
 Périphériques technologiques
IA
Comprendre ce qu'est l'apprentissage automatique en un seul article
Périphériques technologiques
IA
Comprendre ce qu'est l'apprentissage automatique en un seul article
Comprendre ce qu'est l'apprentissage automatique en un seul article

Le monde regorge de données : des images, des vidéos, des feuilles de calcul, des fichiers audio et des textes générés par les humains et les ordinateurs inondent Internet, nous noyant dans une mer d'informations.
Traditionnellement, les humains analysent les données pour prendre des décisions plus intelligentes et cherchent à ajuster les systèmes pour contrôler les changements dans les modèles de données. Cependant, à mesure que la quantité d'informations entrantes augmente, notre capacité à les comprendre diminue, nous laissant face au défi suivant :
Comment utiliser toutes ces données pour en tirer un sens de manière automatisée plutôt que manuelle ?
C'est là que l'apprentissage automatique entre en jeu. Cet article présentera :
- Qu'est-ce que l'apprentissage automatique
- Éléments clés des algorithmes d'apprentissage automatique
- Comment fonctionne l'apprentissage automatique
- 6 applications d'apprentissage automatique du monde réel
- Défis et limites de l'apprentissage automatique
Ces prédictions sont faites par des modèles d'apprentissage automatique à partir d'un ensemble de données appelées « données de formation », et elles peuvent conduire à de nouveaux développements technologiques pour améliorer la vie des gens.
一 Qu'est-ce que l'apprentissage automatique
L'apprentissage automatique est un concept qui permet aux ordinateurs d'apprendre automatiquement à partir d'exemples et d'expériences et d'imiter la prise de décision humaine sans être explicitement programmés.
L'apprentissage automatique est une branche de l'intelligence artificielle qui utilise des algorithmes et des techniques statistiques pour apprendre des données et en tirer des modèles et des informations cachées.
Maintenant, explorons plus en profondeur les tenants et les aboutissants de l’apprentissage automatique.
II Éléments clés des algorithmes d'apprentissage automatique
Il existe des dizaines de milliers d'algorithmes d'apprentissage automatique, qui peuvent être regroupés en fonction du style d'apprentissage ou de la nature du problème à résoudre. Mais chaque algorithme d'apprentissage automatique contient les éléments clés suivants :
- Données d'entraînement – font référence au texte, à l'image, à la vidéo ou aux informations de séries chronologiques à partir desquelles le système d'apprentissage automatique doit apprendre. Les données d'entraînement sont souvent étiquetées pour montrer au système ML quelle est la « bonne réponse », comme par exemple des cadres de délimitation autour des visages dans un détecteur de visage ou la performance future des actions dans un prédicteur boursier.
- signifie - il fait référence à la représentation codée d'objets dans les données d'entraînement, tels que des visages représentés par des caractéristiques telles que des « yeux ». Le codage de certains modèles est plus facile que d’autres, et c’est ce qui détermine la sélection du modèle. Par exemple, les réseaux de neurones forment une représentation et en prennent en charge une autre. La plupart des méthodes modernes utilisent des réseaux de neurones.
- Évaluation – Il s'agit de la façon dont nous jugeons ou identifions un modèle par rapport à un autre. Nous l’appelons généralement fonction d’utilité, fonction de perte ou fonction de notation. L'erreur quadratique moyenne (la sortie du modèle par rapport à la sortie des données) ou la vraisemblance (la probabilité estimée du modèle compte tenu des données observées) sont des exemples de différentes fonctions d'évaluation.
- Optimisation - Cela fait référence à la manière de rechercher l'espace représentant le modèle ou d'améliorer les étiquettes dans les données d'entraînement pour obtenir une meilleure évaluation. L'optimisation signifie mettre à jour les paramètres du modèle pour minimiser la valeur de la fonction de perte. Cela aide le modèle à améliorer sa précision plus rapidement.
Ce qui précède est une classification détaillée des quatre composants des algorithmes d'apprentissage automatique.
Caractéristiques des systèmes d'apprentissage automatique
Descriptif : le système collecte des données historiques, les organise, puis les présente d'une manière facile à comprendre.
