
 Java
javaDidacticiel
Comment spécifier dynamiquement plusieurs sujets à l'aide de @KafkaListener dans springboot+kafka
Java
javaDidacticiel
Comment spécifier dynamiquement plusieurs sujets à l'aide de @KafkaListener dans springboot+kafka
Comment spécifier dynamiquement plusieurs sujets à l'aide de @KafkaListener dans springboot+kafka

Description
Ce projet est un projet d'intégration springboot+kafak, il utilise donc l'annotation de consommation kafak @KafkaListener dans springboot
Tout d'abord, configurez plusieurs sujets séparés par des virgules dans application.properties.
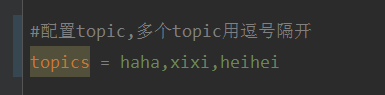
Méthode : utilisez l'expression SpEl de Spring pour configurer les sujets comme : @KafkaListener(topics = "#{’${topics}’.split(’,’)}")
Exécuter le programme et l'effet d'impression de la console est le suivant :

Étant donné qu'un seul fil consommateur est ouvert, tous les sujets et partitions sont attribués à ce fil.
Si vous souhaitez ouvrir plusieurs fils de discussion pour consommer ces sujets, ajoutez le paramètre concurrency de l'annotation @KafkaListener au nombre de consommateurs souhaité (notez que le nombre de consommateurs doit être inférieur ou égal au nombre de consommateurs que vous souhaitez) La somme du nombre de partitions de tous les sujets)

Exécutez le programme et l'effet d'impression de la console est le suivant :

Pour résumer la question la plus fréquemment posée
Comment changer le sujet et consommer pendant l'exécution du programme ? L'utilisateur peut-il consommer le sujet modifié ?
ans : Après avoir essayé, cette exigence ne peut pas être satisfaite à l'aide de l'annotation @KafkaListener. Lorsque le programme démarre, le programme initialise le. consommateur basé sur les informations d'annotation @KafkaListener pour consommer le sujet spécifié. Si le sujet est modifié pendant l'exécution du programme, le consommateur ne sera pas autorisé à modifier la configuration du consommateur, puis à se réabonner au sujet.
Mais nous pouvons avoir un compromis, qui consiste à utiliser le paramètre topicPattern de @KafkaListener pour la correspondance de sujet.
Méthode ultime
Idée
Utilisez la dépendance client native de Kafka, initialisez manuellement les consommateurs et démarrez les threads consommateurs au lieu d'utiliser @KafkaListener.
Dans le fil de discussion consommateur, chaque cycle obtient les dernières informations sur le sujet à partir de la configuration, de la base de données ou d'autres sources de configuration, les compare avec le sujet précédent et, si des changements se produisent, se réabonne au sujet ou initialise le consommateur.
