
 Périphériques technologiques
IA
L'ère de domination de Nvidia est-elle révolue ? ChatGPT déclenche une guerre des puces entre Google et Microsoft, et Amazon rejoint également le jeu
Périphériques technologiques
IA
L'ère de domination de Nvidia est-elle révolue ? ChatGPT déclenche une guerre des puces entre Google et Microsoft, et Amazon rejoint également le jeu
L'ère de domination de Nvidia est-elle révolue ? ChatGPT déclenche une guerre des puces entre Google et Microsoft, et Amazon rejoint également le jeu

Après que ChatGPT soit devenu populaire, la guerre de l'IA entre les deux géants Google et Microsoft a brûlé de nouvelles puces de serveur de terrain.
Aujourd'hui, l'IA et le cloud computing sont devenus des champs de bataille, et les puces sont également devenues la clé pour réduire les coûts et gagner des clients professionnels.
À l'origine, les grandes entreprises comme Amazon, Microsoft et Google étaient célèbres pour leurs logiciels, mais elles dépensent désormais des milliards de dollars en développement et en production de puces.

Puces IA développées par de grands géants de la technologie#🎜 🎜 #
ChatGPT explose, les grands fabricants lancent la compétition de pucesSelon les rapports des médias étrangers The Information et d'autres sources, ces trois grandes entreprises The L'usine a maintenant lancé ou prévoit de lancer 8 serveurs et puces IA pour le développement de produits internes, la location de serveurs cloud, ou les deux.
"Si vous parvenez à fabriquer du silicium optimisé pour l'IA, vous avez une énorme victoire devant vous", a déclaré Glenn O'Donnell, directeur du cabinet de recherche Forrester. .Dites-le de cette façon.
Ces énormes efforts seront-ils récompensés ?
La réponse est, pas nécessairement. Intel, AMD et Nvidia peuvent bénéficier d'économies d'échelle, mais c'est loin d'être le cas pour les grandes entreprises technologiques. Ils sont également confrontés à un certain nombre de défis épineux, tels que recruter des concepteurs de puces et convaincre les développeurs de créer des applications en utilisant leurs puces personnalisées.
Toutefois, les grands constructeurs ont réalisé des progrès impressionnants dans ce domaine.

Il existe deux principaux types de puces développées par Amazon, Microsoft et Google pour leurs centres de données : les puces informatiques standards et les puces spécialisées utilisées pour entraîner et exécuter des modèles d'apprentissage automatique. C'est ce dernier qui alimente les grands modèles de langage comme ChatGPT.
Auparavant, Apple développait avec succès des puces pour iPhone, iPad et Mac, améliorant le traitement de certaines tâches d'IA. Ces grands constructeurs se sont peut-être inspirés d’Apple.
Parmi les trois principaux fabricants, Amazon est le seul fournisseur de services cloud à proposer deux types de puces dans les serveurs. Le concepteur de puces israélien Annapurna Labs, acquis en 2015, fournit ces efforts. poser les bases. Google a lancé une puce pour les charges de travail d'IA en 2015 et développe une puce de serveur standard pour améliorer les performances du serveur de Google Cloud.
En revanche, la recherche et le développement de puces de Microsoft ont commencé plus tard, lancés en 2019, et récemment, Microsoft a été plus rapide dans le lancement de puces spécialement conçues pour la chronologie LLM des puces IA.
La popularité de ChatGPT a déclenché l'enthousiasme pour l'IA parmi les utilisateurs du monde entier. Cela a encore favorisé la transformation stratégique des trois principaux fabricants.
ChatGPT fonctionne sur le cloud Azure de Microsoft et utilise des dizaines de milliers de Nvidia A100. ChatGPT et d'autres logiciels OpenAI intégrés à Bing et à divers programmes nécessitent tellement de puissance de calcul que Microsoft a alloué du matériel serveur aux équipes internes développant l'IA.
Chez Amazon, le directeur financier Brian Olsavsky a déclaré aux investisseurs lors d'un appel aux résultats la semaine dernière qu'Amazon prévoyait de transférer ses dépenses de son activité de vente au détail vers AWS, en partie à cause d'Invest dans l'infrastructure nécessaire pour prendre en charge ChatGPT.
