
 Périphériques technologiques
IA
Le coût de la formation est inférieur à 1 000 yuans, soit une réduction de 90 % ! NUS et l'Université Tsinghua lancent VPGTrans : personnalisez facilement de grands modèles multimodaux de type GPT-4
Périphériques technologiques
IA
Le coût de la formation est inférieur à 1 000 yuans, soit une réduction de 90 % ! NUS et l'Université Tsinghua lancent VPGTrans : personnalisez facilement de grands modèles multimodaux de type GPT-4
Le coût de la formation est inférieur à 1 000 yuans, soit une réduction de 90 % ! NUS et l'Université Tsinghua lancent VPGTrans : personnalisez facilement de grands modèles multimodaux de type GPT-4

Cette année est l'année du développement explosif de la technologie de l'IA, avec la popularité croissante des grands modèles de langage (LLM) représentés par ChatGPT.
En plus de montrer un grand potentiel dans le domaine du langage naturel, les modèles de langage ont également commencé à rayonner progressivement vers d'autres modalités. Par exemple, le modèle de graphe vincentien Stable Diffusion nécessite également un modèle de langage.
Former un modèle de langage visuel (VL-LLM) à partir de zéro nécessite souvent beaucoup de ressources, les solutions existantes consistent donc à connecter le modèle de langage et le modèle de génération d'invites visuelles (Visual Prompt Generator, VPG). ainsi, continuer à régler VPG nécessite toujours des milliers d’heures GPU et des millions de données d’entraînement.
Récemment, des chercheurs de l'Université nationale de Singapour et de l'Université Tsinghua ont proposé une solution, VPGTrans, pour migrer le VPG existant vers le modèle VL-LLM existant afin d'obtenir le modèle LLM cible de manière peu coûteuse.

Lien papier : https://arxiv.org/abs/2305.01278
Lien code : https://github.com/VPGTrans/VPGTrans
Démo du modèle de dialogue multimodal : https://vpgtrans.github.io/
Auteurs : Zhang Ao, Fei Hao, Yao Yuan, Ji Wei, Li Li, Liu Zhiyuan, Chua Tat-Seng
Unité : Université nationale de Singapour, Université Tsinghua
Les principaux points d'innovation de l'article comprennent :
1 Coût de formation extrêmement faible :
Grâce à notre méthode VPGTrans proposée, il peut être rapide (moins de 10 % du temps de formation) Migrez le module visuel du modèle de dialogue multimodal existant vers le nouveau modèle de langage et obtenez des résultats similaires ou meilleurs.
Par exemple, par rapport à la formation du module de vision à partir de zéro, nous pouvons réduire le coût de formation du BLIP-2 FlanT5-XXL de 19 000+ RMB à moins de 1 000 RMB :
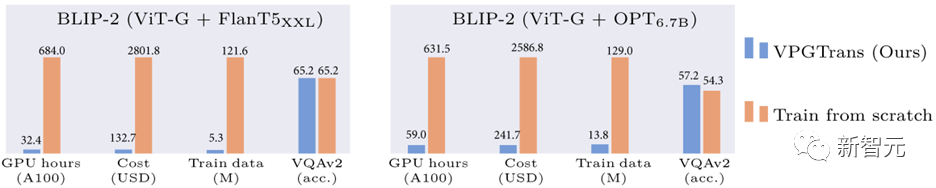
Image 1 : Comparaison de la réduction des frais généraux de formation BLIP-2 basée sur notre méthode VPGTrans
2 Personnalisation multimodale de grands modèles :
Grâce à notre framework VPGTrans, divers nouveaux modèles peuvent être personnalisés en fonction. aux besoins Les grands modèles de langage peuvent ajouter des modules visuels de manière flexible. Par exemple, nous avons produit VL-LLaMA et VL-Vicuna basés sur LLaMA-7B et Vicuna-7B.
