

Au cours du passé, nous avons entendu parler du réseau neuronal récurrent RNN. Son schéma structurel est le suivant :
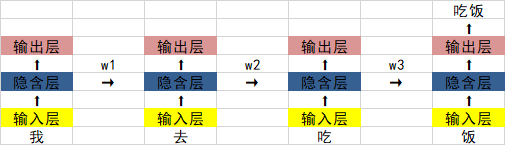
Le plus gros problème est que lorsque w1. , w2 Lorsque les valeurs de w3 et w3 sont inférieures à 0, si une phrase est suffisamment longue, il y aura un problème de disparition du gradient lorsque le réseau neuronal effectuera une propagation vers l'arrière et vers l'avant.
0,925=0,07. Si une phrase contient 20 à 30 mots, alors la sortie de la couche cachée du premier mot sera 0,07 fois celle de l'original lorsqu'elle est passée à la fin, par rapport à l'impact du dernier mot. .
La situation spécifique est la suivante :
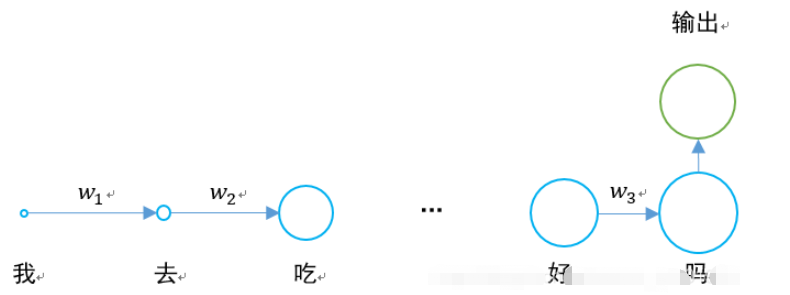
Le réseau de mémoire à long terme et à court terme a émergé pour résoudre le problème de la disparition du gradient.
La couche cachée du RNN d'origine n'a qu'un seul état h, qui est transmis du début à la fin. Elle est très sensible aux entrées à court terme.
Si nous ajoutons un autre état c et le laissons sauvegarder l'état à long terme, le problème peut être résolu.
Pour RNN et LSTM, la comparaison des deux unités d'étape est la suivante.

Nous élargissons la structure du LSTM en fonction de la dimension temporelle :
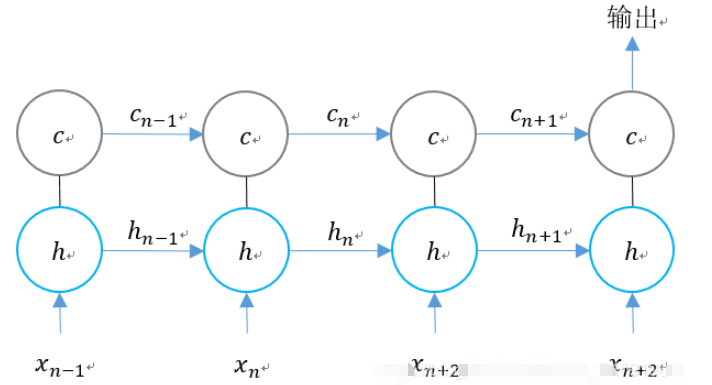
Nous pouvons voir qu'à n instant, il y a trois entrées dans LSTM :
1. le moment actuel ;
2. La valeur de sortie du LSTM au dernier moment
3.