L'objectif principal est de comprendre ce qui se passe déjà dans l'entreprise plutôt que de tirer des conclusions ou des prédictions à partir de ses résultats. L'analyse descriptive utilise des outils mathématiques et statistiques simples tels que l'arithmétique, les moyennes et les pourcentages plutôt que les calculs complexes requis pour l'analyse prédictive et prescriptive.
L'analyse descriptive analyse et déduit principalement des données historiques, tandis que l'analyse prédictive se concentre sur la prévision et la compréhension de situations futures possibles.
L'analyse des modèles et des tendances des données passées en examinant les données historiques peut prédire ce qui pourrait arriver dans le futur.
L'analyse prescriptive nous dit comment agir, tandis que l'analyse descriptive nous raconte ce qui s'est passé dans le passé. L'analyse prédictive nous indique ce qui est susceptible de se produire dans le futur en tirant les leçons du passé. Mais une fois que nous avons une idée de ce qui pourrait se passer, que devons-nous faire ?
Il s’agit d’une analyse normative. Cela aide le système à utiliser les connaissances passées pour formuler plusieurs recommandations sur les actions qu'une personne peut entreprendre. L'analyse prescriptive peut simuler des scénarios et fournir un chemin vers l'obtention des résultats souhaités.
Trois comment fonctionne l'apprentissage automatique
L'apprentissage des algorithmes de ML peut être divisé en trois parties principales.
Processus de décision
Les modèles d'apprentissage automatique sont conçus pour apprendre des modèles à partir de données et appliquer ces connaissances pour faire des prédictions. La question est : comment le modèle fait-il des prédictions ?
Le processus est très basique : recherchez des modèles à partir des données d'entrée (étiquetées ou non) et appliquez-les pour obtenir un résultat.
Fonction d'erreur
Les modèles d'apprentissage automatique sont conçus pour comparer les prédictions qu'ils font à la vérité terrain. L’objectif est de comprendre si l’on apprend dans la bonne direction. Cela détermine la précision du modèle et suggère comment nous pouvons améliorer la formation du modèle.
Processus d'optimisation du modèle
Le but ultime du modèle est d'améliorer les prédictions, ce qui signifie réduire la différence entre les résultats connus et les estimations correspondantes du modèle.
Le modèle doit mieux s'adapter aux échantillons de données d'entraînement en mettant constamment à jour les poids. L'algorithme fonctionne en boucle, évaluant et optimisant les résultats, mettant à jour les poids, jusqu'à ce qu'une valeur maximale soit obtenue concernant la précision du modèle.
Types de méthodes d'apprentissage automatique
L'apprentissage automatique comprend principalement quatre types.
1. Apprentissage automatique supervisé
Dans l'apprentissage supervisé, comme son nom l'indique, la machine apprend sous guidage.
Cela se fait en fournissant à l'ordinateur un ensemble de données étiquetées afin que la machine comprenne quelle est l'entrée et quelle devrait être la sortie. Ici, les humains jouent le rôle de guides, fournissant au modèle des données d’entraînement étiquetées (paires entrée-sortie) à partir desquelles la machine apprend des modèles.
Une fois la relation entre l'entrée et la sortie apprise à partir des ensembles de données précédents, la machine peut facilement prédire la valeur de sortie des nouvelles données.
Où pouvons-nous utiliser l'apprentissage supervisé ?
La réponse est : lorsque nous savons quoi rechercher dans les données d'entrée et ce que nous voulons comme sortie.
Les principaux types de problèmes d'apprentissage supervisé comprennent les problèmes de régression et de classification.
2. Apprentissage automatique non supervisé
L'apprentissage non supervisé fonctionne exactement à l'opposé de l'apprentissage supervisé.
Il utilise des données non étiquetées : la machine doit comprendre les données, trouver des modèles cachés et faire des prédictions en conséquence.
Ici, les machines nous fournissent de nouvelles découvertes après avoir dérivé indépendamment des modèles cachés à partir de données, sans que les humains aient à préciser ce qu'ils recherchent.
Les principaux types de problèmes d'apprentissage non supervisé comprennent l'analyse des règles de clustering et d'association.