3. Modèle de dialogue multimodal open source :
Nous open source VL-Vicuna, un modèle de dialogue multimodal de type GPT-4, qui peut atteindre des niveaux élevés de dialogue. multimodalité de qualité Dialogue :
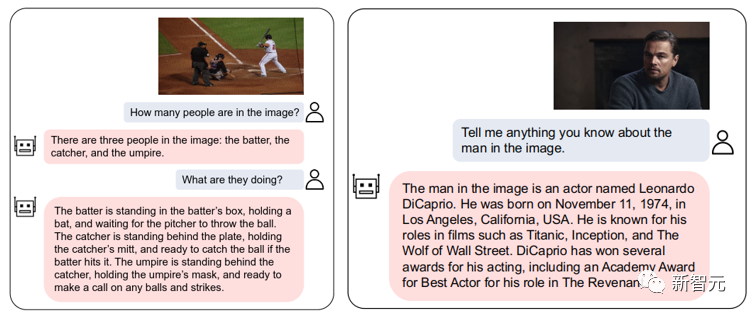
Figure 2 : Exemple d'interaction VL-Vicuna
1. Introduction à la motivation1.1 Contexte
LLM a déclenché un tendance dans le domaine de la compréhension multimodale. Transformation du modèle de langage visuel (VLM) traditionnel pré-entraîné en modèle de langage visuel basé sur un grand modèle de langage (VL-LLM).
En connectant le module visuel au LLM, VL-LLM peut hériter des connaissances, de la capacité de généralisation sans échantillon, de la capacité de raisonnement et de la capacité de planification du LLM existant. Les modèles associés incluent BLIP-2[1], Flamingo[2], PALM-E, etc.

Figure 3 : Architecture VL-LLM couramment utilisée# 🎜🎜#
Le VL-LLM existant couramment utilisé adopte essentiellement l'architecture présentée dans la figure 3 : formation d'un module de génération d'invites visuelles logicielles basé sur un LLM de base (Visual Prompt Générateur, VPG) et une couche linéaire (Projecteur) qui effectue une transformation dimensionnelle.
En termes d'échelle de paramètres, LLM représente généralement la partie principale (comme 11B) , et VPG représente la partie mineure (comme 1,2B), le projecteur est le plus petit (4M).
Pendant le processus de formation, Les paramètres LLM ne sont généralement pas mis à jour , ou seulement un très petit nombre de paramètres sont mis à jour. Les paramètres entraînables proviennent principalement du VPG et du projecteur.
1.2 Motivation
En fait, même si les paramètres du LLM de base sont figés et non entraînés , en raison du LLM En raison de la grande quantité de paramètres, le coût clé de la formation d'un VL-LLM réside toujours dans le chargement du LLM de base.
Par conséquent, la formation d'un VL-LLM ne peut toujours pas éviter d'énormes coûts de calcul. Par exemple, pour obtenir BLIP-2 (le LLM de base est FlanT5-XXL), plus de 600 heures de formation A100 sont nécessaires. Si vous louez la machine A100-40G d'Amazon, cela vous coûtera près de 20 000 yuans.
Comme former un VPG à partir de zéro coûte si cher, nous avons commencé à réfléchir à Pouvons-nous migrer un VPG existant vers un nouveau LLM#🎜 🎜# pour économiser de l'argent. Figure 4 : Migration VPG : migration entre les tailles de LLM et migration de types entre LLM de VPG : #🎜🎜 # (1) Migration de taille Cross-LLM (TaS) : par exemple de OPT-2.7B à OPT-6.7B.
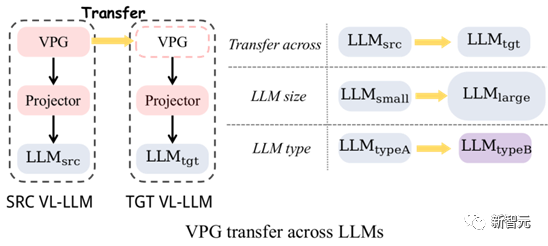 (2) Migration de type Cross-LLM (TaT) : par exemple d'OPT vers FlanT5.
(2) Migration de type Cross-LLM (TaT) : par exemple d'OPT vers FlanT5.
L'importance du TaS est la suivante : dans la recherche scientifique liée au LLM, nous devons généralement ajuster les paramètres d'un petit LLM, puis l'étendre à un grand LLM. Avec TaS, nous pouvons directement migrer le VPG qui a été formé sur le petit LLM vers le grand LLM après avoir ajusté les paramètres.
