
 Périphériques technologiques
IA
Prévisions de séries chronologiques multivariées : prévision indépendante ou prévision conjointe ?
Périphériques technologiques
IA
Prévisions de séries chronologiques multivariées : prévision indépendante ou prévision conjointe ?
Prévisions de séries chronologiques multivariées : prévision indépendante ou prévision conjointe ?

Aujourd'hui, je vous présente un article publié par NTU en avril de cette année. Il traite principalement des différences dans les effets de la prédiction indépendante (indépendante du canal) et de la prédiction conjointe (dépendante du canal) dans les problèmes de prédiction de séries chronologiques multivariées, ainsi que des raisons qui les sous-tendent. , et leur méthode d'optimisation.

Titre de l'article : Le compromis entre capacité et robustesse : revisiter la stratégie indépendante des canaux pour la prévision de séries chronologiques multivariées# 🎜🎜#
Adresse de téléchargement : https://arxiv.org/pdf/2304.05206v1.pdf1 Prévisions indépendantes et prévisions conjointesSéries chronologiques multiples. Dans les problèmes de prévision, il existe deux types du point de vue des méthodes de modélisation multivariées. L'un est la prévision indépendante du canal (indépendant du canal, CI), qui fait référence au traitement des séquences multivariées comme plusieurs prévisions univariées, et l'autre est modélisée séparément. est une prédiction conjointe (dépendante du canal, CD), qui fait référence à la modélisation de plusieurs variables ensemble et à la prise en compte de la relation entre chaque variable. La différence entre les deux est indiquée ci-dessous.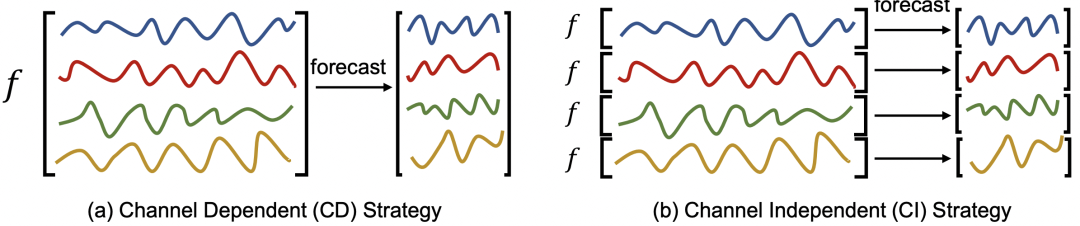
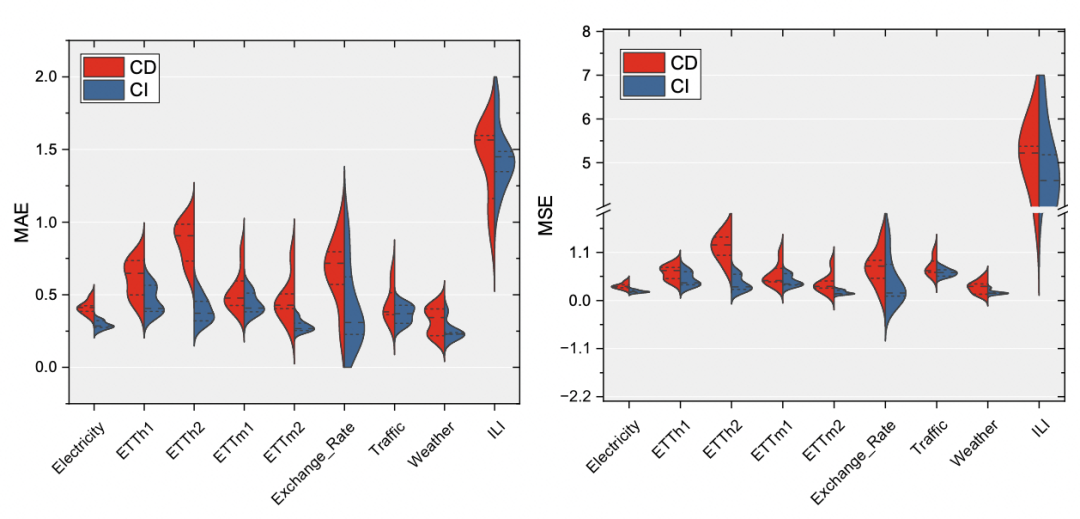
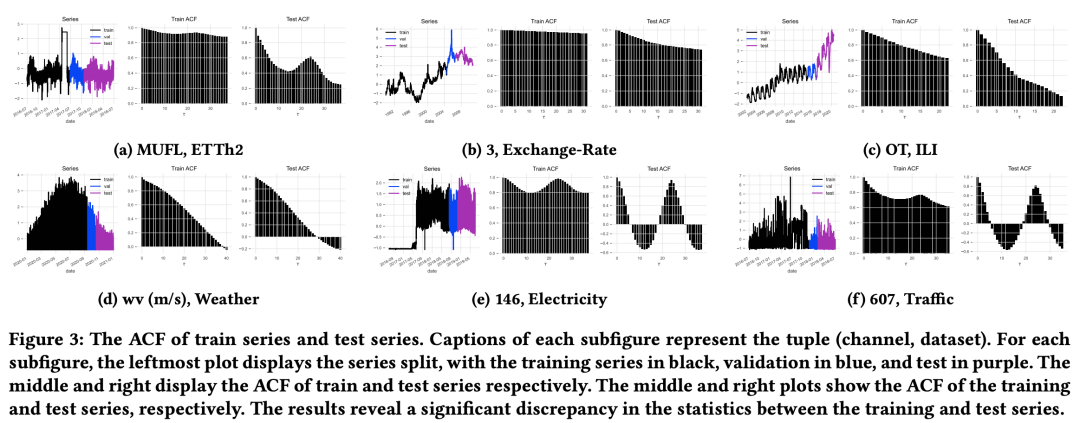
Longueur de la séquence historique d'entrée : pour le modèle CD, plus la séquence historique d'entrée est longue, l'effet peut être réduit. Cela est également dû au fait que plus la séquence historique est longue, plus. le modèle est sensible à