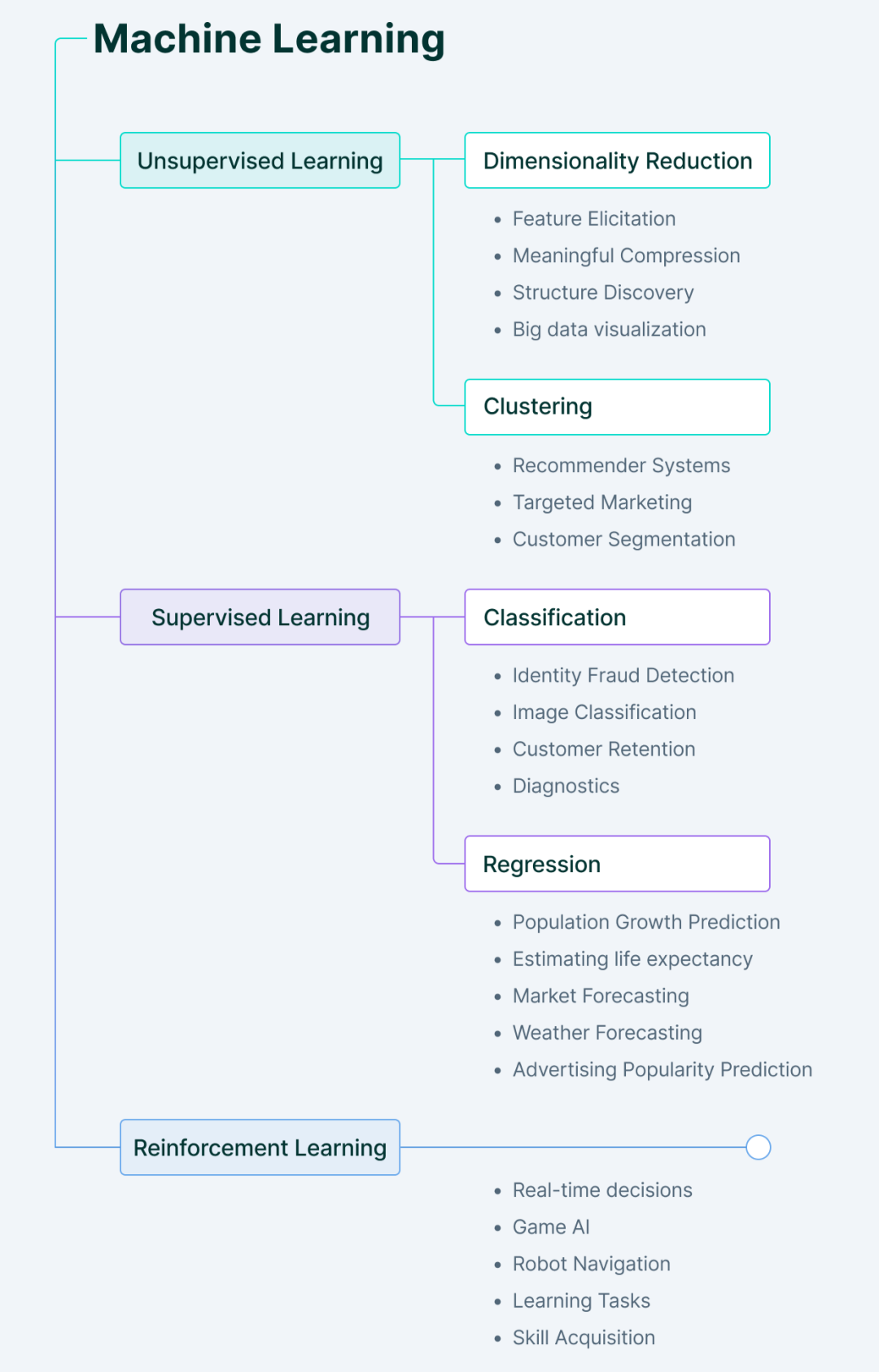
3. Apprentissage par renforcement
L'apprentissage par renforcement implique un agent qui apprend à se comporter dans un environnement en effectuant des actions.
Sur la base des résultats de ces actions, il fournit un retour d'information et ajuste son parcours futur - pour chaque bonne action, l'agent reçoit un retour positif, et pour chaque mauvaise action, l'agent reçoit un retour négatif ou une punition.