La signification de TaT est la suivante : des LLM avec différents types fonctionnels émergent à l'infini, comme LLaMA aujourd'hui, Alpaca et Vicuna demain. TaT nous permet d'utiliser les VPG existants pour ajouter rapidement des capacités de perception visuelle à de nouveaux modèles de langage.1.3 Contribution
(1) Proposer des méthodes efficaces : # 🎜🎜#
Nous avons d'abord exploré les facteurs clés qui affectent l'efficacité de la migration VPG à travers une série d'expériences exploratoires. Sur la base des résultats expérimentaux exploratoires, nous proposons un cadre de migration efficace en deux étapes VPGTrans. Ce cadre peut réduire considérablement la surcharge de calcul et les données de formation requises pour former VL-LLM.
Par exemple, par rapport à une formation à partir de zéro, nous ne pouvons
utiliser qu'environ 10 % en migrant VPG de BLIP-2 OPT-2.7B vers 6.7B Les données et le temps de calculpeuvent obtenir des résultats similaires ou meilleurs pour chaque ensemble de données (Figure 1) .
Le coût de la formation varie de 17901 yuans à 1673 yuans.
(2) Faites des découvertes intéressantes :Nous sommes à en même temps Fournit quelques résultats intéressants dans les scénarios TaS et TaT, et essaie de donner des explications :
a) Dans le scénario TaS, l'utilisation de VPGTrans pour migrer de petit à grand n'affectera pas l'effet final du modèle.
b) Dans le scénario TaS, Plus le VPG formé sur le modèle de langage est petit, plus l'efficacité lors de la migration vers le grand modèle est élevée, et mieux c'est l'effet final# 🎜🎜#.
c) Dans le scénario TaT, plus l'écart de migration est petit, plus l'écart entre les modèles est grand. Dans nos expériences de vérification, la migration mutuelle entre OPT350M et FlanT5-base à l'aide de VPGTrans est presque aussi lente qu'une formation à partir de zéro.
(3) Open source :
# 🎜🎜# Nous avons utilisé VPGTrans pour obtenir deux nouveaux VL-LLM : VL-LLaMA et VL-Vicuna, et les avons open source dans la communauté. Parmi eux, VL-Vicuna implémente un dialogue multimodal de haute qualité similaire à GPT4. 2. Solution de migration VPG à haute efficacité : VPGTrans
Tout d'abord, nous menons une série d'expériences d'exploration et de vérification pour analyser comment pour maximiser la valeur de l’efficacité de la migration VPG. Nous proposons ensuite une solution basée sur ces observations importantes.2.1 Expérience d'exploration
Nous choisissons l'architecture BLIP-2 comme modèle de base et pré-formation corpus En utilisant COCO et SBU, un total de 1,4 million de paires d'images et de textes sont utilisées.
Les tâches en aval sont évaluées à l'aide des paramètres zéro-shot de COCO Caption, NoCaps, VQAv2, GQA et OK-VQA (la tâche de sous-titrage n'est pas strictement zéro-shot) . Voici nos principales conclusions :
(1) Hériter directement d'un VPG formé peut accélérer la convergence, mais l'effet est limité : # 🎜🎜# Nous avons constaté que la migration directe d'un VPG formé sur un LLM vers un grand LLM peut accélérer la convergence du modèle, mais l'effet d'accélération est limité et la convergence L'effet final du modèle
diminuera par rapport à l'entraînement VPG à partir de zéro (les points les plus élevés des lignes bleues VQAv2 et GQA sur la figure 5 sont tous deux inférieurs à la ligne orange). Nous pensons que cette baisse est due au fait que le projecteur initialisé aléatoirement endommagera la capacité de perception visuelle existante dans VPG au début de l'entraînement.

(2) Un entraînement d'échauffement avec le projecteur en premier peut empêcher les points de tomber et accélérer davantage la convergence :
#🎜 🎜 #Donc, nous avons réparé le VPG et le LLM, avons d'abord entraîné le projecteur pendant 3 époques, puis dégelé le VPG pour la prochaine étape de l'entraînement.
Nous avons constaté que cela peut non seulement éviter les chutes de points, mais également accélérer davantage la convergence VPG (Figure 6).
