衣机可以帮我们完成
print("打水")
print("加洗衣粉!!!")
print("洗" + something)
print("甩干")
# 洗衣服
washing_machine("衣服")
# 洗床单
washing_machine("床单")图例

def washing_machine(xidiji,something): # 洗衣机可以帮我们完成
print("打水")
print("加" + xidiji)
print("洗衣服" + something)
print("甩干")
#早上洗衣服
#按照参数位置顺序传递参数的方式叫做位置传参
#使用洗衣机,执行洗衣机内部的逻辑
washing_machine("洗衣液","衣服")#something = 衣服
#中午洗被罩
washing_machine("洗衣粉","被罩")# something = 被罩
#晚上洗床单
washing_machine("五粮液","床单")# something = 床单作用
函数,把 具有独立功能的代码块 组织为一个小模块,在需要的时候 调用
函数的参数,增加函数的 通用性,针对 相同的数据处理逻辑,能够 适应更多的数据
1.在函数 内部,把参数当做 变量 使用,进行需要的数据处理
2.函数调用时,按照函数定义的参数顺序,把 希望在函数内部处理的数据,通过参数 传递
位置参数
与 shell 脚本类似,程序名以及参数都以位置参数的方式传递给 python 程序,使用 sys 模块的 argv 列表接收
图例
默认参数
默认参数就是声明了 默认值 的参数,因为给参数赋予了默认值,所以在函数调用时,不向该参数传入值也是允许的
函数的返回值
在程序开发中,有时候,会希望 一个函数执行结束后,告诉调用者一个结果,以便调用者针对具体的结果做后续的处理
返回值 是函数 完成工作后,最后 给调用者的 一个结果
在函数中使用
returnLa ligne d'en-tête est constituée du mot-clé# 函数的返回值: return, 用于对后续逻辑的处理 # 理解: 把结果揣兜里,后续想干啥干啥,想打印打印,想求和就求和 # 注意: # a. 函数中如果没有return,那么解释器会自动加一个return None # b. return表示函数的终止,return后的代码都不会执行 # 1 定义一个函数,计算两个数的和 # 2 计算这两个数的和是不是偶数 def get_sum(x, y=100): # 默认参数 he = x + y # sum = 10 + 20 return he # return 30 print("return表示函数的终止,return后的代码都不会执行") # 将函数return后的结果赋值给变量dc: dc = sum -> dc = 30 dc = get_sum(10, 20) # x = 10, y = 20 print("dc:", dc) # 30 dc1 = get_sum(10) # x = 10, y = 100 print("dc1:", dc1) # 110 # if dc % 2 == 0: # print("偶数") # else: # print("奇数")Copier après la connexionCopier après la connexiondef. nom de la fonction et l'ensemble des paramètres (le cas échéant), le reste de la clausedefse compose d'une chaîne de documentation facultative mais fortement recommandée, et d'un corps de fonction requis< /strong>🎜🎜La dénomination des noms de fonctions doit être conforme aux règles de dénomination des identifiants🎜- 🎜peut être composé de lettres, de traits de soulignement et de chiffres🎜
- 🎜ne peut pas commencer par un chiffre🎜
- 🎜ne peut pas avoir le même nom qu'un mot-clé🎜< /li>
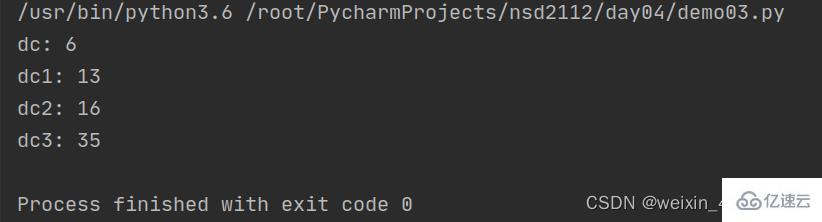
#默认参数 #注意:具有默认值的参数后面不能跟没有默认值的参数 def get_sum(a=20,b=5,c=10): he = a + b+ c return he dc = get_sum(1,2,3) #a=1 b=2 c=3 print("dc:",dc) # 6 dc1 = get_sum(1,2) # a=1 b=2 c=10 print("dc1:",dc1) # 13 dc2 = get_sum(1) # a=1 b=5 c=10 print("dc2:",dc2) # 16 dc3 = get_sum() print("dc3:",dc3) # 35Copier après la connexionCopier après la connexionAppeler une fonction