L'apprentissage par renforcement apprend sans aucune donnée étiquetée. Puisqu’il n’existe pas de données étiquetées, l’agent ne peut apprendre que sur la base de sa propre expérience.
4. Apprentissage semi-supervisé
Le semi-supervisé est l'état entre l'apprentissage supervisé et non supervisé.
Il prend les aspects positifs de chaque apprentissage, c'est-à-dire qu'il utilise des ensembles de données étiquetés plus petits pour guider la classification et effectue une extraction de caractéristiques non supervisée à partir d'ensembles de données non étiquetés plus grands.
Le principal avantage de l'apprentissage semi-supervisé est sa capacité à résoudre des problèmes lorsqu'il n'y a pas suffisamment de données étiquetées pour entraîner le modèle, ou lorsque les données ne peuvent tout simplement pas être étiquetées parce que les humains ne savent pas quoi y rechercher.
Quatre 6 applications d'apprentissage automatique du monde réel
L'apprentissage automatique est au cœur de presque toutes les entreprises technologiques de nos jours, y compris des entreprises comme Google ou le moteur de recherche Youtube.
Ci-dessous, nous avons compilé quelques exemples d'applications réelles de l'apprentissage automatique que vous connaissez peut-être :
Voitures autonomes
Les véhicules sont confrontés à diverses situations sur la route.
Pour que les voitures autonomes soient plus performantes que les humains, elles doivent apprendre et s'adapter aux conditions routières changeantes et au comportement des autres véhicules.
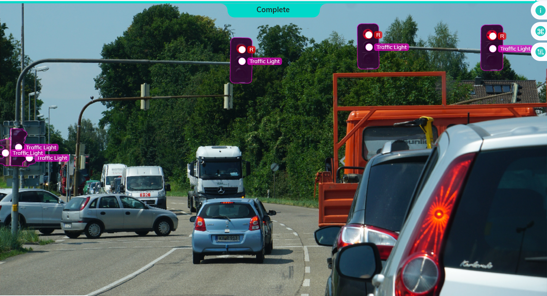
Les voitures autonomes collectent des données sur leur environnement à partir de capteurs et de caméras, puis les interprètent et réagissent en conséquence. Il utilise l'apprentissage supervisé pour identifier les objets environnants, l'apprentissage non supervisé pour identifier les modèles dans d'autres véhicules, et enfin prend des mesures en conséquence à l'aide d'algorithmes de renforcement.
Analyse d'image et détection d'objets
L'analyse d'image est utilisée pour extraire différentes informations des images.
Il a des applications dans des domaines tels que l'inspection des défauts de fabrication, l'analyse du trafic automobile dans les villes intelligentes ou les moteurs de recherche visuels comme Google Lens.
L'idée principale est d'utiliser des techniques d'apprentissage profond pour extraire des fonctionnalités des images, puis d'appliquer ces fonctionnalités à la détection d'objets.
Chatbot du service client
Il est très courant de nos jours que les entreprises utilisent des chatbots IA pour fournir un support client et des ventes. Les chatbots IA aident les entreprises à gérer des volumes élevés de requêtes clients en fournissant une assistance 24h/24 et 7j/7, réduisant ainsi les coûts d'assistance et générant des revenus supplémentaires et des clients satisfaits.
La robotique IA utilise le traitement du langage naturel (NLP) pour traiter le texte, extraire les mots-clés des requêtes et répondre en conséquence.
imagerie médicale et diagnostic
Le fait est le suivant : les données d'imagerie médicale sont à la fois la source d'information la plus riche et l'une des plus complexes.
Analyser manuellement des milliers d'images médicales est une tâche fastidieuse et fait perdre un temps précieux aux pathologistes qui pourrait être utilisé plus efficacement.
Mais il ne s’agit pas seulement de gagner du temps : de petites caractéristiques telles que des artefacts ou des nodules peuvent ne pas être visibles à l’œil nu, ce qui entraîne des retards dans le diagnostic de la maladie et des prédictions incorrectes. C’est pourquoi les techniques d’apprentissage profond impliquant des réseaux de neurones, qui peuvent être utilisées pour extraire des caractéristiques des images, présentent un tel potentiel.