Mais il convient de souligner que puisque le coût principal de la formation est le LLM (paramètres énormes),
n'est que le coût du projecteur de formation #🎜 🎜#ne sera pas beaucoup moins cher que formation VPG et projecteur en même temps . Nous avons donc commencé à explorer les technologies clés pour accélérer le préchauffage du projecteur.
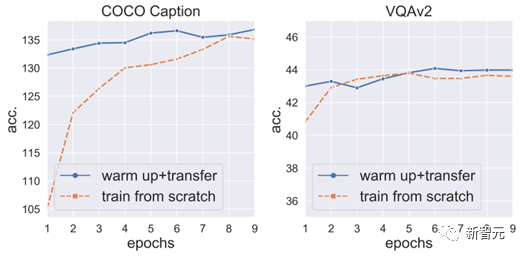 Figure 6 : Le projecteur d'entraînement d'échauffement peut être fait en premier Empêcher les points perdus + accélérer la convergence
Figure 6 : Le projecteur d'entraînement d'échauffement peut être fait en premier Empêcher les points perdus + accélérer la convergence
(3) L'initialisation du convertisseur de vecteurs de mots peut accélérer le préchauffage du projecteur : #🎜🎜 ## 🎜🎜#
Tout d'abord, VPG produit des effets en convertissant les images en invites logicielles que LLM peut comprendre. L'utilisation de soft prompt est en fait très similaire à word vector Ils saisissent tous deux directement le modèle de langage pour inviter le modèle à générer le contenu correspondant. Nous avons donc utilisé des vecteurs de mots comme proxy pour les invites logicielles et formé un convertisseur de vecteurs de mots (une couche linéaire) de
à 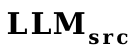
. 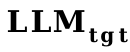
Ensuite, nous fusionnons le convertisseur de vecteur de mots et le projecteur sur
comme initialisation du projecteur. 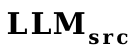
(4) Le projecteur peut converger rapidement à un taux d'apprentissage très élevé :
Nous avons approfondi nos expériences et constaté que le projecteur peut être entraîné avec un taux d'apprentissage 5 fois supérieur à la normale sans planter en raison de son petit nombre de paramètres. .
Grâce à un entraînement avec un taux d'apprentissage 5 fois supérieur, l'échauffement du projecteur peut être encore raccourci à 1 époque
.(5) Un constat supplémentaire :
Bien que l'échauffement du projecteur soit important, la formation du projecteur à elle seule ne suffit pas. Surtout pour la tâche de sous-titrage, l'effet de l'entraînement du projecteur seul est pire que celui de l'entraînement du VPG en même temps (la ligne verte de la figure 5 est bien inférieure à la ligne bleue dans COCO Caption et NoCaps).
Cela signifie également que la simple formation du projecteur entraînera un sous-ajustement
, c'est-à-dire quene pourra pas être entièrement aligné sur les données d'entraînement. 2.2 Notre méthode proposée
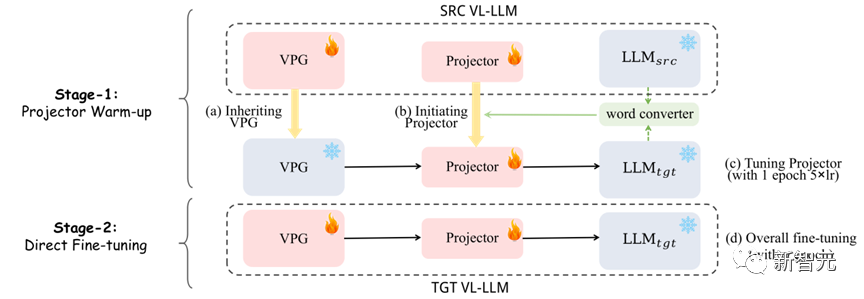
Comme le montre la figure 7, notre méthode est divisée en deux étapes :
(1) La première étape : Nous utilisons d'abord le convertisseur de vecteur de mots pour fusionner avec le projecteur d'origine comme initialisation du nouveau projecteur, puis utilisons Le nouveau projecteur est entraîné avec un taux d'apprentissage 5 fois supérieur pour une époque.
