

Les grands modèles de langage (LLM) deviennent populaires partout dans le monde. L'une de leurs applications importantes est le chat, et ils sont utilisés dans les questions et réponses, le service client et bien d'autres aspects. Cependant, les chatbots sont notoirement difficiles à évaluer. On ne sait pas encore exactement dans quelles circonstances ces modèles sont mieux utilisés. Par conséquent, l’évaluation du LLM est très importante.
Auparavant, un blogueur Medium nommé Marco Tulio Ribeiro a mené une #🎜 sur Vicuna-13B, MPT-7b-Chat et ChatGPT 3.5 sur certaines tâches complexes 🎜##🎜 🎜#test. Les résultats montrent que Vicuna est une alternative viable à ChatGPT (3.5) pour de nombreuses tâches, alors que MPT n'est pas encore prêt pour une utilisation dans le monde réel.
Récemment, le professeur agrégé de la CMU Graham Neubig a mené une évaluation détaillée de sept chatbots existants, a produit un outil open source pour une comparaison automatique et a finalement rédigé un rapport d'évaluation. Dans ce rapport, les évaluateurs ont présenté quelques résultats préliminaires d'évaluation et de comparaison des chatbots, dans le but de permettre aux utilisateurs de comprendre plus facilement l'état actuel de tous les modèles open source apparus récemment et des modèles basés sur des API.Plus précisément, l'évaluateur a créé une nouvelle boîte à outils open source, Zeno Build, pour évaluer le LLM. La boîte à outils combine : (1) une interface unifiée pour utiliser le LLM open source via Hugging Face ou l'API en ligne (2) une interface en ligne pour parcourir et analyser les résultats à l'aide de Zeno, et (3) des métriques pour l'évaluation SOTA du texte à l'aide de Critique ;
Résultats spécifiques pour participer : https : //zeno-ml-chatbot-report.hf.space/
Ce qui suit est un résumé des résultats de l'évaluation :
 Les évaluateurs ont évalué 7 modèles de langage : GPT-2, LLaMa, Alpaca, Vicuna, MPT-Chat, Cohere Command et ChatGPT (gpt-3.5-turbo) ; ## 🎜🎜#
Les évaluateurs ont évalué 7 modèles de langage : GPT-2, LLaMa, Alpaca, Vicuna, MPT-Chat, Cohere Command et ChatGPT (gpt-3.5-turbo) ; ## 🎜🎜#
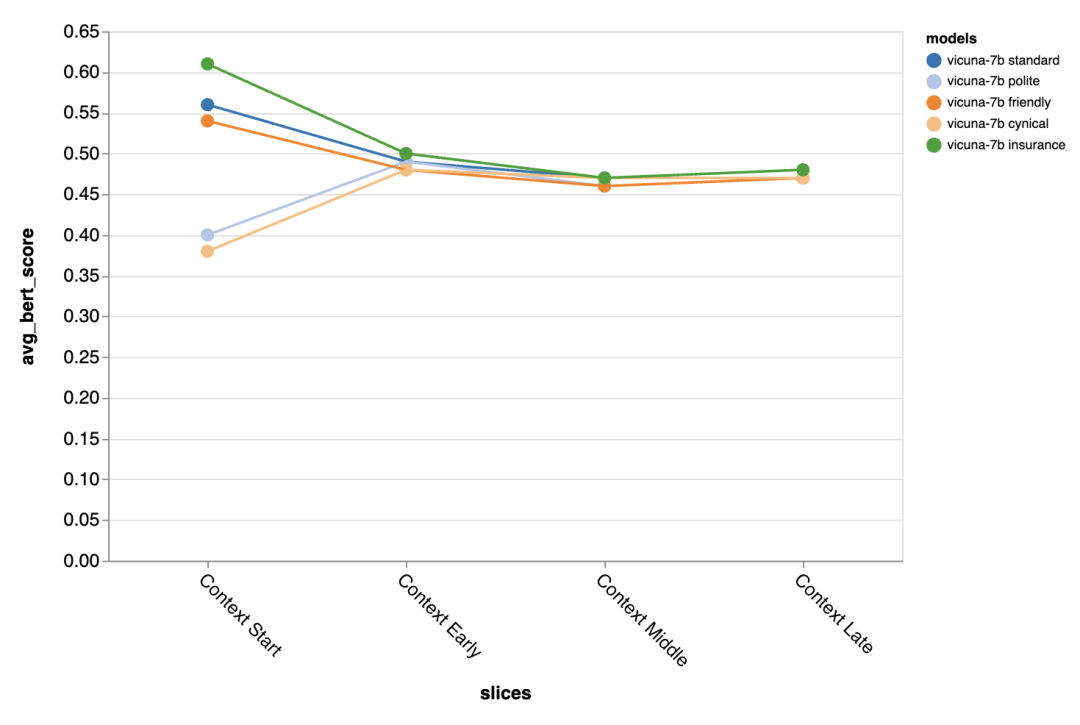
Les modèles sont évalués en fonction de leur capacité à créer des réponses de type humain sur un ensemble de données de service client ; est arrivé en tête, mais le modèle open source Vicuna est également très compétitif 🎜#L'ingénierie rapide est très utile pour améliorer les performances du dialogue du modèle lors des premiers tours de dialogue, mais dans les tours ultérieurs, lorsqu'il y a plus de contexte, l'effet est moins évident
Même un modèle aussi puissant que ChatGPT a de nombreux problèmes évidents, tels que des hallucinations, l'incapacité de explorer plus d’informations, dupliquer du contenu, etc.
