
 Périphériques technologiques
IA
Recherche sur la possibilité de construire un modèle de langage visuel à partir d'un ensemble de mots
Périphériques technologiques
IA
Recherche sur la possibilité de construire un modèle de langage visuel à partir d'un ensemble de mots
Recherche sur la possibilité de construire un modèle de langage visuel à partir d'un ensemble de mots

Traducteur | Zhu Xianzhong
Chonglou
Actuellement, L'intelligence artificielle multimodale est devenue un street talk sujets de discussion brûlants. Avec la récente version de GPT-4, nous voyons d’innombrables nouvelles applications possibles et technologies futures qui étaient inimaginables il y a à peine six mois. En fait, les modèles de langage visuel sont généralement utiles pour de nombreuses tâches différentes. Par exemple, vous pouvez utiliser CLIP (Contrastive Language-Image Pre-training, c'est-à-dire "Contrastive Language-Image Pre-training", lien : https://www.php.cn/link /b02d46e8a3d8d9fd6028f3f2c2495864 Classification d'images sans prise de vue sur des ensembles de données invisibles En général, d'excellentes performances peuvent être obtenues sans aucune formation
Pendant ce temps, les modèles de langage visuel ne sont pas parfaits. Dans cet article, nous allons explorer les limites de ces modèles, en soulignant où et pourquoi ils peuvent échouer. En fait, cet article est une référence à notre expérience récente . publier une description courte/de haut niveau de l'article prévu qui sera publié sous forme de ICLR 2023 Oralarticle Si vous souhaitez le consulter Pour. le code source complet de cet article, cliquez simplement sur le lien https://www.php.cn/link/afb992000fcf79ef7a53fffde9c8e044 IntroductionQu'est-ce qu'un modèle de langage visuel ?
. Les modèles de langage ont révolutionné le domaine en exploitant la synergie entre les données visuelles et linguistiques pour effectuer diverses tâches. Alors que de nombreux modèles de langage visuel ont été introduits dans la littérature existante, CLIP(Contrast Language-Image Pre-training. ) reste le modèle le plus connu et le plus utilisé En intégrant des images et des légendes dans le même espace vectoriel, le modèle CLIP permet de Raisonner selon des modèles, permettant aux utilisateurs d'effectuer des tâches telles que comme la classification d'images sans prise de vue et la récupération texte-image. Et le modèle CLIP utilise des méthodes d'apprentissage contrastées pour apprendre les intégrations d'images et de légendes. apprenez à associer des images à leurs
légendescorrespondantes en minimisant la distance entre les images dans un espace vectoriel partagé. L'ordre obtenu par le modèle CLIP et d'autres modèles basés sur le contraste démontrent que cette approche est très efficace . La perte de contraste est utilisée pour comparer les paires image et
caption par lots, et le modèle est optimisé pour maximiser la similarité image-texte entre les paires d'intégrations et réduire la similarité entre les autres paires image-texte dans. le lotLa figure ci-dessous montre
un exemple d'étapes de mise en lots et de formation possibles,où :
- Le carré violet contient les intégrations pour tous les titres , et le carré vert contient les intégrations pour toutes les images.
- Le carré de la matrice contient le produit scalaire (prononcé « similarité cosinus ») de toutes les intégrations d'images et de toutes les intégrations de texte dans le lot, puisque les intégrations sont normalisées).