Implémentation
Ajouter une dépendance client Kafka (ce serveur de test version Kafka : 2.12-2.4.0)
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.3.0</version> </dependency>
code
@Service
@Slf4j
public class KafkaConsumers implements InitializingBean {
/**
* 消费者
*/
private static KafkaConsumer<String, String> consumer;
/**
* topic
*/
private List<String> topicList;
public static String getNewTopic() {
try {
return org.apache.commons.io.FileUtils.readLines(new File("D:/topic.txt"), "utf-8").get(0);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 初始化消费者(配置写死是为了快速测试,请大家使用配置文件)
*
* @param topicList
* @return
*/
public KafkaConsumer<String, String> getInitConsumer(List<String> topicList) {
//配置信息
Properties props = new Properties();
//kafka服务器地址
props.put("bootstrap.servers", "192.168.9.185:9092");
//必须指定消费者组
props.put("group.id", "haha");
//设置数据key和value的序列化处理类
props.put("key.deserializer", StringDeserializer.class);
props.put("value.deserializer", StringDeserializer.class);
//创建消息者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅topic的消息
consumer.subscribe(topicList);
return consumer;
}
/**
* 开启消费者线程
* 异常请自己根据需求自己处理
*/
@Override
public void afterPropertiesSet() {
// 初始化topic
topicList = Splitter.on(",").splitToList(Objects.requireNonNull(getNewTopic()));
if (org.apache.commons.collections.CollectionUtils.isNotEmpty(topicList)) {
consumer = getInitConsumer(topicList);
// 开启一个消费者线程
new Thread(() -> {
while (true) {
// 模拟从配置源中获取最新的topic(字符串,逗号隔开)
final List<String> newTopic = Splitter.on(",").splitToList(Objects.requireNonNull(getNewTopic()));
// 如果topic发生变化
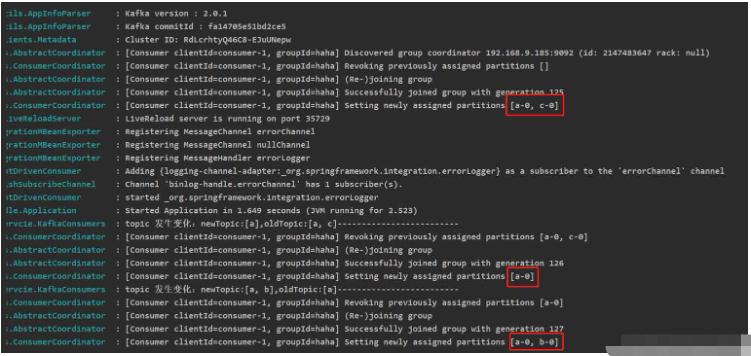
if (!topicList.equals(newTopic)) {
log.info("topic 发生变化:newTopic:{},oldTopic:{}-------------------------", newTopic, topicList);
// method one:重新订阅topic:
topicList = newTopic;
consumer.subscribe(newTopic);
// method two:关闭原来的消费者,重新初始化一个消费者
//consumer.close();
//topicList = newTopic;
//consumer = getInitConsumer(newTopic);
continue;
}
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("key:" + record.key() + "" + ",value:" + record.value());
}
}
}).start();
}
}
}Parlons de la 72ème ligne de code :
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
La ligne de code ci-dessus signifie : en 100 ms Attendez que le courtier de Kafka renvoie les données. Le paramètre supermarché spécifie combien de temps après le retour du sondage, que des données soient disponibles ou non.
Après avoir modifié le sujet, vous devez attendre que les messages extraits de ce sondage soient traités, et détecter les changements dans le sujet pendant la boucle while (true) avant de pouvoir vous réabonner au sujet. Le nombre par défaut de messages obtenus par. la méthode poll() à la fois est la suivante : 500, comme indiqué ci-dessous, est défini dans le code source du client kafka.
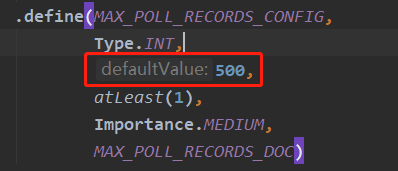 Si vous souhaitez personnaliser cette configuration, vous pouvez ajouter les
Si vous souhaitez personnaliser cette configuration, vous pouvez ajouter les
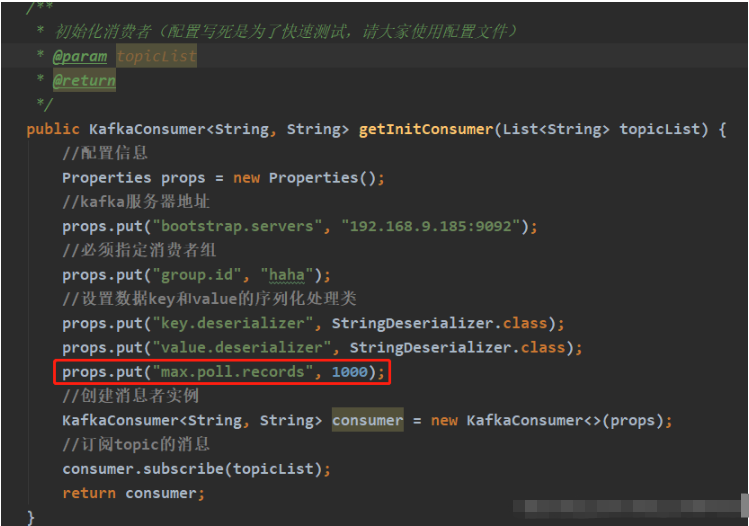 résultats d'exécution lors de l'initialisation du consommateur (il n'y a aucune donnée dans le sujet testé)
résultats d'exécution lors de l'initialisation du consommateur (il n'y a aucune donnée dans le sujet testé)
 Remarque : KafkaConsumer n'est pas sécurisé pour les threads , n'utilisez pas une seule instance de KafkaConsumer pour ouvrir plusieurs consommateurs. Pour ouvrir plusieurs consommateurs, vous devez créer plusieurs nouvelles instances de KafkaConsumer.