Identification des fraudes
À mesure que le secteur du commerce électronique se développe, on observe une augmentation du nombre de transactions en ligne et une diversification des moyens de paiement disponibles. Malheureusement, certaines personnes profitent de cette situation. Dans le monde d’aujourd’hui, les fraudeurs sont hautement qualifiés et peuvent adopter de nouvelles technologies très rapidement.
C'est pourquoi nous avons besoin d'un système capable d'analyser les modèles de données, de faire des prédictions précises et de répondre aux menaces de cybersécurité en ligne telles que les fausses tentatives de connexion ou les attaques de phishing.
Par exemple, les systèmes de prévention de la fraude peuvent découvrir si un achat est légitime en fonction de l'endroit où vous avez effectué des achats dans le passé ou de la durée de votre connexion en ligne. De même, ils peuvent détecter si quelqu’un tente de usurper votre identité en ligne ou par téléphone.
Algorithme de recommandation
Cette pertinence de l'algorithme de recommandation repose sur l'étude des données historiques et dépend de plusieurs facteurs, dont les préférences et les intérêts des utilisateurs.
Des entreprises comme JD.com ou Douyin utilisent des systèmes de recommandation pour organiser et afficher du contenu ou des produits pertinents aux utilisateurs/acheteurs.
Cinq défis et limites de l'apprentissage automatique
Sous-apprentissage et surapprentissage
Dans la plupart des cas, les performances de tout algorithme d'apprentissage automatique Les raisons des mauvaises performances sont dus à un sous-apprentissage et un surapprentissage. Décomposons ces termes dans le contexte de la formation d'un modèle d'apprentissage automatique.
Le sous-ajustement est un scénario dans lequel un modèle d'apprentissage automatique ne peut ni apprendre la relation entre les variables dans les données ni prédire correctement de nouveaux points de données. En d’autres termes, le système d’apprentissage automatique ne détecte pas les tendances entre les points de données. 