Metriques d'évaluation
Les évaluateurs évaluent ces modèles en fonction de la similitude de leurs résultats avec les réponses humaines du service client. Cela se fait à l'aide des métriques fournies par la boîte à outils Critique :
chrf : mesure le chevauchement des chaînes ;
Pour approfondir les résultats, l'examinateur a utilisé l'interface d'analyse de Zeno, en particulier son générateur de rapports, pour analyser les résultats en fonction de la position dans la conversation (début, début, segmentation des exemples par type de conversation). longueurs de référence des réponses humaines (courtes, moyennes, longues) et utilisez son interface d'exploration pour voir des exemples de notation mal automatisés et mieux comprendre où chaque modèle échoue.
Résultats
Quelle est la performance globale du modèle ?
Selon toutes ces mesures, gpt-3.5-turbo est clairement le gagnant ; Vicuna est le gagnant de l'open source et GPT-2 n'est pas si bon, ce qui montre l'importance de s'entraîner directement dans le chat.
Ces classements correspondent également à peu près à ceux de lmsys chat arena, qui utilise des tests A/B humains pour comparer les modèles, mais les résultats de Zeno Build sont obtenus sans aucune évaluation humaine.
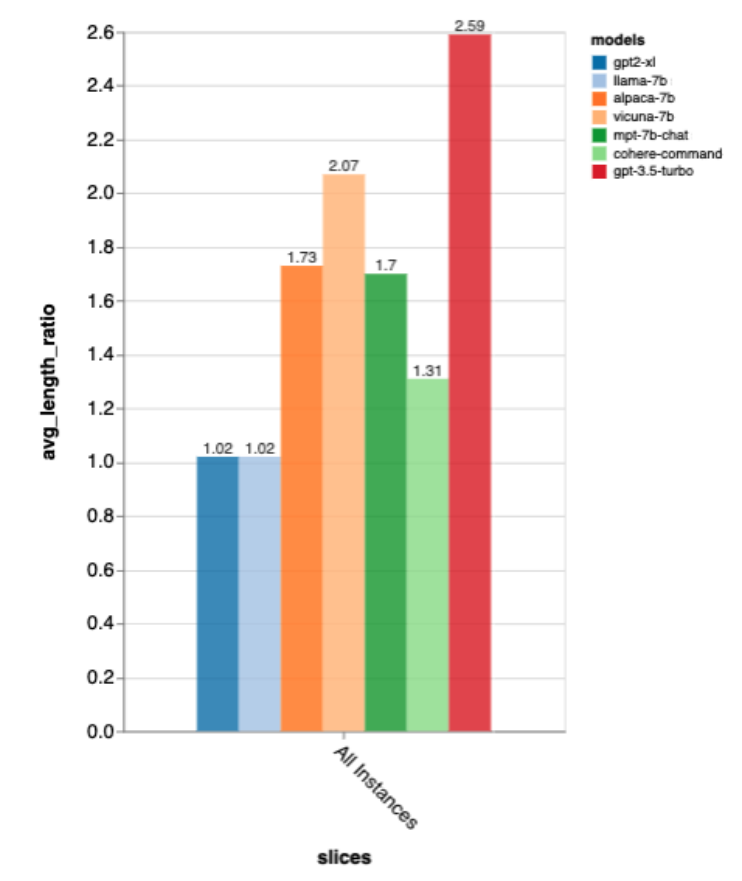
Concernant la longueur de sortie, la sortie de gpt3.5-turbo est beaucoup plus détaillée que celle des autres modèles, et il semble que les modèles réglés dans le sens du chat donnent généralement une sortie détaillée. 