Remarque : KafkaConsumer n'est pas sécurisé pour les threads , n'utilisez pas une seule instance de KafkaConsumer pour ouvrir plusieurs consommateurs. Pour ouvrir plusieurs consommateurs, vous devez créer plusieurs nouvelles instances de KafkaConsumer.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment mettre en œuvre une analyse boursière en temps réel à l'aide de PHP et Kafka
Jun 28, 2023 am 10:04 AM
Comment mettre en œuvre une analyse boursière en temps réel à l'aide de PHP et Kafka
Jun 28, 2023 am 10:04 AM
Avec le développement d’Internet et de la technologie, l’investissement numérique est devenu un sujet de préoccupation croissant. De nombreux investisseurs continuent d’explorer et d’étudier des stratégies d’investissement, dans l’espoir d’obtenir un retour sur investissement plus élevé. Dans le domaine du trading d'actions, l'analyse boursière en temps réel est très importante pour la prise de décision, et l'utilisation de la file d'attente de messages en temps réel Kafka et de la technologie PHP constitue un moyen efficace et pratique. 1. Introduction à Kafka Kafka est un système de messagerie distribué de publication et d'abonnement à haut débit développé par LinkedIn. Les principales fonctionnalités de Kafka sont
 Comparaison et analyse des différences entre SpringBoot et SpringMVC
Dec 29, 2023 am 11:02 AM
Comparaison et analyse des différences entre SpringBoot et SpringMVC
Dec 29, 2023 am 11:02 AM
SpringBoot et SpringMVC sont tous deux des frameworks couramment utilisés dans le développement Java, mais il existe des différences évidentes entre eux. Cet article explorera les fonctionnalités et les utilisations de ces deux frameworks et comparera leurs différences. Tout d’abord, découvrons SpringBoot. SpringBoot a été développé par l'équipe Pivotal pour simplifier la création et le déploiement d'applications basées sur le framework Spring. Il fournit un moyen rapide et léger de créer des fichiers exécutables autonomes.
 Tutoriel pratique de développement SpringBoot+Dubbo+Nacos
Aug 15, 2023 pm 04:49 PM
Tutoriel pratique de développement SpringBoot+Dubbo+Nacos
Aug 15, 2023 pm 04:49 PM
Cet article écrira un exemple détaillé pour parler du développement réel de dubbo+nacos+Spring Boot. Cet article ne couvrira pas trop de connaissances théoriques, mais écrira l'exemple le plus simple pour illustrer comment dubbo peut être intégré à nacos pour créer rapidement un environnement de développement.