- Le carré bleu contient le produit scalaire entre les paires image-texte où le modèle doit maximiser la similarité, les autres carrés blancs sont Nous souhaitons minimiser la similitude (car chacun de ces carrés contient des similitudes de paires image-texte inégalées, comme une image d'un chat et une description de "ma chaise vintage"(#🎜 🎜# myretrochair). Formation (
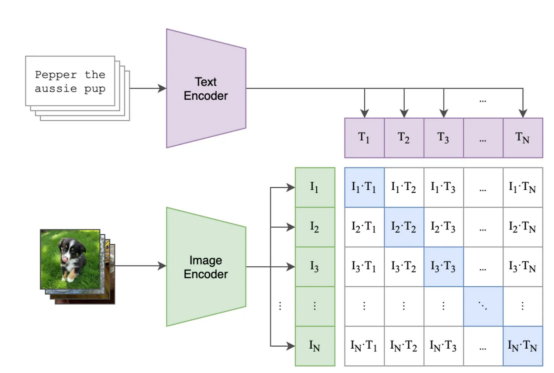 Le carré bleu est le couple image-texte dont nous souhaitons optimiser la similarité
Le carré bleu est le couple image-texte dont nous souhaitons optimiser la similarité
Après la formation, vous devriez être capable de générer un texte dans lequel vous pouvez associer l'image et #🎜 🎜#title Un espace vectoriel significatif à encoder Une fois que vous avez intégré le contenu pour chaque image et chaque texte, vous pouvez effectuer des tâches telles que voir quelles images correspondent le mieux au titre (par exemple rechercher ). dans l'album photo des vacances d'été 2017). "chiens sur la plage" (狗 sur la plage
) ) , ou trouvez quelle étiquette de texte ressemble le plus à des images personnalisées (par exemple, vous avez un tas d'images de vos chiens et chats et vous souhaitez pouvoir identifier lesquels sont lesquels. Les modèles de langage visuel tels que #CLIP sont devenus puissants). des outils pour résoudre des tâches complexes d'intelligence artificielle en intégrant des informations visuelles et linguistiques. Leur capacité à intégrer ces deux types de données dans un espace vectoriel partagé a conduit à une précision sans précédent dans un large éventail d'applications et à des performances exceptionnelles. 🎜#Les modèles de langage visuel peuvent-ils comprendre le langage ? Le travail consiste exactement à à essayer de prendre certaines mesures Pour répondre à cette question de savoir si les modèles profonds peuvent ou non. Il y a actuellement un débat important sur la mesure dans laquelle le langage peut être compris. Ici, notre objectif est d'étudier les modèles de langage visuel et leurs capacités de synthèse. comprendre les composants de test ; ce nouveau benchmark s'appelle ARO ( Attribution, Relations,
and Order# 🎜🎜#: #🎜🎜 #attributes). Ensuite, nous explorons pourquoi la perte contrastive peut être limitée dans ce cas. Enfin, nous proposons une approche simple mais prometteuse. à cette solution.
Nouveau benchmark : ARO (Attributs, Relations et Ordre) J'aime CLIP (et Salesforce Comment un modèle comme le BLIP récemment lancé réussit-il à comprendre le langage ?
Nous avons rassemblé un ensemble de compositions basées sur des attributs title (par exemple "la porte rouge et l'homme debout"(红门和standing人)) et un groupe basé sur les relations Synthèse de title (par exemple "le cheval mange l'herbe"(马在吃草) ) ) et les images correspondantes. Ensuite, nous générons un faux titre qui remplace par , comme #🎜🎜 #"l'herbe mange le cheval"(草是吃马) . Les modèles peuvent-ils trouver le bon titre ? Nous avons également exploré l'effet du mélange des mots : le modèle préfère-t-il le title au mélange title#🎜🎜 # ? Nous fournissons
attributs, relations et ordre (ARO ) )BenchmarkLes quatre jeux de données créés sont présentés ci-dessous (veuillez noter que la commandeparts Contient deux ensembles de données) :
Différents ensembles de données que nous avons créés  # 🎜🎜#Comprend
# 🎜🎜#Comprend
Relation, Attribution et Ordre. Pour chaque ensemble de données, nous montrons un exemple d'image et un titre différent. Parmi eux, Un seul titre est correct, et le modèle doit identifier ce comme le bon titre. Attribut
Testez votre compréhension des attributs- #🎜🎜 #Le résultat est
- :«la route pavée et la maison blanche»(route pavée et la maison blanche# 🎜 🎜#) et "la route blanche et la maison pavée" (白路和狠的屋 #🎜 🎜#) . Test de relation compréhension des relations Le résultat est : « le cheval mange l'herbe »(
- 马在吃草) et #🎜🎜 # "L'herbe mange le cheval"(草在吃草) . Enfin, Order a testé le modèle contre les perturbations de commandeaprès#🎜 Élasticité de 🎜#Results : Nous mélangeons aléatoirement les en-têtes d'un ensemble de données standard (par exemple, MSCOCO). Le modèle de langage visuel peut-il trouver la légende correcte correspondant à l’image ? La tâche semble facile, nous voulons que le modèle comprenne la différence entre « le cheval mange de l'herbe » et « l'herbe mange de l'herbe », non ? Je veux dire, qui a déjà vu de l'herbe manger ?