(2) La deuxième étape : entraîner directement VPG et projecteur normalement.
3. Résultats expérimentaux
3.1 Ratio d'accélération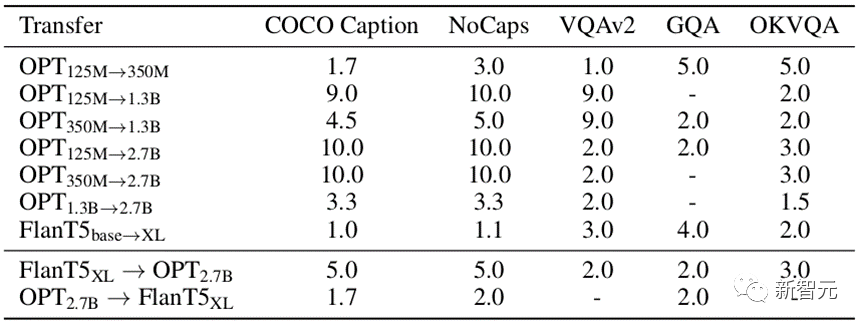
Comme le montre le tableau 1, nous avons testé le taux d'accélération de VPGTrans sur différents ensembles de données sous différents types de migration.
Le taux d'accélération de VPGTrans sur un ensemble de données spécifié A est obtenu en divisant le nombre de cycles d'entraînement à partir de zéro pour obtenir le meilleur effet a sur A par le nombre minimum de cycles d'entraînement où l'effet de VPGTrans sur A dépasse a.
Par exemple, entraîner VPG sur OPT-2.7B à partir de zéro nécessite 10 époques pour obtenir les meilleurs résultats dans la légende COCO, mais la migration de VPG de OPT-125M vers OPT-2.7B ne prend qu'une seule époque pour obtenir les meilleurs résultats. . Le rapport d'accélération est de 10/1 = 10 fois.
Nous pouvons voir que notre VPGTrans peut atteindre une accélération stabledans les scénarios TaS et TaT.
3.2 Découvertes intéressantes
Nous avons sélectionné l'une des découvertes les plus intéressantes à expliquer. Pour des découvertes plus intéressantes, veuillez vous référer à notre article.
Dans le scénario TaS, plus le VPG formé sur le modèle de langage est petit, plus l'efficacité de la migration est élevée et meilleur est l'effet de modèle final. En nous référant au tableau 1, nous pouvons constater que le rapport d'accélération de l'OPT-1.3B à l'OPT-2.7B est bien inférieur au rapport d'accélération de l'OPT-125M et de l'OPT-350M à l'OPT-2.7b.
Nous avons essayé de fournir une explication : Généralement, plus le modèle de langage est grand, en raison de la dimensionnalité plus élevée de son espace de texte, sera plus susceptible d'endommager le VPG (VPG est généralement un modèle pré-entraîné similaire à CLIP) Propre capacité de perception visuelle . Nous l'avons vérifié d'une manière similaire au sondage linéaire :
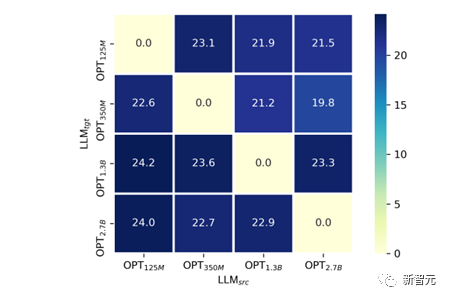
Figure 8 : Transfert de taille Cross-LLM de la seule couche de projecteur linéaire d'entraînement (sondage linéaire simulé)
Comme le montre la figure 8 , nous avons effectué une migration sur des tailles LLM comprises entre OPT-125M, 350M, 1,3B, 2,7B.
Dans l'expérience, Afin de comparer équitablement les capacités de perception visuelle du VPG formé sous différentes tailles de modèle, nous avons fixé les paramètres du VPG et formé uniquement la couche de projecteur linéaire. Nous avons sélectionné l'indicateur SPICE sur COCO Caption comme mesure de la capacité de perception visuelle.