Quelles sont les causes du sous-apprentissage et du surapprentissage ?
Des cas plus généraux incluent des situations dans lesquelles les données utilisées pour la formation ne sont pas propres et contiennent beaucoup de bruit ou de valeurs inutiles, ou la taille des données est trop petite. Il existe cependant des raisons plus spécifiques.
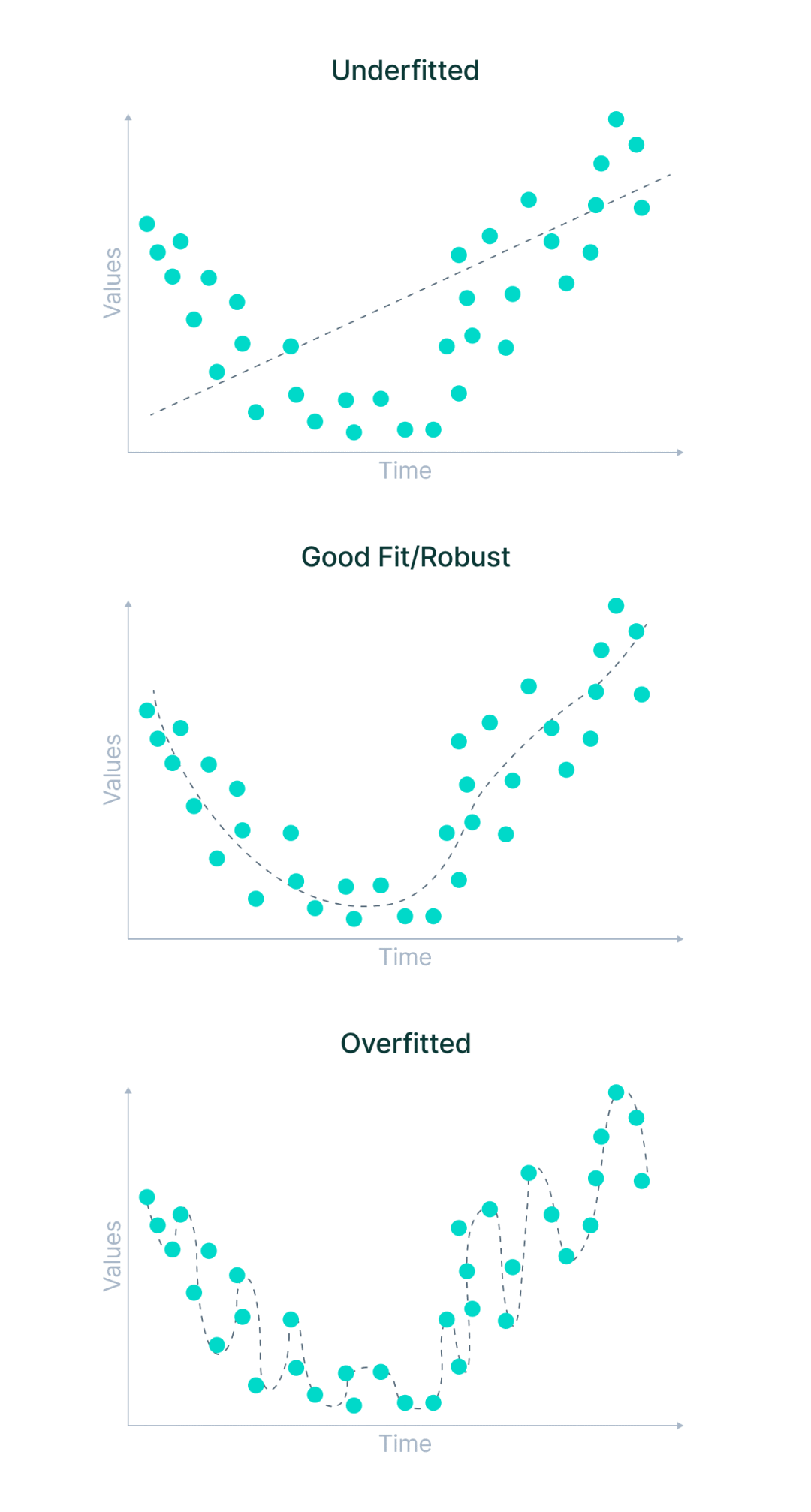 Jetons-y un coup d'œil.
Jetons-y un coup d'œil.
- Le modèle a été entraîné avec les mauvais paramètres et les données d'entraînement n'ont pas été entièrement observées
- Le modèle est trop simple et ne peut pas mémoriser suffisamment de fonctionnalités
- Les données d'entraînement sont trop diverses ou complexes
Cela peut se produire dans les situations suivantes Surajustement :
- Le modèle a été entraîné avec les mauvais paramètres et a surobservé les données d'entraînement.
- Le modèle était trop complexe et n'était pas pré-entraîné sur des données plus diverses.
- Les étiquettes des données d'entraînement sont trop strictes ou les données originales sont trop uniformes et ne représentent pas la véritable distribution.

Dimensionnalité
La précision de tout modèle d'apprentissage automatique est directement proportionnelle à la dimensionnalité de l'ensemble de données. Mais cela ne fonctionne que jusqu'à un certain seuil.
La dimensionnalité d'un ensemble de données fait référence au nombre d'attributs/caractéristiques présents dans l'ensemble de données. L'augmentation exponentielle du nombre de dimensions conduit à l'ajout d'attributs non essentiels qui perturbent le modèle, réduisant ainsi la précision du modèle d'apprentissage automatique.
Nous appelons ces difficultés associées à la formation de modèles d’apprentissage automatique la « malédiction de la dimensionnalité ».
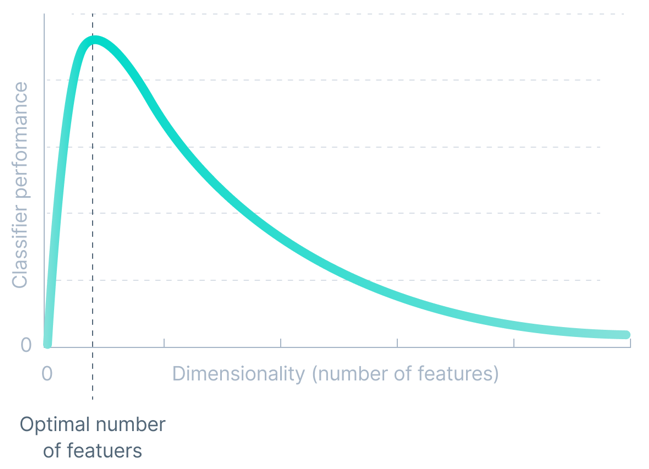
Qualité des données
Les algorithmes d'apprentissage automatique sont sensibles aux données d'entraînement de mauvaise qualité.