-
Eh bien, c'est peut-être le modèle BLIP parce qu'il ne peut pas comprendre « le cheval mange de l'herbe » et « l'herbe est manger de l'herbe” La différence entre:

Le modèle BLIP ne comprend pas la différence entre "l'herbe mange de l'herbe" et "le cheval mange de l'herbe" ( où contient des éléments de l'ensemble de données visuel du génome , photo fournie par l'auteur )
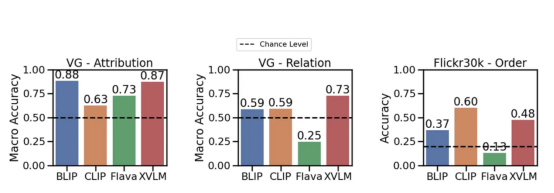
Maintenant , prenons un regard sur EXPERIMENT RESULTS : Peu de modèles peuvent aller au-delà de la compréhension des relations dans une large mesure. possibilités (par exemple, eating — eating ). Cependant, CLIP modèle est en property#🎜🎜 # L'avantage de et la relation est légèrement supérieur à ce possibilité#🎜 🎜 #. Cela indique en fait qu'il y a un problème avec le modèle de langage visuel. Différents modèles dans Attributs# Performance sur des benchmarks 🎜🎜#
, relationnels et séquentiels (Flick30k). qui utilise CLIP, BLIP et autres modèles SoTA One L'un des principaux résultats de ce travail est que l'apprentissage des langues peut nécessiter plus que la perte contrastive standard . Pourquoi c'est ? Commençons par le début : les modèles de langage visuel sont souvent évalués dans des tâches de récupération : prenez un titre et trouvez ce qu'il correspond à l'image. Si vous regardez les ensembles de données utilisés pour évaluer ces modèles (par exemple MSCOCO, Flickr30K), vous verrez qu'ils contiennent souvent des images décrites par titres , qui #🎜 🎜#Titre
Nécessite une compréhension de la composition (par exemple, "le chat orange est sur la table rouge":#🎜🎜 # chat orange sur table rouge). Donc, si title est complexe, pourquoi le modèle ne peut-il pas apprendre à comprendre la composition ? [Description
] est effectuée sur ces ensembles de données La récupération ne nécessite pas nécessairement une compréhension de la composition. Nous avons essayé de mieux comprendre le problème et testé le modèle lors de la récupération lors de la modification de l'ordre des mots dans la performance du titre. Pouvons-nous trouver la bonne image avec le titre "les livres que sont les gens qui regardent" ? Si la réponse est oui;
Notre modèle de test est chargé de la récupération à l'aide de titres brouillés. Même si on brouille les légendes, le modèle peut retrouver correctement l'image correspondante (et vice versa). Cela suggère que la tâche de récupération est peut-être trop simple , Image fournie par l'auteur.
Nous avons testé différents processus de shuffle, et les résultats sont positifs : même si différentes techniques de shuffle sont utilisées, les performances de récupération ne sont fondamentalement pas affectées.
Répétons-le : les modèles de langage visuel permettent une récupération haute performance sur ces ensembles de données, même lorsque les informations d'instruction sont inaccessibles. Ces modèles peuvent se comporter comme une pile de mots , où l'ordre n'a pas d'importance : si le modèle n'a pas besoin de comprendre l'ordre des mots pour bien fonctionner en récupération, alors que mesurons-nous réellement en récupération ?
Que faire ?
Maintenant que nous savons qu'il y a un problème, nous voudrons peut-être chercher une solution. Le moyen le plus simple est de faire comprendre au modèle CLIP que "le chat est sur la table" et "la table est sur le chat" sont différents.