Il n'est pas difficile de constater que pour chaque 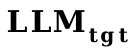 donné, c'est presque cohérent avec le phénomène selon lequel plus le
donné, c'est presque cohérent avec le phénomène selon lequel plus le 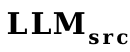 est petit, plus l'ÉPICE finale est élevée.
est petit, plus l'ÉPICE finale est élevée.
3.3 Expériences à grande échelle
Les expériences précédentes visent principalement à vérifier la conjecture dans des scénarios à petite échelle. Afin de prouver l'efficacité de notre méthode, nous avons simulé le processus de pré-entraînement de BLIP-2 et mené des expériences à grande échelle :
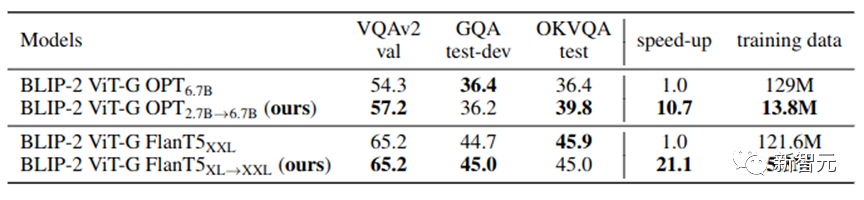
Tableau 2 : Résultats expérimentaux à grande échelle dans des scénarios réels
Comme le montre le tableau 2, notre VPGTrans est toujours efficace dans des scénarios à grande échelle. En migrant d'OPT-2.7B vers OPT-6.7B, nous n'avons utilisé que 10,8 % des données et moins de 10 % du temps de formation pour obtenir des résultats similaires ou meilleurs.
En particulier, notre méthode permet d'obtenir un 4,7% de contrôle des coûts de formation en BLIP-2 VL-LLM basé sur FlanT5-XXL.
4. Personnalisez vos VL-LLM
Notre VPGTrans peut rapidement ajouter des modules de perception visuelle à tout nouveau LLM, obtenant ainsi un tout nouveau VL-LLM de haute qualité. Dans ce travail, nous formons en outre un VL-LLaMA et un VL-Vicuna. L'effet de VL-LLaMA est le suivant :
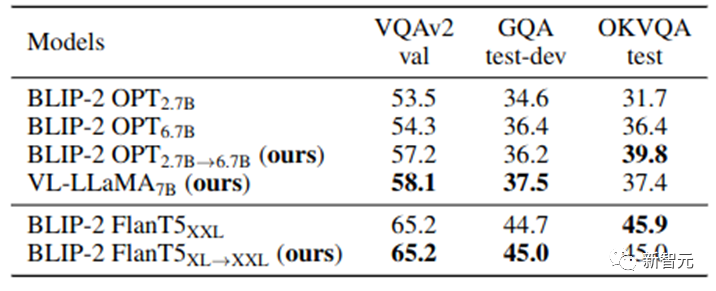
Tableau 3 : Affichage des effets de VL-LLaMA
En même temps, notre VL-Vicuna peut mener des conversations multimodales similaires à GPT-4. Nous avons fait une comparaison simple avec MiniGPT-4 :
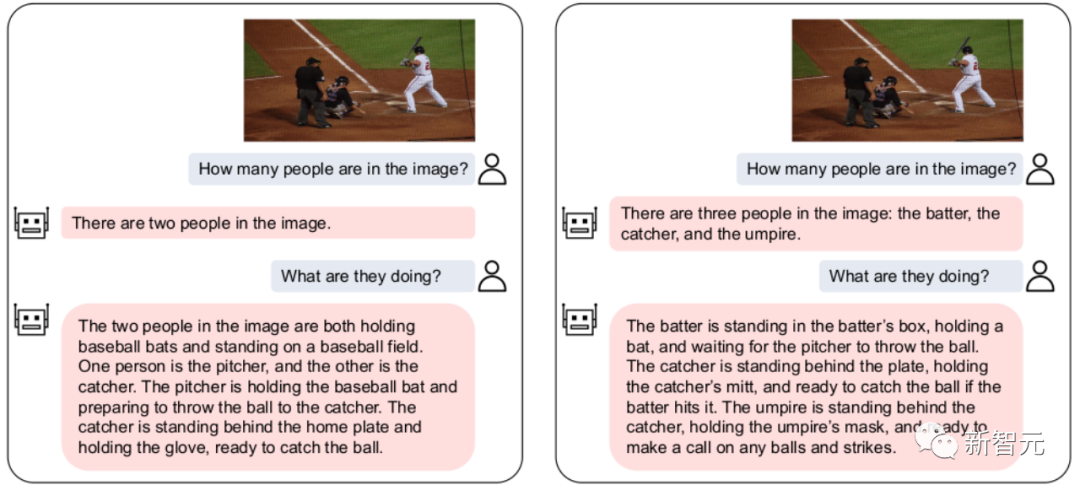
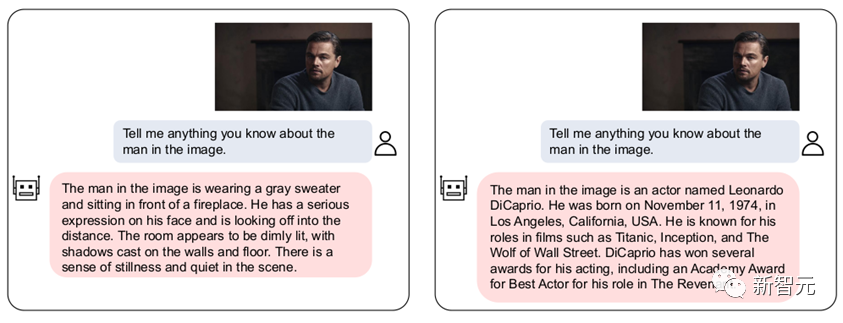
5. Résumé
Dans ce travail, nous avons mené une recherche sur le problème de migration des VPG entre LLM Enquête complète. Nous explorons d’abord les facteurs clés qui maximisent l’efficacité de la migration.
Sur la base d'observations clés, nous proposons un nouveau cadre de migration en deux étapes, à savoir VPGTrans. Il peut atteindre des performances équivalentes ou supérieures tout en réduisant considérablement les coûts de formation.