🎜Utilisez une paire de parenthèses () pour appeler une fonction S'il n'y a pas de parenthèses, c'est juste une référence à la fonction🎜🎜Tous les paramètres d'entrée. doit être placé entre parenthèses🎜🎜Légende : < /strong>🎜🎜 🎜🎜 Cas : Ajouter de la lessive🎜🎜
🎜🎜 Cas : Ajouter de la lessive🎜🎜def new_fib(n=8): list01 = [0,1] #定义列表,指定初始值 for dc in range(n-2): list01.append(list01[-1]+list01[-2]) return list01 dc = new_fib() #不加参数默认是8 dc1 = new_fib(10) print("dc:",dc) print("dc1:",dc1)Copier après la connexionCopier après la connexion🎜🎜Résumé🎜- 🎜Après la définition la fonction, cela signifie seulement que cette fonction encapsule un morceau de code🎜
- 🎜Si vous n'appelez pas activement la fonction, la fonction ne sera pas activement exécutée🎜
- 🎜Puis-je placer l'appel de fonction au-dessus de la définition de fonction ? 🎜
- 🎜Non ! 🎜
- 🎜Parce qu'avant d'utiliser le nom de la fonction pour appeler la fonction, vous devez vous assurer que
Pythonconnaît déjà l'existence de la fonction🎜 - 🎜 Sinon, la console affichera
NameError : le nom 'menu' n'est pas défini(NameError : le nom 'menu' n'est pas défini)🎜 - 🎜Paramètres formels : Définition Lorsqu'une fonction est utilisée, les paramètres entre parenthèses sont utilisés pour recevoir des paramètres. Ils sont utilisés comme variables à l'intérieur de la fonction🎜
- 🎜<. strong>paramètres réels
Paramètres formels et paramètres réels
#练习:生成随机密码
#创建 randpass.py 脚本,要求如下:
#编写一个能生成8位随机密码的程序
#使用 random 的 choice 函数随机取出字符
#由用户决定密码长度
import random
def new_password():
n = int(input("密码长度:"))
password = ""
all = "0123456789zxcvbnmlkjhgfdsaqwertyuiopPOIUYTREWQASDFGHJKLMNBVCXZ" # 0-9 a-z A-Z
random.choice(all)
for i in range(n):
dc = random.choice(all)
password += dc
# print("passwd:",password)
return password
# 调用函数,才能执行函数内部逻辑
dc = new_password()
print("dc:",dc)#练习:生成随机密码
#创建 randpass.py 脚本,要求如下:
#编写一个能生成8位随机密码的程序
#使用 random 的 choice 函数随机取出字符
#由用户决定密码长度
import random,string
def new_password():
n = int(input("密码长度:"))
password = ""
all = string.ascii_letters + string.digits