Précision de la longueur de réponse de référence
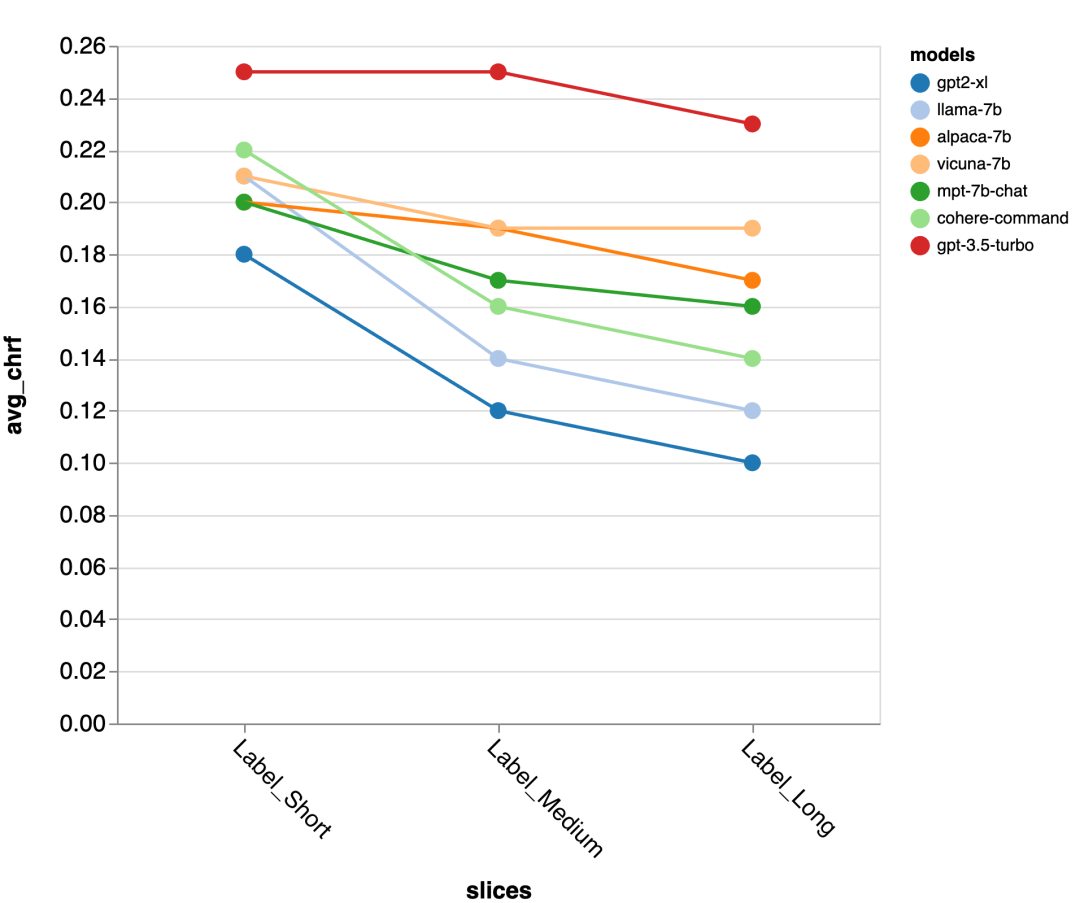
gpt-3.5-turbo et Vicuna maintiennent la précision même lors de cycles de dialogue plus longs, tandis que la précision des autres modèles diminue.
La question suivante est de savoir quelle est l'importance de la taille de la fenêtre contextuelle ? Les évaluateurs ont mené des expériences avec Vicuna et la fenêtre contextuelle variait de 1 à 4 discours précédents. Lorsqu'ils ont augmenté la fenêtre contextuelle, les performances du modèle ont augmenté, ce qui indique que des fenêtres contextuelles plus grandes sont importantes.