l'influence du changement de distribution. Pour le modèle CI, l'augmentation de la longueur de la séquence historique peut améliorer de manière plus stable l'effet de prédiction. 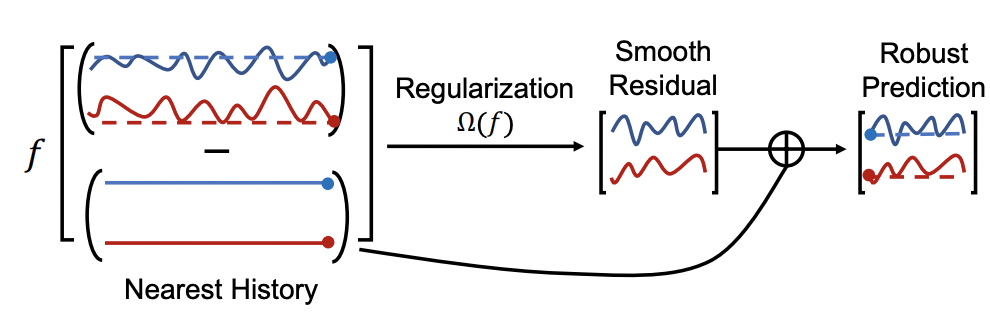
4. Résultats expérimentaux
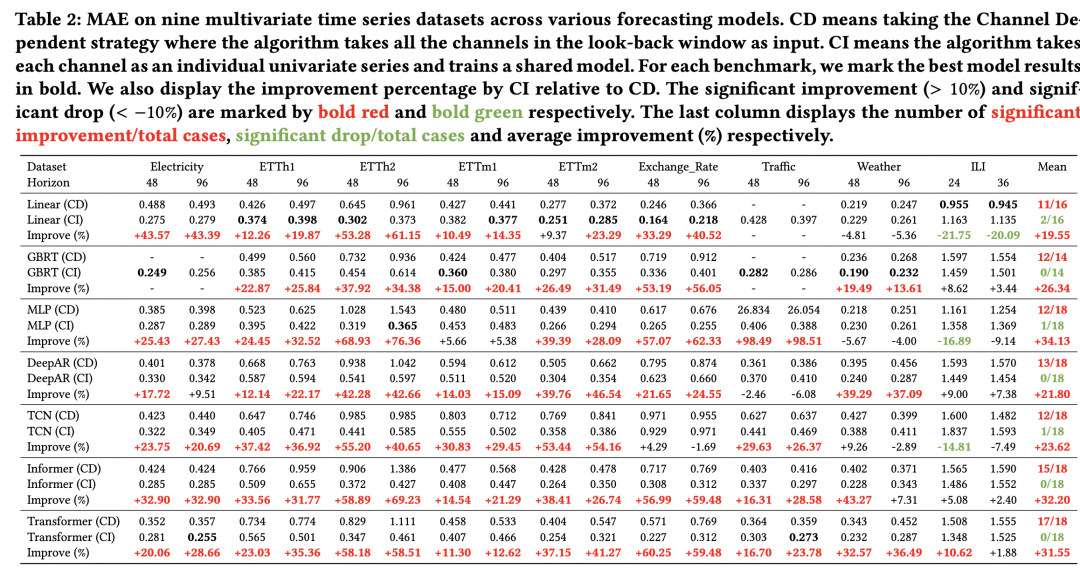
La méthode mentionnée ci-dessus pour améliorer le modèle CD a été testée sur plusieurs ensembles de données. Par rapport au CD, une amélioration de l'effet relativement stable a été obtenue, indiquant que la méthode ci-dessus est relativement efficace pour améliorer la robustesse du multivarié. prédiction de séquence. Les résultats expérimentaux montrent que des facteurs tels que la décomposition de bas rang, la longueur historique de la fenêtre et le type de fonction de perte sont également répertoriés dans l'article en termes d'influence sur l'effet.
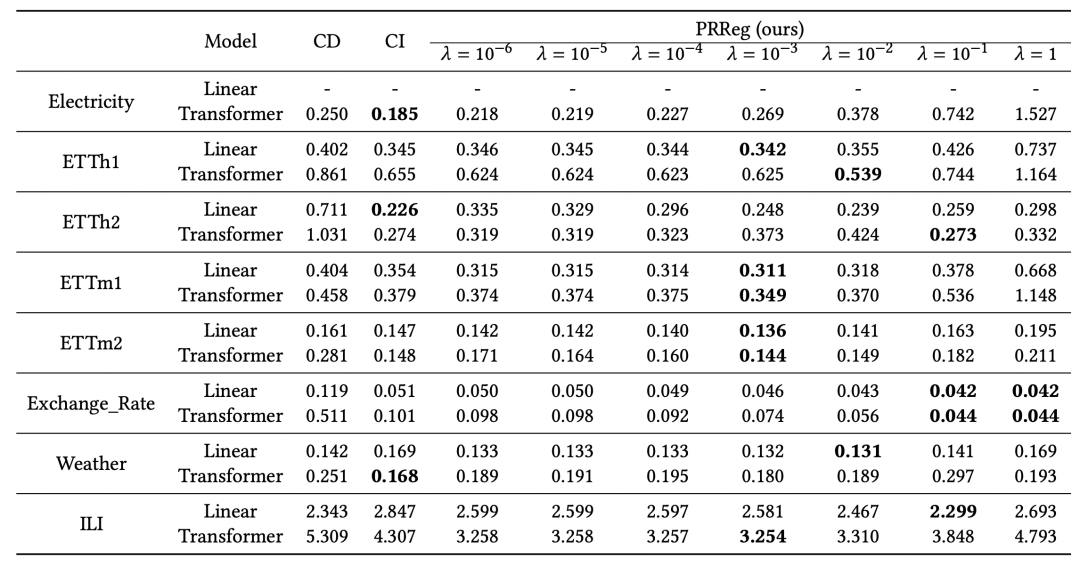
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 J'ai essayé le codage d'ambiance avec Cursor Ai et c'est incroyable!