LSTM a deux sorties :
1. Valeur de sortie LSTM au moment actuel ;
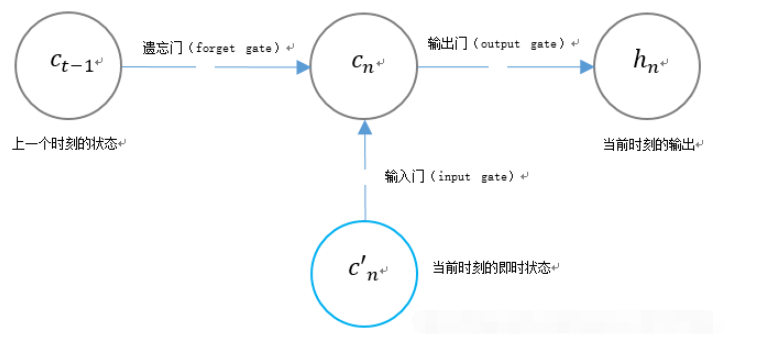
3. La structure de porte unique du LSTM
LSTM utilise deux portes pour contrôler le contenu de l'état de l'unité cn :
LSTM utilise une porte pour contrôler le contenu de la valeur de sortie actuelle hn :
 Fonctions associées de LSTM dans tensorflow
Fonctions associées de LSTM dans tensorflow
tf.contrib.rnn.BasicLSTMCell(
num_units,
forget_bias=1.0,
state_is_tuple=True,
activation=None,
reuse=None,
name=None,
dtype=None
)forget_bias : biais ajouté à la porte d'oubli. Définissez manuellement le point de contrôle de formation CudnnLSTM restauré sur 0,0.
state_is_tuple : si True, les états acceptés et renvoyés sont des 2-uplets de c_state et m_state ; si False, ils sont connectés le long de l'axe de la colonne. False est sur le point d’être obsolète.
activation : fonction d'activation.
reuse : Décrit s'il faut réutiliser la variable dans la portée existante. Si une portée existante possède déjà la variable donnée et qu'elle n'est pas True, une erreur est générée.
name : Le nom du calque.
dtype : Le type de données de cette couche.
Lorsqu'il est utilisé, il peut être défini comme :
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
Une fois la définition terminée, l'état peut être initialisé :
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
tf.nn.dynamic_rnn
tf.nn.dynamic_rnn(
cell,
inputs,
sequence_length=None,
initial_state=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None
)time_major:输入和输出tensor的形状格式。这些张量的形状必须为[max_time, batch_size, depth],若表述正确,则它为真。这些张量的形状必须是[batch_size,max_time,depth],如果为假。time_major=true可以提高效率,因为它避免了在RNN计算的开头和结尾进行转置操作。默认情况下,此函数为False,因为大多数的 TensorFlow 数据以批处理主数据的形式存在。
scope:创建的子图的可变作用域;默认为“RNN”。
在LSTM的最后,需要用该函数得出结果。
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn( lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
返回的是一个元组 (outputs, state):
outputs:LSTM的最后一层的输出,是一个tensor。如果为time_major== False,则它的shape为[batch_size,max_time,cell.output_size]。如果为time_major== True,则它的shape为[max_time,batch_size,cell.output_size]。
states:states是一个tensor。state是最终的状态,也就是序列中最后一个cell输出的状态。一般情况下states的形状为 [batch_size, cell.output_size],但当输入的cell为BasicLSTMCell时,states的形状为[2,batch_size, cell.output_size ],其中2也对应着LSTM中的cell state和hidden state。
整个LSTM的定义过程为:
def add_input_layer(self,):
#X最开始的形状为(256 batch,28 steps,28 inputs)
#转化为(256 batch*28 steps,128 hidden)
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='to_2D')
#获取Ws和Bs
Ws_in = self._weight_variable([self.input_size, self.cell_size])
bs_in = self._bias_variable([self.cell_size])
#转化为(256 batch*28 steps,256 hidden)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# (batch * n_steps, cell_size) ==> (batch, n_steps, cell_size)
# (256*28,256)->(256,28,256)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='to_3D')
def add_cell(self):
#神经元个数
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
#每一次传入的batch的大小
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
#不是主列
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
#设置Ws,Bs
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size])
# shape = (batch,output_size)
# (256,10)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(self.cell_final_state[-1], Ws_out) + bs_out该例子为手写体识别例子,将手写体的28行分别作为每一个step的输入,输入维度均为28列。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
mnist = input_data.read_data_sets("MNIST_data",one_hot = "true")