 Comment créer des applications de traitement de données en temps réel à l'aide de React et Apache Kafka
Sep 27, 2023 pm 02:25 PM
Comment créer des applications de traitement de données en temps réel à l'aide de React et Apache Kafka
Sep 27, 2023 pm 02:25 PM
Comment utiliser React et Apache Kafka pour créer des applications de traitement de données en temps réel Introduction : Avec l'essor du Big Data et du traitement de données en temps réel, la création d'applications de traitement de données en temps réel est devenue la priorité de nombreux développeurs. La combinaison de React, un framework front-end populaire, et d'Apache Kafka, un système de messagerie distribué hautes performances, peut nous aider à créer des applications de traitement de données en temps réel. Cet article expliquera comment utiliser React et Apache Kafka pour créer des applications de traitement de données en temps réel, et
 Cinq sélections d'outils de visualisation pour explorer Kafka
Feb 01, 2024 am 08:03 AM
Cinq sélections d'outils de visualisation pour explorer Kafka
Feb 01, 2024 am 08:03 AM
Cinq options pour les outils de visualisation Kafka ApacheKafka est une plateforme de traitement de flux distribué capable de traiter de grandes quantités de données en temps réel. Il est largement utilisé pour créer des pipelines de données en temps réel, des files d'attente de messages et des applications basées sur des événements. Les outils de visualisation de Kafka peuvent aider les utilisateurs à surveiller et gérer les clusters Kafka et à mieux comprendre les flux de données Kafka. Ce qui suit est une introduction à cinq outils de visualisation Kafka populaires : ConfluentControlCenterConfluent
 Analyse comparative des outils de visualisation kafka : Comment choisir l'outil le plus approprié ?
Jan 05, 2024 pm 12:15 PM
Analyse comparative des outils de visualisation kafka : Comment choisir l'outil le plus approprié ?
Jan 05, 2024 pm 12:15 PM
Comment choisir le bon outil de visualisation Kafka ? Analyse comparative de cinq outils Introduction : Kafka est un système de file d'attente de messages distribué à haute performance et à haut débit, largement utilisé dans le domaine du Big Data. Avec la popularité de Kafka, de plus en plus d'entreprises et de développeurs ont besoin d'un outil visuel pour surveiller et gérer facilement les clusters Kafka. Cet article présentera cinq outils de visualisation Kafka couramment utilisés et comparera leurs caractéristiques et fonctions pour aider les lecteurs à choisir l'outil qui répond à leurs besoins. 1. KafkaManager
 Comment installer Apache Kafka sur Rocky Linux ?
Mar 01, 2024 pm 10:37 PM
Comment installer Apache Kafka sur Rocky Linux ?
Mar 01, 2024 pm 10:37 PM
Pour installer ApacheKafka sur RockyLinux, vous pouvez suivre les étapes suivantes : Mettre à jour le système : Tout d'abord, assurez-vous que votre système RockyLinux est à jour, exécutez la commande suivante pour mettre à jour les packages système : sudoyumupdate Installer Java : ApacheKafka dépend de Java, vous vous devez d'abord installer JavaDevelopmentKit (JDK). OpenJDK peut être installé via la commande suivante : sudoyuminstalljava-1.8.0-openjdk-devel Télécharger et décompresser : Visitez le site officiel d'ApacheKafka () pour télécharger le dernier package binaire. Choisissez une version stable
 La pratique du go-zero et Kafka+Avro : construire un système de traitement de données interactif performant
Jun 23, 2023 am 09:04 AM
La pratique du go-zero et Kafka+Avro : construire un système de traitement de données interactif performant
Jun 23, 2023 am 09:04 AM
Ces dernières années, avec l'essor du Big Data et des communautés open source actives, de plus en plus d'entreprises ont commencé à rechercher des systèmes de traitement de données interactifs hautes performances pour répondre aux besoins croissants en matière de données. Dans cette vague de mises à niveau technologiques, le go-zero et Kafka+Avro suscitent l’attention et sont adoptés par de plus en plus d’entreprises. go-zero est un framework de microservices développé sur la base du langage Golang. Il présente les caractéristiques de hautes performances, de facilité d'utilisation, d'extension facile et de maintenance facile. Il est conçu pour aider les entreprises à créer rapidement des systèmes d'applications de microservices efficaces. sa croissance rapide