random.choice(all)
for i in range(n):
dc = random.choice(all)
password += dc
# print("passwd:",password)
return password
# 调用函数,才能执行函数内部逻辑
dc = new_password()
print("dc:",dc)Passer les paramètres
- 🎜Remplissez les paramètres entre parenthèses après le nom de la fonction🎜 < li>🎜Utilisez
- 🎜Lors de l'appel d'une fonction, le nombre de paramètres réels doit être cohérent avec le nombre de paramètres formels et les paramètres réels sera transmis dans l'ordre Donnez les paramètres formels🎜
, pour séparer plusieurs paramètres🎜# test.py,将 file_copy.py 放在同级目录下 # 需求:要将/etc/passwd复制到/tmp/passwd src_path = "/etc/passwd" dst_path = "/tmp/passwd" # 如何复制? # 调用已有模块中的方法 # - 很推荐,简单粗暴不动脑 # - 直接使用 file_copy.py的方法即可 # 导入方法一:直接导入模块 import file_copy # 要注意路径问题 file_copy.copy(src_path, dst_path) # 导入方法二:只导入 file_copy 模块的 copy 方法 from file_copy import copy # 如果相同时导入多个模块 from file_copy import * copy(src_path, dst_path) # 导入方法四:导入模块起别名 as import file_copy as fc fc.copy(src_path, dst_path)
 🎜
🎜# foo.py print(__name__) # bar.py import foo # 导入foo.py,会将 foo.py 中的代码完成的执行一次,所以会执行 foo 中的 print(__name__)
- 🎜 fonction, avec indépendant Le bloc de code fonctionnel est organisé en un petit module. Les paramètres de la fonction 🎜
- 🎜 sont appelés en cas de besoin, augmentant la polyvalence de la fonction. Pour la même logique de traitement des données, elle peut. s'adapter à plus de données 🎜
Paramètres de position
🎜 est similaire au scriptshell Le nom du programme et les paramètres sont transmis. au programme python sous forme de paramètres de position, en utilisant La liste <code>argv du module sys reçoit 🎜🎜Legend🎜🎜 🎜Paramètres par défaut< /h5>🎜Les paramètres par défaut sont des paramètres avec une valeur par défaut déclarée. Étant donné que le paramètre reçoit une valeur par défaut, il est autorisé de ne pas transmettre de valeur au paramètre lors de l'appel de la fonction🎜🎜La valeur de retour. de la fonction🎜- 🎜Dans le développement de programmes Parfois, vous souhaitez indiquer à l'appelant un résultat après l'exécution d'une fonction afin que l'appelant puisse faire traitement ultérieur sur le résultat spécifique🎜