En fait, l'une des façons que nous avons suggérées est d'améliorer la formation CLIP en ajoutant un négatif dur spécialement conçu pour résoudre ce problème. Il s'agit d'une solution très simple et efficace : elle nécessite de très petites modifications de la perte CLIP d'origine sans affecter les performances globales (vous pouvez lire quelques mises en garde dans l'article). Nous appelons cette version de CLIP NegCLIP.
Introduction des négatifs durs dans CLIPmodèle (Nous avons ajouté des négatifs durs d'images et de texte, images fournies par l'auteur)
En gros, nous demandons au modèle NegCLIPde placer une image d'un chat noir sur la phrase « un chat noir assis sur un bureau » Près, mais loinphrase « un bureau noir assis sur un chat" (un bureau noir assis sur un chat). Remarque, Ce dernier est généré automatiquement à l'aide de balises POS. L'effet de ce correctif est qu'il améliore réellement les performances du benchmark ARO sans nuire aux performances de récupération ou aux performances des tâches en aval telles que la récupération et la classification. Voir le graphique ci-dessous pour les résultats sur différents benchmarks (voir cet article correspondant pour plus de détails).
NegCLIPmodel versus CLIPmodel sur différents benchmarks. Parmi eux, le benchmark bleu est le benchmark que nous avons introduit, et le benchmark vert vient du réseaudocumentation(photo fournie par l'auteur)
Vous peut voir cela ici et c'est une énorme amélioration par rapport au benchmark ARO, et il y a aussi des améliorations edge ou des performances similaires sur d'autres tâches en aval.
Mise en œuvre de la programmation
Mert (auteur principal du article) dans la création d'une petite bibliothèque pour tester des modèles de langage visuel fait. Vous pouvez utiliser son code pour reproduire nos résultats ou expérimenter de nouveaux modèles.
Cela ne prend que quelques lignes de P :
import clip from dataset_zoo import VG_Relation, VG_Attribution model, image_preprocess = clip.load("ViT-B/32", device="cuda") root_dir="/path/to/aro/datasets" #把 download设置为True将把数据集下载到路径`root_dir`——如果不存在的话 #对于VG-R和VG-A,这将是1GB大小的压缩zip文件——它是GQA的一个子集 vgr_dataset = VG_Relation(image_preprocess=preprocess, download=True, root_dir=root_dir) vga_dataset = VG_Attribution(image_preprocess=preprocess, download=True, root_dir=root_dir) #可以对数据集作任何处理。数据集中的每一项具有类似如下的形式: # item = {"image_options": [image], "caption_options": [false_caption, true_caption]}Copier après la connexionDe plus, nous avons implémenté NegCLIP Modèle (Il s'agit en fait d'une copie mise à jour d'OpenCLIP), son adresse complète de téléchargement de code est https://github.com/vinid/neg_clip.
Conclusion
En bref, le modèle de langage visuelpeut actuellement faire beaucoup de choses. Ensuite, Nous avons hâte de voir ce que les futurs modèles comme GPT4 pourront faire !
Présentation du traducteur
Zhu Xianzhong, rédacteur en chef de la communauté 51CTO, blogueur expert 51CTO, conférencier, professeur d'informatique dans une université de Weifang et vétéran de l'industrie de la programmation indépendante.
Titre original : Votre modèle vision-langage pourrait être un sac de mots, auteur : Federico Bianchi

 qui utilise
qui utilise 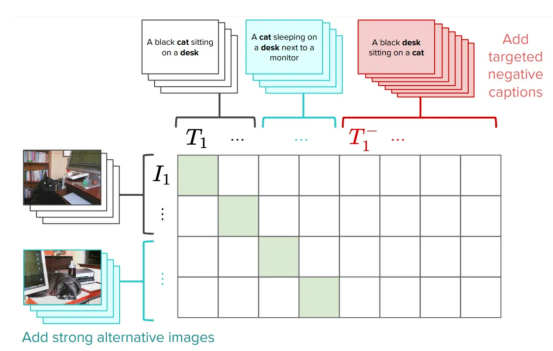
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1207
24
52
1207
24

 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