Chez Google, l'équipe d'ingénierie responsable de la construction de l'unité de traitement Tensor a été transférée vers Google Cloud. Il semblerait que les organisations cloud puissent désormais développer une feuille de route pour les TPU et les logiciels qui les exécutent, dans l'espoir de permettre aux clients du cloud de louer davantage de serveurs équipés de TPU. Dès 2020, Google a déployé la puce IA la plus puissante de l'époque, le TPU v4, dans son propre centre de données. Cependant, ce n'est que le 4 avril de cette année que Google a annoncé pour la première fois les détails techniques de ce supercalculateur IA. Google : TPU V4 spécialement adapté à l'IA
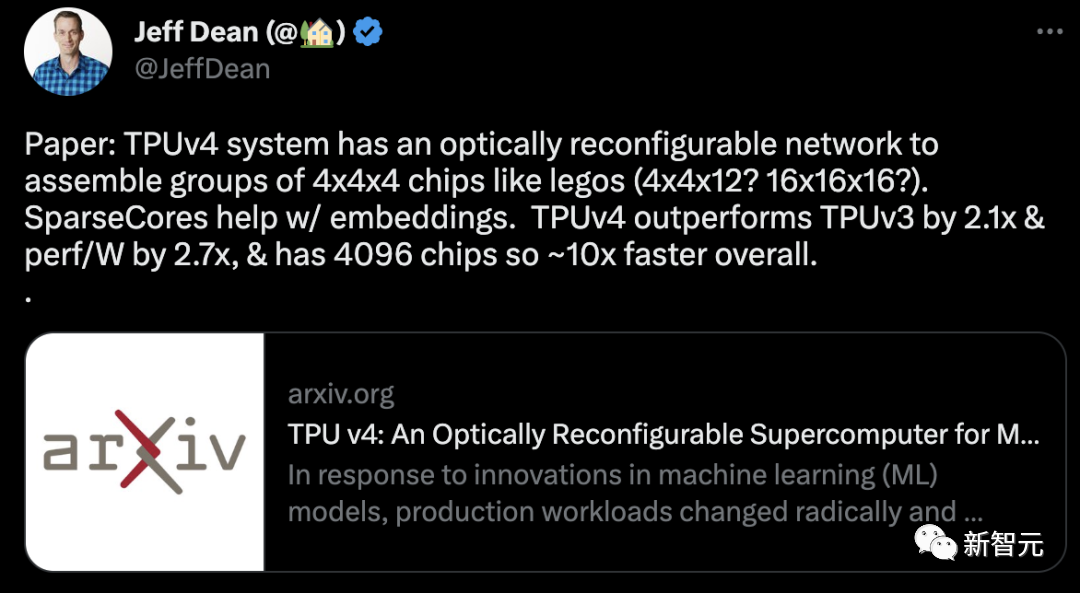
Par rapport au TPU v3, les performances du TPU v4 sont 2,1 fois supérieures, et après avoir intégré 4096 puces, les performances du supercalcul sont améliorées de 10 fois.
Dans le même temps, Google affirme également que sa propre puce est plus rapide et plus économe en énergie que NVIDIA A100. Pour des systèmes de taille comparable, le TPU v4 peut offrir des performances 1,7 fois supérieures à celles du NVIDIA A100, tout en améliorant également l'efficacité énergétique de 1,9 fois.
Pour des systèmes de taille similaire, TPU v4 est 1,15 fois plus rapide que l'A100 sur BERT et environ 4,3 fois plus rapide que l'IPU. Pour ResNet, TPU v4 est respectivement 1,67x et environ 4,5x plus rapide.
Par ailleurs, Google a laissé entendre qu'il travaillait sur un nouveau TPU pour concurrencer le Nvidia H100. Jouppi, chercheur chez Google, a déclaré dans une interview à Reuters que Google disposait d'une "ligne de production pour les futures puces".
Microsoft : l'arme secrète Athéna
Quoi qu'il en soit, Microsoft est toujours impatient d'essayer dans ce conflit de puces.
Auparavant, la nouvelle avait été annoncée selon laquelle une équipe de 300 personnes secrètement formée par Microsoft avait commencé à développer une puce personnalisée appelée « Athena » en 2019.

Selon le plan initial, "Athena" sera construit à l'aide du processus 5 nm de TSMC, qui devrait réduire le coût de chaque puce d'un tiers.
S'il peut être mis en œuvre à grande échelle l'année prochaine, les équipes internes de Microsoft et OpenAI pourront utiliser "Athena" pour effectuer simultanément la formation et l'inférence du modèle.
De cette façon, la pénurie d'ordinateurs dédiés peut être grandement atténuée.
Bloomberg a rapporté la semaine dernière que la division puces de Microsoft avait coopéré avec AMD pour développer la puce Athena, ce qui a également entraîné une hausse du cours de l'action d'AMD de 6,5 % jeudi.