Mar 20, 2025 pm 03:34 PM
J'ai essayé le codage d'ambiance avec Cursor Ai et c'est incroyable!
Mar 20, 2025 pm 03:34 PM
Le codage des ambiances est de remodeler le monde du développement de logiciels en nous permettant de créer des applications en utilisant le langage naturel au lieu de lignes de code sans fin. Inspirée par des visionnaires comme Andrej Karpathy, cette approche innovante permet de dev
 Top 5 Genai Lunets de février 2025: GPT-4.5, Grok-3 et plus!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Lunets de février 2025: GPT-4.5, Grok-3 et plus!
Mar 22, 2025 am 10:58 AM
Février 2025 a été un autre mois qui change la donne pour une IA générative, nous apportant certaines des mises à niveau des modèles les plus attendues et de nouvelles fonctionnalités révolutionnaires. De Xai's Grok 3 et Anthropic's Claude 3.7 Sonnet, à Openai's G
 Comment utiliser YOLO V12 pour la détection d'objets?
Mar 22, 2025 am 11:07 AM
Comment utiliser YOLO V12 pour la détection d'objets?
Mar 22, 2025 am 11:07 AM
Yolo (vous ne regardez qu'une seule fois) a été un cadre de détection d'objets en temps réel de premier plan, chaque itération améliorant les versions précédentes. La dernière version Yolo V12 introduit des progrès qui améliorent considérablement la précision
 Chatgpt 4 o est-il disponible?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 o est-il disponible?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 est actuellement disponible et largement utilisé, démontrant des améliorations significatives dans la compréhension du contexte et la génération de réponses cohérentes par rapport à ses prédécesseurs comme Chatgpt 3.5. Les développements futurs peuvent inclure un interg plus personnalisé
 Google & # 039; s Gencast: Prévision météorologique avec Mini démo Gencast
Mar 16, 2025 pm 01:46 PM
Google & # 039; s Gencast: Prévision météorologique avec Mini démo Gencast
Mar 16, 2025 pm 01:46 PM
Gencast de Google Deepmind: une IA révolutionnaire pour les prévisions météorologiques Les prévisions météorologiques ont subi une transformation spectaculaire, passant des observations rudimentaires aux prédictions sophistiquées alimentées par l'IA. Gencast de Google Deepmind, un terreau
 Quelle IA est la meilleure que Chatgpt?
Mar 18, 2025 pm 06:05 PM
Quelle IA est la meilleure que Chatgpt?
Mar 18, 2025 pm 06:05 PM
L'article traite des modèles d'IA dépassant Chatgpt, comme Lamda, Llama et Grok, mettant en évidence leurs avantages en matière de précision, de compréhension et d'impact de l'industrie. (159 caractères)
 O1 vs GPT-4O: le nouveau modèle Openai est-il meilleur que GPT-4O?
Mar 16, 2025 am 11:47 AM
O1 vs GPT-4O: le nouveau modèle Openai est-il meilleur que GPT-4O?
Mar 16, 2025 am 11:47 AM
O1'S O1: Une vague de cadeaux de 12 jours commence par leur modèle le plus puissant à ce jour L'arrivée de décembre apporte un ralentissement mondial, les flocons de neige dans certaines parties du monde, mais Openai ne fait que commencer. Sam Altman et son équipe lancent un cadeau de don de 12 jours
 Comment utiliser Mistral OCR pour votre prochain modèle de chiffon
Mar 21, 2025 am 11:11 AM
Comment utiliser Mistral OCR pour votre prochain modèle de chiffon
Mar 21, 2025 am 11:11 AM
Mistral OCR: révolutionner la génération de la récupération avec une compréhension du document multimodal Les systèmes de génération (RAG) (RAG) de la récupération ont considérablement avancé les capacités d'IA, permettant à de vastes magasins de données pour une responsabilité plus éclairée