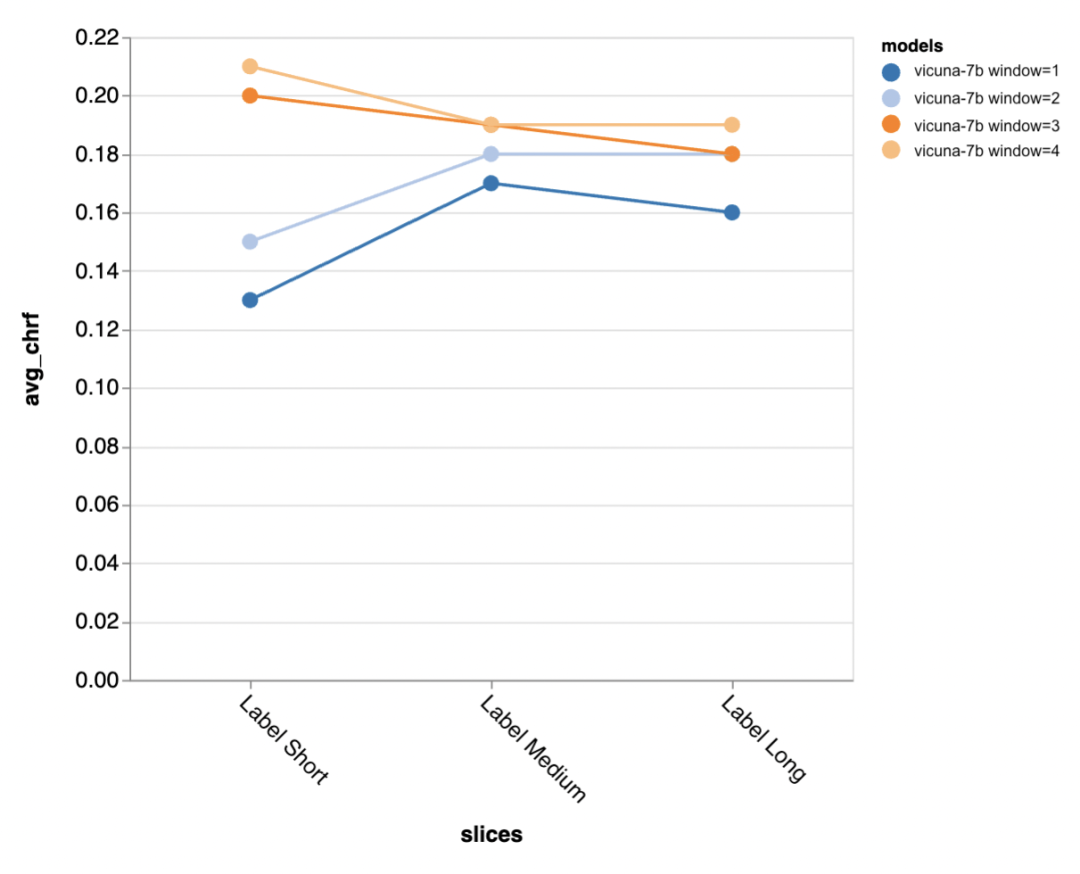
Les résultats de l'évaluation montrent qu'un contexte plus long est particulièrement important au milieu et à la fin de la conversation, car les réponses dans ces positions n'ont pas autant de modèles et s'appuient davantage sur ce qui a été dit auparavant. .