Mais un initié a déclaré qu'AMD n'était pas impliqué, mais développait son propre GPU pour concurrencer Nvidia, et AMD a discuté de la conception de la puce avec Microsoft car Microsoft devrait acheter ce GPU.
Amazon : Déjà en tête
Dans la course aux puces avec Microsoft et Google, Amazon semble avoir pris les devants.
Au cours de la dernière décennie, Amazon a conservé un avantage concurrentiel sur Microsoft et Google dans les services de cloud computing en proposant une technologie plus avancée et des prix plus bas.
Au cours des dix prochaines années, Amazon devrait également continuer à conserver un avantage concurrentiel grâce à sa propre puce de serveur, Graviton, développée en interne.
En tant que dernière génération de processeurs, AWS Graviton3 améliore les performances de calcul jusqu'à 25 % par rapport à la génération précédente et améliore les performances en virgule flottante jusqu'à 2 fois. Il prend également en charge la mémoire DDR5, dont la bande passante est augmentée de 50 % par rapport à la mémoire DDR4.
Pour les charges de travail d'apprentissage automatique, AWS Graviton3 offre des performances jusqu'à 3 fois supérieures à celles de la génération précédente et prend en charge bfloat16.
Les services cloud basés sur les puces Graviton 3 sont très populaires dans certaines régions, et ont même atteint un état d'offre dépassant la demande.
Un autre avantage d'Amazon est qu'il est actuellement le seul fournisseur de cloud qui fournit des puces informatiques standards (Graviton) et des puces spécifiques à l'IA (Inferentia et Trainium) dans ses serveurs.
Dès 2019, Amazon a lancé sa propre puce d'inférence d'IA, Inferentia.
Il permet aux clients d'exécuter des applications d'inférence d'apprentissage automatique à grande échelle telles que la reconnaissance d'images, la reconnaissance vocale, le traitement du langage naturel, la personnalisation et la détection de fraude à faible coût dans le cloud.
Le dernier Inferentia 2 a amélioré les performances de calcul de 3 fois, la mémoire totale de l'accélérateur a été étendue de 4 fois, le débit a été augmenté de 4 fois et la latence a été réduite à 1/10.

Après le lancement de l'Inferentia original, Amazon a publié une puce personnalisée conçue principalement pour la formation en IA - Trainium.
Il est optimisé pour les charges de travail de formation en deep learning, notamment la classification d'images, la recherche sémantique, la traduction, la reconnaissance vocale, le traitement du langage naturel et les moteurs de recommandation, etc.

Dans certains cas, la personnalisation des puces peut non seulement réduire les coûts d'un ordre de grandeur et réduire la consommation d'énergie à 1/10, mais ces solutions personnalisées peuvent fournir aux clients de meilleurs services avec une latence plus faible. .
Il n'est pas si facile d'ébranler le monopole de NVIDIA
Mais jusqu'à présent, la plupart des charges de travail d'IA fonctionnent toujours sur des GPU et NVIDIA produit la plupart des puces.
Selon des rapports précédents, la part de marché des GPU indépendants de Nvidia a atteint 80 % et sa part de marché des GPU haut de gamme a atteint 90 %.
En 20 ans, 80,6 % des centres de cloud computing et de données mondiaux exécutant l’IA ont été pilotés par des GPU NVIDIA. En 2021, Nvidia a déclaré qu'environ 70 % des 500 meilleurs superordinateurs du monde étaient pilotés par ses propres puces.
Et maintenant, même le centre de données Microsoft exécutant ChatGPT utilise des dizaines de milliers de GPU NVIDIA A100.
Pendant longtemps, qu'il s'agisse du top ChatGPT, ou du Bard, du Stable Diffusion et d'autres modèles, derrière lui se cache la puissance de calcul fournie par la puce NVIDIA A100 d'une valeur d'environ 10 000 $ US chacune.

De plus, l'A100 est désormais devenu le « principal cheval de bataille » des professionnels de l'intelligence artificielle. Le rapport 2022 sur l’état de l’intelligence artificielle répertorie également certaines des entreprises utilisant le supercalculateur A100.