- 🎜Return La valeur est le résultat donné à l'appelant une fois que la fonction termine son travail strong> et finally Utilisez le mot-clé
return pour renvoyer les résultats🎜 调用函数一方,可以 使用变量 来 接收 函数的返回结果
案例:计算任意两个数字的和
# 函数的返回值: return, 用于对后续逻辑的处理
# 理解: 把结果揣兜里,后续想干啥干啥,想打印打印,想求和就求和
# 注意:
# a. 函数中如果没有return,那么解释器会自动加一个return None
# b. return表示函数的终止,return后的代码都不会执行
# 1 定义一个函数,计算两个数的和
# 2 计算这两个数的和是不是偶数
def get_sum(x, y=100): # 默认参数
he = x + y # sum = 10 + 20
return he # return 30
print("return表示函数的终止,return后的代码都不会执行")
# 将函数return后的结果赋值给变量dc: dc = sum -> dc = 30
dc = get_sum(10, 20) # x = 10, y = 20
print("dc:", dc) # 30
dc1 = get_sum(10) # x = 10, y = 100
print("dc1:", dc1) # 110
# if dc % 2 == 0:
# print("偶数")
# else:
# print("奇数")Copier après la connexionCopier après la connexion#默认参数
#注意:具有默认值的参数后面不能跟没有默认值的参数
def get_sum(a=20,b=5,c=10):
he = a + b+ c
return he
dc = get_sum(1,2,3) #a=1 b=2 c=3
print("dc:",dc) # 6
dc1 = get_sum(1,2) # a=1 b=2 c=10
print("dc1:",dc1) # 13
dc2 = get_sum(1) # a=1 b=5 c=10
print("dc2:",dc2) # 16
dc3 = get_sum()
print("dc3:",dc3) # 35Copier après la connexionCopier après la connexion
return pour renvoyer les résultats🎜调用函数一方,可以 使用变量 来 接收 函数的返回结果
# 函数的返回值: return, 用于对后续逻辑的处理
# 理解: 把结果揣兜里,后续想干啥干啥,想打印打印,想求和就求和
# 注意:
# a. 函数中如果没有return,那么解释器会自动加一个return None
# b. return表示函数的终止,return后的代码都不会执行
# 1 定义一个函数,计算两个数的和
# 2 计算这两个数的和是不是偶数
def get_sum(x, y=100): # 默认参数
he = x + y # sum = 10 + 20
return he # return 30
print("return表示函数的终止,return后的代码都不会执行")
# 将函数return后的结果赋值给变量dc: dc = sum -> dc = 30
dc = get_sum(10, 20) # x = 10, y = 20
print("dc:", dc) # 30
dc1 = get_sum(10) # x = 10, y = 100
print("dc1:", dc1) # 110
# if dc % 2 == 0:
# print("偶数")
# else:
# print("奇数")#默认参数
#注意:具有默认值的参数后面不能跟没有默认值的参数
def get_sum(a=20,b=5,c=10):
he = a + b+ c
return he
dc = get_sum(1,2,3) #a=1 b=2 c=3
print("dc:",dc) # 6
dc1 = get_sum(1,2) # a=1 b=2 c=10
print("dc1:",dc1) # 13
dc2 = get_sum(1) # a=1 b=5 c=10
print("dc2:",dc2) # 16
dc3 = get_sum()
print("dc3:",dc3) # 35
修改菲波那切数列
def new_fib(n=8):
list01 = [0,1] #定义列表,指定初始值
for dc in range(n-2):
list01.append(list01[-1]+list01[-2])
return list01
dc = new_fib() #不加参数默认是8
dc1 = new_fib(10)
print("dc:",dc)
print("dc1:",dc1)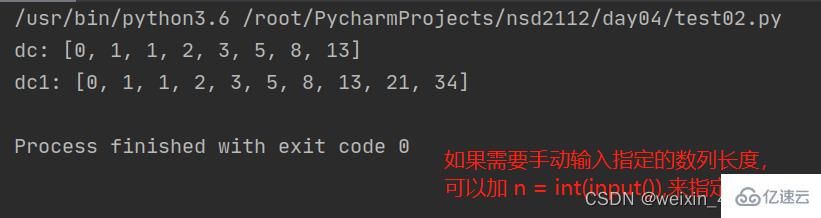