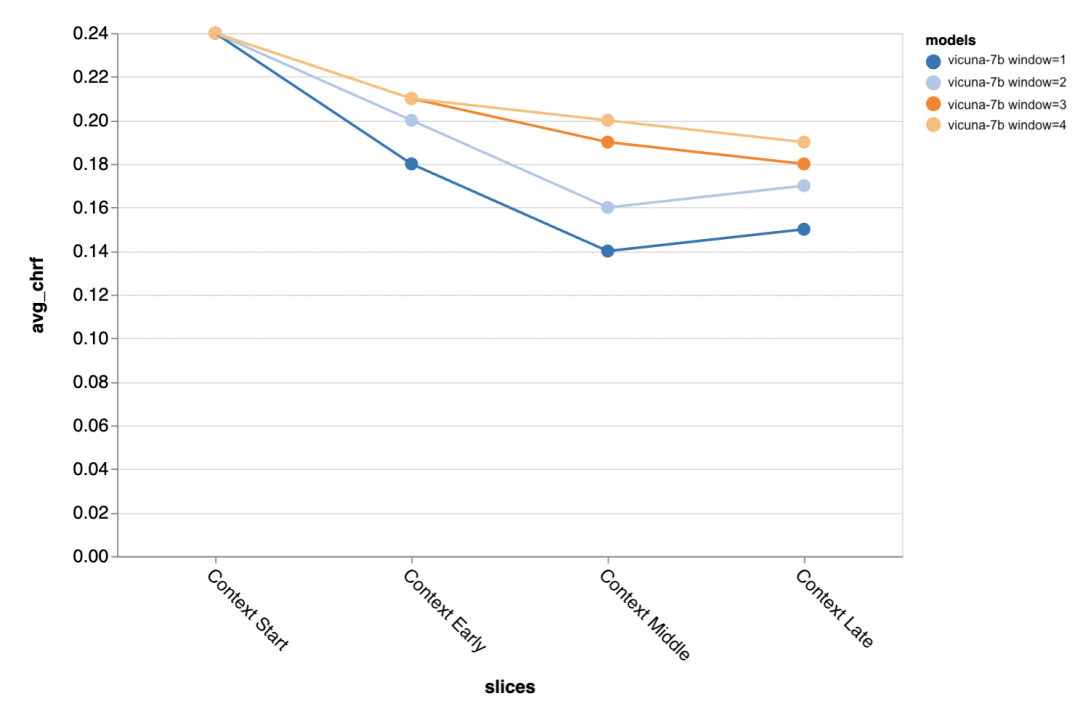
Plus de contexte est particulièrement important lorsque l'on essaie de générer une sortie plus courte de référence (probablement parce qu'il y a plus d'ambiguïté).
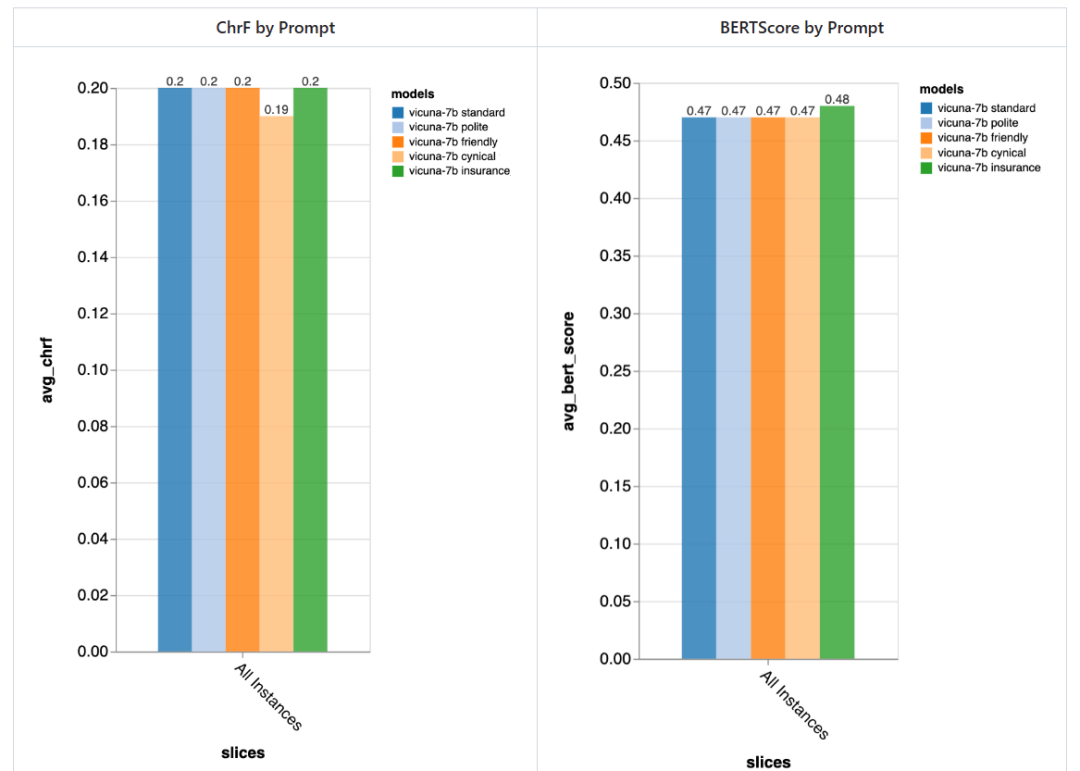
Quelle est l'importance de l'invite ?