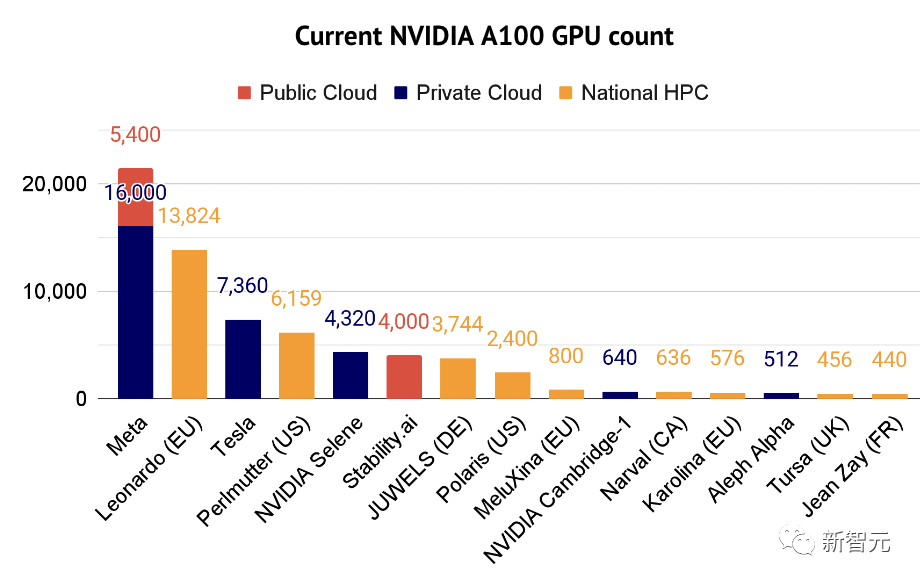
Il est évident que NVIDIA a monopolisé la puissance de calcul mondiale et domine le monde avec ses propres puces.
Selon les praticiens, par rapport aux puces à usage général, les puces à circuits intégrés spécifiques à une application (ASIC) développées par Amazon, Google et Microsoft peuvent effectuer des tâches d'apprentissage automatique plus rapidement et consommer moins d'énergie.
Le directeur O'Donnell a utilisé cette comparaison en comparant les GPU et les ASIC : "Vous pouvez utiliser une Prius pour la conduite quotidienne, mais si vous devez utiliser les quatre roues motrices en montagne, une Jeep Wrangler serait plus adaptée."

Cependant, malgré tous les efforts, Amazon, Google et Microsoft sont tous confrontés à des défis : comment convaincre les développeurs d'utiliser ces puces d'IA ?
Maintenant, les GPU de NVIDIA sont dominants et les développeurs connaissent déjà son langage de programmation propriétaire CUDA pour créer des applications pilotées par GPU.
S'ils passent à une puce personnalisée d'Amazon, de Google ou de Microsoft, ils devront apprendre un nouveau langage logiciel. Seront-ils disposés ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
Pour créer un tableau de données à l'aide de PhpMyAdmin, les étapes suivantes sont essentielles: connectez-vous à la base de données et cliquez sur le nouvel onglet. Nommez le tableau et sélectionnez le moteur de stockage (InnODB recommandé). Ajouter les détails de la colonne en cliquant sur le bouton Ajouter une colonne, y compris le nom de la colonne, le type de données, s'il faut autoriser les valeurs nuls et d'autres propriétés. Sélectionnez une ou plusieurs colonnes comme clés principales. Cliquez sur le bouton Enregistrer pour créer des tables et des colonnes.
 Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
La création d'une base de données Oracle n'est pas facile, vous devez comprendre le mécanisme sous-jacent. 1. Vous devez comprendre les concepts de la base de données et des SGBD Oracle; 2. Master les concepts de base tels que SID, CDB (base de données de conteneurs), PDB (base de données enfichable); 3. Utilisez SQL * Plus pour créer CDB, puis créer PDB, vous devez spécifier des paramètres tels que la taille, le nombre de fichiers de données et les chemins; 4. Les applications avancées doivent ajuster le jeu de caractères, la mémoire et d'autres paramètres et effectuer un réglage des performances; 5. Faites attention à l'espace disque, aux autorisations et aux paramètres des paramètres, et surveillez et optimisez en continu les performances de la base de données. Ce n'est qu'en le maîtrisant habilement une pratique continue que vous pouvez vraiment comprendre la création et la gestion des bases de données Oracle.
 Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:36 PM
Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:36 PM
Pour créer une base de données Oracle, la méthode commune consiste à utiliser l'outil graphique DBCA. Les étapes sont les suivantes: 1. Utilisez l'outil DBCA pour définir le nom DBN pour spécifier le nom de la base de données; 2. Définissez Syspassword et SystemPassword sur des mots de passe forts; 3. Définir les caractères et NationalCharacterset à Al32Utf8; 4. Définissez la taille de mémoire et les espaces de table pour s'ajuster en fonction des besoins réels; 5. Spécifiez le chemin du fichier log. Les méthodes avancées sont créées manuellement à l'aide de commandes SQL, mais sont plus complexes et sujets aux erreurs. Faites attention à la force du mot de passe, à la sélection du jeu de caractères, à la taille et à la mémoire de l'espace de table
 Comment rédiger des instructions de base de données Oracle
Apr 11, 2025 pm 02:42 PM
Comment rédiger des instructions de base de données Oracle
Apr 11, 2025 pm 02:42 PM
Le cœur des instructions Oracle SQL est sélectionné, insérer, mettre à jour et supprimer, ainsi que l'application flexible de diverses clauses. Il est crucial de comprendre le mécanisme d'exécution derrière l'instruction, tel que l'optimisation de l'indice. Les usages avancés comprennent des sous-requêtes, des requêtes de connexion, des fonctions d'analyse et PL / SQL. Les erreurs courantes incluent les erreurs de syntaxe, les problèmes de performances et les problèmes de cohérence des données. Les meilleures pratiques d'optimisation des performances impliquent d'utiliser des index appropriés, d'éviter la sélection *, d'optimiser les clauses et d'utiliser des variables liées. La maîtrise d'Oracle SQL nécessite de la pratique, y compris l'écriture de code, le débogage, la réflexion et la compréhension des mécanismes sous-jacents.
 Comment ajouter, modifier et supprimer le guide de fonctionnement du champ de table de données MySQL
Apr 11, 2025 pm 05:42 PM
Comment ajouter, modifier et supprimer le guide de fonctionnement du champ de table de données MySQL
Apr 11, 2025 pm 05:42 PM
Guide de fonctionnement du champ dans MySQL: Ajouter, modifier et supprimer les champs. Ajouter un champ: alter table table_name Ajouter Column_name data_type [pas null] [Default default_value] [Clé primaire] [Auto_increment] Modifier le champ: alter table table_name modifie Column_name data_type [pas null] [default default_value] [clé primaire]
 Quelles sont les contraintes d'intégrité des tables de base de données Oracle?
Apr 11, 2025 pm 03:42 PM
Quelles sont les contraintes d'intégrité des tables de base de données Oracle?
Apr 11, 2025 pm 03:42 PM
Les contraintes d'intégrité des bases de données Oracle peuvent garantir la précision des données, notamment: Not Null: les valeurs nulles sont interdites; Unique: garantie l'unicité, permettant une seule valeur nulle; Clé primaire: contrainte de clé primaire, renforcer unique et interdire les valeurs nulles; Clé étrangère: maintenir les relations entre les tableaux, les clés étrangères se réfèrent aux clés primaires primaires; Vérifiez: limitez les valeurs de colonne en fonction des conditions.
 Explication détaillée des instances de requête imbriquées dans la base de données MySQL
Apr 11, 2025 pm 05:48 PM
Explication détaillée des instances de requête imbriquées dans la base de données MySQL
Apr 11, 2025 pm 05:48 PM
Les requêtes imbriquées sont un moyen d'inclure une autre requête dans une requête. Ils sont principalement utilisés pour récupérer des données qui remplissent des conditions complexes, associer plusieurs tables et calculer des valeurs de résumé ou des informations statistiques. Les exemples incluent la recherche de salaires supérieurs aux employés, la recherche de commandes pour une catégorie spécifique et le calcul du volume des commandes totales pour chaque produit. Lorsque vous écrivez des requêtes imbriquées, vous devez suivre: écrire des sous-requêtes, écrire leurs résultats sur les requêtes extérieures (référencées avec des alias ou en tant que clauses) et optimiser les performances de la requête (en utilisant des index).
 Comment les journaux Tomcat aident à dépanner les fuites de mémoire
Apr 12, 2025 pm 11:42 PM
Comment les journaux Tomcat aident à dépanner les fuites de mémoire
Apr 12, 2025 pm 11:42 PM
Les journaux TomCat sont la clé pour diagnostiquer les problèmes de fuite de mémoire. En analysant les journaux TomCat, vous pouvez avoir un aperçu de l'utilisation de la mémoire et du comportement de collecte des ordures (GC), localiser et résoudre efficacement les fuites de mémoire. Voici comment dépanner les fuites de mémoire à l'aide des journaux Tomcat: 1. Analyse des journaux GC d'abord, activez d'abord la journalisation GC détaillée. Ajoutez les options JVM suivantes aux paramètres de démarrage TomCat: -xx: printgcdetails-xx: printgcdatestamps-xloggc: gc.log Ces paramètres généreront un journal GC détaillé (GC.Log), y compris des informations telles que le type GC, la taille et le temps des objets de recyclage. Analyse GC.Log