生成随机密码:
#练习:生成随机密码
#创建 randpass.py 脚本,要求如下:
#编写一个能生成8位随机密码的程序
#使用 random 的 choice 函数随机取出字符
#由用户决定密码长度
import random
def new_password():
n = int(input("密码长度:"))
password = ""
all = "0123456789zxcvbnmlkjhgfdsaqwertyuiopPOIUYTREWQASDFGHJKLMNBVCXZ" # 0-9 a-z A-Z
random.choice(all)
for i in range(n):
dc = random.choice(all)
password += dc
# print("passwd:",password)
return password
# 调用函数,才能执行函数内部逻辑
dc = new_password()
print("dc:",dc)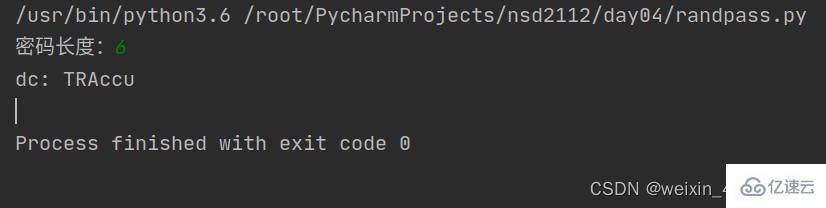
#练习:生成随机密码
#创建 randpass.py 脚本,要求如下:
#编写一个能生成8位随机密码的程序
#使用 random 的 choice 函数随机取出字符
#由用户决定密码长度
import random,string
def new_password():
n = int(input("密码长度:"))
password = ""
all = string.ascii_letters + string.digits
random.choice(all)
for i in range(n):
dc = random.choice(all)
password += dc
# print("passwd:",password)
return password
# 调用函数,才能执行函数内部逻辑
dc = new_password()
print("dc:",dc)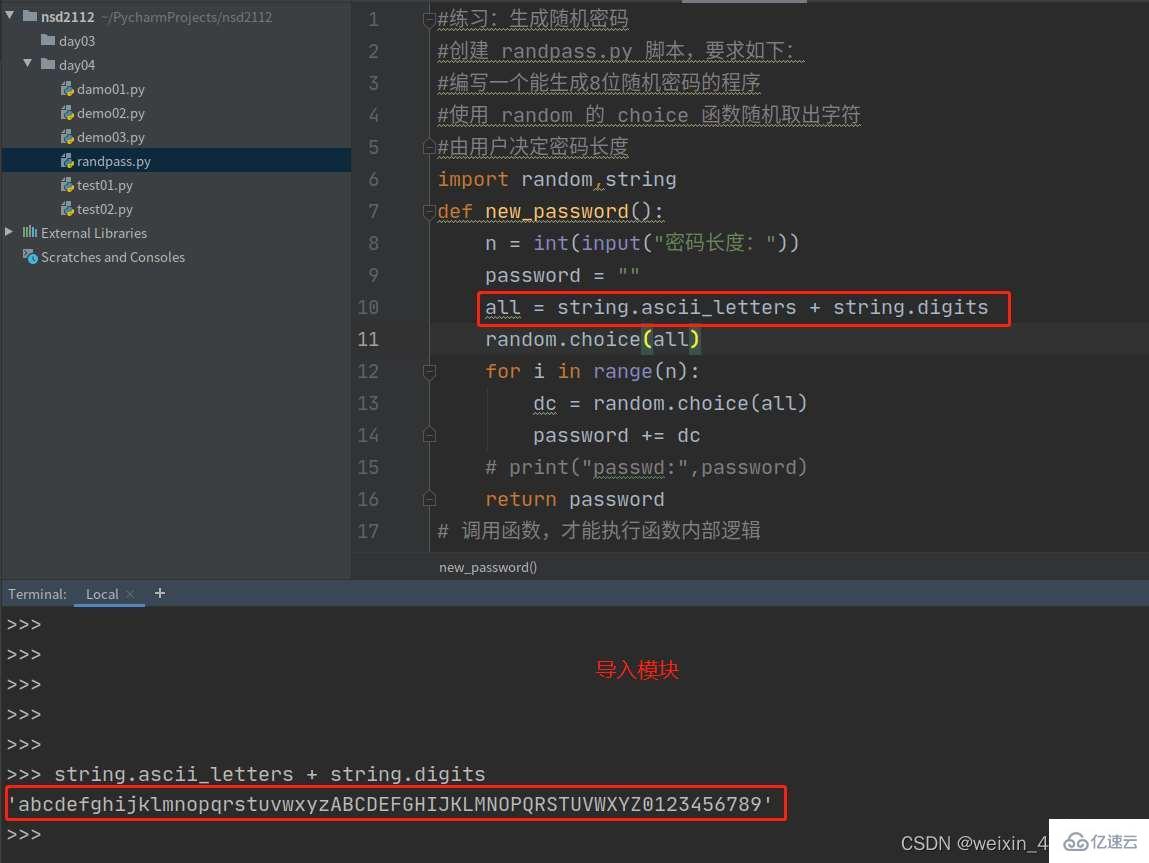
模块基础
定义模块
基本概念
模块是从逻辑上组织python代码的形式
当代码量变得相当大的时候,最好把代码分成一些有组织的代码段,前提是保证它们的 彼此交互
这些代码片段相互间有一定的联系,可能是一个包含数据成员和方法的类,也可能是一组相关但彼此独立的操作函数
导入模块 (import)
使用 import 导入模块
模块属性通过 “模块名.属性” 的方法调用
如果仅需要模块中的某些属性,也可以单独导入
为什么需要导入模块?
可以提升开发效率,简化代码
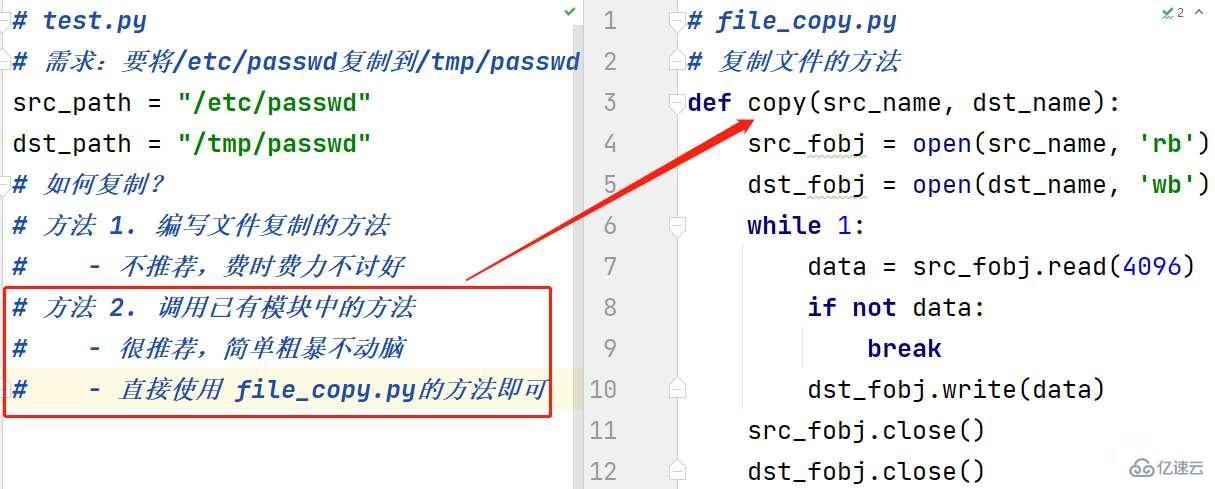
正确使用
# test.py,将 file_copy.py 放在同级目录下 # 需求:要将/etc/passwd复制到/tmp/passwd src_path = "/etc/passwd" dst_path = "/tmp/passwd" # 如何复制? # 调用已有模块中的方法 # - 很推荐,简单粗暴不动脑 # - 直接使用 file_copy.py的方法即可 # 导入方法一:直接导入模块 import file_copy # 要注意路径问题 file_copy.copy(src_path, dst_path) # 导入方法二:只导入 file_copy 模块的 copy 方法 from file_copy import copy # 如果相同时导入多个模块 from file_copy import * copy(src_path, dst_path) # 导入方法四:导入模块起别名 as import file_copy as fc fc.copy(src_path, dst_path)
常用的导入模块的方法
一行指导入一个模块,可以导入多行, 例如:
import random只导入模块中的某些方法,例如:
from random import choice,randint
模块加载 (load)
一个模块只被 加载一次,无论它被导入多少次
只加载一次可以 阻止多重导入时,代码被多次执行
如果两个文件相互导入,防止了无限的相互加载
模块加载时,顶层代码会自动执行,所以只将函数放入模块的顶层是最好的编程习惯
模块特性及案例
模块特性
模块在被导入时,会先完整的执行一次模块中的 所有程序
案例
# foo.py print(__name__) # bar.py import foo # 导入foo.py,会将 foo.py 中的代码完成的执行一次,所以会执行 foo 中的 print(__name__)
结果:
# foo.py -> __main__ 当模块文件直接执行时,__name__的值为‘__main__’
# bar.py -> foo 当模块被另一个文件导入时,__name__的值就是该模块的名字
所以我们以后在 Python 模块中执行代码的标准格式:
def test():
......