La qualité des données peut souffrir du bruit dans les données dû à des données incorrectes ou à des valeurs manquantes. Même des erreurs relativement petites dans les données d’entraînement peuvent entraîner des erreurs à grande échelle dans les résultats du système.
Lorsqu'un algorithme fonctionne mal, cela est généralement dû à des problèmes de qualité des données tels qu'une quantité insuffisante/des données biaisées/bruyantes ou des fonctionnalités insuffisantes pour décrire les données.
Par conséquent, avant de former un modèle d'apprentissage automatique, un nettoyage des données est souvent nécessaire pour obtenir des données de haute qualité.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
MetaFAIR s'est associé à Harvard pour fournir un nouveau cadre de recherche permettant d'optimiser le biais de données généré lors de l'apprentissage automatique à grande échelle. On sait que la formation de grands modèles de langage prend souvent des mois et utilise des centaines, voire des milliers de GPU. En prenant comme exemple le modèle LLaMA270B, sa formation nécessite un total de 1 720 320 heures GPU. La formation de grands modèles présente des défis systémiques uniques en raison de l’ampleur et de la complexité de ces charges de travail. Récemment, de nombreuses institutions ont signalé une instabilité dans le processus de formation lors de la formation des modèles d'IA générative SOTA. Elles apparaissent généralement sous la forme de pics de pertes. Par exemple, le modèle PaLM de Google a connu jusqu'à 20 pics de pertes au cours du processus de formation. Le biais numérique est à l'origine de cette imprécision de la formation,
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
 Apprentissage automatique en C++ : un guide pour la mise en œuvre d'algorithmes d'apprentissage automatique courants en C++
Jun 03, 2024 pm 07:33 PM
Apprentissage automatique en C++ : un guide pour la mise en œuvre d'algorithmes d'apprentissage automatique courants en C++
Jun 03, 2024 pm 07:33 PM
En C++, la mise en œuvre d'algorithmes d'apprentissage automatique comprend : Régression linéaire : utilisée pour prédire des variables continues. Les étapes comprennent le chargement des données, le calcul des poids et des biais, la mise à jour des paramètres et la prédiction. Régression logistique : utilisée pour prédire des variables discrètes. Le processus est similaire à la régression linéaire, mais utilise la fonction sigmoïde pour la prédiction. Machine à vecteurs de support : un puissant algorithme de classification et de régression qui implique le calcul de vecteurs de support et la prédiction d'étiquettes.
 Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
1. Contexte de la construction de la plateforme 58 Portraits Tout d'abord, je voudrais partager avec vous le contexte de la construction de la plateforme 58 Portraits. 1. La pensée traditionnelle de la plate-forme de profilage traditionnelle ne suffit plus. La création d'une plate-forme de profilage des utilisateurs s'appuie sur des capacités de modélisation d'entrepôt de données pour intégrer les données de plusieurs secteurs d'activité afin de créer des portraits d'utilisateurs précis. Elle nécessite également l'exploration de données pour comprendre le comportement et les intérêts des utilisateurs. et besoins, et fournir des capacités côté algorithmes ; enfin, il doit également disposer de capacités de plate-forme de données pour stocker, interroger et partager efficacement les données de profil utilisateur et fournir des services de profil. La principale différence entre une plate-forme de profilage d'entreprise auto-construite et une plate-forme de profilage de middle-office est que la plate-forme de profilage auto-construite dessert un seul secteur d'activité et peut être personnalisée à la demande. La plate-forme de mid-office dessert plusieurs secteurs d'activité et est complexe ; modélisation et offre des fonctionnalités plus générales. 2.58 Portraits d'utilisateurs de l'arrière-plan de la construction du portrait sur la plate-forme médiane 58