L'évaluateur a essayé 5 invites différentes, dont 4 sont universelles, et une est spécifiquement adaptée aux tâches de chat du service client dans le domaine de l'assurance :
La différence apportée par les différentes invites est particulièrement évidente dans le premier tour de la conversation, ce qui montre que les invites sont les plus importantes lorsqu'il y a peu d'autres contextes sur lesquels s'appuyer.
Enfin, le critique a utilisé l'interface utilisateur d'exploration de Zeno pour essayer de trouver des bogues possibles via gpt-3.5-turbo. Plus précisément, ils ont examiné tous les exemples avec un faible chrf (
Échec de la sonde
Parfois, le modèle n'est pas en mesure de sonder plus d'informations lorsque cela est réellement nécessaire, par exemple, le modèle n'est pas encore parfait dans la gestion des numéros (les numéros de téléphone doivent comporter 11 chiffres, la longueur des numéros donnés par le modèle ne correspond pas à la réponse). Cela peut être atténué en modifiant l'invite pour rappeler au modèle la longueur requise de certaines informations.
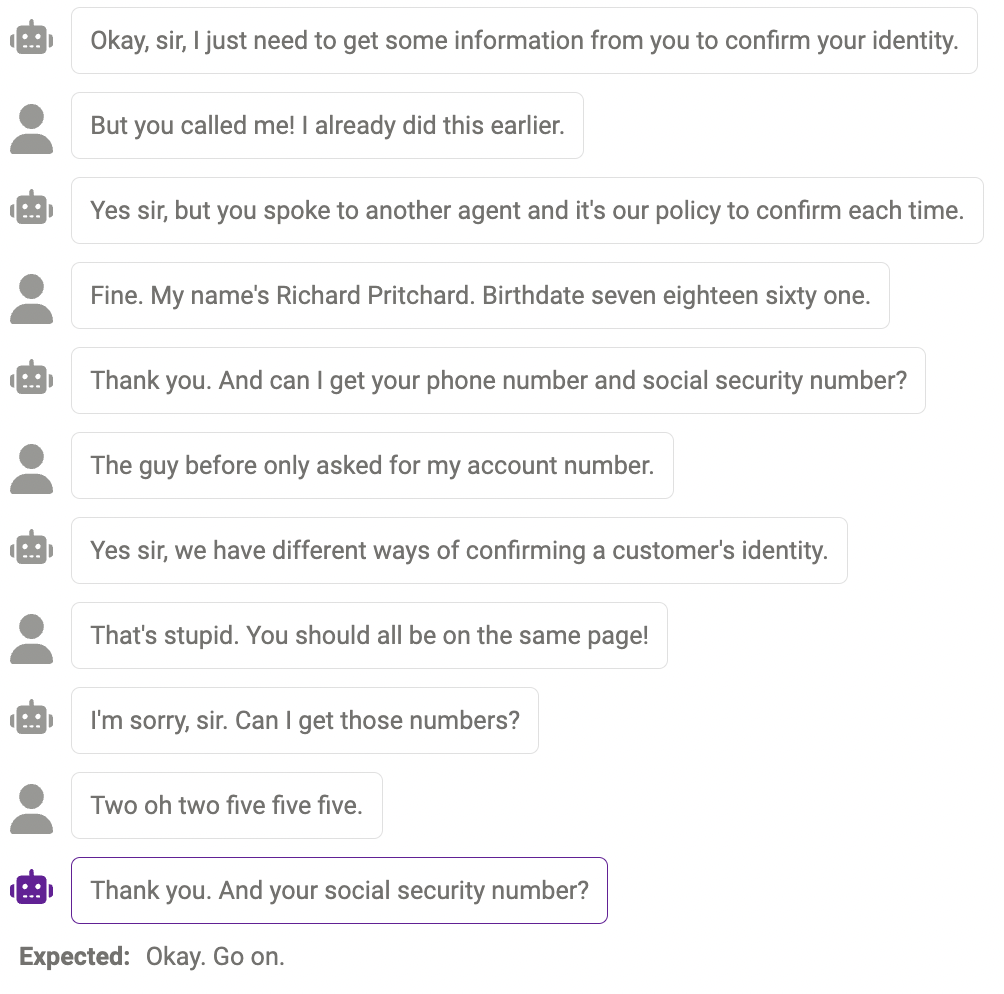
Contenu en double
Parfois, le même contenu est répété plusieurs fois, par exemple, le chatbot a dit "merci" deux fois ici.