if __name__ == "__main__":
test()Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Miniopen Centos Compatibilité
Apr 14, 2025 pm 05:45 PM
Miniopen Centos Compatibilité
Apr 14, 2025 pm 05:45 PM
Minio Object Storage: Déploiement haute performance dans le système Centos System Minio est un système de stockage d'objets distribué haute performance développé sur la base du langage Go, compatible avec Amazons3. Il prend en charge une variété de langages clients, notamment Java, Python, JavaScript et GO. Cet article introduira brièvement l'installation et la compatibilité de Minio sur les systèmes CentOS. Compatibilité de la version CentOS Minio a été vérifiée sur plusieurs versions CentOS, y compris, mais sans s'y limiter: CentOS7.9: fournit un guide d'installation complet couvrant la configuration du cluster, la préparation de l'environnement, les paramètres de fichiers de configuration, le partitionnement du disque et la mini
 Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
La formation distribuée par Pytorch sur le système CentOS nécessite les étapes suivantes: Installation de Pytorch: La prémisse est que Python et PIP sont installés dans le système CentOS. Selon votre version CUDA, obtenez la commande d'installation appropriée sur le site officiel de Pytorch. Pour la formation du processeur uniquement, vous pouvez utiliser la commande suivante: pipinstalltorchtorchVisionTorChaudio Si vous avez besoin d'une prise en charge du GPU, assurez-vous que la version correspondante de CUDA et CUDNN est installée et utilise la version Pytorch correspondante pour l'installation. Configuration de l'environnement distribué: la formation distribuée nécessite généralement plusieurs machines ou des GPU multiples uniques. Lieu
 Comment choisir la version Pytorch sur Centos
Apr 14, 2025 pm 06:51 PM
Comment choisir la version Pytorch sur Centos
Apr 14, 2025 pm 06:51 PM
Lors de l'installation de Pytorch sur le système CentOS, vous devez sélectionner soigneusement la version appropriée et considérer les facteurs clés suivants: 1. Compatibilité de l'environnement du système: Système d'exploitation: Il est recommandé d'utiliser CentOS7 ou plus. CUDA et CUDNN: La version Pytorch et la version CUDA sont étroitement liées. Par exemple, Pytorch1.9.0 nécessite CUDA11.1, tandis que Pytorch2.0.1 nécessite CUDA11.3. La version CUDNN doit également correspondre à la version CUDA. Avant de sélectionner la version Pytorch, assurez-vous de confirmer que des versions compatibles CUDA et CUDNN ont été installées. Version Python: branche officielle de Pytorch
 Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
CENTOS L'installation de Nginx nécessite de suivre les étapes suivantes: Installation de dépendances telles que les outils de développement, le devet PCRE et l'OpenSSL. Téléchargez le package de code source Nginx, dézippez-le et compilez-le et installez-le, et spécifiez le chemin d'installation AS / USR / LOCAL / NGINX. Créez des utilisateurs et des groupes d'utilisateurs de Nginx et définissez les autorisations. Modifiez le fichier de configuration nginx.conf et configurez le port d'écoute et le nom de domaine / adresse IP. Démarrez le service Nginx. Les erreurs communes doivent être prêtées à prêter attention, telles que les problèmes de dépendance, les conflits de port et les erreurs de fichiers de configuration. L'optimisation des performances doit être ajustée en fonction de la situation spécifique, comme l'activation du cache et l'ajustement du nombre de processus de travail.