BATCH_SIZE = 256 # 每一个batch的数据数量
TIME_STEPS = 28 # 图像共28行,分为28个step进行传输
INPUT_SIZE = 28 # 图像共28列
OUTPUT_SIZE = 10 # 共10个输出
CELL_SIZE = 256 # RNN 的 hidden unit size,隐含层神经元的个数
LR = 1e-3 # learning rate,学习率
def get_batch(): #获取训练的batch
batch_xs,batch_ys = mnist.train.next_batch(BATCH_SIZE)
batch_xs = batch_xs.reshape([BATCH_SIZE,TIME_STEPS,INPUT_SIZE])
return [batch_xs,batch_ys]
class LSTMRNN(object): #构建LSTM的类
def __init__(self, n_steps, input_size, output_size, cell_size, batch_size):
self.n_steps = n_steps
self.input_size = input_size
self.output_size = output_size
self.cell_size = cell_size
self.batch_size = batch_size
#输入输出
with tf.name_scope('inputs'):
self.xs = tf.placeholder(tf.float32, [None, n_steps, input_size], name='xs')
self.ys = tf.placeholder(tf.float32, [None, output_size], name='ys')
#直接加层
with tf.variable_scope('in_hidden'):
self.add_input_layer()
#增加LSTM的cell
with tf.variable_scope('LSTM_cell'):
self.add_cell()
#直接加层
with tf.variable_scope('out_hidden'):
self.add_output_layer()
#计算损失值
with tf.name_scope('cost'):
self.compute_cost()
#训练
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(LR).minimize(self.cost)
#正确率计算
self.correct_pre = tf.equal(tf.argmax(self.ys,1),tf.argmax(self.pred,1))
self.accuracy = tf.reduce_mean(tf.cast(self.correct_pre,tf.float32))
def add_input_layer(self,):
#X最开始的形状为(256 batch,28 steps,28 inputs)
#转化为(256 batch*28 steps,128 hidden)
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='to_2D')
#获取Ws和Bs
Ws_in = self._weight_variable([self.input_size, self.cell_size])
bs_in = self._bias_variable([self.cell_size])
#转化为(256 batch*28 steps,256 hidden)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# (batch * n_steps, cell_size) ==> (batch, n_steps, cell_size)
# (256*28,256)->(256,28,256)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='to_3D')
def add_cell(self):
#神经元个数
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
#每一次传入的batch的大小
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
#不是主列
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
#设置Ws,Bs
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size])
# shape = (batch,output_size)
# (256,10)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(self.cell_final_state[-1], Ws_out) + bs_out
def compute_cost(self):
self.cost = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits = self.pred,labels = self.ys)
)
def _weight_variable(self, shape, name='weights'):
initializer = np.random.normal(0.0,1.0 ,size=shape)
return tf.Variable(initializer, name=name,dtype = tf.float32)
def _bias_variable(self, shape, name='biases'):
initializer = np.ones(shape=shape)*0.1
return tf.Variable(initializer, name=name,dtype = tf.float32)
if __name__ == '__main__':
#搭建 LSTMRNN 模型
model = LSTMRNN(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
#训练10000次
for i in range(10000):
xs, ys = get_batch() #提取 batch data
if i == 0:
#初始化data
feed_dict = {
model.xs: xs,
model.ys: ys,
}
else:
feed_dict = {
model.xs: xs,
model.ys: ys,
model.cell_init_state: state #保持 state 的连续性
}
#训练
_, cost, state, pred = sess.run(
[model.train_op, model.cost, model.cell_final_state, model.pred],
feed_dict=feed_dict)
#打印精确度结果
if i % 20 == 0:
print(sess.run(model.accuracy,feed_dict = {
model.xs: xs,
model.ys: ys,
model.cell_init_state: state #保持 state 的连续性
}))Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