Grâce à VPGTrans, nous avons réalisé la migration VPG de BLIP-2 OPT 2.7B vers BLIP-2 OPT 6.7B. Par rapport à la connexion de VPG à OPT 6.7B à partir de zéro, VPGTrans ne nécessite que 10,7 % des données de formation et moins de 10 % du temps de formation.
De plus, nous présentons et discutons une série de découvertes intéressantes et les raisons possibles qui les sous-tendent. Enfin, nous démontrons la valeur pratique de notre VPGTrans dans la personnalisation du nouveau VL-LLM en formant VL-LLaMA et LL-Vicuna.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
Le DALL-E 3 a été officiellement introduit en septembre 2023 en tant que modèle considérablement amélioré par rapport à son prédécesseur. Il est considéré comme l’un des meilleurs générateurs d’images IA à ce jour, capable de créer des images avec des détails complexes. Cependant, au lancement, c'était exclu
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Le FP8 et la précision de quantification inférieure en virgule flottante ne sont plus le « brevet » du H100 ! Lao Huang voulait que tout le monde utilise INT8/INT4, et l'équipe Microsoft DeepSpeed a commencé à exécuter FP6 sur A100 sans le soutien officiel de NVIDIA. Les résultats des tests montrent que la quantification FP6 de la nouvelle méthode TC-FPx sur A100 est proche ou parfois plus rapide que celle de INT4, et a une précision supérieure à celle de cette dernière. En plus de cela, il existe également une prise en charge de bout en bout des grands modèles, qui ont été open source et intégrés dans des cadres d'inférence d'apprentissage profond tels que DeepSpeed. Ce résultat a également un effet immédiat sur l'accélération des grands modèles : dans ce cadre, en utilisant une seule carte pour exécuter Llama, le débit est 2,65 fois supérieur à celui des cartes doubles. un
 Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Lien du projet écrit devant : https://nianticlabs.github.io/mickey/ Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle. Cet article propose MicKey, un processus de correspondance de points clés capable de prédire les correspondances métriques dans l'espace d'une caméra 3D. En apprenant la correspondance des coordonnées 3D entre les images, nous sommes en mesure de déduire des métriques relatives.