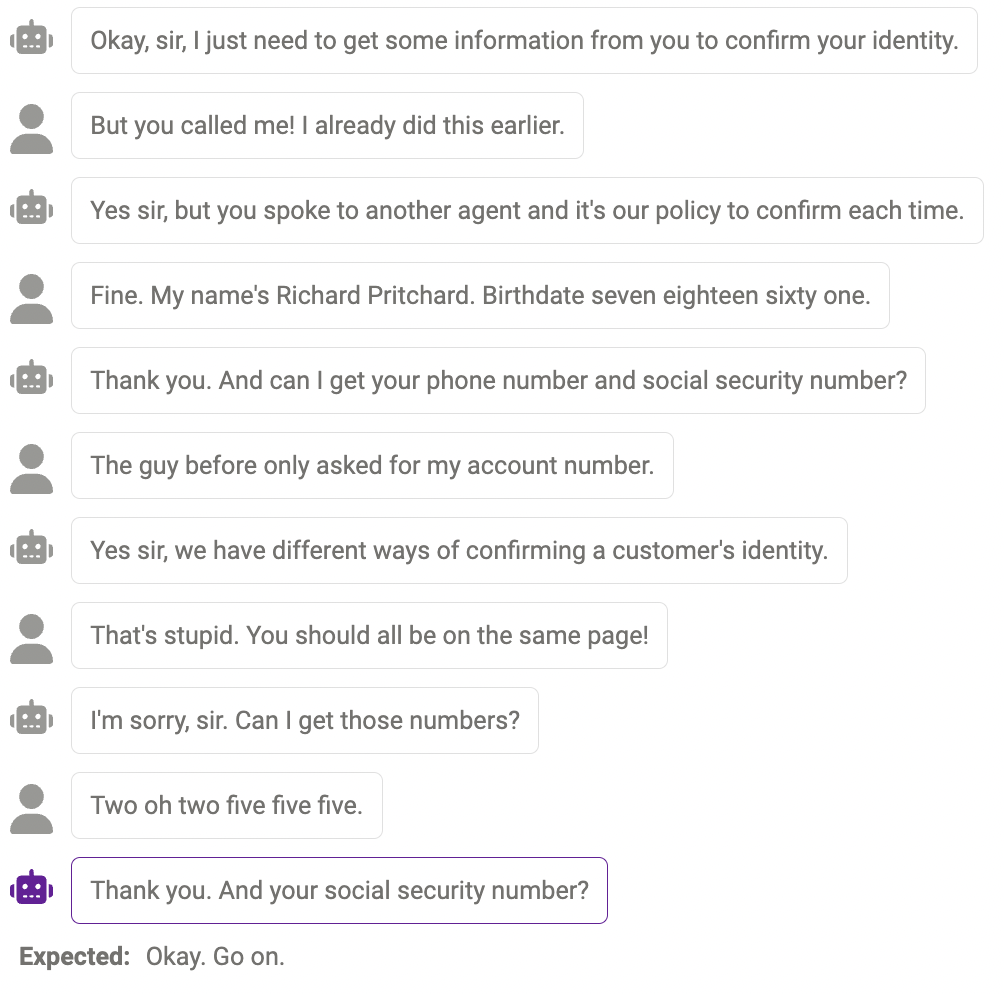
Une réponse qui a du sens, mais pas comme le font les humains
Parfois, la réponse est raisonnable, mais pas comme le feraient les humains.

Ce qui précède sont les résultats de l'évaluation. Enfin, les évaluateurs espèrent que ce rapport sera utile aux chercheurs ! Si vous souhaitez toujours essayer d'autres modèles, ensembles de données, invites ou autres paramètres d'hyperparamètres, vous pouvez accéder à l'exemple de chatbot sur le référentiel zeno-build pour l'essayer.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



